O log é uma parte importante de qualquer aplicativo. Qualquer sistema de registro passa por três etapas evolutivas principais. O primeiro é enviado para o console, o segundo é o log para um arquivo e a aparência de uma estrutura para o log estruturado e o terceiro é o log distribuído ou a coleta de logs de vários serviços em um único centro.
Se o registro estiver bem organizado, ele permitirá que você entenda o que, quando e como isso dá errado e transmita as informações necessárias para as pessoas que precisam corrigir esses erros. Para um sistema no qual 100 mil mensagens são enviadas a cada segundo em 10 datacenters em 190 países, e 350 engenheiros implantam algo todos os dias, o sistema de registro é especialmente importante.
 Ivan Letenko
Ivan Letenko é líder de equipe e desenvolvedor da Infobip. Para resolver o problema de processamento centralizado e rastreamento de log na arquitetura de microsserviços sob cargas tão enormes, a empresa tentou várias combinações da pilha ELK, Graylog, Neo4j e MongoDB. Como resultado, depois de muito rake, eles escreveram seu serviço de log no Elasticsearch e o PostgreSQL foi usado como um banco de dados para obter informações adicionais.
Sob o comando do gato em detalhes, com exemplos e gráficos: arquitetura e evolução do sistema, varreduras, registro e rastreamento, métricas e monitoramento, a prática de trabalhar com clusters do Elasticsearch e administrá-los com recursos limitados.
Para apresentá-lo ao contexto, vou falar um pouco sobre a empresa. Ajudamos as organizações clientes a entregar mensagens a seus clientes: mensagens de um serviço de táxi, SMS de um banco sobre cancelamento ou uma senha única ao inserir o VC.
350 milhões de mensagens passam diariamente por nós para clientes em 190 países. Aceitamos, processamos, faturamos, encaminhamos, adaptamos, enviamos aos operadores e processamos relatórios de entrega na direção oposta e formulamos análises.
Para que tudo isso funcione em tais volumes, temos:
- 36 data centers em todo o mundo;
- Mais de 5000 máquinas virtuais
- Mais de 350 engenheiros;
- 730+ microsserviços diferentes.
Este é um sistema complexo, e nem um único guru consegue entender sozinho a escala completa. Um dos principais objetivos de nossa empresa é a alta velocidade de entrega de novos recursos e lançamentos para os negócios. Nesse caso, tudo deve funcionar e não cair. Estamos trabalhando nisso: 40.000 implantações em 2017, 80.000 em 2018, 300 implantações por dia.
Temos 350 engenheiros -
todos os engenheiros implantam algo diariamente . Apenas alguns anos atrás, apenas uma pessoa em uma empresa tinha essa produtividade - Kreshimir, nosso engenheiro principal. Mas garantimos que todo engenheiro se sinta tão confiante quanto Kresimir ao pressionar o botão Deploy ou executar um script.
O que é necessário para isso? Primeiro de tudo, a
confiança de que entendemos o que está acontecendo no sistema e em que estado ele está. A confiança é dada pela capacidade de fazer uma pergunta ao sistema e descobrir a causa do problema durante o incidente e durante o desenvolvimento do código.
Para alcançar essa confiança, investimos em
observabilidade . Tradicionalmente, esse termo combina três componentes:
- registro;
- métricas
- rastreamento.
Nós vamos falar sobre isso. Primeiro de tudo, vamos olhar para a nossa solução de log, mas também abordaremos métricas e rastreamentos.
Evolução
Quase qualquer aplicativo ou sistema de registro, incluindo o nosso, passa por vários estágios de evolução.
O primeiro passo é
enviar para o console .
Segundo - começamos
a gravar logs em um arquivo , aparece uma
estrutura para saída estruturada em um arquivo. Geralmente usamos o Logback porque vivemos na JVM. Nesse estágio, o log estruturado em um arquivo é exibido, entendendo que logs diferentes devem ter níveis, avisos e erros diferentes.
Assim
que houver várias instâncias de nosso serviço ou serviços diferentes, a tarefa de
acesso centralizado aos logs para desenvolvedores e suporte será exibida. Passamos para o log distribuído - combinamos vários serviços em um único serviço de log.
Log distribuído
A opção mais famosa é a pilha ELK: Elasticsearch, Logstash e Kibana, mas escolhemos o
Graylog . Ele possui uma interface interessante, voltada para o log. Os alarmes já saem da caixa na versão gratuita, que não está no Kibana, por exemplo. Para nós, essa é uma excelente escolha em termos de logs e, sob o capô, é a mesma Elasticsearch.
 No Graylog, você pode criar alertas, gráficos como o Kibana e até métricas de log.
No Graylog, você pode criar alertas, gráficos como o Kibana e até métricas de log.Os problemas
Nossa empresa estava crescendo e, em algum momento, ficou claro que havia algo errado com o Graylog.
Carga excessiva . Houve problemas de desempenho. Muitos desenvolvedores começaram a usar os recursos interessantes do Graylog: eles criaram métricas e painéis que executam agregação de dados. Não é a melhor opção para criar análises complexas no cluster Elasticsearch, que está sob muita carga de gravação.
Colisões Existem muitas equipes, não existe um esquema único. Tradicionalmente, quando um ID atingia o Graylog pela primeira vez por muito tempo, o mapeamento ocorria automaticamente. Se outra equipe decidir que deve ser escrito o UUID como uma string - isso interromperá o sistema.
Primeira decisão
Logs de aplicativos e logs de comunicação separados . Logs diferentes têm diferentes cenários e métodos de aplicação. Há, por exemplo, logs de aplicativos para os quais equipes diferentes têm requisitos diferentes para parâmetros diferentes: pelo tempo de armazenamento no sistema, pela velocidade da pesquisa.
Portanto, a primeira coisa que fizemos foi separar os logs de aplicativos e de comunicação. O segundo tipo são logs importantes que armazenam informações sobre a interação de nossa plataforma com o mundo exterior e sobre a interação dentro da plataforma. Falaremos mais sobre isso.
Substituiu uma parte substancial dos logs por métricas . Em nossa empresa, a escolha padrão é Prometheus e Grafana. Algumas equipes usam outras soluções. Mas é importante que nos livramos de um grande número de painéis com agregações dentro do Graylog, transferimos tudo para Prometheus e Grafana. Isso facilitou bastante a carga nos servidores.
Vejamos os cenários para aplicação de logs, métricas e rastreios.
Logs
Alta dimensionalidade, depuração e pesquisa . O que são bons logs?
Logs são os eventos que registramos.
Eles podem ter uma dimensão grande: é possível registrar ID da solicitação, ID do usuário, atributos da solicitação e outros dados, cuja dimensão não é limitada. Eles também são bons para depuração e pesquisa, para fazer perguntas ao sistema sobre o que aconteceu e procurar causas e efeitos.
Métricas
Baixa dimensionalidade, agregação, monitoramento e alertas . Sob o capô de todos os sistemas de coleta de métricas estão os bancos de dados de séries temporais. Esses bancos de dados fazem um excelente trabalho de agregação; portanto, as métricas são adequadas para agregação, monitoramento e criação de alertas.
As métricas são muito sensíveis à dimensão dos dados.
Para métricas, a dimensão dos dados não deve exceder mil. Se adicionarmos alguns IDs de solicitação, nos quais o tamanho dos valores não é limitado, encontraremos rapidamente problemas sérios. Já pisamos neste rake.
