A topologia dos modernos data centers e dispositivos neles não nos permite mais nos contentar exclusivamente com o
monitoramento da caixa branca . Com o tempo, precisei de uma ferramenta que mostrasse o desempenho de dispositivos específicos, com base na situação real da transferência de tráfego (dataplane) em qualquer lugar da
rede Clos . Algumas semanas atrás, na conferência
Next Hop , o engenheiro de rede da Yandex, Alexander Klimenko, compartilhou sua experiência na solução desse problema.
- Trabalho no departamento de operação e desenvolvimento da rede Yandex e às vezes sou forçado a resolver alguns problemas, em vez de desenhar belas nuvens nas folhas ou inventar um futuro brilhante. As pessoas vêm e dizem que algo não funciona para elas. Se esse assunto for monitorado, se nossos engenheiros de serviço perceberem que não funciona, será mais fácil para mim. Portanto, essas meia hora serão dedicadas ao monitoramento.

Mais cedo ou mais tarde, todos chegam à ideia de monitorar. Ou seja, a princípio, você pode coletar recursos dos próprios usuários, eles irão bater em você e dizer que algo não está funcionando para eles. Mas é claro que esse sistema não escala bem. Se você possui mais de um comutador, se possui uma rede suficientemente grande, com esta opção de monitoramento, você não pode ir longe.
E, mais cedo ou mais tarde, todos chegam à conclusão de que é necessário coletar alguns dados do equipamento. Este é o primeiro passo. Pode ser logs, vários dados no SNMP, descargas, você pode construir topologias de acordo com o LLDP, etc. Há um sinal de menos - o próprio dispositivo fornece toda essa informação para você. Pode não dizer nada, enganá-lo etc.
O estágio lógico no desenvolvimento do seu monitoramento é o monitoramento nos hosts. Podemos dizer que há um pequeno ramo. Se você tiver sorte - ou não - de ter uma rede em um fornecedor, ele poderá oferecer algumas de suas próprias opções de monitoramento. Mas no ano passado, no Next Hop, Dima Ershov
disse que nossa fábrica foi criada a partir de dois fornecedores básicos e que não podemos permitir esse luxo. Ou podemos, mas apenas parcialmente.
Finalmente, a última opção, que todos de alguma forma alcançam com o desenvolvimento da rede. Isso está monitorando nos hosts finais. Yandex tem esse monitoramento. É chamado Netmon.

Na parte inferior do slide,
há um link com uma apresentação detalhada sobre como o Netmon funciona. Vou dizer literalmente dentro de um slide. Se alguém quiser, leia a palestra de outra conferência da Netmon.
Netmon são agentes instalados em quase todos os hosts da rede. A tarefa chega aos agentes: enviar alguns pacotes para algum nó da rede. Eles podem ser completamente diferentes: UDP, TCP, ICMP. Pode ser como tintas diferentes, ou seja, DSCP e destino. As portas de origem e destino também podem ser diferentes.
Esses dados são agregados, carregados em um armazenamento separado e obtemos aqui uma fatia como a da direita na figura. Uma fatia pode ser mais agregada ou menos agregada, dependendo do que queremos ver. Por exemplo, aqui, até onde eu vejo, temos uma fatia de toda a conectividade do data center, ou seja, entre todos os nossos data centers. Podemos cair mais fundo nos quadrados - ver a conectividade entre o POD ou dentro do edifício de um data center; ainda mais profundo - dentro do POD entre os racks; e ainda mais profundo - mesmo dentro do rack.

O que poderia dar errado aqui? Uma pequena digressão para quem não assistiu ao Next Hop do ano passado.
Utilizamos 400 gigabits por ToR e, no primeiro momento de implementação desta fábrica, incluímos apenas 200, porque havia tarefas mais importantes. Não importa o porquê. Eles ligaram 200, os serviços vieram e disseram: por que 200? Queremos 400! Começou a ligá-lo. E aconteceu que a segunda parte da fábrica, que incluímos, tinha algum tipo de casamento na memória dos cartões. Como resultado, ligamos a fábrica e vemos esta imagem:

Este Netmon, os quadrados vermelhos, está pegando fogo. Entendemos que tudo está perdido. Agarramos nossas cabeças, como Homer, e tentamos empurrar algo freneticamente. E o que pressionar, o que desligar, não entendemos. Ou seja, o Netmon nos mostra a presença de um problema, mas não mostra onde, de fato, o problema está localizado na rede.

Chegamos à tarefa que precisamos concluir. O que precisa ser feito? Determine com qual dispositivo da rede há um problema e tire-o de serviço - automaticamente, ou por forças, por exemplo, engenheiros de serviço.
Além disso, as condições iniciais são tais que temos uma topologia bastante regular, ou seja, não há vínculos estranhos entre giros de segundo nível ou entre toros. Temos a maior parte do tráfego - TCP, existe um local central, já fomos informados sobre o assunto e os servidores são administrados mais ou menos centralmente. Podemos chegar a esse lugar central e razoavelmente declarar: pessoal, queremos fazê-lo, por favor.
Que opções consideramos?

A primeira coisa que vem à mente é o rastreamento. Porque Como o mesmo Netmon descarrega os pares de origem e destino com falha em um coletor separado. Assim, podemos pegar essa 5-tupla, olhar para ela e fazer um rastreamento com os mesmos parâmetros. E para agregar dados sobre qual link ou através de quais dispositivos o maior número de rastreamentos passa.
Infelizmente, porém, o MPLS é usado em nossa fábrica (agora estamos nos movendo na direção oposta do MPLS, mas também precisamos monitorar as antigas fábricas de alguma forma, mas não as descartamos, na verdade). Temos o MPLS na fábrica e o problema com o MPLS e o rastreamento é que ele precisa encapsular a mensagem ICMP excedida TTL, subjacente ao rastreamento. Tendo perdido essa mensagem da entrada para a saída, podemos perder o próprio monitoramento. Ou seja, não entenderemos por quais nós essa mensagem passou. Isso não nos convinha para o monitoramento.
