O resultado cumulativo (cumulativo) há muito tempo é considerado uma das chamadas SQL. Surpreendentemente, mesmo após o aparecimento das funções da janela, ele continua sendo um espantalho (em qualquer caso, para iniciantes). Hoje, examinamos a mecânica das 10 soluções mais interessantes para esse problema - das funções da janela a hacks muito específicos.
Em planilhas como o Excel, o total em execução é calculado de maneira muito simples: o resultado no primeiro registro corresponde ao seu valor:
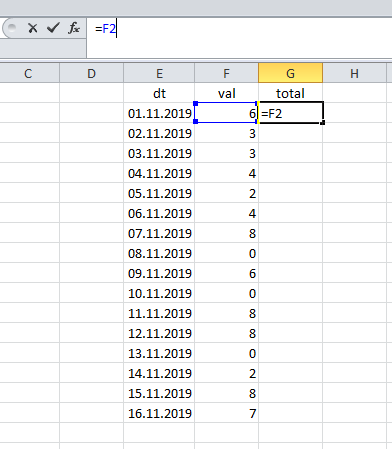
... e depois resumimos o valor atual e o total anterior.

Em outras palavras
... ou:
A aparência de dois ou mais grupos na tabela complica um pouco a tarefa: agora contamos vários resultados (para cada grupo separadamente). No entanto, aqui a solução está na superfície: cada vez que é necessário verificar a qual grupo pertence o registro atual.
Clique e arraste , e o trabalho está concluído:
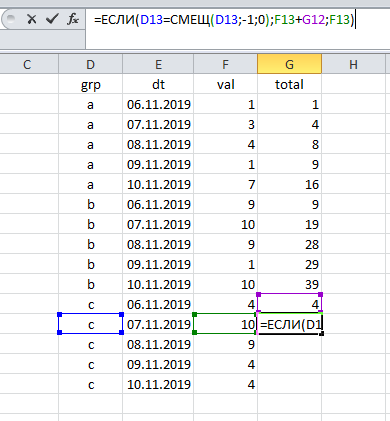
Como você pode ver, o cálculo do total acumulado está associado a dois componentes inalterados:
(a) classificação dos dados por data e
(b) referindo-se à linha anterior.
Mas o que é SQL? Durante muito tempo, não houve funcionalidade necessária. Uma ferramenta necessária - funções da janela - apareceu pela primeira vez apenas no padrão
SQL: 2003 . Neste ponto, eles já estavam no Oracle (versão 8i). Mas a implementação em outros DBMSs foi adiada por 5 a 10 anos: SQL Server 2012, MySQL 8.0.2 (2018), MariaDB 10.2.0 (2017), PostgreSQL 8.4 (2009), DB2 9 para z / OS (2007) ano) e até SQLite 3.25 (2018).
1. Funções da janela
As funções da janela são provavelmente a maneira mais fácil. No caso base (tabela sem grupos), consideramos os dados classificados por data:
order by dt
... mas estamos interessados apenas nas linhas anteriores à atual:
rows between unbounded preceding and current row
Por fim, precisamos de uma soma com estes parâmetros:
sum(val) over (order by dt rows between unbounded preceding and current row)
Uma solicitação completa ficaria assim:
select s.*, coalesce(sum(s.val) over (order by s.dt rows between unbounded preceding and current row), 0) as total from test_simple s order by s.dt;
No caso de um total acumulado para grupos (campo
grp ), precisamos apenas de uma pequena edição. Agora, consideramos os dados divididos em "janelas", com base no grupo:

Para explicar essa separação, você deve usar a
partition by palavra-chave:
partition by grp
E, portanto, considere a quantidade para essas janelas:
sum(val) over (partition by grp order by dt rows between unbounded preceding and current row)
Em seguida, toda a consulta é convertida assim:
select tg.*, coalesce(sum(tg.val) over (partition by tg.grp order by tg.dt rows between unbounded preceding and current row), 0) as total from test_groups tg order by tg.grp, tg.dt;
O desempenho das funções da janela dependerá das especificidades do seu DBMS (e sua versão!), O tamanho da tabela e a disponibilidade dos índices. Mas, na maioria dos casos, esse método será o mais eficaz. No entanto, as funções de janela não estão disponíveis nas versões mais antigas do DBMS (que ainda estão em uso). Além disso, eles não estão em DBMSs como Microsoft Access e SAP / Sybase ASE. Se for necessária uma solução independente do fornecedor, deve-se considerar alternativas.
