Olá pessoal! Meu nome é Vlad e trabalho como cientista de dados na equipe de tecnologias de fala Tinkoff, usada em nosso assistente de voz Oleg.
Neste artigo, gostaria de dar uma breve visão geral das tecnologias de síntese de fala usadas na indústria e compartilhar a experiência de nossa equipe na criação de nosso próprio mecanismo de síntese.

Síntese da fala
A síntese de fala é a criação de som com base em texto. Hoje, esse problema é resolvido por duas abordagens:
- Seleção de unidade [1] ou uma abordagem concatenativa. É baseado na colagem de fragmentos de áudio gravado. Desde o final dos anos 90, há muito tempo é considerado o padrão de fato para o desenvolvimento de mecanismos de síntese de fala. Por exemplo, uma voz tocada pelo método de seleção de unidade pode ser encontrada em Siri [2].
- Síntese paramétrica da fala [3], cuja essência é construir um modelo probabilístico que preveja as propriedades acústicas de um sinal de áudio para um determinado texto.
O discurso dos modelos de seleção de unidades é de alta qualidade, baixa variabilidade e requer uma grande quantidade de dados para treinamento. Ao mesmo tempo, para o treinamento de modelos paramétricos, é necessária uma quantidade muito menor de dados, eles geram entonações mais diversas, mas até recentemente sofreram com uma qualidade de som geral bastante ruim em comparação com a abordagem de seleção de unidades.
No entanto, com o desenvolvimento de tecnologias de aprendizado profundo, os modelos de síntese paramétrica alcançaram um crescimento significativo em todas as métricas de qualidade e são capazes de criar uma fala praticamente indistinguível da fala humana.
Métricas de qualidade
Antes de falar sobre quais modelos de síntese de fala são melhores, você precisa determinar as métricas de qualidade pelas quais os algoritmos serão comparados.
Como o mesmo texto pode ser lido de várias formas, a priori não existe a maneira correta de pronunciar uma frase específica. Portanto, frequentemente as métricas para a qualidade da síntese da fala são subjetivas e dependem da percepção do ouvinte.
A métrica padrão é o MOS (pontuação média de opinião), uma avaliação média da naturalidade da fala, fornecida pelos avaliadores para áudio sintetizado em uma escala de 1 a 5. Um significa som completamente implausível e cinco significa fala que é indistinguível da humana. Os registros de pessoas reais geralmente recebem cerca de 4,5, e um valor maior que 4 é considerado bastante alto.
Como funciona a síntese da fala
O primeiro passo para construir qualquer sistema de síntese de fala é coletar dados para treinamento. Geralmente, são gravações de áudio de alta qualidade nas quais o locutor lê frases especialmente selecionadas. O tamanho aproximado do conjunto de dados necessário para os modelos de seleção de unidades de treinamento é de 10 a 20 horas de fala pura [2], enquanto que para os métodos paramétricos da rede neural, o limite superior é de aproximadamente 25 horas [4, 5].
Discutimos as duas tecnologias de síntese.
Seleção de unidade
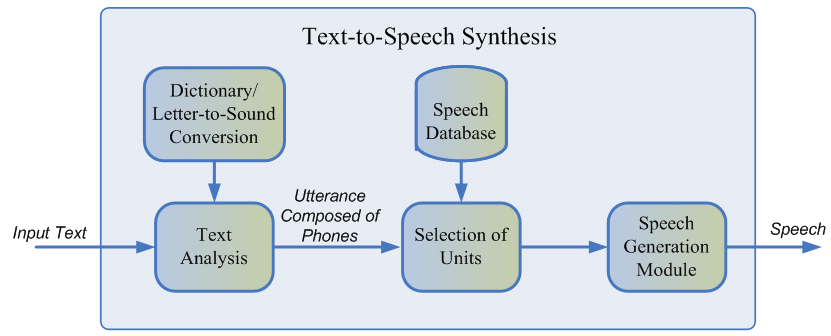
Normalmente, a fala gravada do falante não pode cobrir todos os casos possíveis nos quais a síntese será usada. Portanto, a essência do método é dividir toda a base de áudio em pequenos fragmentos chamados unidades, que são então coladas usando um pós-processamento mínimo. Normalmente, as unidades são unidades mínimas de linguagem acústica, como meio-telefone ou diphons [2].
Todo o processo de geração consiste em duas etapas: o front end da PNL, responsável por extrair a representação lingüística do texto, e o back-end, que calcula a função de penalidade unitária para os recursos lingüísticos especificados. O front end da PNL inclui:
- A tarefa de normalizar o texto é a tradução de todos os caracteres não alfabéticos (números, sinais de porcentagem, moedas e assim por diante) em suas representações verbais. Por exemplo, "5%" deve ser convertido para "cinco por cento".
