Desempenho no .NET Core

Olá pessoal! Este artigo é uma coleção de práticas recomendadas que eu e meus colegas utilizamos há muito tempo ao trabalhar em diferentes projetos.
Informações sobre a máquina na qual os cálculos foram realizados:BenchmarkDotNet = v0.11.5, SO = Windows 10.0.18362
CPU Intel Core i5-8250U 1,60 GHz (Kaby Lake R), 1 CPU, 8 núcleos lógicos e 4 físicos
SDK do .NET Core = 3.0.100
[Host]: .NET Core 2.2.7 (CoreCLR 4.6.28008.02, CoreFX 4.6.28008.03), RyuJIT de 64 bits
Núcleo: .NET Core 2.2.7 (CoreCLR 4.6.28008.02, CoreFX 4.6.28008.03), RyuJIT de 64 bits
[Host]: .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), RyuJIT de 64 bits
Núcleo: .NET Core 3.0.0 (CoreCLR 4.700.19.46205, CoreFX 4.700.19.46214), RyuJIT de 64 bits
Trabalho = Core Runtime = Core
ToList vs ToArray e Ciclos
Planejei preparar essas informações com o lançamento do .NET Core 3.0, mas elas ficaram à minha frente, não quero roubar a fama de outra pessoa e copiar as informações de outra pessoa; portanto, apenas apontarei um
link para um bom artigo em que a comparação é detalhada .
Só quero apresentar minhas medidas e resultados, adicionando loops reversos a eles para os amantes do "estilo C ++" de escrever loops.
Código:public class Bench { private List<int> _list; private int[] _array; [Params(100000, 10000000)] public int N; [GlobalSetup] public void Setup() { const int MIN = 1; const int MAX = 10; Random random = new Random(); _list = Enumerable.Repeat(0, N).Select(i => random.Next(MIN, MAX)).ToList(); _array = _list.ToArray(); } [Benchmark] public int ForList() { int total = 0; for (int i = 0; i < _list.Count; i++) { total += _list[i]; } return total; } [Benchmark] public int ForListFromEnd() { int total = 0;t for (int i = _list.Count-1; i > 0; i--) { total += _list[i]; } return total; } [Benchmark] public int ForeachList() { int total = 0; foreach (int i in _list) { total += i; } return total; } [Benchmark] public int ForeachArray() { int total = 0; foreach (int i in _array) { total += i; } return total; } [Benchmark] public int ForArray() { int total = 0; for (int i = 0; i < _array.Length; i++) { total += _array[i]; } return total; } [Benchmark] public int ForArrayFromEnd() { int total = 0; for (int i = _array.Length-1; i > 0; i--) { total += _array[i]; } return total; } }
O desempenho no .NET Core 2.2 e 3.0 é quase idêntico. Aqui está o que eu consegui obter no .NET Core 3.0:
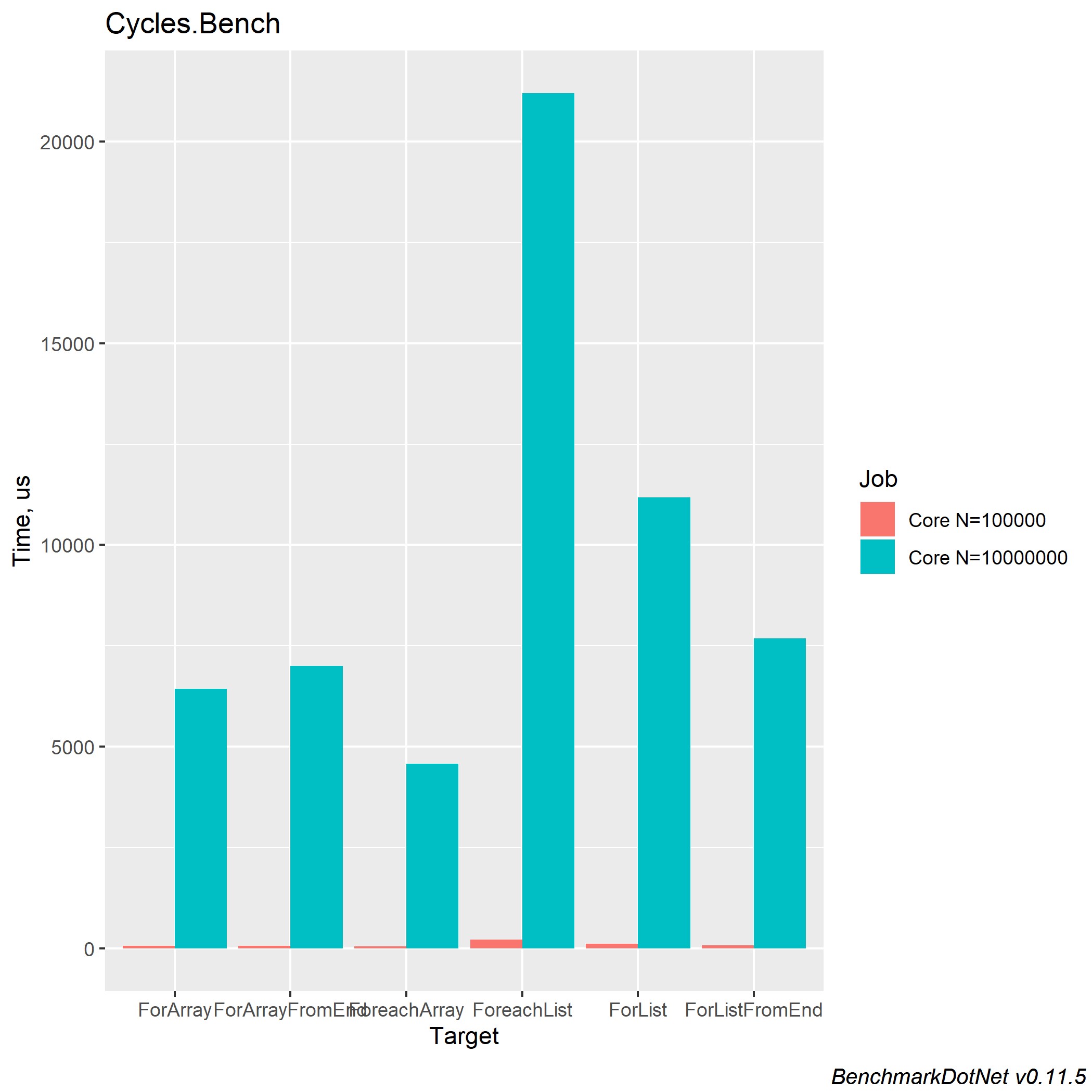
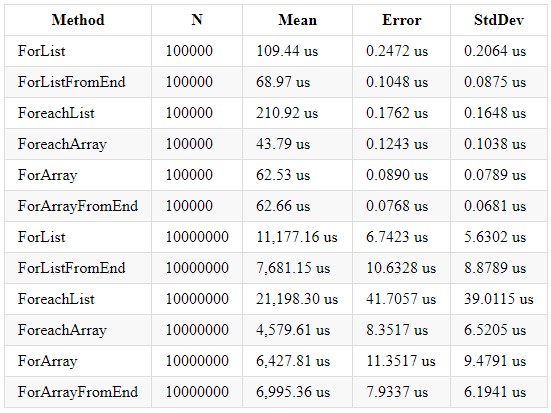
Podemos concluir que o processamento de loop de uma coleção do tipo Array é mais rápido, devido às otimizações internas e alocação explícita do tamanho da coleção. Também é importante lembrar que uma coleção do tipo Lista tem suas vantagens e você deve usar a coleção desejada, dependendo dos cálculos necessários. Mesmo se você escrever a lógica de trabalhar com ciclos, não esqueça que esse é um loop comum e também está sujeito a uma possível otimização dos ciclos. Um artigo apareceu no habr por um longo tempo:
https://habr.com/en/post/124910/ . Ainda é relevante e recomendado para leitura.
Arremesso
Há um ano, trabalhei em uma empresa em um projeto legado, naquele projeto estava dentro do escopo normal lidar com a validação de campo por meio de uma construção try-catch-throw. Eu já entendi que essa era uma lógica comercial doentia do projeto, então tentei não usar esse design, se possível. Mas vamos ver qual é a má abordagem para lidar com erros com esse design. Escrevi um pequeno código para comparar as duas abordagens e fotografar os “bancos” de cada opção.
