Em 26 de outubro, Linz am Rhein (Alemanha) organizou a mini-conferência HaxeUp Sessions 2019 dedicada à Haxe e tecnologias relacionadas. E seu evento mais significativo foi, é claro, a versão final do Haxe 4.0.0 (no momento da publicação, ou seja, após cerca de uma semana, a atualização 4.0.1 foi lançada ). Neste artigo, gostaria de apresentar uma tradução do primeiro relatório da conferência - um relatório sobre o trabalho realizado pela equipe da Haxe em 2019.

Um pouco sobre o autor do relatório:
Simon trabalha com Haxe desde 2010, quando ainda era aluno e escreveu um trabalho sobre simulações de fluidos no Flash. A implementação dessa simulação exigia acesso constante aos dados que descrevem o estado das partículas (em cada etapa foram feitas mais de 100 consultas a matrizes de dados sobre o estado de cada célula na simulação), enquanto o trabalho com matrizes no ActionScript 3 não é tão rápido. Portanto, a implementação inicial era simplesmente inoperante e necessária para encontrar uma solução para esse problema. Em sua pesquisa, Simon encontrou um artigo de Nicolas Kannass (criador do Haxe) sobre os opcodes da Alquimia não documentados que não estavam disponíveis no ActionScript, mas o Haxe permitiu que eles fossem usados. Reescrevendo a simulação no Haxe usando opcodes, Simon conseguiu uma simulação de trabalho! E assim, graças às matrizes lentas no ActionScript, Simon aprendeu sobre o Haxe.
Desde 2011, Simon ingressou no desenvolvimento do Haxe, ele começou a estudar o OCaml (no qual o compilador está escrito) e a fazer várias correções no compilador.
E desde 2012, ele se tornou o principal desenvolvedor de compiladores. No mesmo ano, a Fundação Haxe foi criada (uma organização cujos principais objetivos são o desenvolvimento e manutenção do ecossistema Haxe, ajudando a comunidade a organizar conferências, serviços de consultoria), e Simon se tornou um dos seus co-fundadores.

Em 2014-2015, Simon convidou Josephine Pertosa para a Fundação Haxe, que com o tempo se tornou responsável pela organização de conferências e relações com a comunidade.
Em 2016, Simon fez sua primeira apresentação no Haxe e, em 2018, organizou as primeiras sessões do HaxeUp .

Então, o que aconteceu no mundo Haxe nos últimos 2019?
Em fevereiro e março, foram lançados 2 candidatos a liberação (4.0.0-rc1 e 4.0.0-rc2)
Em abril, Aurel Bili (como estagiário) e Alexander Kuzmenko (como desenvolvedor de compiladores) se juntaram à equipe da Haxe Foundation.
Em maio, foi realizada a Haxe US Summit 2019 .
Em junho, o Haxe 4.0.0-rc3 foi lançado. E em setembro - Haxe 4.0.0-rc4 e Haxe 4.0.0-rc5.

O Haxe não é apenas um compilador, mas também um conjunto inteiro de várias ferramentas, e ao longo do ano o trabalho nelas também era constantemente conduzido:
Graças aos esforços de Andy Lee, Haxe agora usa os pipelines do Azure em vez do Travis CI e do AppVeyor. Isso significa que agora os testes de montagem e automatizados são muito mais rápidos.
Hugh Sanderson continua trabalhando no hxcpp (uma biblioteca de suporte ao C ++ no Haxe).
De repente, os usuários do Github terurou e takashiski juntaram-se ao trabalho de externos para o Node.js.
Rudy Ges trabalhou em correções e melhorias para dar suporte ao destino C #.
George Corney continua a suportar o gerador externo de HTML.
Jens Fisher está trabalhando no vshaxe (uma extensão do VS Code para trabalhar com o Haxe) e em muitos outros projetos relacionados ao Haxe.

E o principal evento do ano, é claro, foi o tão esperado lançamento do Haxe 4.0.0 (assim como o neko 2.3.0), que coincidiu acidentalmente com o HaxeUp 2019 Linz :)

Simon dedicou a maior parte do relatório aos novos recursos do Haxe 4.0.0 (você também pode aprender sobre eles no relatório de Alexander Kuzmenko do último Haxe US Summit 2019).