- Extrair recursos linguísticos de um texto normalizado: representação de fonemas, estresse, partes do discurso e assim por diante.
Normalmente, o front-end da PNL é implementado usando regras prescritas manualmente para um idioma específico, mas recentemente houve um viés crescente em relação ao uso de modelos de aprendizado de máquina [7].
A penalidade estimada pelo subsistema de back-end é a soma do custo-alvo, ou a correspondência da representação acústica da unidade para um fonema específico, e o custo de concatenação, ou seja, a adequação da conexão de duas unidades vizinhas. Para avaliar as funções finas, pode-se usar as regras ou o modelo acústico já treinado da síntese paramétrica [2]. A seleção da sequência mais ótima de unidades do ponto de vista das penalidades definidas acima ocorre usando o algoritmo de Viterbi [1].
Valores aproximados dos modelos de seleção de unidade MOS para o idioma inglês: 3.7-4.1 [2, 4, 5].
Vantagens da abordagem de seleção de unidades:
- O som natural.
- Geração de alta velocidade.
- Tamanho pequeno dos modelos - isso permite que você use a síntese diretamente no seu dispositivo móvel.
Desvantagens:
- O discurso sintetizado é monótono, não contém emoções.
- Artefatos de colagem característicos.
- Requer uma base de treinamento suficientemente grande de dados de áudio para cobrir todos os tipos de contextos.
- Em princípio, não pode gerar som que não seja encontrado no conjunto de treinamento.
Síntese paramétrica da fala
A abordagem paramétrica é baseada na idéia de construir um modelo probabilístico que estima a distribuição das características acústicas de um determinado texto.
O processo de geração da fala na síntese paramétrica pode ser dividido em quatro etapas:
- O front end da PNL é o mesmo estágio de pré-processamento de dados da abordagem de seleção de unidades, cujo resultado é um grande número de recursos linguísticos sensíveis ao contexto.
- Modelo de duração que prevê a duração do fonema.
- Um modelo acústico que restaura a distribuição de recursos acústicos sobre os lingüísticos. Os recursos acústicos incluem valores de frequência fundamentais, representação espectral do sinal e assim por diante.
- Um vocoder que traduz recursos acústicos em uma onda sonora.
Para duração do treinamento e modelos acústicos, podem ser utilizados modelos ocultos de Markov [3], redes neurais profundas ou suas variedades recorrentes [6]. Um vocoder tradicional é um algoritmo baseado no modelo de filtro de origem [3], que assume que a fala é o resultado da aplicação de um filtro de ruído linear ao sinal original.
A qualidade geral da fala dos métodos paramétricos clássicos é bastante baixa devido ao grande número de suposições independentes sobre a estrutura do processo de geração de som.
No entanto, com o advento das tecnologias de aprendizado profundo, tornou-se possível treinar modelos de ponta a ponta que predizem diretamente sinais acústicos por letra. Por exemplo, as redes neurais Tacotron [4] e Tacotron 2 [5] inserem uma sequência de letras e retornam o espectrograma de giz usando o algoritmo seq2seq [8]. Assim, os passos 1 a 3 da abordagem clássica são substituídos por uma única rede neural. O diagrama abaixo mostra a arquitetura da rede Tacotron 2, que obtém uma qualidade de som bastante alta.
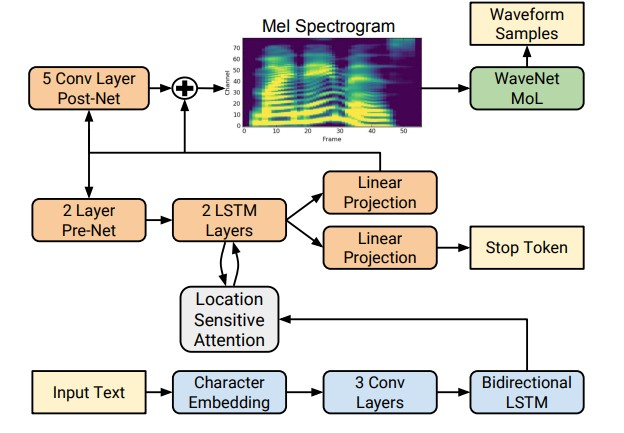
Outro fator de um aumento significativo na qualidade da fala sintetizada foi o uso de vocoders de rede neural em vez de algoritmos de processamento de sinal digital.
O primeiro desses vocoder foi a rede neural WaveNet [9], que sequencialmente, passo a passo, previu a amplitude da onda sonora.
Devido ao uso de um grande número de camadas convolucionais com lacunas para capturar mais contexto e pular a conexão na arquitetura de rede, foi possível obter uma melhoria de cerca de 10% no MOS em comparação aos modelos de seleção de unidade. O diagrama abaixo mostra a arquitetura da rede WaveNet.