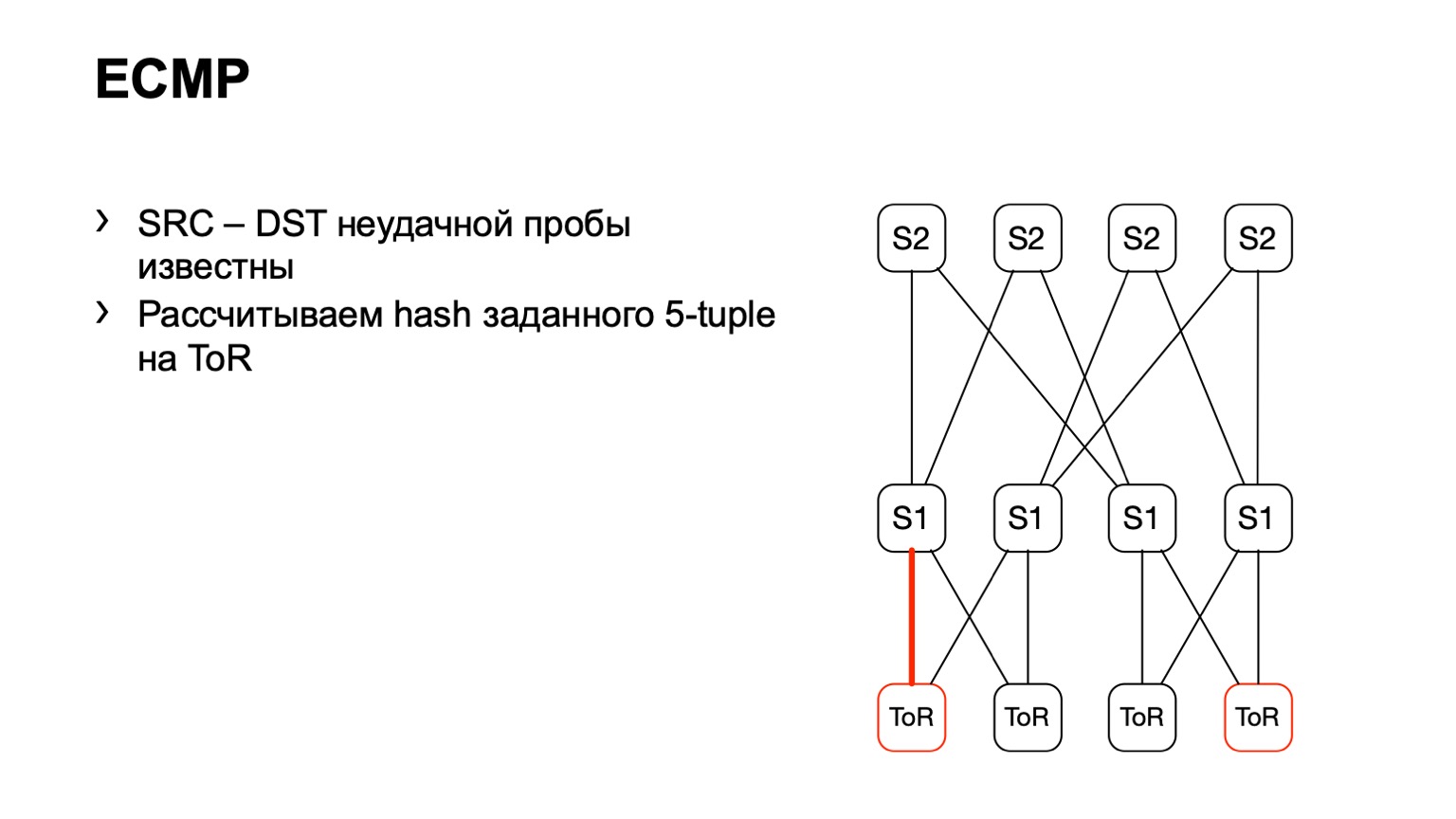
Há uma segunda opção relacionada ao ECMP. Adotamos o mesmo par de origem e destino, além de origem-porta destino-porta. Chegamos a um pedaço de ferro, por meio da API ou da CLI, alimentamos esse pedaço de ferro com o pedaço de ferro e obtemos a interface de saída. Muitos dispositivos suportam esse tipo de saída.
Chegamos ao ToR, veja que o ToR escolheu um link esquerdo ou direito. Nesse caso, o link esquerdo está voltado para o S1 esquerdo.
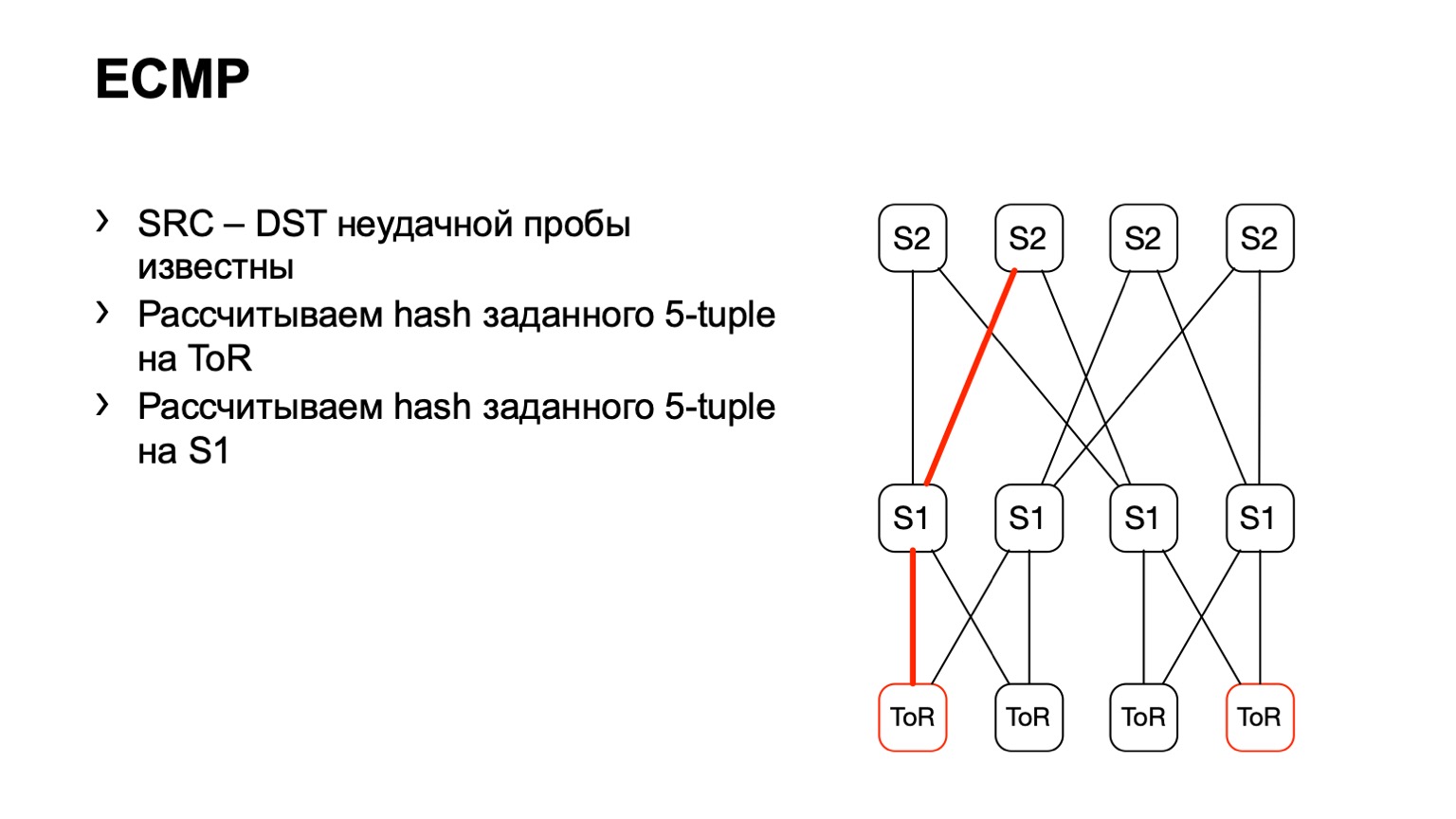
Chegamos a este S1, parecíamos, à direita S2, e dessa maneira um caminho pronto se formou.