Correlação e Rastreio
Os logs devem ser correlacionados.
Logs estruturados não são suficientes para procurarmos convenientemente por dados. Deve haver campos com certos valores: ID da solicitação, ID do usuário e outros dados dos serviços dos quais os logs vieram.
A solução tradicional é atribuir um ID exclusivo à transação (log) na entrada do sistema. Em seguida, esse ID (contexto) é encaminhado por todo o sistema através de uma cadeia de chamadas em um serviço ou entre serviços.
 Correlação e rastreamento.
Correlação e rastreamento.Existem termos bem estabelecidos. O rastreamento é dividido em extensões e demonstra a pilha de chamadas de um serviço em relação a outro, um método em relação a outro em relação à linha do tempo. Você pode rastrear claramente o caminho da mensagem, todos os horários.
Primeiro usamos o Zipkin. Já em 2015, tínhamos uma Prova de Conceito (projeto piloto) dessas soluções.
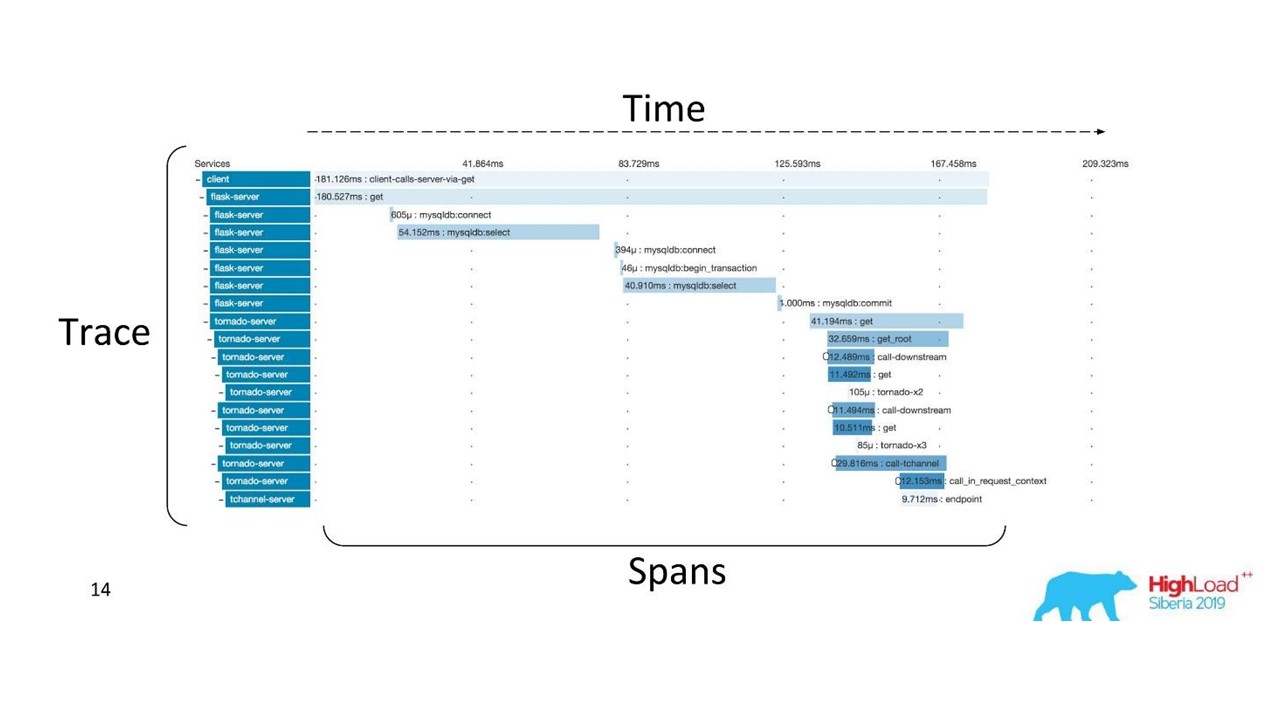 Rastreio distribuído
Rastreio distribuídoPara obter uma imagem, o
código precisa ser instrumentado . Se você já estiver trabalhando com uma base de código existente, precisará passar por ela - ela requer alterações.
Para obter uma visão completa e se beneficiar dos rastreamentos, você precisa
instrumentar todos os serviços da cadeia , e não apenas um serviço no qual você está trabalhando atualmente.
Esta é uma ferramenta poderosa, mas requer custos administrativos e de hardware significativos, portanto, mudamos do Zipkin para outra solução, fornecida por "como serviço".
Relatórios de entrega
Os logs devem ser correlacionados. Os traços também devem ser correlacionados. Precisamos de um único ID - um contexto comum que possa ser encaminhado por toda a cadeia de chamadas. Mas muitas vezes isso não é possível - a
correlação ocorre dentro do sistema como resultado de sua operação . Quando iniciamos uma ou mais transações, ainda não sabemos que elas fazem parte de um único todo grande.
Considere o primeiro exemplo.
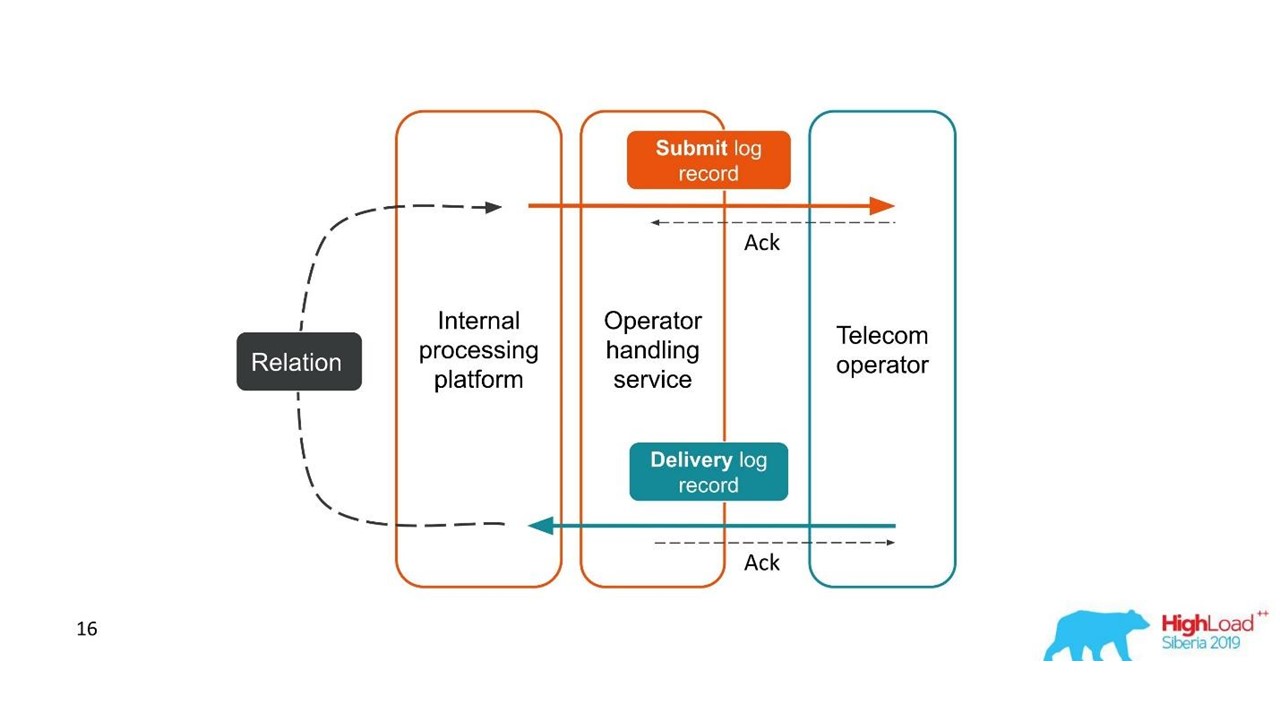 Relatórios de entrega.
