O poder do JavaScript e da API do navegadorO mundo está se tornando mais interconectado - o número de pessoas com acesso à Internet cresceu para
4,5 bilhões .
Mas esses dados não refletem o número de pessoas que têm uma conexão com a Internet lenta ou interrompida. Mesmo nos Estados Unidos,
4,9 milhões de residências não podem acessar o acesso à Internet com fio a velocidades superiores a 3 megabits por segundo.
O resto do mundo - aqueles com acesso confiável à Internet - ainda está propenso a perder a conectividade.
Alguns fatores que podem afetar a qualidade da sua conexão de rede incluem:
- Má cobertura do provedor.
- Condições climáticas extremas.
- Quedas de energia.
- Usuários que caem em zonas mortas, como prédios que bloqueiam suas conexões de rede.
- Viagens de trem e viagens de túnel.
- Conexões controladas por terceiros e com tempo limitado.
- Práticas culturais que requerem acesso limitado ou inexistente à Internet em horários ou dias específicos.
Diante disso, fica claro que devemos considerar uma experiência autônoma ao desenvolver e criar aplicativos.

Este artigo foi traduzido com o suporte da EDISON Software, uma empresa que realiza excelentes pedidos do sul da China e também desenvolve aplicativos e sites da web .
Recentemente, tive a oportunidade de adicionar autonomia a um aplicativo existente usando trabalhadores de serviço, armazenamento em cache e IndexedDB. O trabalho técnico necessário para o aplicativo funcionar offline foi reduzido para quatro tarefas separadas, as quais discutirei neste post.
Trabalhadores de serviço
Os aplicativos criados para uso offline não devem depender muito da rede. Conceitualmente, isso só é possível se, no caso de uma falha, existirem opções de backup.
Se o aplicativo da Web falhar ao carregar, devemos levar os recursos para o navegador em algum lugar (HTML / CSS / JavaScript). De onde vêm esses recursos, se não de uma solicitação de rede? Que tal um cache. A maioria das pessoas concorda que é melhor fornecer uma interface de usuário potencialmente desatualizada do que uma página em branco.
O navegador consulta dados constantemente. O serviço de cache de dados como substituto ainda exige que de alguma forma interceptemos solicitações do navegador e escrevamos regras de cache. É aqui que os trabalhadores do serviço entram em cena - pense neles como um intermediário.
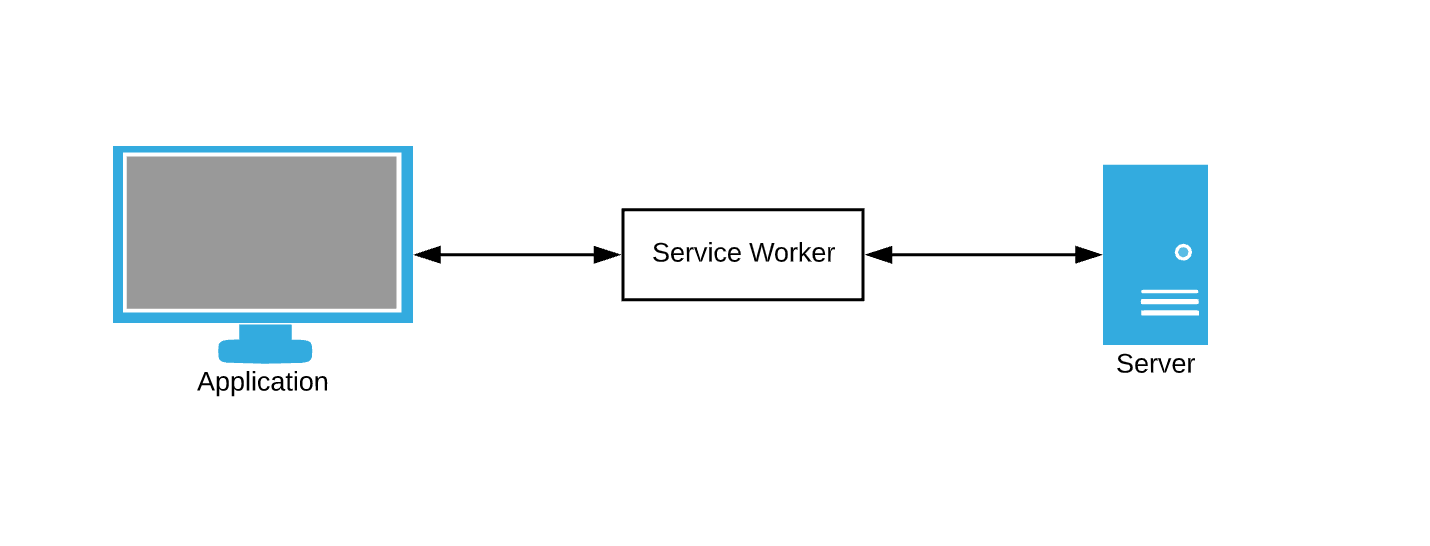
O responsável pelo serviço é apenas um arquivo JavaScript no qual podemos assinar eventos e escrever nossas próprias regras para armazenar em cache e manipular falhas de rede.