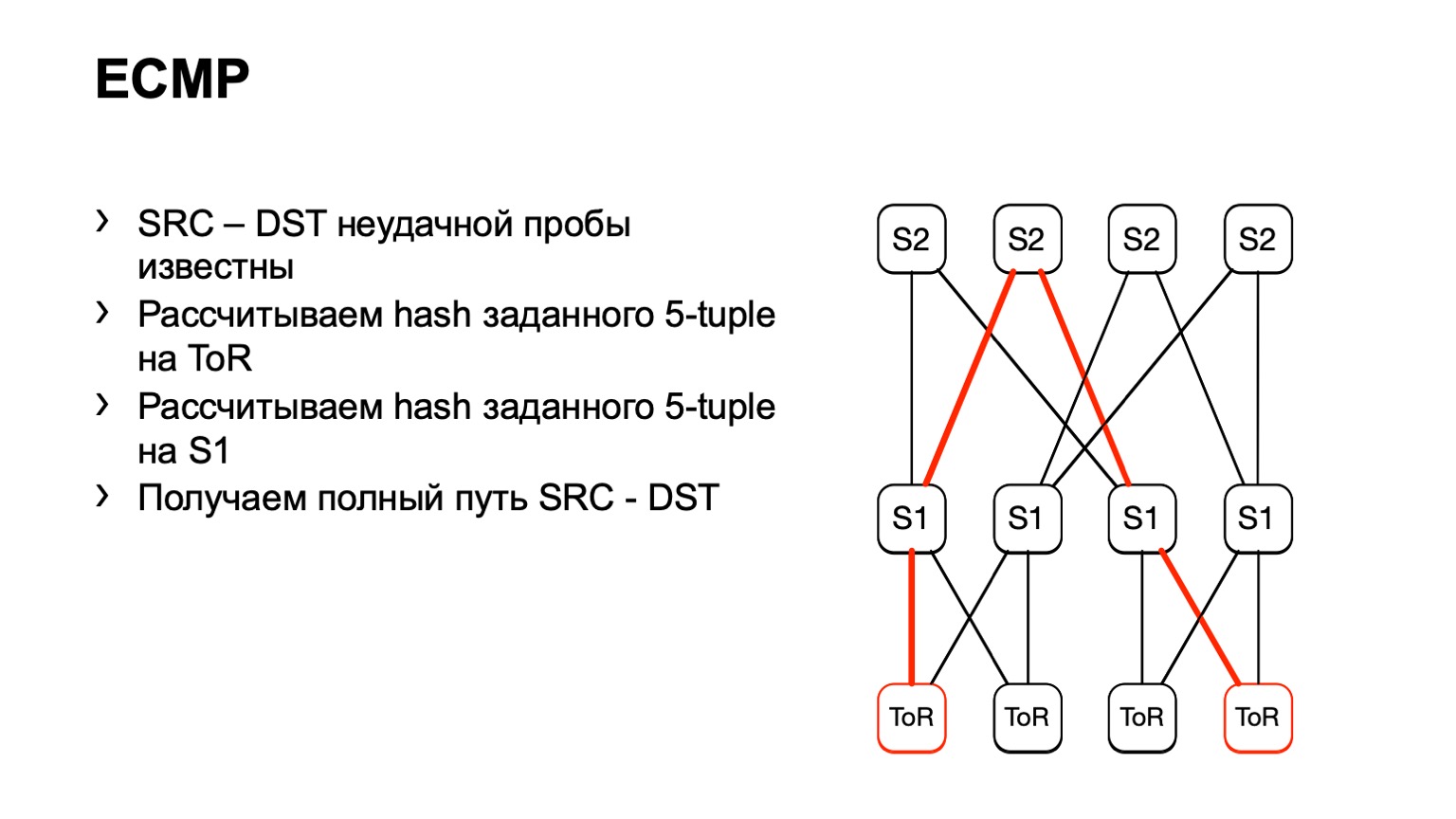
Existem algumas desvantagens. Em primeiro lugar, nem todos os dispositivos podem normalmente aceitar esses dados de entrada que fornecemos a eles. Isso se deve ao fato de termos IPv6 e MPLS, além de alguns fornecedores simplesmente não implementarem isso. O segundo ponto negativo desta solução: confiamos no que o pedaço de ferro nos dirá novamente, em vez de observar o que está acontecendo nos hosts. E, finalmente, o terceiro menos - durante o tempo em que você vai ver o que acontece, algo já pode mudar na rede e seus dados não serão relevantes.

Então nos deparamos com uma apresentação interessante feita pelo Facebook. Gostamos da ideia que o Facebook propôs, decidimos tentar fazer algo semelhante.
Qual foi a ideia principal? Use um programa eBPF no host para colorir a retransmissão TCP e depois calcular o número de tais pacotes. Infelizmente, não conseguimos fazê-lo como no Facebook, tivemos que inventar nossa própria bicicleta. Vou tentar falar sobre o caminho da dor e do sofrimento que atravessamos.
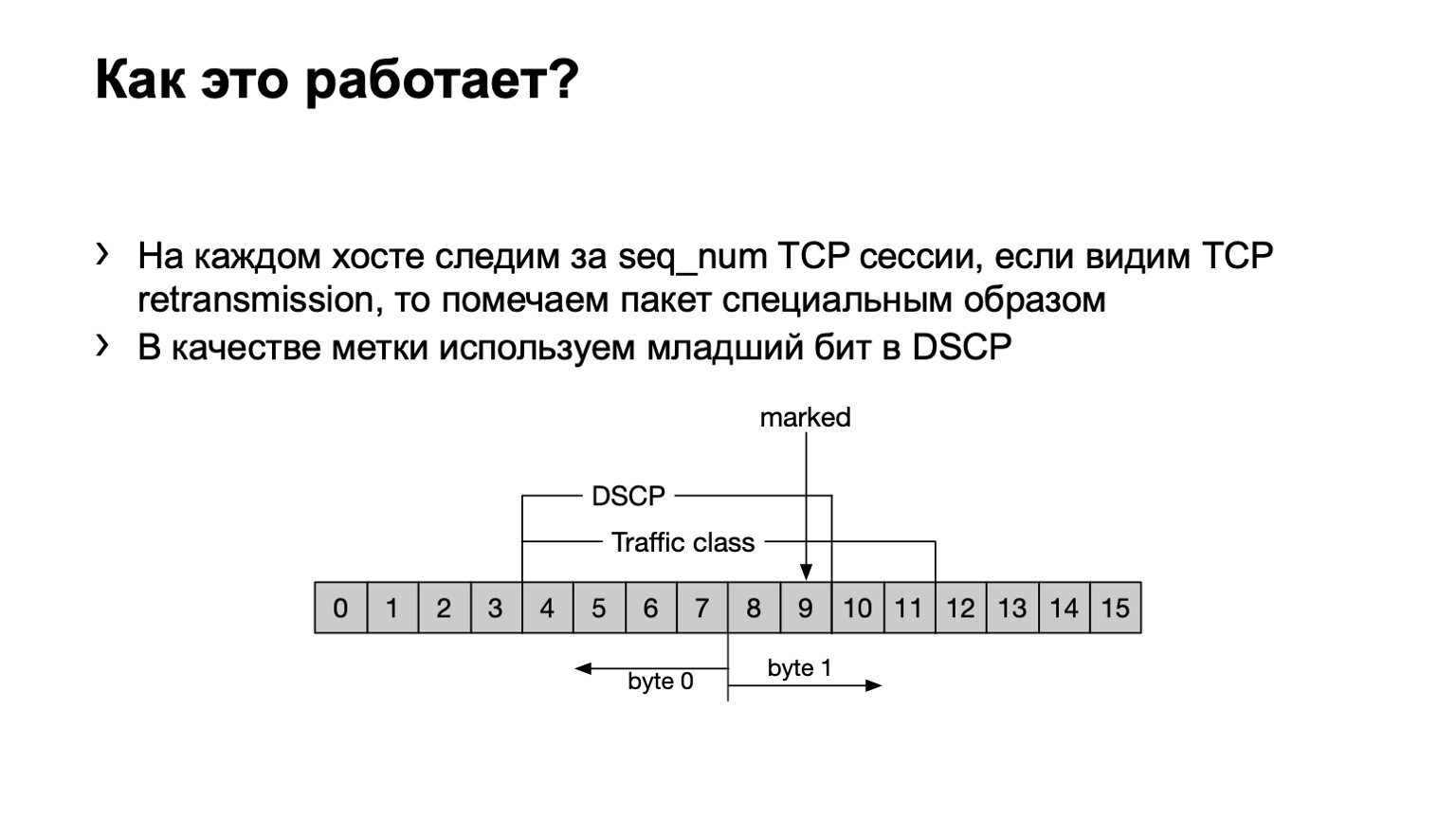
O que fizemos? Só para garantir, ressaltarei que a retransmissão TCP é uma mensagem TCP repetida várias vezes devido ao fato de o recebimento não ter sido confirmado. Temos um programa eBPF instalado no host e verifica se essa mensagem TCP é retransmitida ou não. Fá-lo brega - pelo número de sequência. Se o mesmo número de sequência for transmitido em uma sessão TCP, isso será retransmitido.