Relatórios de entrega.- O cliente enviou uma solicitação para uma mensagem e nossa plataforma interna a processou.
- O serviço, que está envolvido em interação com o operador, enviou esta mensagem ao operador - uma entrada apareceu no sistema de log.
- Posteriormente, o operador nos envia um relatório de entrega.
- O serviço de processamento não sabe a qual mensagem este relatório de entrega está relacionado. Esse relacionamento é criado posteriormente em nossa plataforma.
Duas transações relacionadas são partes de uma única transação inteira. Essas informações são muito importantes para engenheiros de suporte e desenvolvedores de integração. Mas isso é completamente impossível de ver com base em um único rastreamento ou um único ID.
O segundo caso é semelhante - o cliente nos envia uma mensagem em um pacote grande e, em seguida, desmontamos, eles também retornam em lotes. O número de pacotes pode até variar, mas todos eles são combinados.
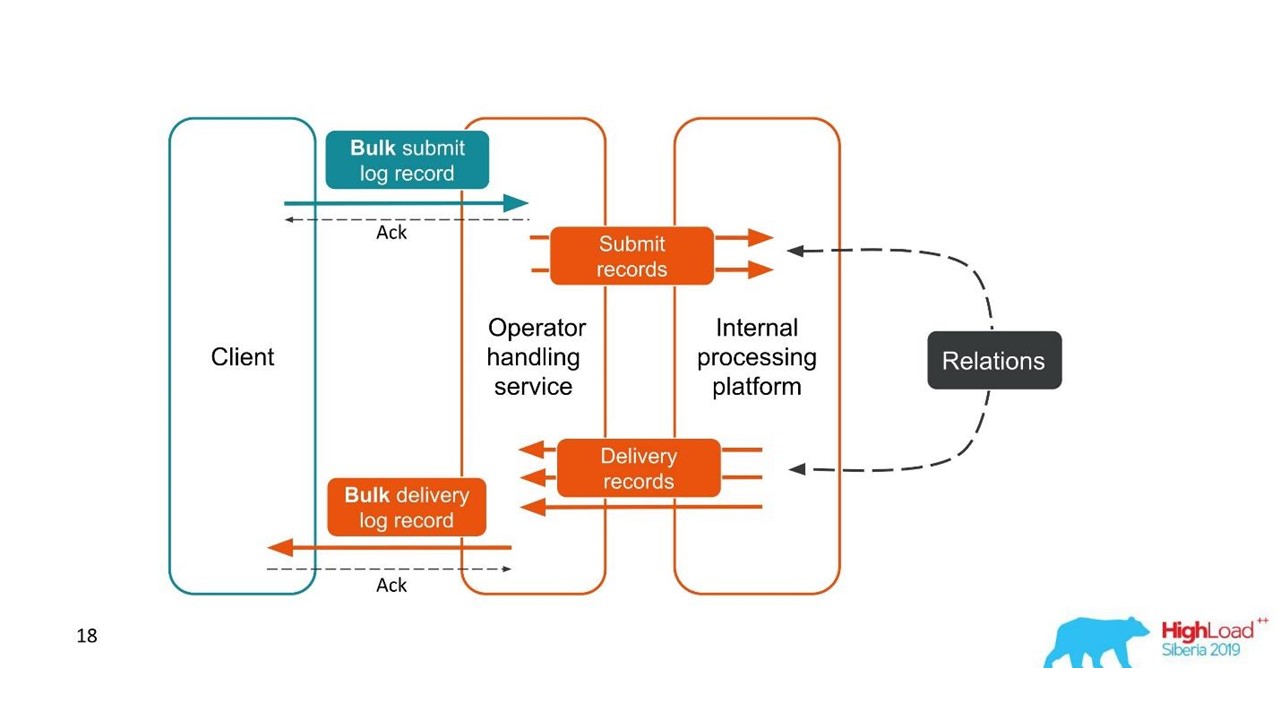
Do ponto de vista do cliente, ele enviou uma mensagem e recebeu uma resposta. Mas temos várias transações independentes que precisam ser combinadas. Acontece um relacionamento um para muitos e com um relatório de entrega - um para um. Este é essencialmente um gráfico.
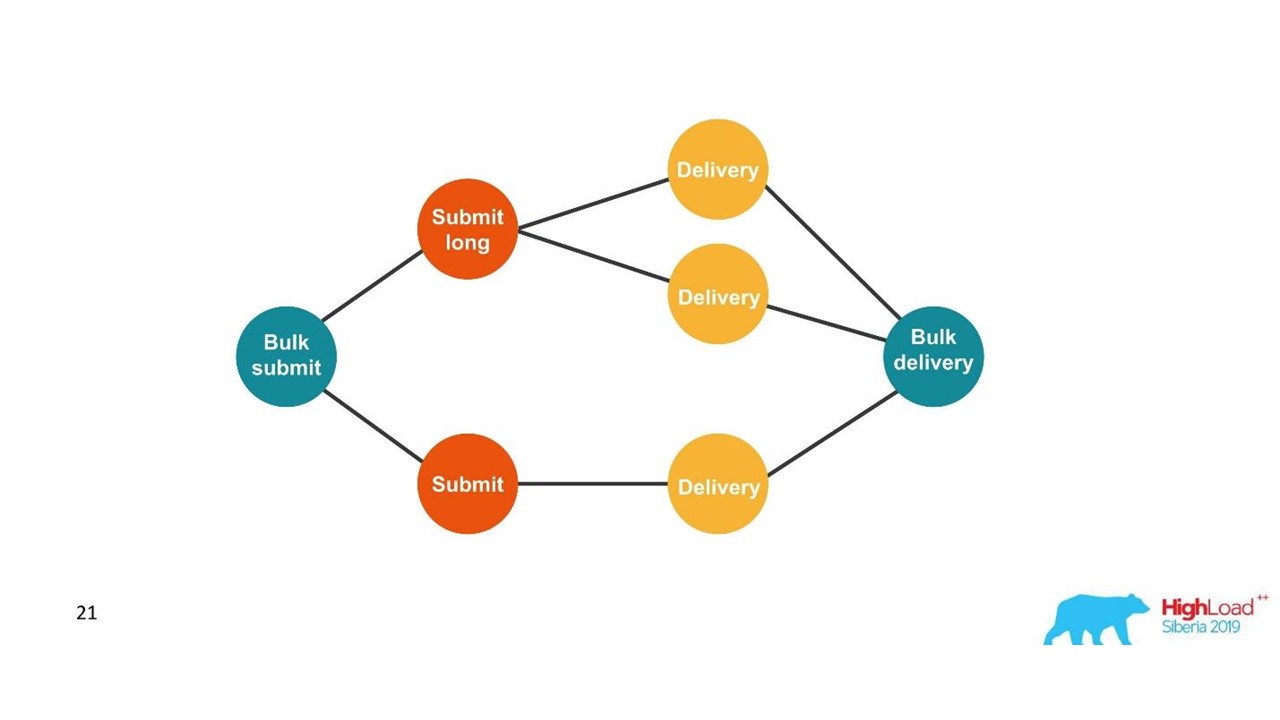 Estamos construindo um gráfico.
