Existem várias maneiras de testar APIs e interfaces. Em conexão com a abertura de amplo acesso à Acronis Cyber Platform, fomos forçados a procurar maneiras de testar os serviços “quanto à durabilidade” em várias posições. Neste post, o arquiteto líder de software da Acronis, Dmitry Salomatin, fala sobre como escolhemos a estrutura para teste, quais dificuldades encontramos e quais melhorias tivemos que fazer sozinhos.

Devo dizer imediatamente que nós da Acronis somos especialmente cuidadosos ao testar APIs. O fato é que nossos próprios produtos acessam serviços através das mesmas APIs usadas para conectar sistemas externos. Portanto, é necessário testar o desempenho de cada interface. Testamos a operação da API e isolamos a operação da interface do usuário isoladamente. Os resultados do teste permitirão avaliar se a própria API funciona bem, bem como as interfaces do usuário. Confirme o desenvolvimento bem-sucedido ou formule uma tarefa para desenvolvimento adicional.
Mas os testes diferem. Às vezes, um serviço não mostra degradação imediatamente. Mesmo se executarmos um serviço semelhante aos produtos já lançados no release, para verificação, você poderá carregá-lo com os mesmos dados que são usados “no prod”. Nesse caso, você pode ver a regressão, mas é absolutamente impossível avaliar a perspectiva. Você simplesmente não sabe o que acontecerá se a quantidade de dados aumentar acentuadamente ou a frequência das solicitações aumentar.
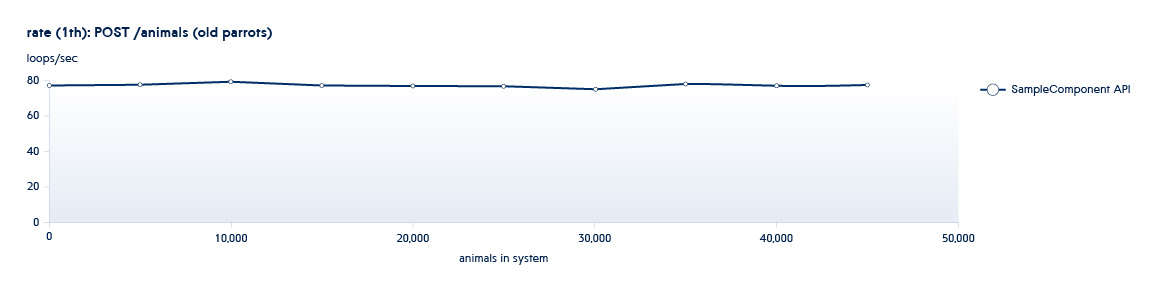
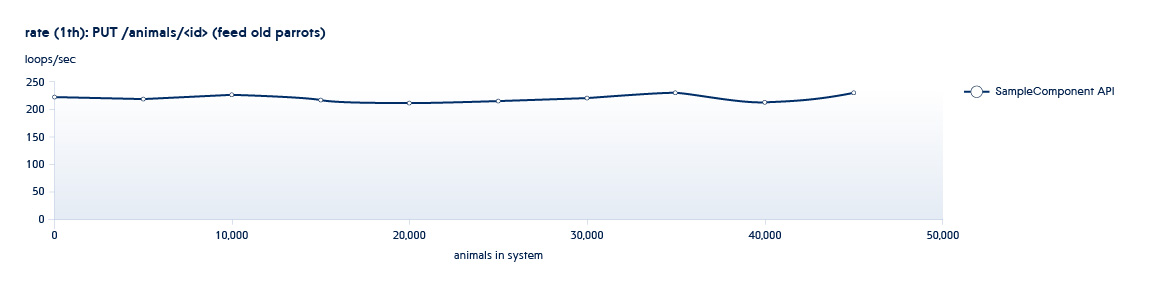
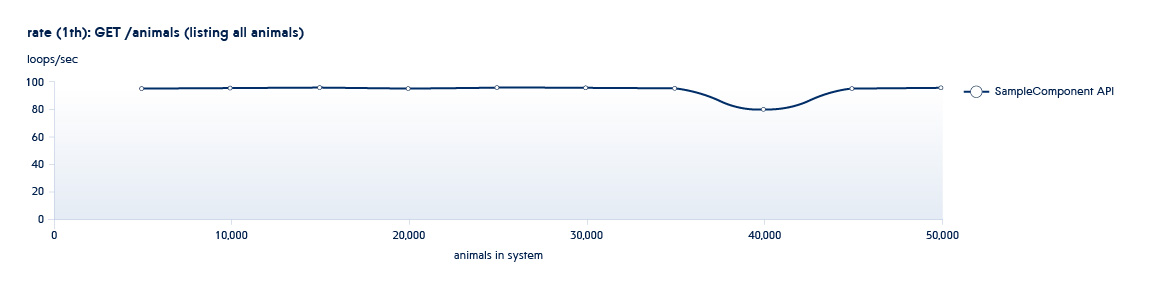
Abaixo está um gráfico mostrando como o número de APIs processadas pelo back-end por segundo muda com o crescimento dos dados no sistema

Suponha que o serviço que estamos testando esteja em um estado típico do início deste planejamento. Nesse caso, mesmo com um pequeno crescimento do sistema, a velocidade dessa API diminuirá bastante.