O que fazemos com esses pacotes? Definimos o último bit no campo DSCP como um para calcular ainda mais a coisa toda.
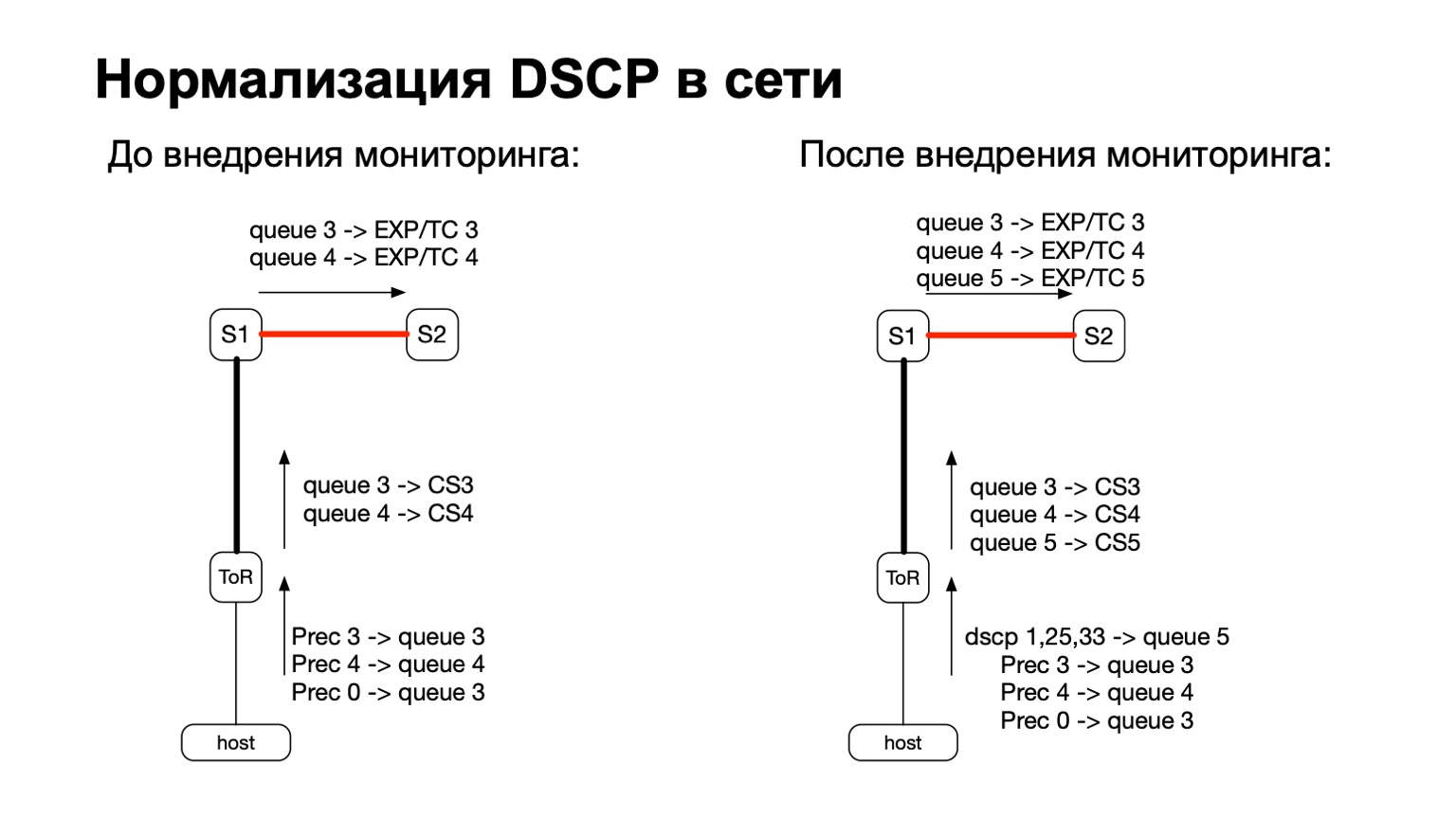
De um modo geral, o DSCP está de alguma forma relacionado à QoS, certo? E com a QoS, a história em nossa rede é bastante complicada e antiga. Temos certas políticas que são monitoradas nos switches ToR. A essas políticas, adicionamos a necessidade de contar mais e esses pacotes coloridos.
Assim, para pacotes coloridos (leia-se: para pacotes de retransmissão TCP do host), simplesmente adicionamos outra fila de QoS. Isso foi fácil o suficiente, porque ainda tínhamos linhas livres. Além disso, isso é conveniente, porque no estágio de transição entre IPv6 e MPLS na fábrica, ou seja, no estágio em que o pacote voa S1 e sai para a parte MPLS da fábrica, é conveniente pegar e repintar EXP / TC no cabeçalho do pacote MPLS para cada fila específica .