Código: public bool ContainsHash() { bool result = false; foreach (var file in _files) { var extension = Path.GetExtension(file); if (_hash.Contains(extension)) result = true; } return result; } public bool ContainsHashTryCatch() { bool result = false; try { foreach (var file in _files) { var extension = Path.GetExtension(file); if (_hash.Contains(extension)) result = true; } if(!result) throw new Exception("false"); } catch (Exception e) { result = false; } return result; }
Os resultados no .NET Core 3.0 e Core 2.2 têm um resultado semelhante (.NET Core 3.0):
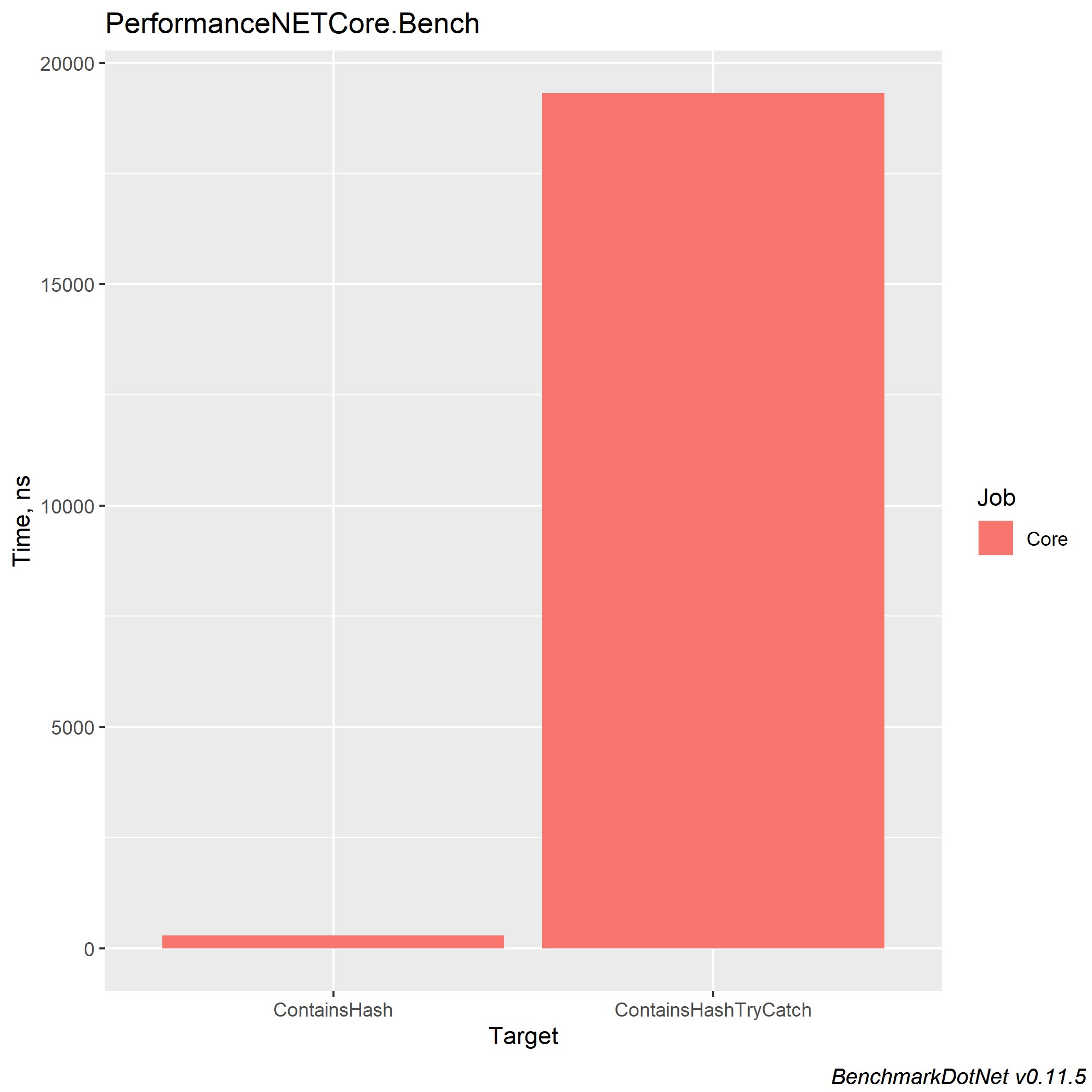
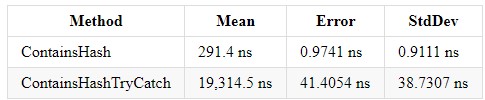
Try catch complica a compreensão do código e aumenta o tempo de execução do seu programa. Mas se você precisar dessa construção, não deverá inserir as linhas de código das quais não é esperado o tratamento de erros - isso facilitará a compreensão do código. De fato, não é o tratamento de exceções que carrega o sistema, mas gera os próprios erros através da nova construção de exceção de lançamento.