Vamos começar.
Observe: nosso aplicativo de demonstraçãoAo longo deste post, adicionaremos funções independentes ao aplicativo de demonstração. O aplicativo de demonstração é uma página simples para pegar / alugar livros na biblioteca. O progresso será apresentado como uma série de GIFs e o uso de simulações offline do Chrome DevTools.
Aqui está o estado inicial:
Tarefa 1 - Recursos estáticos em cache
Recursos estáticos são recursos que não mudam frequentemente. HTML, CSS, JavaScript e imagens podem se enquadrar nessa categoria. O navegador tenta carregar recursos estáticos usando solicitações que podem ser interceptadas pelo responsável pelo serviço.
Vamos começar registrando nosso técnico de serviço.
if ('serviceWorker' in navigator) { window.addEventListener('load', function() { navigator.serviceWorker.register('/sw.js'); }); }
Os trabalhadores do serviço são trabalhadores da
Web ocultos e, portanto, devem ser importados de um arquivo JavaScript separado. O registro ocorre usando o método de
register após o carregamento do site.
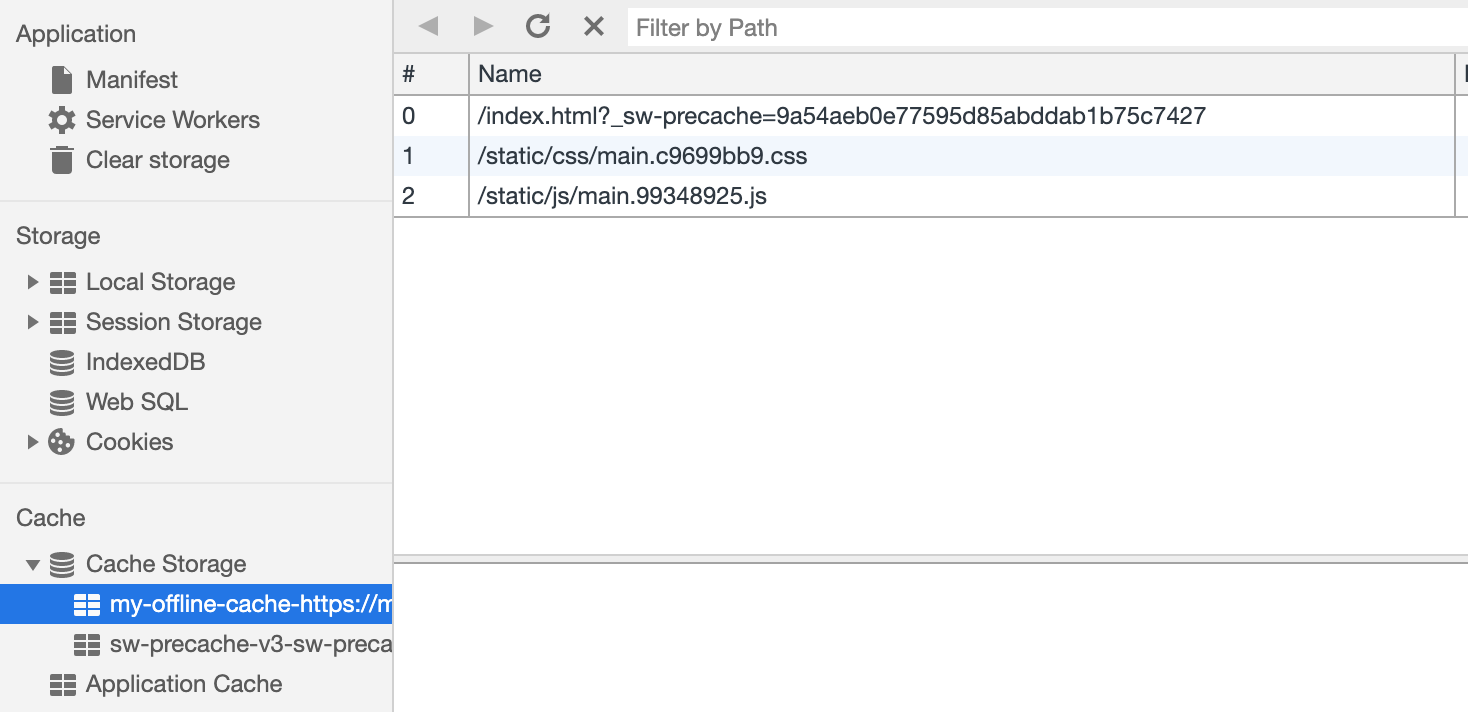
Agora que temos um trabalhador de serviço carregado, vamos armazenar em cache nossos recursos estáticos.