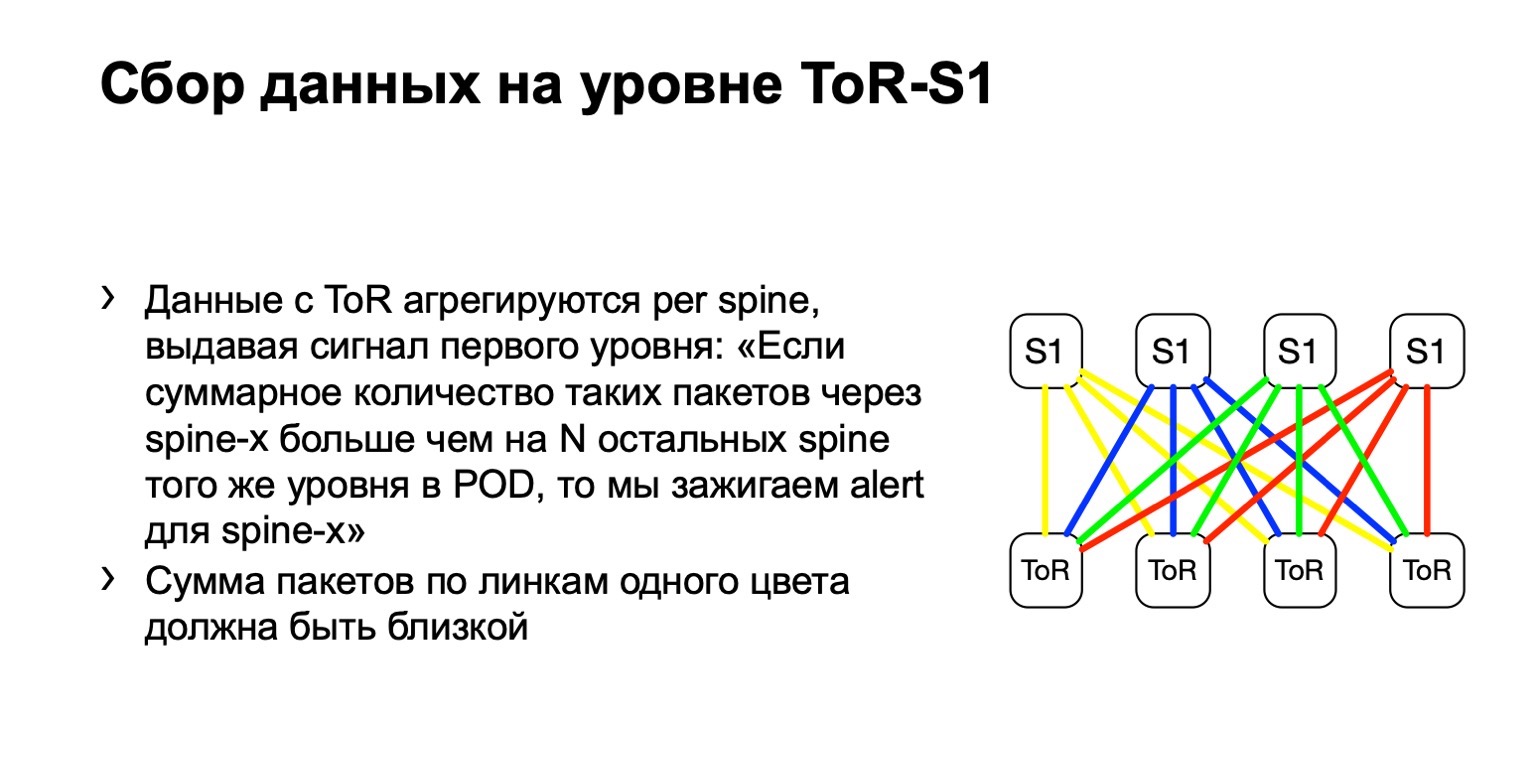
O que fazemos com esses dados? Nós os coletamos com filtros ACL padrão, classe de tráfego. Ou seja, funciona, em princípio, em qualquer fornecedor. Podemos coletar e calcular o número desses pacotes em qualquer lugar.
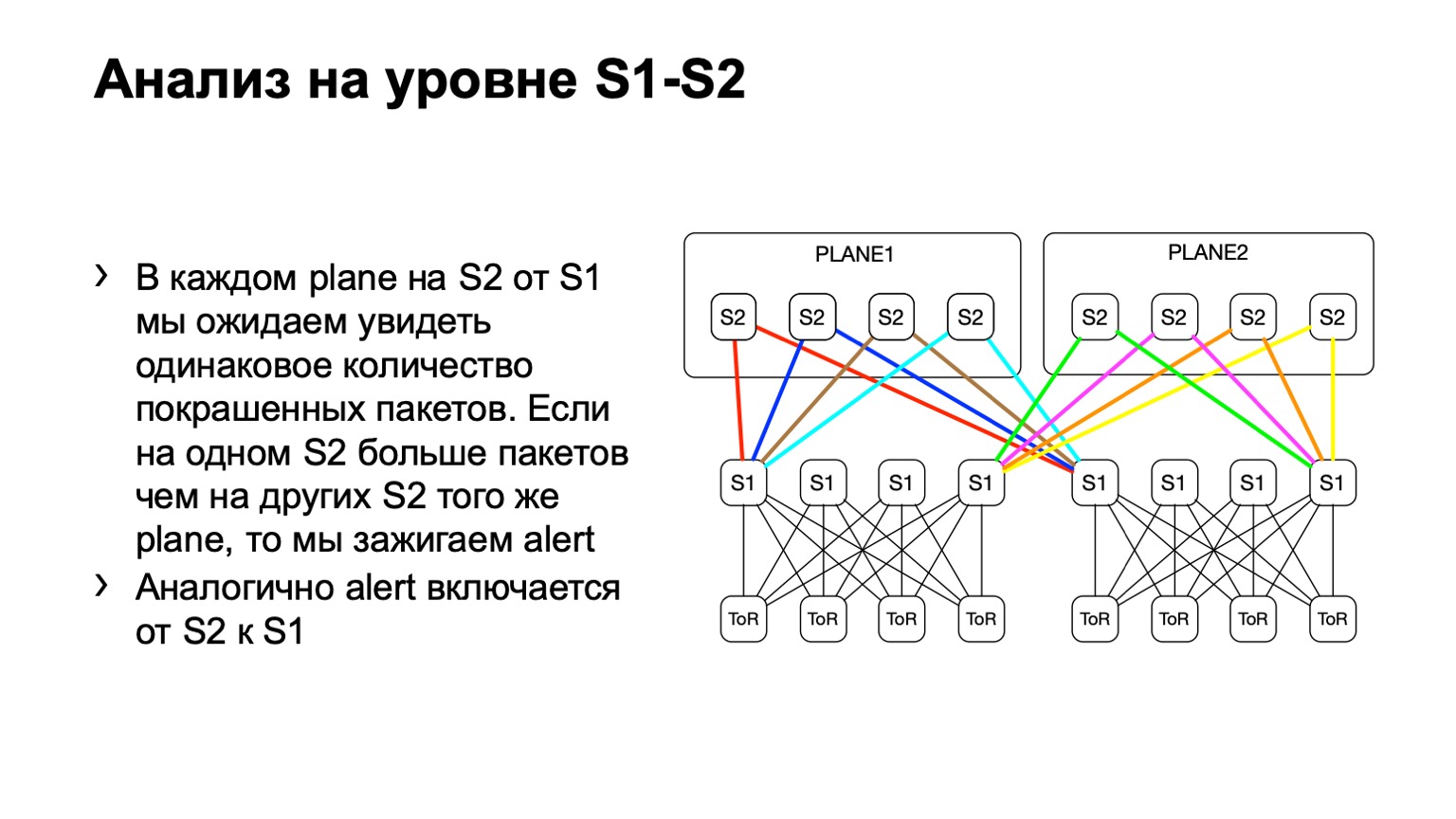
A seguir, veremos a distribuição desigual de tais pacotes no POD. Nele, por exemplo, quatro espinha, como na figura. Se o número de pacotes nos links amarelos, no azul, no verde e no vermelho for o mesmo, acreditamos que tudo está mais ou menos bom. Se, em algum momento, vemos um aumento, digamos, na coluna mais à direita do primeiro nível, entendemos que esse dispositivo atrai retransmissão, algo está errado com ele. Em seguida, tentamos desativá-lo ou pelo menos alugá-lo. Pelo menos quando encontrarmos problemas no Netmon, saberemos com qual dispositivo eles podem surgir.