Para excluir tais situações, aumentamos a quantidade de dados várias vezes, aumentamos o número de threads paralelos para entender como o serviço se comportará se a carga aumentar dramaticamente.
Mas há mais uma nuance. Se o trabalho de um serviço "familiar" muda de acordo com o aumento da quantidade de dados, seu desenvolvimento, o surgimento de novas funções, com novos serviços, a situação é ainda mais complicada. Quando um serviço conceitualmente novo aparece em um produto, ele precisa ser considerado de vários ângulos diferentes. Para essa situação, você precisa preparar conjuntos de dados especiais, realizar testes de carga, sugerindo possíveis casos de uso.
Funcionalidades de teste de desempenho no Acronis
Geralmente, nossos processos de teste ocorrem em um "padrão espiral". Uma das fases de teste envolve o uso da API para aumentar o número de entidades (dimensionamento) e a segunda executando novas operações nos conjuntos de dados existentes (uso). Todos os testes são executados em um número diferente de threads. Por exemplo, temos o serviço Animais e ele possui as seguintes APIs:
POST /animals PUT /animals/<id> GET /animals?filter=criteria
1 e 2 são APIs chamadas em testes de dimensionamento - aumentam o número de novas entidades no sistema.
3 são APIs chamadas na fase de uso. Essa API tem várias opções de filtragem. Nesse sentido, haverá mais de um teste
Assim, executando testes de tamanho e uso iterativamente, obtemos uma imagem da mudança no desempenho do sistema com seu crescimento

Estrutura necessária ...
Para realizar testes em larga escala de um grande número de serviços novos e atualizados, precisávamos de uma estrutura flexível que nos permitisse executar scripts diferentes. E o principal é realmente testar a API, e não apenas criar uma carga nos serviços com operações repetitivas.
O teste de desempenho pode ocorrer tanto em uma carga sintética quanto no uso de um padrão de carga registrado na produção. Ambas as abordagens têm seus prós e contras. Um método com carga real pode ser mais caracterizado como teste de estresse - temos uma imagem real do desempenho do sistema sob essa carga, mas não temos a capacidade de identificar facilmente áreas problemáticas, medir a taxa de transferência dos componentes individualmente, não obtemos os números exatos que a carga os componentes individuais podem suportar. No caso da abordagem sintética, obtemos números exatos, temos grande flexibilidade e podemos consertar facilmente áreas problemáticas e, executando vários scripts de teste em paralelo, podemos reproduzir a carga de estresse. As principais desvantagens da segunda abordagem são os altos custos de mão-de-obra para escrever scripts de teste, bem como o risco crescente de perder algum script importante. Portanto, decidimos seguir o caminho mais difícil.
Portanto, a escolha de uma estrutura foi determinada pela tarefa. E nossa tarefa é:
- Localizando Gargalos da API
- Verifique a resistência a altas cargas
- Avaliar a eficácia do serviço com o crescimento dos volumes de dados
- Identifique erros cumulativos que ocorrem ao longo do tempo
Existem tantas estruturas de desempenho no mercado que podem disparar um grande número de solicitações idênticas. Muitos deles não permitem alterar nada dentro (por exemplo, Apache Benchmark) ou com recursos limitados para descrever scripts (por exemplo, JMeter).