O novo intérprete de macro de avaliação é várias vezes mais rápido que o antigo. Simon falou sobre ele em detalhes em seu discurso na Haxe Summit EU 2017 . Mas desde então, ele aprimorou os recursos de depuração do código, corrigiu muitos bugs e reformulou a implementação de strings.
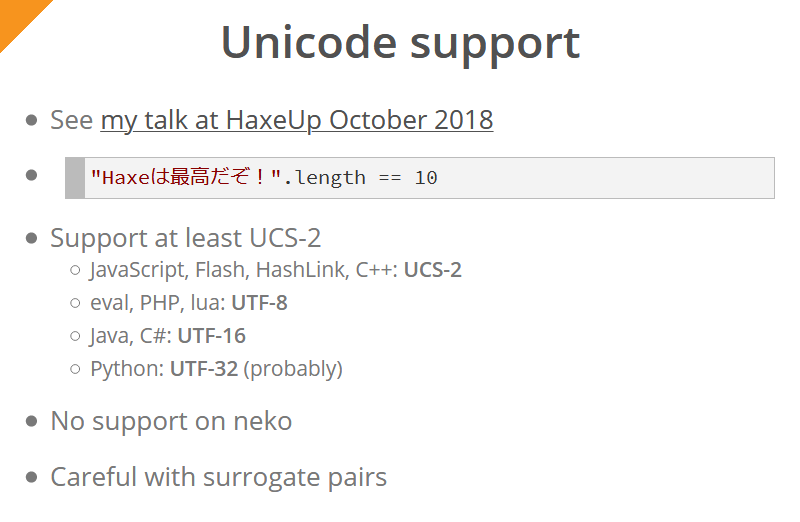
O Haxe 4 apresenta o suporte Unicode para todas as plataformas (exceto Neko). Simon descreveu isso em detalhes no discurso do ano passado . Para o usuário final do compilador, isso significa que a expressão "Haxeは最高だぞ!".length de todas as plataformas sempre retornará 10 (novamente, exceto Neko).
A codificação UCS-2 é minimamente suportada (uma codificação suportada nativamente é usada para cada plataforma / idioma; tentar suportar a mesma codificação em qualquer lugar seria impraticável):
- JavaScript, Flash, HashLink e C ++ usam codificação UCS-2
- para eval, PHP, lua - UTF-8
- para Java e C # - UTF-16
- para Python - UTF-32
Todos os caracteres que estão fora do plano multilíngue principal (incluindo emoji) são representados como "pares substitutos" - esses caracteres são representados por dois bytes. Por exemplo, se em Java / C # / JavaScript (ou seja, para cadeias de caracteres nas codificações UTF-16 e UCS-2) solicitar o comprimento de uma cadeia de caracteres composta por um emoji, o resultado será "2". Esse fato deve ser levado em consideração ao trabalhar com essas seqüências nessas plataformas.
O Haxe 4 apresenta um novo tipo de iterador - valor-chave:

Funciona com contêineres do tipo Map (dicionários) e strings (usando a classe StringTools), o suporte a matrizes ainda não foi implementado. Também é possível implementar esse iterador para classes personalizadas, para isso basta implementar o método keyValueIterator():KeyValueIterator<K, V> para elas keyValueIterator():KeyValueIterator<K, V> .
A nova meta tag @:using permite associar extensões estáticas a tipos no local da declaração.
No exemplo mostrado no slide abaixo, a enumeração MyOption associada ao MyOptionTools , então expandimos estaticamente essa enumeração (o que é impossível na situação usual) e temos a oportunidade de chamar o método get() , referindo-se a ele como um método de objeto.

Neste exemplo, o método get() é embutido, o que também permite que o compilador otimize ainda mais o código: em vez de chamar o MyOptionTools.get(myOption) , o compilador substituirá o valor armazenado, ou seja, 12 .
Se o método não for declarado como incorporável, outra ferramenta de otimização disponível para o programador é incorporar as funções no local da chamada (inlining do site de chamada). Para fazer isso, ao chamar a função, você também deve usar a inline - inline :

Graças ao trabalho de Daniil Korostelev , Haxe agora tem a oportunidade de gerar classes ES6 para JavaScript. Tudo que você precisa fazer é adicionar a flag de compilação -D js-es=6 .
Atualmente, o compilador gera um arquivo js para todo o projeto (pode ser possível no futuro gerar arquivos js separados para cada uma das classes, mas até agora isso só pode ser feito usando ferramentas adicionais ).

Para enumerações abstratas, os valores agora são gerados automaticamente.
No Haxe 3, era necessário definir valores manualmente para cada construtor. No Haxe 4, as enumerações abstratas criadas no topo do Int se comportam de acordo com as mesmas regras do C. As enumerações abstratas criadas no topo das seqüências de caracteres se comportam de maneira semelhante - para elas, os valores gerados coincidirão com os nomes dos construtores.