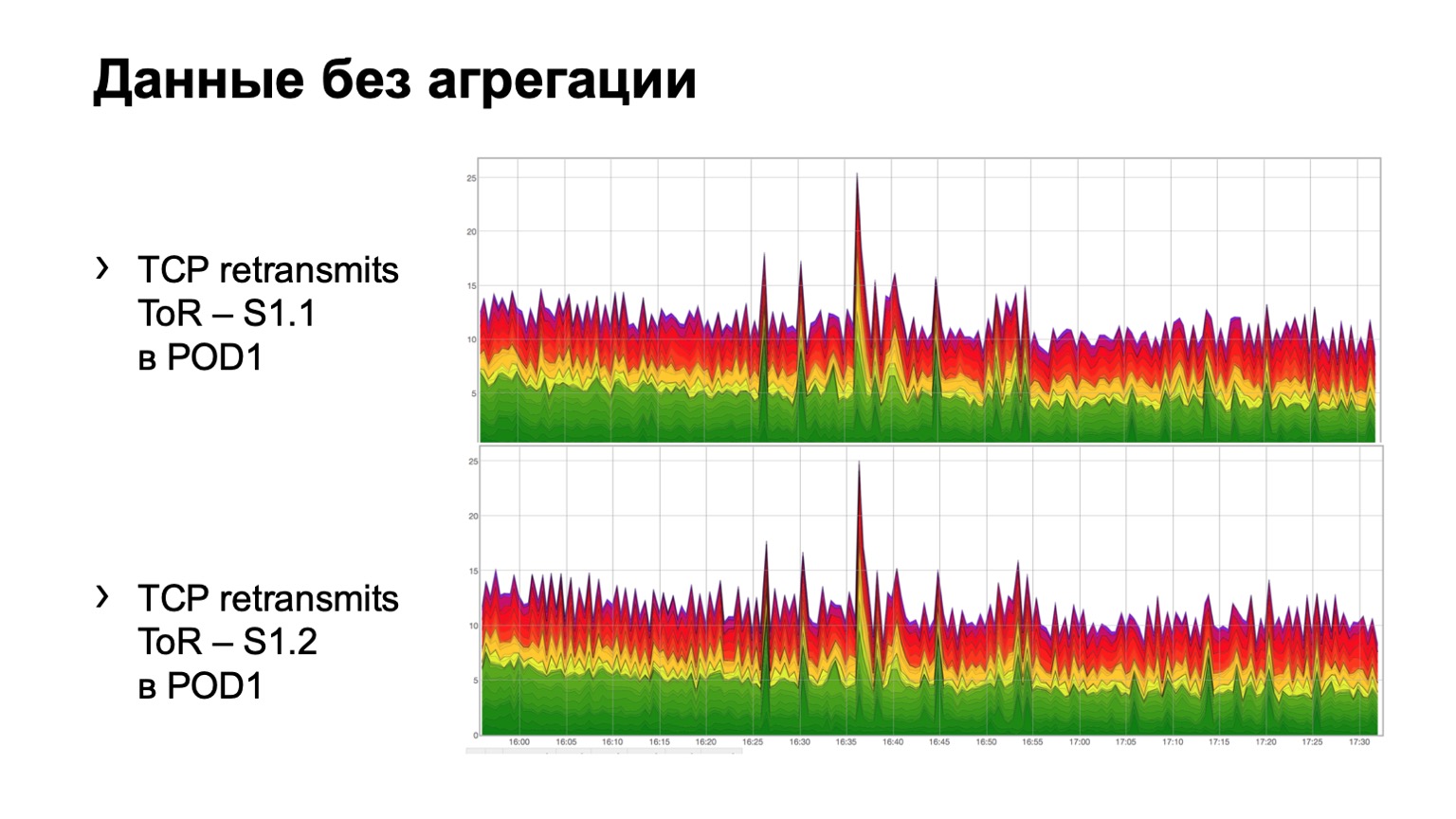
Como fica em dados brutos simples? Aqui estão dois gráficos. De fato, esses são gráficos de retransmissão com ToR para a coluna do primeiro nível. No exemplo, duas lombadas no módulo. O gráfico superior é a agregação da primeira coluna, o gráfico inferior é a segunda coluna. Observar isso neste formulário não é muito conveniente, por isso adicionamos agregação dessas informações.
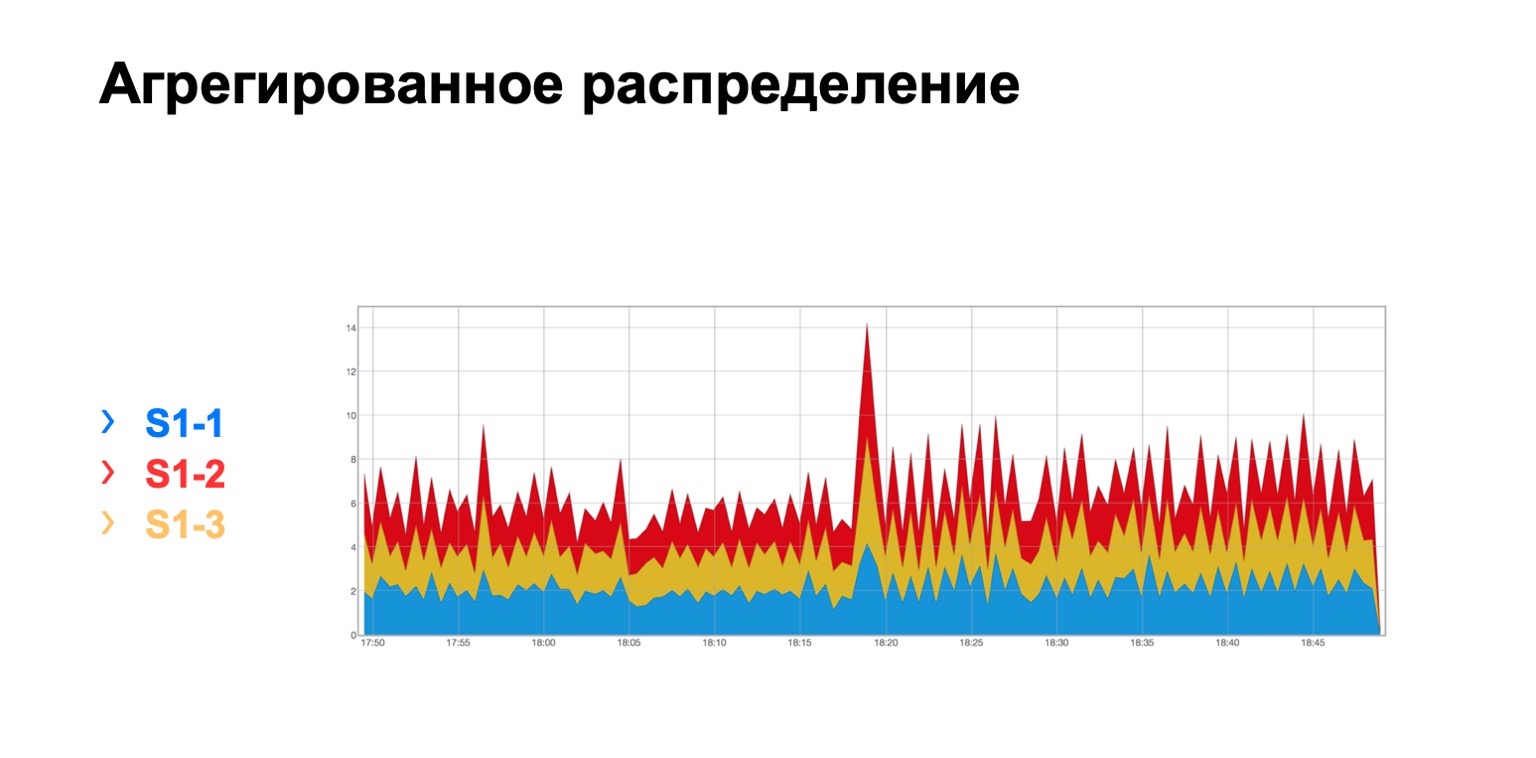
Parece assim. Existe um módulo no qual três espinhos, por alguma razão, não importa qual, e vemos aqui uma distribuição total de retransmissões para três espinhos. É, em princípio, bastante uniforme.
Para a coluna do segundo nível, podemos ter vários desvios, vamos chamá-los assim. A topologia ainda permanece regular, mas, dependendo do data center, podemos ou não usar uma arquitetura semelhante a uma placa. O ponto aqui é exatamente o mesmo. Em um nível, devemos ter aproximadamente a mesma distribuição de pacotes coloridos.