2. Subconsulta
Como mencionado acima, as funções da janela foram introduzidas muito tarde no DBMS principal. Esse atraso não deve ser surpreendente: na teoria relacional, os dados não são ordenados. Muito mais para o espírito da teoria relacional corresponde a uma solução através de uma subconsulta.
Essa subconsulta deve considerar a soma dos valores com uma data anterior à atual (e incluindo a atual):
.
O que no código se parece com isso:
select s.*, (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt <= s.dt) as total from test_simple s order by s.dt;
Uma solução um pouco mais eficiente será aquela em que a subconsulta considera o total até a data atual (mas não a inclui) e, em seguida, resume-o com o valor na linha:
select s.*, s.val + (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt < s.dt) as total from test_simple s order by s.dt;
No caso de um resultado cumulativo para vários grupos, precisamos usar uma subconsulta correlacionada:
select g.*, (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt) as total from test_groups g order by g.grp, g.dt;
A condição
g.grp = t2.grp verifica as linhas para inclusão no grupo (que, em princípio, é semelhante ao trabalho de
partition by grp nas funções da janela).
3. Conexão interna
Como subconsultas e junções são intercambiáveis, podemos facilmente substituir uma pela outra. Para fazer isso, você deve usar a Junção automática, conectando duas instâncias da mesma tabela:
select s.*, coalesce(sum(t2.val), 0) as total from test_simple s inner join test_simple t2 on t2.dt <= s.dt group by s.dt, s.val order by s.dt;
Como você pode ver, a condição de filtragem na subconsulta
t2.dt <= s.dt se tornou uma condição de junção. Além disso, para usar a função agregadora
sum() precisamos agrupar por data e valor por
group by s.dt, s.val .
Da mesma forma, você pode fazer o caso com diferentes grupos
grp :
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g inner join test_groups t2 on g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
4. produto cartesiano
Como substituímos a subconsulta por join, por que não experimentar o produto cartesiano? Esta solução exigirá apenas edições mínimas:
select s.*, coalesce(sum(t2.val), 0) as total from test_simple s, test_simple t2 where t2.dt <= s.dt group by s.dt, s.val order by s.dt;
Ou para o caso de grupos:
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g, test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
As soluções listadas (subconsulta, junção interna, junção cartesiana) correspondem ao
SQL-92 e
SQL: 1999 e, portanto, estarão disponíveis em quase todos os DBMS. O principal problema com todas essas soluções é o baixo desempenho. Isso não é um grande problema se materializarmos uma tabela com o resultado (mas você ainda deseja mais velocidade!). Métodos adicionais são muito mais eficazes (ajustados para as especificidades de DBMSs específicos e suas versões já especificadas, tamanho da tabela, índices).
5. Pedido recursivo
Uma das abordagens mais específicas é uma consulta recursiva em uma expressão de tabela comum. Para fazer isso, precisamos de uma "âncora" - uma consulta que retorne a primeira linha:
select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple)
Em seguida, com a ajuda da
union all , os resultados de uma consulta recursiva são adicionados à "âncora". Para fazer isso, você pode confiar no campo
dt date, adicionando um dia a ele:
select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt)
A parte do código que adiciona um dia não é universal. Por exemplo, este é
r.dt = dateadd(day, 1, cte.dt) para o SQL Server,
r.dt = cte.dt + 1 para Oracle, etc.
Combinando a "âncora" e a solicitação principal, obtemos o resultado final:
with cte (dt, val, total) as (select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple) union all select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt)
A solução para o caso com grupos não será muito mais complicada:
with cte (dt, grp, val, total) as (select g.dt, g.grp, g.val, g.val as total from test_groups g where g.dt = (select min(dt) from test_groups where grp = g.grp) union all select r.dt, r.grp, r.val, cte.total + r.val from cte inner join test_groups r on r.dt = dateadd(day, 1, cte.dt)
6. Consulta recursiva com a função row_number()
A decisão anterior foi baseada na continuidade do campo
dt date com um aumento seqüencial de 1 dia. Evitamos isso usando a função da janela
row_number() , que numera as linhas. Claro, isso é injusto - porque vamos considerar alternativas às funções da janela. No entanto, essa solução pode ser uma espécie de
prova de conceito : na prática, pode haver um campo que substitua os números de linha (ID do registro). Além disso, no SQL Server, a função
row_number() apareceu antes da introdução do suporte completo às funções da janela (incluindo
sum() ).