var CACHE_NAME = 'my-offline-cache'; var urlsToCache = [ '/', '/static/css/main.c9699bb9.css', '/static/js/main.99348925.js' ]; self.addEventListener('install', function(event) { event.waitUntil( caches.open(CACHE_NAME) .then(function(cache) { return cache.addAll(urlsToCache); }) ); });
Como controlamos os URLs dos recursos estáticos, podemos armazená-los em cache imediatamente após a inicialização do trabalhador do serviço usando o
Cache Storage .
Agora que nosso cache está cheio dos recursos estáticos solicitados mais recentemente, vamos carregar esses recursos a partir do cache no caso de uma falha na solicitação.
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request).catch(function() { caches.match(event.request).then(function(response) { return response; } ); ); });
O evento de
fetch é acionado toda vez que o navegador faz uma solicitação. Nosso novo manipulador de eventos de
fetch agora tem lógica adicional para retornar respostas em cache em caso de interrupções na rede.
Número de demonstração 1
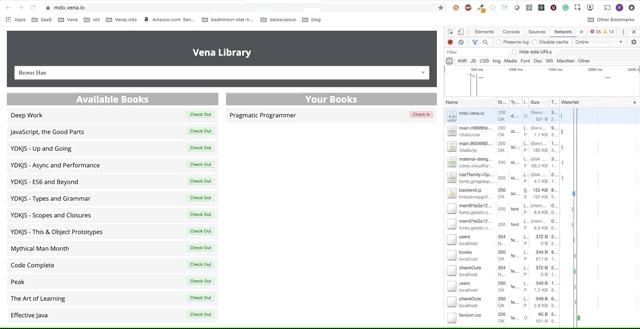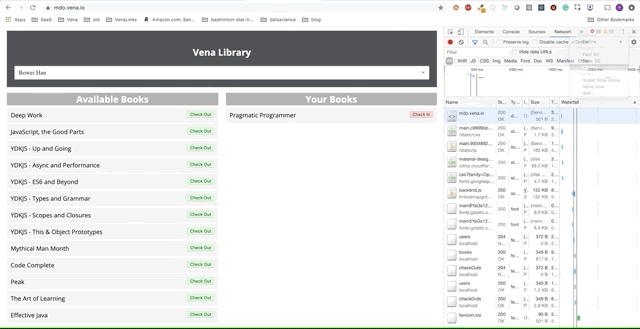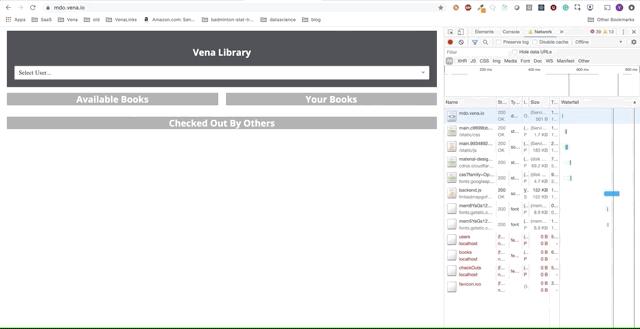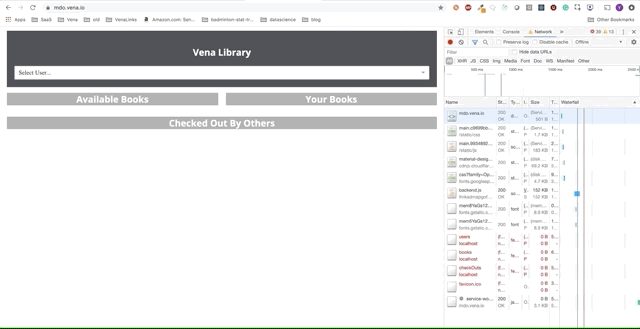
Nosso aplicativo de demonstração agora pode servir recursos estáticos offline! Mas onde estão nossos dados?