Geralmente usamos scripts mais complexos nos testes. Freqüentemente, as chamadas de API precisam ser feitas seqüencialmente - uma após a outra, ou para alterar os parâmetros de solicitação de acordo com algum tipo de lógica. O exemplo mais simples quando queremos testar uma API REST do formulário
PUT /endpoint/resource/<id>
Nesse caso, você precisa conhecer antecipadamente o <id> do recurso que queremos alterar para medir o tempo de execução da consulta líquida.
Portanto, precisamos da capacidade de criar scripts para executar consultas de teste complexas.
Mais rápido
Como os produtos Acronis são projetados para alta carga, estamos testando APIs em dezenas de milhares de solicitações por segundo. Descobriu-se que nem toda estrutura pode permitir que isso seja feito. Por exemplo, nem sempre é possível usar o Python para os testes, pois, devido às peculiaridades da linguagem, a capacidade de criar uma grande carga multithread é limitada.
Outro problema é o uso de recursos. Por exemplo, vimos primeiro a estrutura Locust, que pode ser executada a partir de vários nós de hardware ao mesmo tempo e obtém um bom desempenho. Mas, ao mesmo tempo, muitos recursos são gastos no trabalho do sistema de teste e sua operação é cara.
Como resultado, escolhemos a estrutura K6, que nos permite descrever scripts em Javascript completo e fornece desempenho acima da média. Essa estrutura está escrita em Go e está rapidamente ganhando popularidade. Por exemplo, no Github, o projeto já recebeu quase 5,5 mil estrelas! O K6 está se desenvolvendo ativamente, e a comunidade já propôs quase 3 mil confirmações, e o projeto tem 50 colaboradores que criaram 36 ramificações de código. Obviamente, o K6 ainda está longe do ideal, mas gradualmente a estrutura está melhorando, e você pode ler sobre sua comparação com o Jmeter
aqui .
Dificuldades e suas soluções
Dada a “juventude” do K6, mesmo após uma escolha equilibrada da estrutura, enfrentamos vários problemas. Por exemplo, antes de testar uma API como / endpoint /, você deve primeiro encontrar esses endpoints de alguma forma. Não podemos usar os mesmos valores, porque, devido ao armazenamento em cache, os resultados estarão incorretos.
Você pode obter os dados necessários de diferentes maneiras:
- Você pode solicitá-los via API
- Você pode usar o acesso direto ao banco de dados
O segundo método funciona mais rápido e, ao usar bancos de dados relacionais, costuma ser muito mais conveniente, pois permite economizar tempo significativo durante longos testes. O único "mas" é que você pode usá-lo apenas se o código de serviço e os testes forem escritos pelas mesmas pessoas. Como para trabalhar com o banco de dados, os testes devem estar sempre atualizados. No entanto, no caso do K6, a estrutura não possui mecanismos de acesso aos bancos de dados. Portanto, eu tive que escrever o módulo apropriado.
Outro problema surge ao testar APIs não idempotentes. Nesse caso, é importante que eles sejam chamados apenas uma vez com os mesmos parâmetros (por exemplo, a API DELETE). Em nossos testes, preparamos os dados com antecedência, na fase de configuração, quando o sistema é configurado e preparado. E durante o teste, são feitas medições de chamadas de API puras, pois não são mais necessários tempo e recursos para a preparação de dados. No entanto, isso levanta o problema de distribuir dados pré-preparados pelos fluxos não sincronizados do teste principal. Esse problema foi resolvido com êxito gravando uma fila de dados interna. Mas esse é um tópico muito grande, que discutiremos nas próximas postagens.
Estrutura pronta
Resumindo, gostaria de observar que não foi fácil encontrar uma estrutura completamente pronta e ainda precisava terminar algumas coisas com as mãos. Hoje, no entanto, temos uma ferramenta adequada para nós, que, levando em consideração as melhorias, nos permite realizar testes complexos, criando uma simulação de altas cargas para garantir o desempenho da API e da GUI em diferentes condições.
No próximo post, falarei sobre como resolvemos o problema de testar um serviço que suporta a conexão simultânea de centenas de milhares de conexões usando recursos mínimos.