Estamos construindo um gráfico.Quando vemos um gráfico, uma escolha adequada são os bancos de dados gráficos, por exemplo, o Neo4j. A escolha foi óbvia, porque o Neo4j oferece camisetas legais e livros gratuitos em conferências.
Neo4j
Implementamos a Prova de conceito: um host de 16 núcleos que pode processar um gráfico de 100 milhões de nós e 150 milhões de links. O gráfico ocupava apenas 15 GB de disco - então nos convinha.
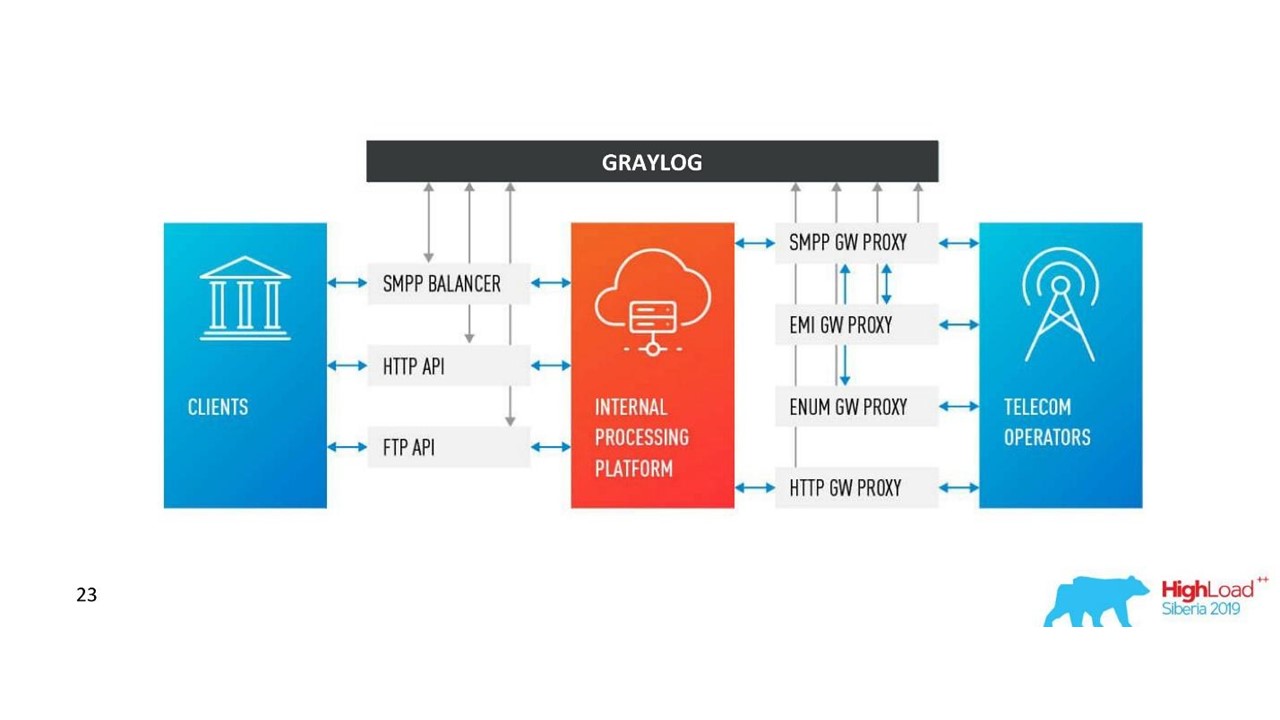 Nossa decisão. Arquitetura de log.
Nossa decisão. Arquitetura de log.Além do Neo4j, agora temos uma interface simples para visualizar logs relacionados. Com ele, os engenheiros veem o quadro todo.
Mas, rapidamente, ficamos decepcionados com esse banco de dados.
Problemas com o Neo4j
Rotação de dados . Temos volumes poderosos e os dados devem ser rotacionados. Mas quando um nó é excluído do Neo4j, os dados no disco não são limpos. Eu tive que criar uma solução complexa e reconstruir completamente os gráficos.
Performance . Todos os bancos de dados de gráficos são somente leitura. Na gravação, o desempenho é notavelmente menor. Nosso caso é absolutamente o oposto: escrevemos muito e lemos relativamente raramente - são unidades de solicitações por segundo ou mesmo por minuto.
Alta disponibilidade e análise de cluster por uma taxa . Em nossa escala, isso se traduz em custos decentes.
Portanto, seguimos o outro caminho.
Solução com PostgreSQL
Decidimos que, uma vez que raramente lemos, o gráfico pode ser construído instantaneamente durante a leitura. Portanto, no banco de dados relacional do PostgreSQL, armazenamos a lista de adjacências de nossos IDs na forma de uma placa simples com duas colunas e um índice em ambas. Quando a solicitação chega, ignoramos o gráfico de conectividade usando o algoritmo DFS familiar (profundidade da travessia) e obtemos todos os IDs associados. Mas isso é necessário.
A rotação de dados também é fácil de resolver. Para cada dia, iniciamos uma nova placa e, após alguns dias, chega a hora, excluímos e liberamos os dados. Uma solução simples.
Agora temos 850 milhões de conexões no PostgreSQL, elas ocupam 100 GB de disco. Escrevemos lá a uma velocidade de 30 mil por segundo e, para isso, no banco de dados, existem apenas duas VMs com 2 CPUs e 6 GB de RAM. Conforme necessário, o PostgreSQL pode escrever rapidamente rapidamente.
Ainda existem pequenas máquinas para o serviço em si, que giram e controlam.