Tarefa 2 - Armazenamento em cache de recursos dinâmicos
Os aplicativos de página única (SPA) geralmente solicitam dados gradualmente após o carregamento inicial da página, e nosso aplicativo de demonstração não é uma exceção - a lista de livros não é carregada imediatamente. Esses dados geralmente vêm de solicitações XHR que retornam respostas que mudam frequentemente para fornecer um novo estado para o aplicativo - portanto, elas são dinâmicas.
O armazenamento em cache de recursos dinâmicos é realmente muito semelhante ao armazenamento em cache de recursos estáticos - a principal diferença é que precisamos atualizar o cache com mais frequência. Gerar uma lista completa de todas as possíveis solicitações dinâmicas de XHR também é bastante difícil, portanto, nós as armazenaremos em cache assim que chegarem, em vez de ter uma lista predefinida, como fizemos para recursos estáticos.
Dê uma olhada no nosso manipulador de
fetch :
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request).catch(function() { caches.match(event.request).then(function(response) { return response; } ); ); });
Podemos personalizar essa implementação adicionando algum código que armazena em cache solicitações e respostas bem-sucedidas. Isso garante que constantemente adicionamos novas solicitações ao nosso cache e atualizamos constantemente os dados em cache.
self.addEventListener('fetch', function(event) { event.respondWith( fetch(event.request) .then(function(response) { caches.open(CACHE_NAME).then(function(cache) { cache.put(event.request, response); }); }) .catch(function() { caches.match(event.request).then(function(response) { return response; } ); ); });
Atualmente, nosso
Cache Storage tem várias entradas.

Número de demonstração 2
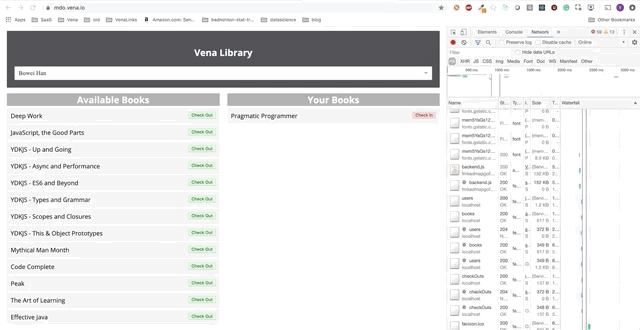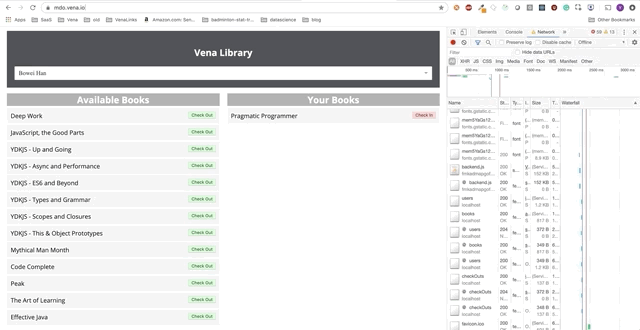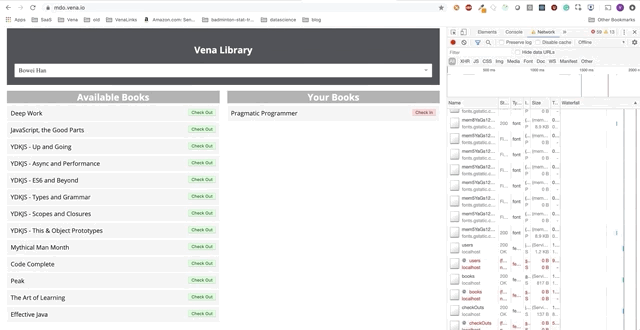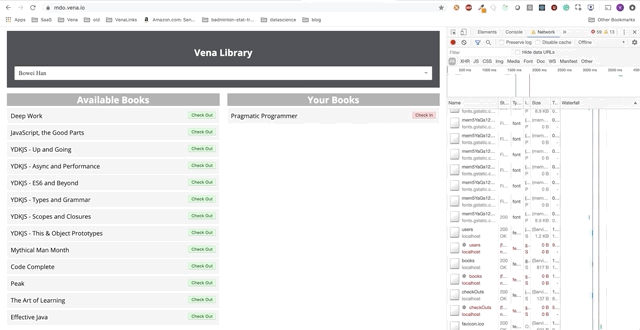
Nossa demonstração agora tem a mesma aparência na inicialização, independentemente do status da nossa rede!