A principal desvantagem do WaveNet é a baixa velocidade associada a um circuito de amostragem de sinal serial. Esse problema pode ser resolvido usando a otimização de engenharia para uma arquitetura específica do ferro ou substituindo o esquema de amostragem por um mais rápido.
Ambas as abordagens foram implementadas com sucesso na indústria. O primeiro é no Tinkoff.ru e, como parte da segunda abordagem, o Google introduziu a rede Parallel WaveNet [10] em 2017, cujas realizações são usadas no Google Assistant.
Valores aproximados de MOS para métodos de rede neural: 4.4-4.5 [5, 11], ou seja, a fala sintetizada praticamente não difere da fala humana.
Vantagens da síntese paramétrica:
- Som natural e suave ao usar a abordagem de ponta a ponta.
- Maior variedade na entonação.
- Use menos dados que os modelos de seleção de unidade.
Desvantagens:
- Baixa velocidade em comparação com a seleção da unidade.
- Grande complexidade computacional.
Como funciona a síntese de fala Tinkoff
Como se segue na revisão, os métodos de síntese paramétrica da fala baseados em redes neurais são atualmente significativamente superiores em qualidade à abordagem de seleção de unidades e são muito mais simples de desenvolver. Portanto, para construir nosso próprio mecanismo de síntese, nós os usamos.
Para os modelos de treinamento, foram utilizadas cerca de 25 horas de fala pura de um palestrante profissional. Os textos de leitura foram especialmente selecionados de forma a abranger a fonética do discurso coloquial. Além disso, para adicionar mais variedade à síntese na entonação, solicitamos ao locutor que lesse textos com uma expressão dependendo do contexto.
A arquitetura da nossa solução é conceitualmente parecida com esta:
- Front-end da PNL, que inclui a normalização de texto de rede neural e um modelo para colocar pausas e tensões.
- Tacotron 2 aceitando letras como entrada.
- WaveNet autoregressivo, trabalhando em tempo real na CPU.
Graças a essa arquitetura, nosso mecanismo gera fala expressiva de alta qualidade em tempo real, não requer a construção de um dicionário de fonemas e possibilita o controle de tensões em palavras individuais. Exemplos de áudio sintetizado podem ser ouvidos clicando no link .
Referências:
[1] AJ Hunt, AW Black. Seleção de unidades em um sistema de síntese de fala concatenativa usando um banco de dados de fala grande, ICASSP, 1996.
[2] T. Capes, P. Coles, A. Conkie, L. Golipour, A. Hadjitarkhani, Q. Hu, N. Huddleston, M. Hunt, J. Li, M. Neeracher, K. Prahallad, T. Raitio R. Rasipuram, G. Townsend, B. Williamson, D. Winarsky, Z. Wu, H. Zhang. Sistema Text-to-Speech de Seleção de Unidade Guiada por Aprendizagem Profunda no Dispositivo Siri, Interspeech, 2017.
[3] H. Zen, K. Tokuda, AW Black. Síntese estatística paramétrica da fala, Comunicação de fala, vol. 51, n. 11, pp. 1039-1064, 2009.
[4] Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark, Rif A. Saurous . Tacotron: Em direção à síntese de fala de ponta a ponta.
[5] Jonathan Shen, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis, Yonghui Wu. Síntese natural de TTS condicionando WaveNet em previsões de espectrograma de mel.
[6] Heiga Zen, Andrew Sênior, Mike Schuster. Síntese estatística paramétrica da fala usando redes neurais profundas.
[7] Hao Zhang, Richard Sproat, Axel H. Ng, Felix Stahlberg, Xiaochang Peng, Kyle Gorman e Brian Roark. Modelos Neurais de Normalização de Texto para Aplicações de Fala.
[8] Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Sequence to Sequence Learning com redes neurais.
[9] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior e Koray Kavukcuoglu. WaveNet: um modelo generativo para áudio bruto.
[10] Aaron van den Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, George van den Driessche, Edward Lockhart, Luis C. Cobo, Florian Stimberg, Norman Casagrande, Dominik Grewe, Seb Noury, Sander Dieleman Erich Elsen, Nal Kalchbrenner, Heiga Zen, Alex Graves, Helen King, Tom Walters, Dan Belov e Demis Hassabis. WaveNet paralelo: síntese rápida de voz de alta fidelidade.
[11] Wei Ping Kainan Peng Jitong Chen. ClariNet: Geração de ondas paralelas em conversão de texto em fala de ponta a ponta.
[12] Dario Rethage, Jordi Pons, Xavier Serra. Um Wavenet para a fala Denoising.