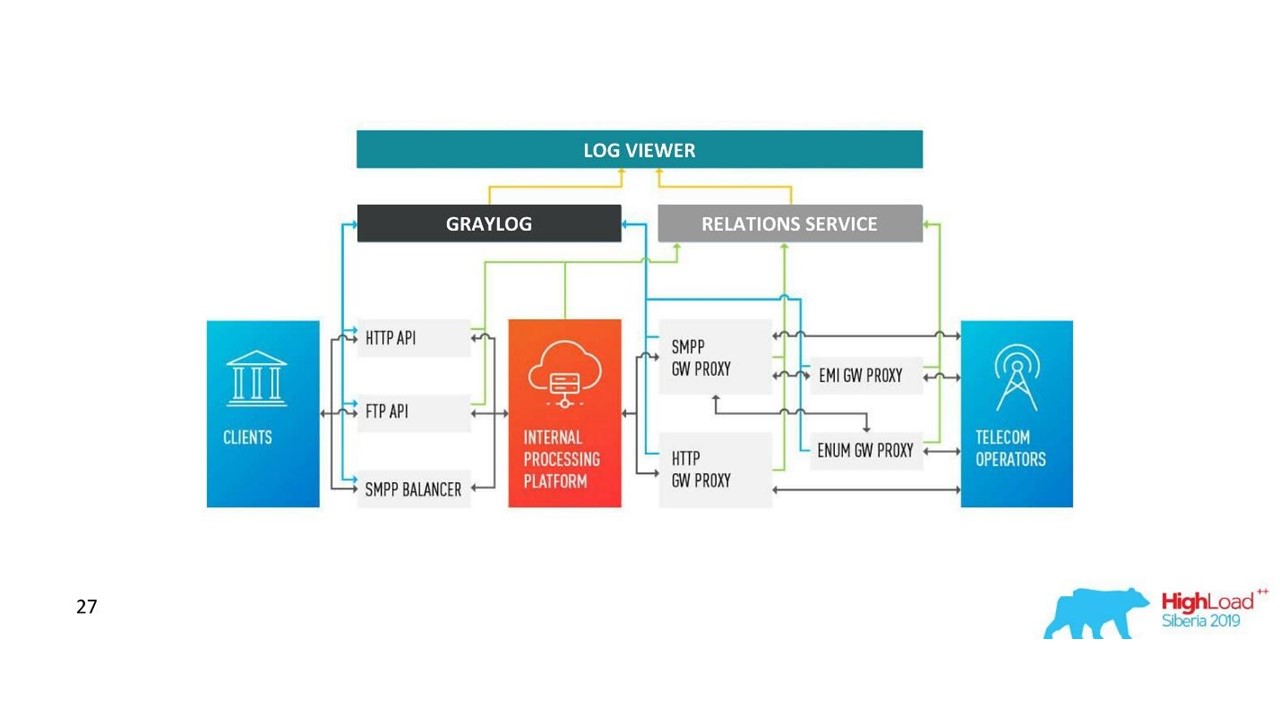 Como nossa arquitetura mudou.
Como nossa arquitetura mudou.Desafios com o Graylog
A empresa cresceu, novos data centers apareceram, a carga aumentou notavelmente, mesmo com uma solução com logs de comunicação. Nós pensamos que o Graylog não é mais perfeito.
Esquema unificado e centralização . Eu gostaria de ter uma única ferramenta de gerenciamento de cluster em 10 data centers. Além disso, surgiu a questão de um esquema de mapeamento de dados unificado para que não houvesse colisões.
API Usamos nossa própria interface para exibir as conexões entre os logs e a API Graylog padrão nem sempre era conveniente, por exemplo, quando você precisa exibir dados de diferentes datacenters, classificá-los e marcá-los corretamente. Portanto, queríamos poder alterar a API como quiséssemos.
Desempenho, é difícil avaliar a perda . Nosso tráfego é de 3 TB de logs por dia, o que é decente. Portanto, o Graylog nem sempre funcionava de maneira estável, era necessário entrar em seu interior para entender as causas das falhas. Acabou que não estávamos mais usando-o como uma ferramenta - tivemos que fazer algo a respeito.
Atrasos no processamento (filas) . Não gostamos da implementação padrão da fila no Graylog.
A necessidade de suportar o MongoDB . Graylog arrasta o MongoDB, era necessário administrar esse sistema também.
Percebemos que, nesta fase, queremos nossa própria solução. Talvez haja menos recursos interessantes de alerta que não tenham sido usados para painéis, mas os deles são melhores.
Nossa decisão
Desenvolvemos nosso próprio serviço de logs.
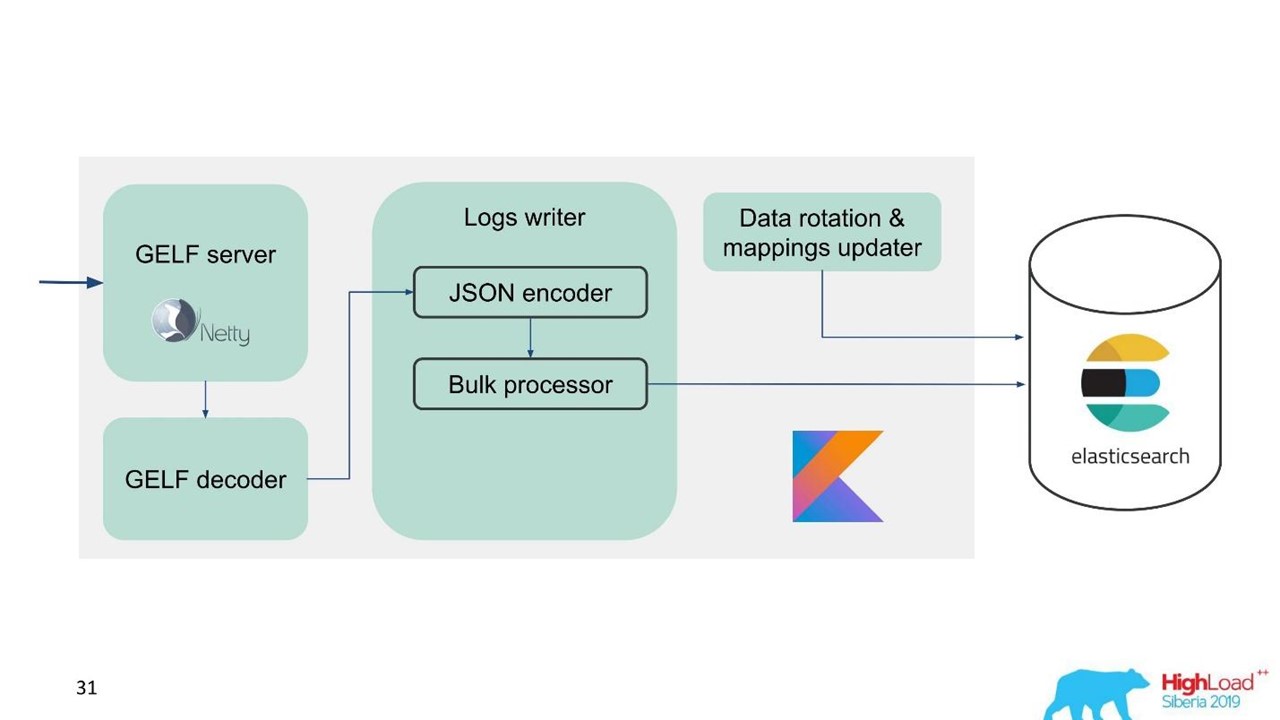
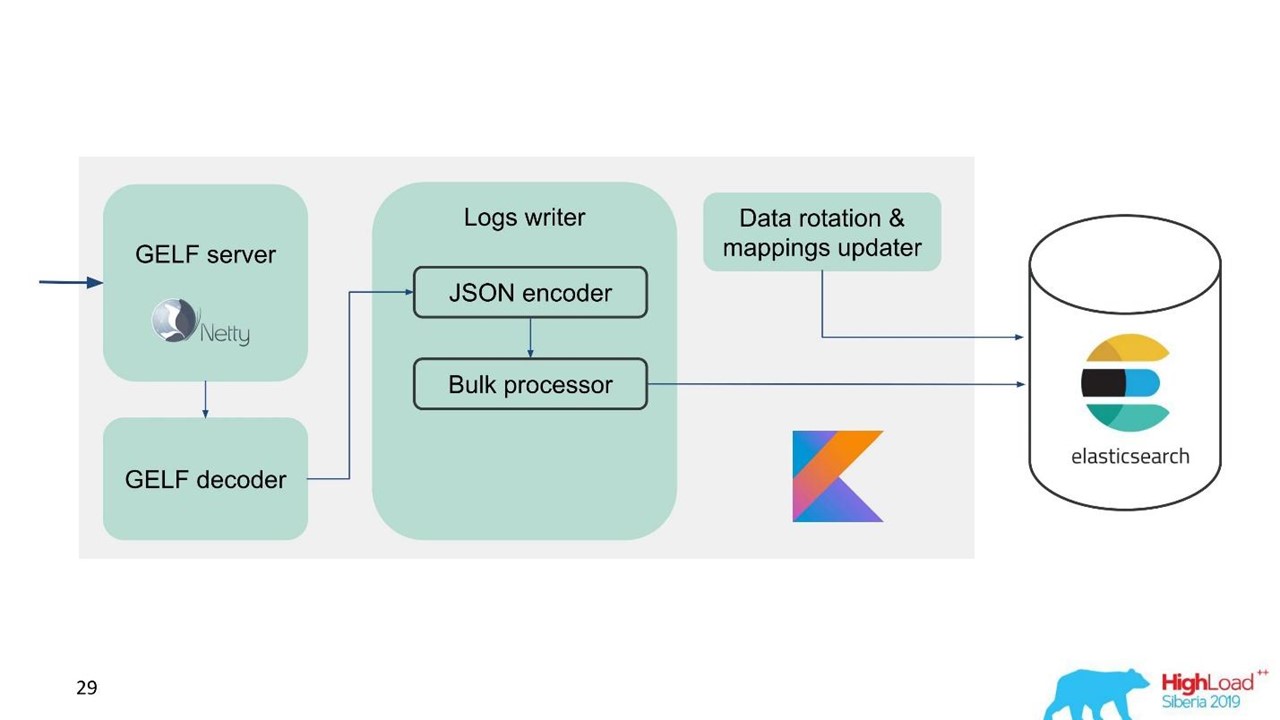 Serviço de log.