Portanto, para uma consulta recursiva com
row_number() , precisamos de dois STEs. No primeiro, apenas numeramos as linhas:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple)
... e se o número da linha já estiver na tabela, você poderá ficar sem ele. Na consulta a seguir, já estamos nos
cte1 ao
cte1 :
cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 )
E toda a solicitação é assim:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple), cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 ) select dt, val, total from cte2 order by dt;
... ou no caso de grupos:
with cte1 (dt, grp, val, rn) as (select dt, grp, val, row_number() over (partition by grp order by dt) as rn from test_groups), cte2 (dt, grp, val, rn, total) as (select dt, grp, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.grp, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.grp = cte2.grp and cte1.rn = cte2.rn + 1 ) select dt, grp, val, total from cte2 order by grp, dt;
7. LATERAL / LATERAL
Uma das maneiras mais exóticas de calcular um total em execução é usar a instrução
CROSS APPLY (SQL Server, Oracle) ou seu equivalente
LATERAL (MySQL, PostgreSQL). Esses operadores apareceram bastante tarde (por exemplo, no Oracle apenas da versão 12c). E em alguns DBMSs (por exemplo,
MariaDB ) eles não são de todo. Portanto, essa decisão é de interesse puramente estético.
Funcionalmente, o uso de
CROSS APPLY ou
LATERAL idêntico à subconsulta: anexamos o resultado do cálculo à solicitação principal:
cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2
... que se parece com isso:
select s.*, t2.total from test_simple s cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2 order by s.dt;
A solução para o caso com grupos será semelhante:
select g.*, t2.total from test_groups g cross apply (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt ) t2 order by g.grp, g.dt;
Total: examinamos as principais soluções independentes de plataforma. Mas existem soluções específicas para DBMS específico! Como existem muitas opções aqui, vamos nos debruçar sobre algumas das mais interessantes.
8. MODEL (Oracle)
A instrução
MODEL no Oracle fornece uma das soluções mais elegantes. No início do artigo, examinamos a fórmula geral do total acumulado:
MODEL permite que você implemente essa fórmula literalmente um para um! Para fazer isso, primeiro preenchemos o campo
total com os valores da linha atual
select dt, val, val as total from test_simple
... então calculamos o número da linha como
row_number() over (order by dt) as rn (ou usamos o campo finalizado com o número, se houver). E, finalmente, introduzimos uma regra para todas as linhas, exceto a primeira:
total[rn >= 2] = total[cv() - 1] + val[cv()] .
A função
cv() aqui é responsável pelo valor da linha atual. E toda a solicitação ficará assim:
select dt, val, total from (select dt, val, val as total from test_simple) t model dimension by (row_number() over (order by dt) as rn) measures (dt, val, total) rules (total[rn >= 2] = total[cv() - 1] + val[cv()]) order by dt;
9. Cursor (SQL Server)
Um total em execução é um dos poucos casos em que o cursor no SQL Server não é apenas útil, mas também preferível a outras soluções (pelo menos até a versão 2012, onde as funções da janela eram exibidas).
A implementação através do cursor é bastante trivial. Primeiro, você precisa criar uma tabela temporária e preenchê-la com datas e valores do principal:
create table
Em seguida, definimos as variáveis locais através das quais a atualização ocorrerá:
declare @VarTotal int, @VarDT date, @VarVal int; set @VarTotal = 0;
Depois disso, atualizamos a tabela temporária através do cursor:
declare cur cursor local static read_only forward_only for select dt, val from
E, finalmente, obtemos o resultado desejado:
select dt, val, total from
10. Atualize através de uma variável local (SQL Server)
A atualização por meio de uma variável local no SQL Server é baseada em comportamento não documentado, portanto não pode ser considerada confiável. No entanto, essa talvez seja a solução mais rápida e interessante.
Vamos criar duas variáveis: uma para totais acumulados e uma variável de tabela:
declare @VarTotal int = 0; declare @tv table (dt date null, val int null, total int null );
Primeiro, preencha
@tv dados da tabela principal
insert @tv (dt, val, total) select dt, val, 0 as total from test_simple order by dt;
Em seguida
@tv atualizamos a variável de tabela
@tv usando
@VarTotal :
update @tv set @VarTotal = total = @VarTotal + val from @tv;
... após o qual obtemos o resultado final:
select * from @tv order by dt;
Resumo: Revisamos as 10 principais maneiras de calcular totais acumulados no SQL. Como você pode ver, mesmo sem as funções da janela, esse problema é completamente solucionável e a mecânica da solução não pode ser chamada de complicada.