Também vale a pena mencionar algumas melhorias na sintaxe:
- enumerações abstratas e funções externas tornaram-se membros de pleno direito do Haxe e agora você não precisa usar as metatags
@:enum e @:extern para declará-las - O quarto Haxe usa uma nova sintaxe de interseção de tipo que reflete melhor a essência das estruturas em expansão. Tais construções são mais úteis ao declarar estruturas de dados: a expressão
typedef T = A & B significa que a estrutura T possui todos os campos dos tipos A e B - Da mesma forma, os quatro declaram restrições de parâmetro de tipo: a entrada
<T:A & B> indica que o tipo de parâmetro T deve ser A e B - a sintaxe antiga funcionará (exceto a sintaxe para restrições de tipo, porque entrará em conflito com a nova sintaxe para descrever os tipos de função)

A nova sintaxe para descrever os tipos de função (sintaxe do tipo de função) é mais lógica: usar parênteses em torno dos tipos de argumentos da função é visualmente mais fácil de ler. Além disso, a nova sintaxe permite definir nomes de argumentos, que podem ser usados como parte da documentação do código (embora isso não afete a digitação).

Nesse caso, a sintaxe antiga continua sendo suportada e não é preterida, pois caso contrário, exigiria muitas alterações no código existente (o próprio Simon constantemente se encontra fora de hábito e continua a usar a sintaxe antiga).
O Haxe 4 finalmente possui funções de seta (ou expressões lambda)!

Os recursos das funções de seta no Haxe são:
return implícito. Se o corpo da função consistir em uma expressão, essa função retornará implicitamente o valor dessa expressão- é possível definir os tipos de argumentos da função, porque o compilador nem sempre pode determinar o tipo necessário (por exemplo,
Float ou Int ) - se o corpo da função consistir em várias expressões, você precisará cercá-lo com chaves
- mas não há como definir explicitamente o tipo de retorno da função
Em geral, a sintaxe das funções de seta é muito semelhante à usada no Java 8 (embora funcione de maneira um pouco diferente).
E como mencionamos o Java, deve-se dizer que no Haxe 4 foi possível gerar diretamente o bytecode da JVM. Para fazer isso, ao compilar um projeto em Java, basta adicionar o sinalizador -D jvm .
Gerar um bytecode da JVM significa que não há necessidade de usar um compilador Java e o processo de compilação é muito mais rápido.

Até o momento, o destino da JVM possui status experimental pelos seguintes motivos:
- em alguns casos, o bytecode é um pouco mais lento que o resultado da tradução do Haxe em Java e da compilação com o javac. Mas a equipe do compilador está ciente do problema e sabe como corrigi-lo, apenas requer trabalho adicional.
- existem problemas com o MethodHandle no Android, o que também requer trabalho adicional (Simon ficará feliz se ele for ajudado a resolver esses problemas).

Uma comparação geral da geração direta do bytecode (genjvm) e da compilação do Haxe no código Java, que é então compilado no bytecode (genjava):
- como já mencionado, em termos de velocidade de compilação, o genjvm é mais rápido que o genjava
em termos de velocidade de execução, o bytecode genjvm ainda é inferior ao genjava - existem alguns problemas ao usar parâmetros de tipo e genjava
- O genJvm usa o MethodHandle para se referir às funções, e o genjava usa as chamadas "funções Waneck" (em homenagem a Kaui Vanek , graças às quais o suporte a Java e C # apareceu no Haxe). Embora o código obtido usando as funções Waneck não pareça bonito, ele funciona e funciona com rapidez suficiente.
Dicas gerais para trabalhar com Java no Haxe:
- Devido ao fato de o coletor de lixo em Java ser rápido, os problemas associados a ele são raros. Obviamente, criar constantemente novos objetos não é uma boa ideia, mas Java lida bem com o gerenciamento de memória e a necessidade de cuidar constantemente das alocações não é tão aguda quanto em outras plataformas suportadas pelo Haxe (por exemplo, no HashLink)
- acessar os campos de uma classe em um destino jvm pode funcionar muito lentamente no caso em que isso é feito através de uma estrutura (
typedef ) - enquanto o compilador não pode otimizar esse código - o uso excessivo da palavra-chave
inline deve ser evitado - o compilador JIT faz um bom trabalho - Evite usar
Null<T> , especialmente ao lidar com cálculos matemáticos complexos. Caso contrário, muitas instruções condicionais aparecerão no código gerado, o que afetará negativamente a velocidade do seu código.
O novo recurso Haxe 4, segurança nula, pode ajudar a evitar o uso de Null<T> . Alexander Kuzmenko falou em detalhes sobre ela no HaxeUp do ano passado .