Ótimo. Vamos agora tentar usar nosso aplicativo.
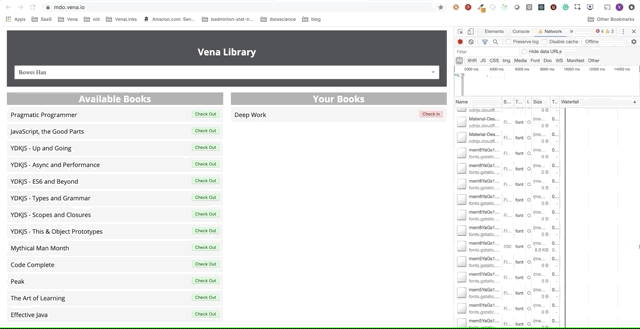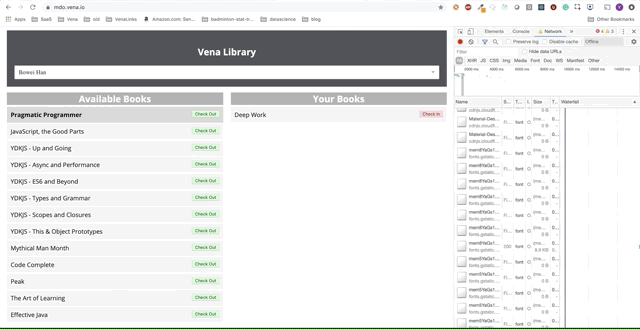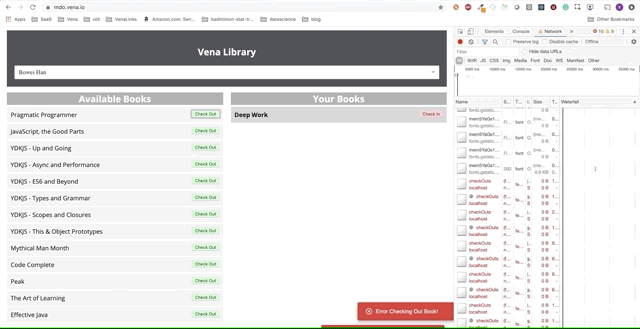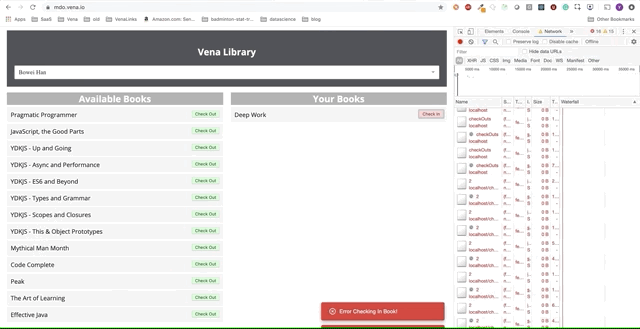
Infelizmente, as mensagens de erro estão por toda parte. Parece que todas as nossas interações com a interface não funcionam. Não posso escolher ou entregar o livro! O que precisa ser corrigido?
Tarefa 3 - Criar uma interface de usuário otimista
No momento, o problema com nosso aplicativo é que nossa lógica de coleta de dados ainda depende muito das respostas da rede. A ação de check-in ou check-out envia uma solicitação ao servidor e espera uma resposta bem-sucedida. Isso é ótimo para a consistência dos dados, mas ruim para a nossa experiência independente.