Serviço de log.Naquele momento, já tínhamos experiência em serviços e manutenção de grandes clusters do Elasticsearch, por isso tomamos o Elasticsearch como base. A pilha padrão na empresa é a JVM, mas, para o back-end, também usamos o Kotlin de maneira famosa, por isso adotamos esse idioma para o serviço.
A primeira pergunta é como rotacionar dados e o que fazer com o mapeamento. Usamos mapeamento fixo. No Elasticsearch, é melhor ter índices do mesmo tamanho. Mas com esses índices, precisamos mapear de alguma forma os dados, especialmente para vários datacenters, um sistema distribuído e um estado distribuído. Havia idéias para fixar o ZooKeeper, mas isso é novamente uma complicação da manutenção e do código.
Portanto, decidimos simplesmente - escrever a tempo.
Um índice por uma hora, em outros datacenters, 2 índices por uma hora, no terceiro, por 3 horas, mas em tempo integral. Os índices são obtidos em tamanhos diferentes, porque à noite o tráfego é menor do que durante o dia, mas geralmente funciona. A experiência mostrou que não são necessárias complicações.
Para facilitar a migração e, devido à grande quantidade de dados, escolhemos o protocolo GELF, um simples protocolo Graylog baseado em TCP. Então, nós temos um servidor GELF para Netty e um decodificador GELF.
Em seguida, o JSON é codificado para gravação no Elasticsearch. Usamos a API Java oficial da Elasticsearch e escrevemos em massa.
Para alta velocidade de gravação, você precisa escrever Bulk'ami.
Esta é uma otimização importante. A API fornece um processador em massa que acumula solicitações automaticamente e as envia para gravação em um pacote configurável ou ao longo do tempo.
Problema com o Processador em Massa
Tudo parece estar bem. Mas começamos e percebemos que descansávamos no processador em massa - era inesperado. Não podemos alcançar os valores em que estávamos contando - o problema veio do nada.
Na implementação padrão, o processador em massa é de thread único, síncrono, apesar de haver uma configuração de paralelismo. Esse foi o problema.
Reviramos e descobrimos que esse é um bug conhecido, mas não resolvido. Mudamos um pouco o processador em massa - fizemos um bloqueio explícito através do ReentrantLock. Somente em maio, alterações semelhantes foram feitas no repositório oficial do Elasticsearch e estarão disponíveis apenas na versão 7.3. O atual é 7.1, e estamos usando a versão 6.3.
Se você também trabalha com um processador em massa e deseja fazer um overclock de uma entrada no Elasticsearch - observe essas
alterações no GitHub e volte para a sua versão. As alterações afetam apenas o processador em massa. Não haverá dificuldades se você precisar portar para a versão abaixo.
Está tudo bem, o processador em massa se foi, a velocidade acelerou.
O desempenho de gravação do Elasticsearch é instável ao longo do tempo, pois várias operações ocorrem lá: fusão de índice, liberação. Além disso, o desempenho diminui por um tempo durante a manutenção, quando parte dos nós é removida do cluster, por exemplo.
Nesse sentido, percebemos que precisamos implementar não apenas o buffer na memória, mas também a fila. Decidimos que apenas enviaríamos mensagens rejeitadas para a fila - somente aquelas que o processador em massa não pôde gravar no Elasticsearch.
Repetir fallback
Esta é uma implementação simples.
- Nós salvamos as mensagens rejeitadas no arquivo -
RejectedExecutionHandler .
- Submeta novamente no intervalo especificado em um executor separado.
- No entanto, não atrasamos o tráfego novo.
Para engenheiros e desenvolvedores de suporte, o novo tráfego no sistema é notavelmente mais importante do que aquele que, por algum motivo, foi atrasado durante o pico ou desaceleração do Elasticsearch. Ele permaneceu, mas viria mais tarde - não é grande coisa. Novo tráfego é priorizado.
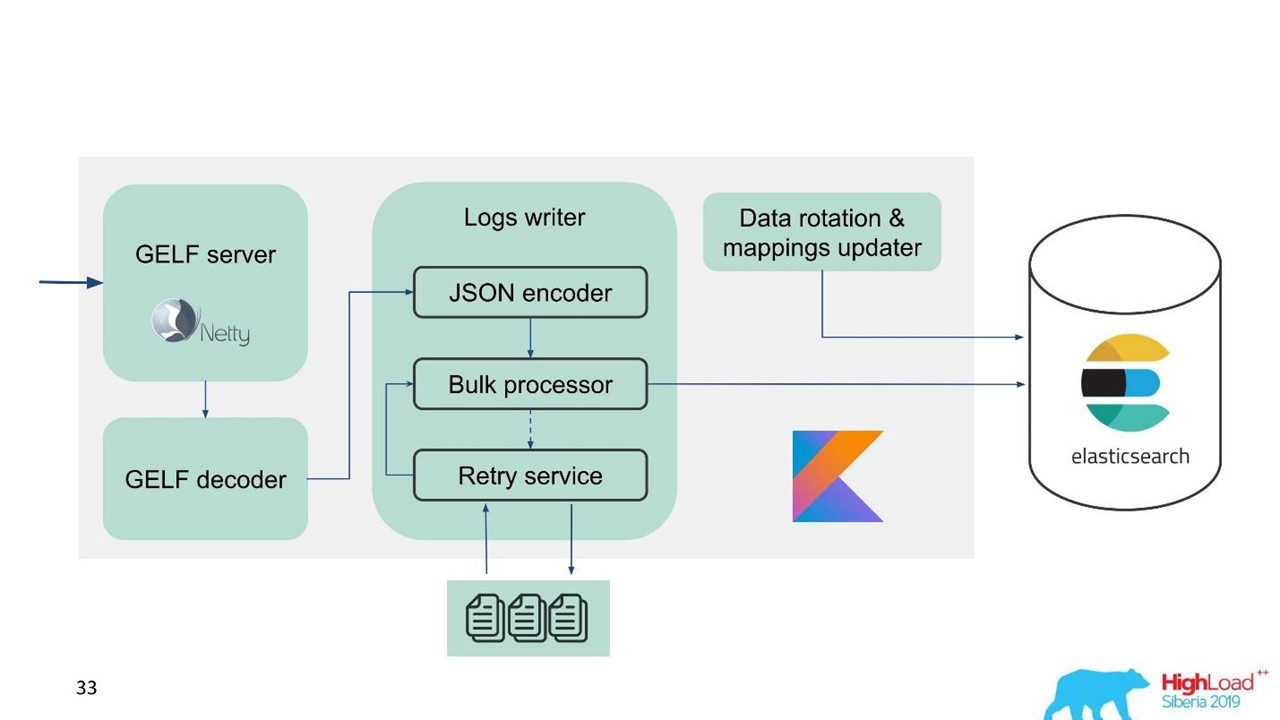 Nosso esquema começou a ficar assim.