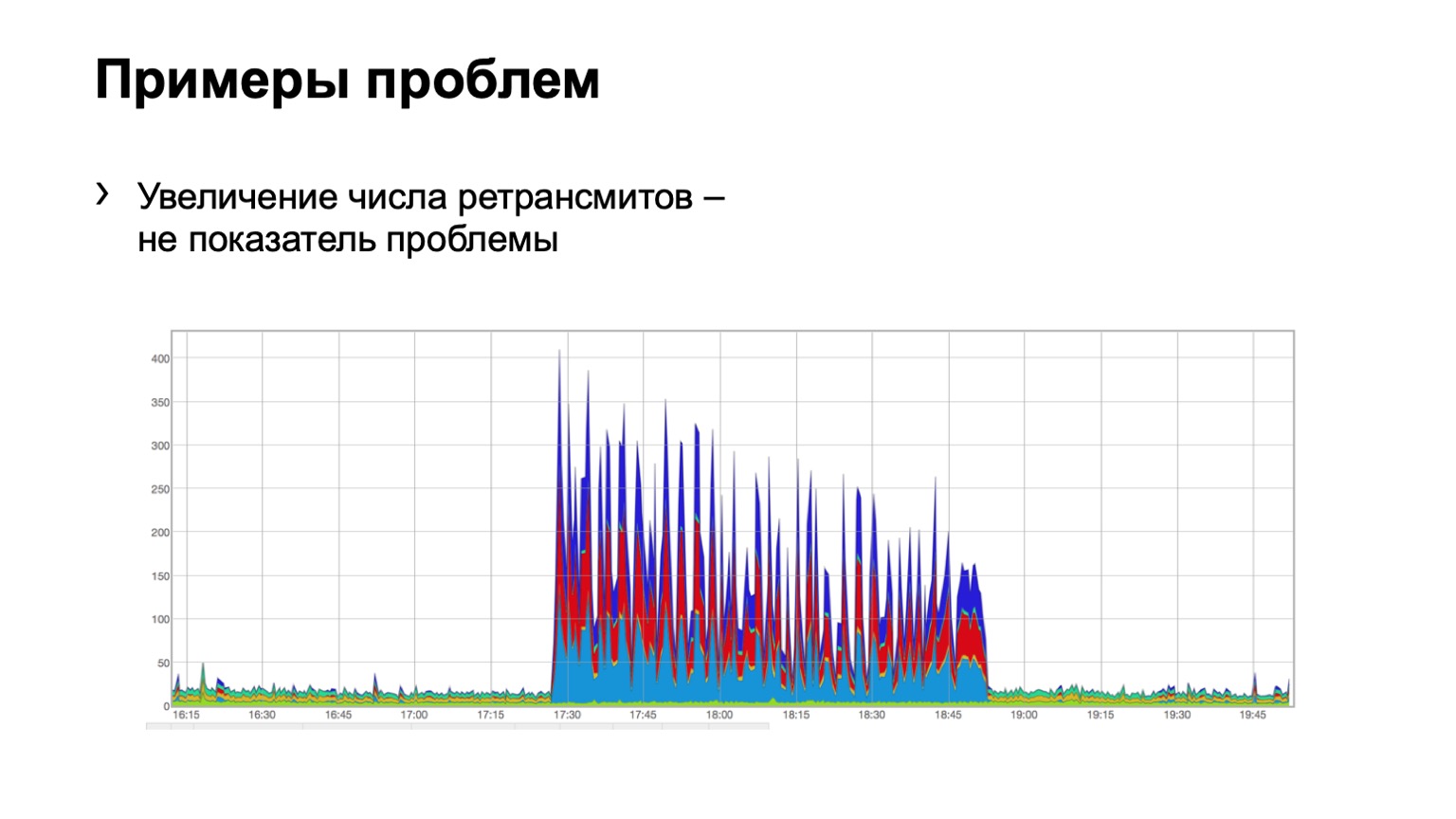
Vejamos alguns exemplos. Alguém vê um problema nesse gráfico? Há um problema aqui, mas não existe ao mesmo tempo. Sim, este é um problema de Schrödinger. Por que ela está lá e não? Como vemos um aumento no número de retransmissões, é diretamente óbvio que algo aconteceu por nós. Mas, ao mesmo tempo, vemos que esse crescimento é bastante uniforme. Ou seja, três azuis da coluna, vermelhos, azuis, distribuição uniforme sobre eles. O que isso significa? Que havia algum tipo de problema na rede, mas não está relacionado a esse nível de agregação de dados. Ela está em outro lugar.
Talvez alguém tenha fechado a porta em firewalls, desconectado algum cluster, ou seja, algo aconteceu. Mas não estamos interessados no que estava lá e por quê. Ou seja, nem sequer consideramos esse problema.
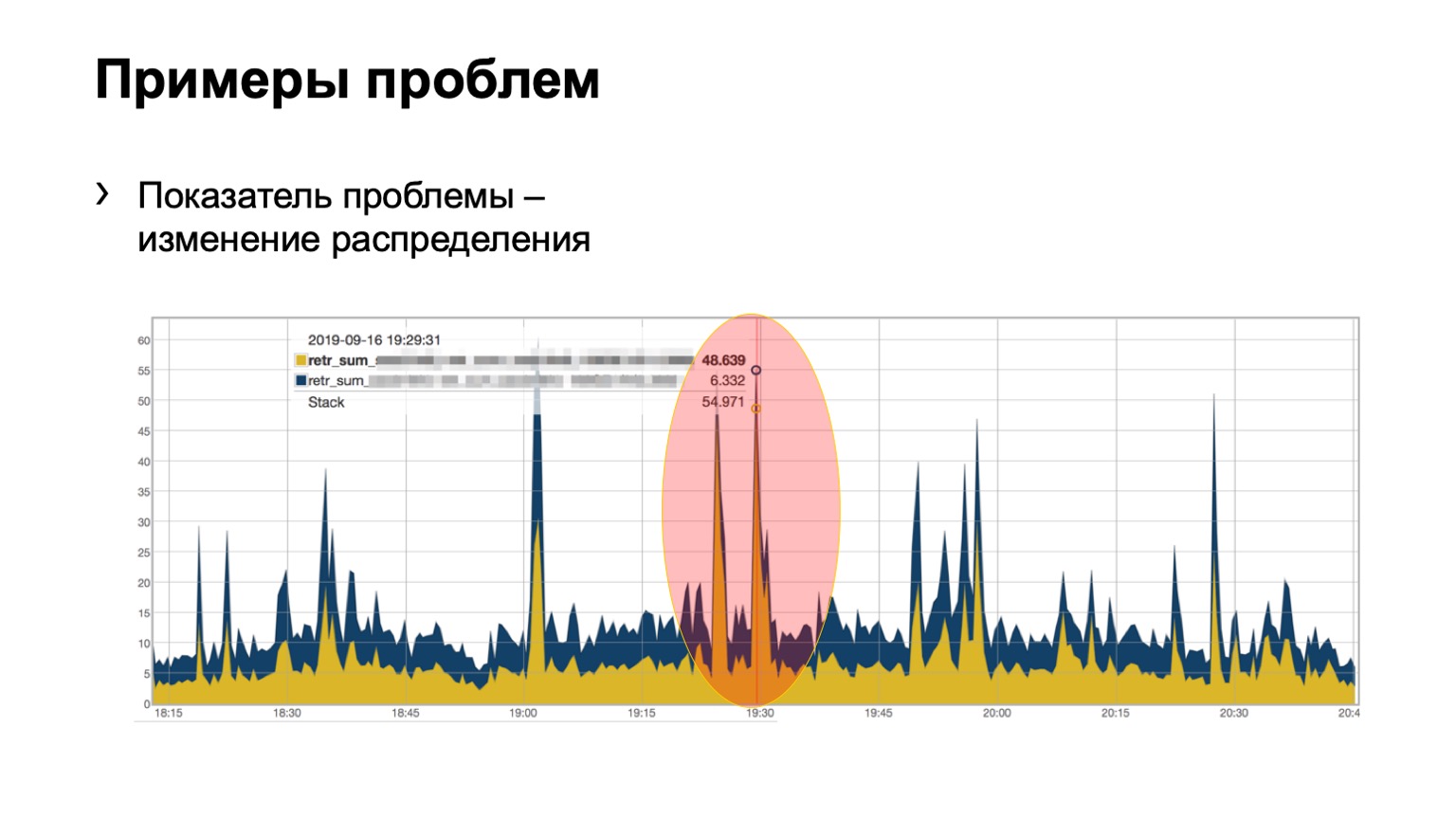
E aqui, talvez, não tão claramente, mas o problema é visível. Dois espinhos no módulo, 46 pacotes pintados voaram em um, e um pouco no segundo. Entendemos que temos um problema com algum tipo de coluna na rede, temos que fazer algo a respeito.