Para que essas interações funcionem offline, precisamos tornar nosso aplicativo mais
otimista . As interações otimistas não exigem uma resposta do servidor e exibem de bom grado uma visualização atualizada dos dados. A operação otimista usual na maioria dos aplicativos da Web é a
delete - por que não dar feedback instantâneo ao usuário se já temos todas as informações necessárias?
Desconectar nosso aplicativo da rede usando uma abordagem otimista é relativamente fácil de implementar.
case CHECK_OUT_SUCCESS: case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); return { ...state, list, }; case CHECK_IN_SUCCESS: case CHECK_IN_FAILURE; list = [...state.list]; for (let i = 0; i < list.length; i++) { if (list[i].id === action.payload.id) { list.splice(i, 1, action.payload); } } return { ...state, list, };
A chave é lidar com as ações do usuário da mesma maneira - independentemente de a solicitação de rede ser bem-sucedida ou não. O trecho de código acima é retirado do redutor de redux de nosso aplicativo,
SUCCESS e
FAILURE lançados dependendo da disponibilidade da rede. Independentemente de como a solicitação de rede for concluída, atualizaremos nossa lista de livros.
Número de demonstração 3
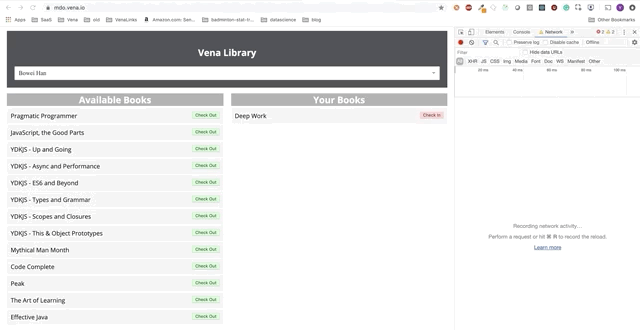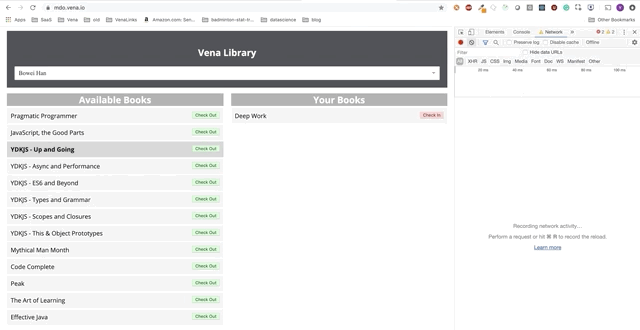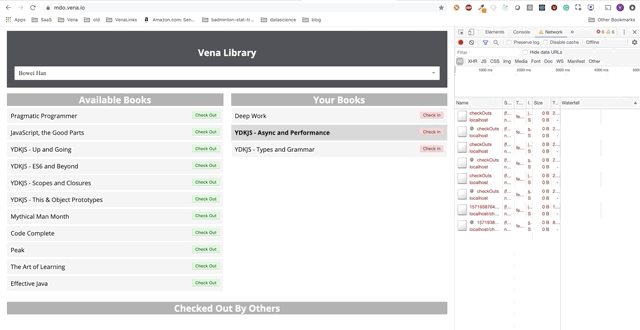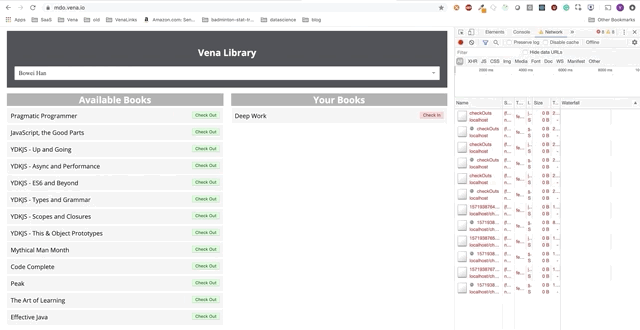
A interação do usuário agora ocorre online (não literalmente). Os botões "check-in" e "check-out" atualizam a interface adequadamente, embora as mensagens vermelhas do console mostrem que as solicitações de rede não estão sendo executadas.
Bom! Há apenas um pequeno problema com a renderização offline otimista ...
Não perdemos nossa mudança!?