Nosso esquema começou a ficar assim.Agora vamos falar sobre como preparamos o Elasticsearch, quais parâmetros usamos e como configuramos.
Configuração do Elasticsearch
O problema que enfrentamos é a necessidade de fazer um overclock do Elasticsearch e otimizá-lo para escrever, pois o número de leituras é visivelmente menor.
Nós usamos vários parâmetros.
"ignore_malformed": true -
descarte campos com o tipo errado e não o documento inteiro . Ainda queremos armazenar os dados, mesmo que por algum motivo os campos com mapeamento incorreto tenham vazado lá. Esta opção não está totalmente relacionada ao desempenho.
Para o ferro, a Elasticsearch tem uma nuance. Quando começamos a solicitar clusters grandes, fomos informados de que as matrizes RAID das unidades SSD para seus volumes são terrivelmente caras. Porém, matrizes não são necessárias porque a tolerância a falhas e o particionamento já estão integrados no Elasticsearch. Mesmo no site oficial, há uma recomendação para levar mais ferro barato do que menos caro e bom. Isso se aplica aos discos e ao número de núcleos do processador, porque todo o Elasticsearch se compara muito bem.
"index.merge.scheduler.max_thread_count": 1 -
recomendado para HDD .
Se você não obteve SSDs, mas HDDs comuns, defina esse parâmetro como um. Os índices são escritos em pedaços, depois esses pedaços são congelados. Isso economiza um pouco de disco, mas, acima de tudo, acelera a pesquisa. Além disso, quando você para de gravar no índice, pode
force merge . Quando a carga no cluster é menor, ela congela automaticamente.
"index.unassigned.node_left.delayed_timeout": "5m" -
atraso na implantação quando um nó desaparece . É o tempo após o qual o Elasticsearch começará a implementar índices e dados se um nó for reinicializado, implantado ou retirado para manutenção. Mas se você tiver uma carga pesada no disco e na rede, a implantação será uma operação difícil. Para não sobrecarregá-los, esse tempo limite é melhor para controlar e entender quais atrasos são necessários.
"index.refresh_interval": -1 -
não atualize índices se não houver consultas de pesquisa . Em seguida, o índice será atualizado quando uma consulta de pesquisa aparecer. Este índice pode ser definido em segundos e minutos.
"index.translogDurability": "async" - com que freqüência executar fsync: com cada solicitação ou por tempo. Dá ganhos de desempenho para discos lentos.
Também temos uma maneira interessante de usá-lo. O suporte e os desenvolvedores desejam poder pesquisar em texto completo e usar regexp'ov em todo o corpo da mensagem. Mas no Elasticsearch isso não é possível - ele pode pesquisar apenas por tokens que já existem em seu sistema. RegExp e curinga podem ser usados, mas o token não pode começar com alguns RegExp. Portanto, adicionamos
word_delimiter ao filtro:
"tokenizer": "standard" "filter" : [ "word_delimiter" ]
Ele divide automaticamente as palavras em tokens:
- “Wi-Fi” → “Wi”, “Fi”;
- “PowerShot” → “Power”, “Shot”;
- “SD500” → “SD”, “500”.
De maneira semelhante, o nome da classe é escrito, várias informações de depuração. Com isso, resolvemos alguns dos problemas com a pesquisa de texto completo. Aconselho que você adicione essas configurações ao trabalhar com o login.
Sobre o cluster
O número de shards deve ser igual ao número de nós de dados para balanceamento de carga . O número mínimo de réplicas é 1, então cada nó terá um fragmento principal e uma réplica. Mas se você tiver dados valiosos, por exemplo, transações financeiras, é melhor para 2 ou mais.
O tamanho do shard é de alguns GB a várias dezenas de GB . O número de shards em um nó não passa de 20 por 1 GB de quadril do Elasticsearch, é claro. O Elasticsearch mais lento diminui - nós também o atacamos. Nos datacenters em que há pouco tráfego, os dados não giram em volume, milhares de índices apareceram e o sistema travou.
Use allocation awareness , por exemplo, pelo nome de um hypervisor em caso de serviço. Ajuda a espalhar índices e shards por diferentes hipervisores, para que não se sobreponham quando um hipervisor desiste.
Crie índices antecipadamente . Boas práticas, especialmente ao escrever a tempo. O índice está imediatamente quente, pronto e não há atrasos.
Limite o número de shards de um índice por nó .
"index.routing.allocation.total_shards_per_node": 4 é o número máximo de shards de um índice por nó. No caso ideal, existem 2 deles, colocamos 4 apenas no caso, se ainda temos menos carros.
Qual é o problema aqui? Usamos a
allocation awareness - a Elasticsearch sabe como distribuir índices adequadamente entre os hipervisores. Mas descobrimos que depois que o nó foi desativado por um longo período de tempo e depois voltamos ao cluster, o Elasticsearch vê que há formalmente menos índices nele e eles são restaurados. Até que os dados sejam sincronizados, formalmente existem poucos índices no nó. Se necessário, aloque um novo índice, o Elasticsearch tenta martelar esta máquina o mais densamente possível com novos índices. Portanto, um nó recebe uma carga não apenas do fato de que os dados são replicados para ele, mas também de um novo tráfego, índices e novos dados que caem nesse nó. Controle e limite.
Recomendações de manutenção do Elasticsearch
Quem trabalha com o Elasticsearch está familiarizado com essas recomendações.
Durante a manutenção agendada, aplique as recomendações para atualização sem interrupção: desabilite a alocação de shard, liberação sincronizada.
Desativar alocação de shard . Desabilite a alocação de shard de réplicas, deixe a capacidade de alocar apenas o primário. Isso ajuda visivelmente o Elasticsearch - ele não realocará os dados que você não precisa. Por exemplo, você sabe que em meia hora o nó aumentará - por que transferir todos os shards de um nó para outro? Nada terrível acontecerá se você viver com o cluster amarelo por meia hora, quando apenas os fragmentos primários estiverem disponíveis.
Liberação sincronizada . Nesse caso, o nó sincroniza muito mais rapidamente quando retorna ao cluster.