Por que eu falei pela primeira vez sobre o caminho da dor e do sofrimento? Porque existem muitos problemas com essa solução. O principal problema é, obviamente, o problema de qualquer monitoramento, isso é falso positivo. O falso positivo foi bastante. Principalmente devido ao fato de usarmos o DSCP e geralmente estarmos vinculados à QoS.

Descobrimos que os pacotes de outras pessoas voam na nossa pintura e nos alertam para o nosso monitoramento. Ou seja, achamos que isso é uma retransmissão, e alguém coloca seus pacotes lá e, em geral, estraga a imagem para nós. Naturalmente, começamos a entender, encontramos muitos lugares onde pensávamos que funcionava, mas na verdade não funciona da maneira que pensamos. Por exemplo, o tráfego que entra na rede aparentemente deve ser repintado, o tráfego com as classes CS6 e CS7 nos pensionistas não deve entrar na nossa rede. Mas em alguns lugares havia, digamos, falhas, e nós as tratamos com sucesso.
Alguns fabricantes apresentaram surpresas na forma de contadores na direção de saída de tais pacotes, e o chip funciona de tal maneira que, de fato, para processar a lista de acesso de saída, ele envolve o tráfego novamente, cortando metade da largura de banda do chip. . Era 900 gigabits por chip, tornou-se a metade.
E fizemos algumas melhorias devido ao fato de que as configurações no host podem ser diferentes. Ou seja, alguns hosts podem enviar retransmissões com mais freqüência, outros podem ser menos prováveis, outros dois, outros cinco e tudo isso alerta nosso monitoramento, tudo isso é falso positivo.
Primeiro, abandonamos a idéia de pintar cada retransmissão de TCP. Percebemos que, em princípio, não precisamos de todas as retransmissões para entender onde está o problema. Começamos a pintar apenas retransmitir SYN. O SYN é o primeiro pacote da sessão, é o suficiente para recebermos um sinal. Também pintamos SYN-ACL.
Mesmo assim, deu algum falso positivo. Fomos um pouco mais longe. Começamos a pintar apenas a primeira retransmissão TCP SYN na sessão. Ou seja, na verdade existem vários deles enviados, pintamos cada um - apenas um começou a ser pintado. Então chegamos ao que temos agora.
No total, existe o Netmon, existem agentes nos hosts que colorem a primeira retransmissão SYN na sessão e contamos essas retransmissões em todos os dispositivos, em quase todos os links da nossa rede.

Mas olhar com os olhos para a foto que eu costumava mostrar não é muito conveniente. Ou seja, você não pode vendê-lo a um oficial de serviço, porque em cada seção você deve avaliar tudo com seus olhos. E chegamos ao fato de que eu quero ter um alerta. Quero que acenda uma luz: um dispositivo como esse é um problema; outro dispositivo é um problema.
Vamos relembrar algumas estatísticas matemáticas. A idéia com alerta é que cada dispositivo seja essencialmente uma cesta. Temos uma probabilidade de sucesso e uma probabilidade de falha para quatro dispositivos. A probabilidade de retransmitir entrar na cesta, isto é sucesso, é ¼. Acontece uma distribuição binomial.
Qual é a dificuldade de fazer um alerta aqui? O fato de não podermos tornar estáticos os limites, não podemos dizer: se dez retransmissões chegam em um dispositivo e nove no outro, então não há problema. E se dez e cinco, então há um problema. Porque se o escalarmos para mil PPS, esses dados não serão mais relevantes. 1000 PPS e 800 PPS entre diferentes dispositivos é definitivamente um problema.
Não podemos definir limites estáticos em PPS ou bytes, não podemos defini-los como uma porcentagem - o mesmo problema com eles. Portanto, precisamos de uma solução que torne esse limite mais ou menos dinâmico, dependendo do número de pacotes.
E o charme da distribuição binomial é que, no aumento do PPS, ela tende a normal e, para uma distribuição normal, já podemos calcular a expectativa, a variação e o intervalo de confiança, o que fizemos. O intervalo de confiança para nós é 3NPQ, isto é, depende do número de pacotes através do dispositivo. Como resultado, temos um limiar de mudança dinâmica.
É assim que nosso sinal fica na imagem. Se algum dispositivo for eliminado da distribuição, levantamos uma bandeira - algo está errado com ele.

Onde queremos desenvolver mais, o que queremos melhorar aqui, além de, é claro, a luta contra o falso positivo? Antes de mais, estaríamos interessados em ver o que havia na época do problema? Para fazer isso, temos essa opção no agente - Debug. Podemos fazer upload de exatamente o que foi retransmitido, ou seja, um pacote de 5 tuplas, por exemplo, em um coletor separado e, em seguida, verificá-lo. Mas isso dá um pouco de carga aos hosts, então às vezes somos proibidos de fazê-lo. Queremos fixar o ERSPAN e descarregar esses pacotes no coletor do próprio hardware, porque ninguém nos proíbe de fazer isso no hardware.
Dima Afanasyev
contou como desenvolveremos nossas fábricas, e um dos pontos foi a transição da fábrica MPLS para o IPv6. O que isso nos dá? O MPLS possui três bits para marcação de QoS. No IPv6, pelo menos seis. Atualmente, apenas três bits são usados em nossa rede. Ou seja, ainda temos mais três bits nos quais podemos colocar, de fato, qualquer informação do host.
Por exemplo, agora estamos pintando apenas a primeira retransmissão de SYN na sessão. E podemos colorir o segundo bit, por exemplo, se o pacote for para uma rede externa. E podemos retransmitir, ou seja, destacar outro sinal, que consideraremos separadamente.
Além disso, a transição para o design com o pod de borda, quando o DCI é feito em algum lugar específico, nos ameaça com o fato de que nesse local podemos controlar com mais precisão nosso domínio diffserv. Ou seja, repintar e fazer algo com tintas para eliminar o falso positivo.
Como resultado, fazer tudo o que foi mencionado acima acabou sendo bastante doloroso, mas interessante. Não havia com o que se preocupar. De fato, desenvolvemos uma solução que todos podem usar. É testado em praticamente todos os fornecedores, funciona, não é difícil. E mostra realmente qual dispositivo na rede há um problema. Portanto, minha mensagem é - não tenha medo de fazer o mesmo e deixe seu monitoramento permanecer verde. Obrigado por ouvir.