Tarefa 4 - Filas de ações do usuário para sincronização
Precisamos rastrear as ações executadas pelo usuário quando ele estava offline, para que possamos sincronizá-las com nosso servidor quando o usuário retornar à rede. Existem vários mecanismos de armazenamento no navegador que podem atuar como uma fila de ações, e vamos usar o IndexedDB. O IndexedDB fornece algumas coisas que você não obterá do LocalStorage:
- Operações assíncronas sem bloqueio
- Limites de armazenamento significativamente mais altos
- Gerenciamento de transações
Veja o nosso código redutor antigo:
case CHECK_OUT_SUCCESS: case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); return { ...state, list, }; case CHECK_IN_SUCCESS: case CHECK_IN_FAILURE; list = [...state.list]; for (let i = 0; i < list.length; i++) { if (list[i].id === action.payload.id) { list.splice(i, 1, action.payload); } } return { ...state, list, };
Vamos modificá-lo para armazenar os eventos de check-in e check-out no IndexedDB durante o evento
FAILURE .
case CHECK_OUT_FAILURE: list = [...state.list]; list.push(action.payload); addToDB(action);
Aqui está a implementação da criação do IndexedDB junto com o
addToDB addToDB.
let db = indexedDB.open('actions', 1); db.onupgradeneeded = function(event) { let db = event.target.result; db.createObjectStore('requests', { autoIncrement: true }); }; const addToDB = action => { var db = indexedDB.open('actions', 1); db.onsuccess = function(event) { var db = event.target.result; var objStore = db .transaction(['requests'], 'readwrite') .objectStore('requests'); objStore.add(action); }; };
Agora que todas as nossas ações de usuário offline estão armazenadas na memória do navegador, podemos usar o ouvinte de eventos do navegador
online -
online para sincronizar dados quando a conexão é restaurada.
window.addEventListener('online', () => { const db = indexedDB.open('actions', 1); db.onsuccess = function(event) { let db = event.target.result; let objStore = db .transaction(['requests'], 'readwrite') .objectStore('requests'); objStore.getAll().onsuccess = function(event) { let requests = event.target.result; for (let request of requests) { send(request);
Nesta fase, podemos limpar a fila de todas as solicitações enviadas com êxito ao servidor.
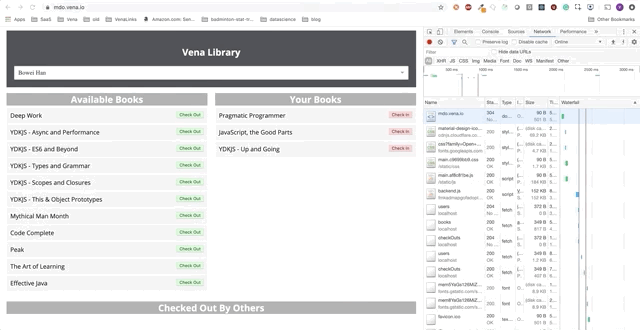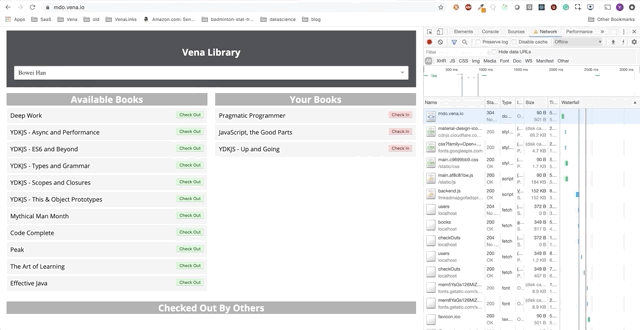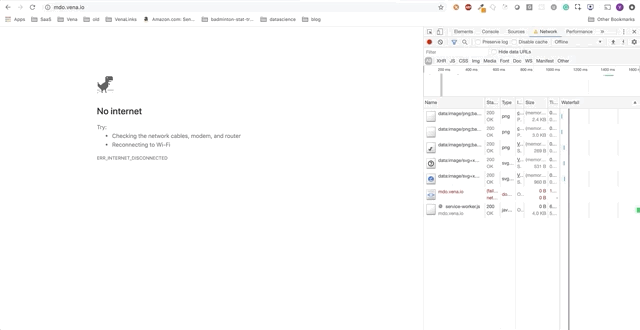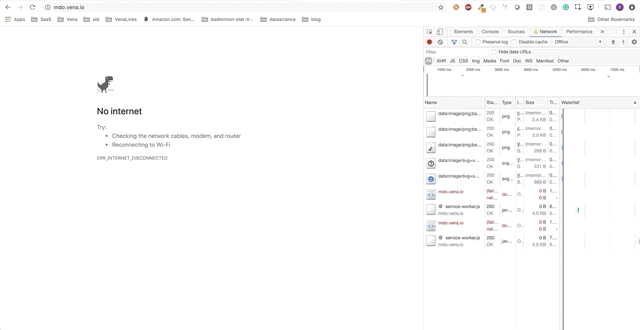
Número de demonstração 4
A demo final parece um pouco mais complicada. À direita, na janela escura do terminal, todas as atividades da API são registradas. A demonstração envolve ficar offline, selecionar vários livros e retornar online.