No exemplo no slide acima, o método static safe() possui o modo Rigoroso para verificar a segurança Nula ativada e esse método possui um parâmetro arg opcional, que pode ter um valor nulo. Para que essa função seja compilada com êxito, o programador precisará adicionar uma verificação do valor do argumento arg (caso contrário, o compilador exibirá uma mensagem sobre a impossibilidade de chamar o método charAt() em um objeto potencialmente nulo).
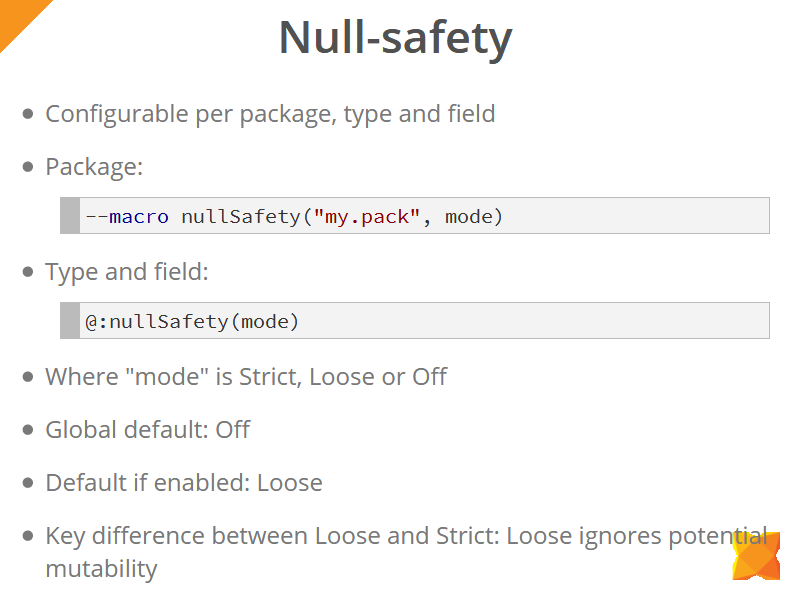
A segurança nula pode ser configurada no nível do pacote (usando uma macro) e tipos e campos individuais de objetos (usando a metatag @:nullSafety ).
Os modos nos quais as verificações de segurança nula funcionam são: Estrito, Solto e Desativado. Globalmente, essas verificações estão desativadas (modo desativado). Quando estão ativados, o modo Loose é usado por padrão (a menos que você especifique explicitamente o modo). A principal diferença entre os modos Loose e Strict é que o modo Loose ignora a possibilidade de alterar valores entre operações de acesso a esses valores. No exemplo no slide abaixo, vemos que uma verificação null foi adicionada para a variável x . No entanto, no modo Estrito, esse código não é compilado, porque antes de trabalhar diretamente com a variável x , o método sideEffect() é sideEffect() , o que pode potencialmente anular o valor dessa variável; portanto, você precisará adicionar outra verificação ou copiar o valor da variável em uma variável local, com a qual continuaremos trabalhando.

O Haxe 4 apresenta uma nova palavra-chave final , que tem um significado diferente, dependendo do contexto:
- se você usá-lo em vez da palavra-chave
var , o campo declarado dessa maneira não poderá receber um novo valor. Você pode defini-lo diretamente apenas ao declarar (para campos estáticos) ou no construtor (para campos não estáticos) - se você usá-lo ao declarar uma classe, ele proibirá a herança dela
- se você o usar como um modificador para acessar a propriedade de um objeto, isso proibirá a redefinição de getter / setter nas classes derivadas.

Teoricamente, o compilador, tendo encontrado a palavra-chave final , pode tentar otimizar o código, assumindo que o valor desse campo não seja alterado. Mas, por enquanto, essa possibilidade está sendo considerada apenas e não está implementada no compilador.

E um pouco sobre o futuro de Haxe:
- atualmente trabalhando na API de E / S assíncrona
O suporte à Coroutine está planejado, mas, até o momento, o trabalho sobre eles está paralisado no estágio de planejamento. Talvez eles apareçam no Haxe 4.1, e talvez mais tarde. - A otimização de chamada de cauda aparecerá no compilador
- e possivelmente as funções disponíveis no nível do módulo . Embora a prioridade desse recurso esteja constantemente mudando