Com uma carga pesada ao gravar no índice ou na recuperação, você pode reduzir o número de réplicas.
Se você fizer o download de uma grande quantidade de dados, por exemplo, pico de carregamento, poderá desativar os shards e depois fornecer um comando ao Elasticsearch para criá-los quando o carregamento já for menor.
Aqui estão alguns comandos que eu gosto de usar:
GET _cat/thread_pool?v - permite que você veja thread_pool em cada nó: o que é interessante agora, quais são as filas de gravação e leitura.
GET _cat/recovery/?active_only=true - quais índices são implantados para onde e onde a recuperação ocorre.
GET _cluster/allocation/explain - em uma forma humana conveniente, por que e quais índices ou réplicas não foram alocados.
Para o monitoramento, usamos o Grafana.
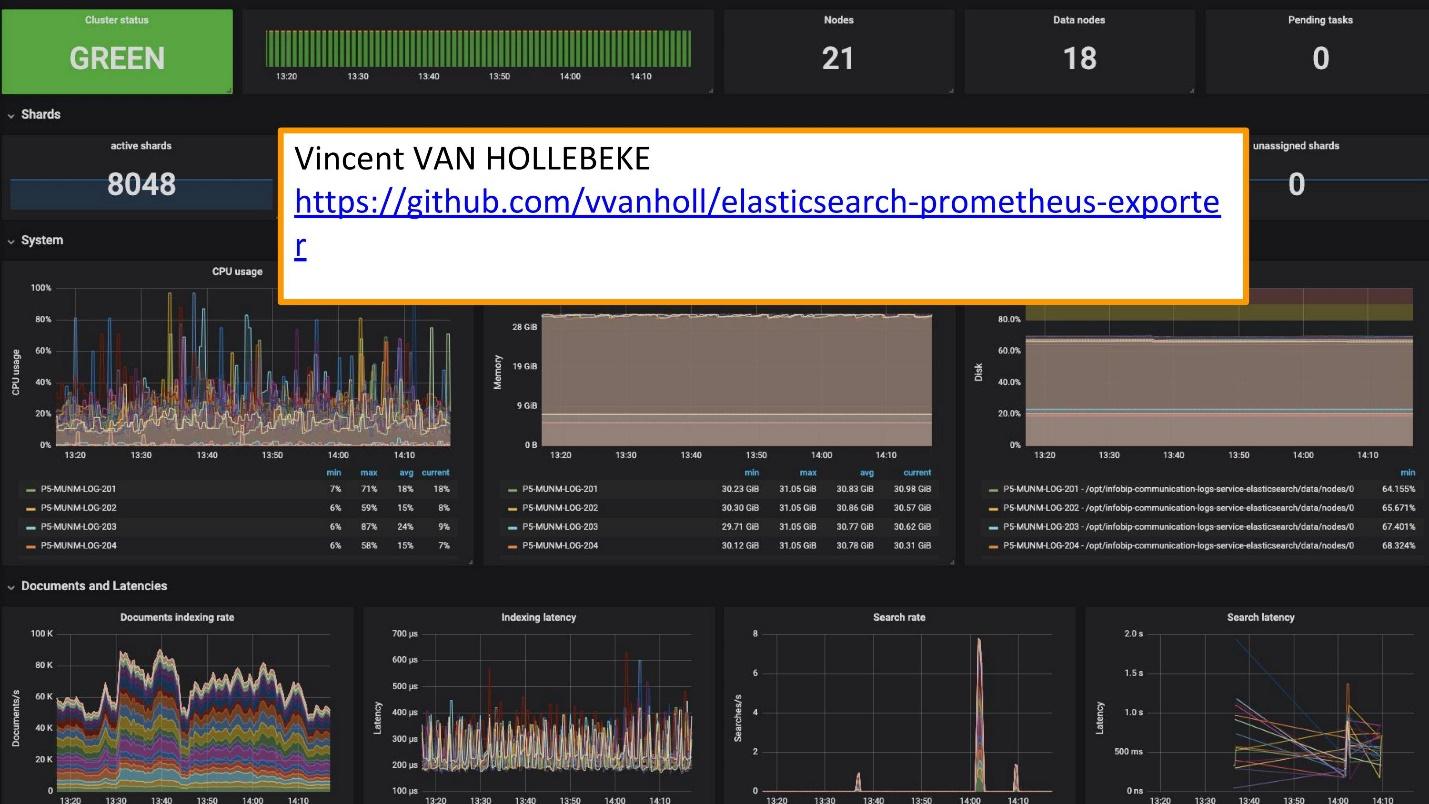
Existe um excelente
exportador e uma equipe Grafana de
Vincent van Hollebeke , que permite ver visualmente o status do cluster e todos os seus principais parâmetros. Adicionamos à nossa imagem do Docker e a todas as métricas ao implantar a partir de nossa caixa.
Conclusões de registro
Os logs devem ser:
- centralizado - um único ponto de entrada para desenvolvedores;
- disponível - a capacidade de pesquisar rapidamente;
- estruturado - para extração rápida e conveniente de informações valiosas;
- correlacionados - não apenas entre si, mas também com outras métricas e sistemas que você usa.
O concurso
Melodifestivalen sueco foi realizado recentemente. Esta é uma seleção de representantes da Suécia para a Eurovision. Antes da competição, nosso serviço de suporte nos contatou: “Agora, na Suécia, haverá uma grande carga. O tráfego é bastante sensível e queremos correlacionar alguns dados. Você tem dados nos logs que estão faltando no painel Grafana. Temos métricas que podem ser obtidas no Prometheus, mas precisamos de dados sobre solicitações de identificação específicas. ”
Eles adicionaram o Elasticsearch como a fonte do Grafana e foram capazes de correlacionar esses dados, fechar o problema e obter bons resultados com rapidez suficiente.
Explorar suas próprias soluções é muito mais fácil.
Agora, em vez dos 10 clusters Graylog que funcionaram para esta solução, temos vários serviços. São 10 centros de dados, mas nem sequer temos uma equipe dedicada e pessoas que os atendem. Existem várias pessoas que trabalharam nelas e mudaram algo conforme necessário. Essa pequena equipe está perfeitamente integrada à nossa infraestrutura - a implantação e a manutenção são mais fáceis e baratas.
Separe casos e use as ferramentas apropriadas.
Essas são ferramentas separadas para registro, rastreamento e monitoramento. Não existe um "instrumento de ouro" que cubra todas as suas necessidades.
Para entender qual ferramenta é necessária, o que monitorar, quais logs usar, quais requisitos de log, você deve definitivamente consultar o
SLI / SLO - Indicador de Nível de Serviço / Objetivo do Nível de Serviço. Você precisa saber o que é importante para seus clientes e seus negócios, para quais indicadores eles olham.
Uma semana depois, o SKOLKOVO sediará o HighLoad ++ 2019 . Na noite de 7 de novembro, Ivan Letenko lhe dirá como ele mora com Redis no prod, e no total há 150 relatórios no programa sobre vários tópicos.
Se você está tendo problemas para visitar o HighLoad ++ 2019 ao vivo, temos boas notícias. Este ano, a conferência será realizada em três cidades ao mesmo tempo - em Moscou, Novosibirsk e São Petersburgo. Ao mesmo tempo Como será e como chegar lá - descubra em uma página promocional separada do evento.