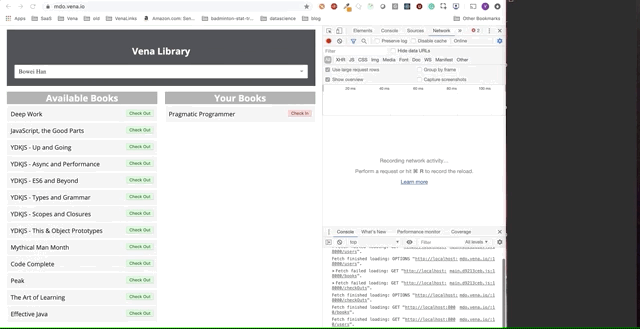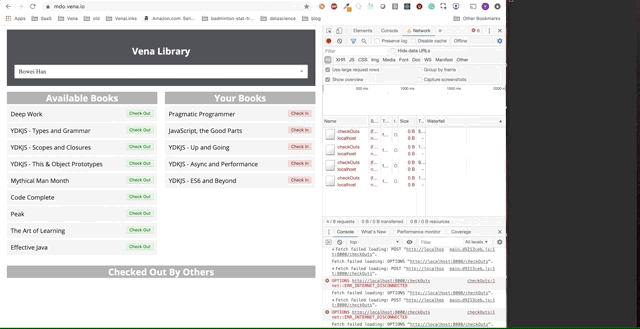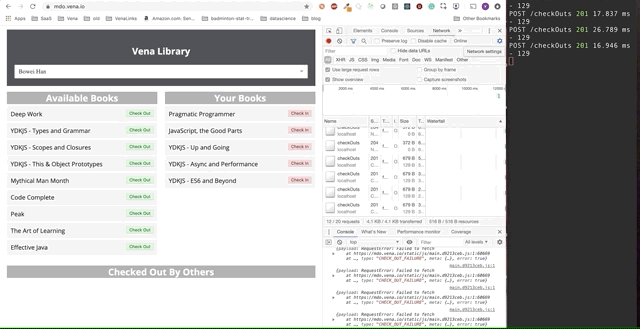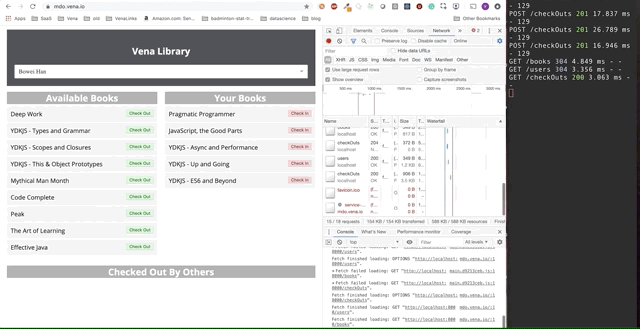
É claro que as solicitações feitas offline foram enfileiradas e enviadas imediatamente quando o usuário retorna online.
Essa abordagem de "brincadeira" é um pouco ingênua. Por exemplo, provavelmente não precisamos fazer duas solicitações se recebermos e devolvermos o mesmo livro. Também não funcionará se várias pessoas usarem o mesmo aplicativo.
Isso é tudo
Saia e torne seus aplicativos web offline! Esta postagem demonstra algumas das muitas coisas que você pode fazer para adicionar recursos autônomos aos seus aplicativos e definitivamente não é exaustiva.
Para saber mais, consulte
os Fundamentos da web do Google . Para ver outra implementação offline, confira
esta palestra .

Leia também o blog
Empresa EDISON:
20 bibliotecas para
aplicação iOS espetacular