Lançar exceções é mais lento que qualquer classe que coleta um erro no formato desejado. Se você está processando um formulário ou qualquer dado e obviamente sabe qual erro deve ser, por que não processá-lo?
Você não deve escrever throw new Exception () se essa situação não for excepcional.
Manipular e lançar uma exceção é muito caro !!!ToLower, ToLowerInvariant, ToUpper, ToUpperInvariant
Durante seus 5 anos de experiência na plataforma .NET, ele conheceu muitos projetos que usavam correspondência de string. Também vi a seguinte imagem: havia uma solução Enterprise com muitos projetos, cada um deles realizando comparações de strings de maneiras diferentes. Mas o que vale a pena usar e como unificá-lo? No CLR de Richter via C #, li que ToUpperInvariant () é mais rápido que ToLowerInvariant ().
Recorte do livro:

Obviamente, eu não acreditei nisso e decidi realizar alguns testes naquela época no .NET Framework, e o resultado me chocou - mais de 15% de aumento de desempenho. Mais tarde, ao chegar ao trabalho, mostrei essas medidas aos meus superiores e dei acesso à fonte. Depois disso, 2 dos 14 projetos foram alterados para novas medições e, como esses dois projetos existiam para processar grandes tabelas de excel, o resultado foi mais do que significativo para o produto.
Também apresento medidas para diferentes versões do .NET Core, para que cada um de vocês possa fazer uma escolha na direção da melhor solução. E só quero acrescentar que, na empresa em que trabalho, usamos ToUpper () para comparar strings.
Código: public const string defaultString = "VXTDuob5YhummuDq1PPXOHE4PbrRjYfBjcHdFs8UcKSAHOCGievbUItWhU3ovCmRALgdZUG1CB0sQ4iMj8Z1ZfkML2owvfkOKxBCoFUAN4VLd4I8ietmlsS5PtdQEn6zEgy1uCVZXiXuubd0xM5ONVZBqDu6nOVq1GQloEjeRN8jXrj0MVUexB9aIECs7caKGddpuut3"; [Benchmark] public bool ToLower() { return defaultString.ToLower() == defaultString.ToLower(); } [Benchmark] public bool ToLowerInvariant() { return defaultString.ToLowerInvariant() == defaultString.ToLowerInvariant(); } [Benchmark] public bool ToUpper() { return defaultString.ToUpper() == defaultString.ToUpper(); } [Benchmark] public bool ToUpperInvariant() { return defaultString.ToUpperInvariant() == defaultString.ToUpperInvariant(); } ; public const string defaultString = "VXTDuob5YhummuDq1PPXOHE4PbrRjYfBjcHdFs8UcKSAHOCGievbUItWhU3ovCmRALgdZUG1CB0sQ4iMj8Z1ZfkML2owvfkOKxBCoFUAN4VLd4I8ietmlsS5PtdQEn6zEgy1uCVZXiXuubd0xM5ONVZBqDu6nOVq1GQloEjeRN8jXrj0MVUexB9aIECs7caKGddpuut3"; [Benchmark] public bool ToLower() { return defaultString.ToLower() == defaultString.ToLower(); } [Benchmark] public bool ToLowerInvariant() { return defaultString.ToLowerInvariant() == defaultString.ToLowerInvariant(); } [Benchmark] public bool ToUpper() { return defaultString.ToUpper() == defaultString.ToUpper(); } [Benchmark] public bool ToUpperInvariant() { return defaultString.ToUpperInvariant() == defaultString.ToUpperInvariant(); }
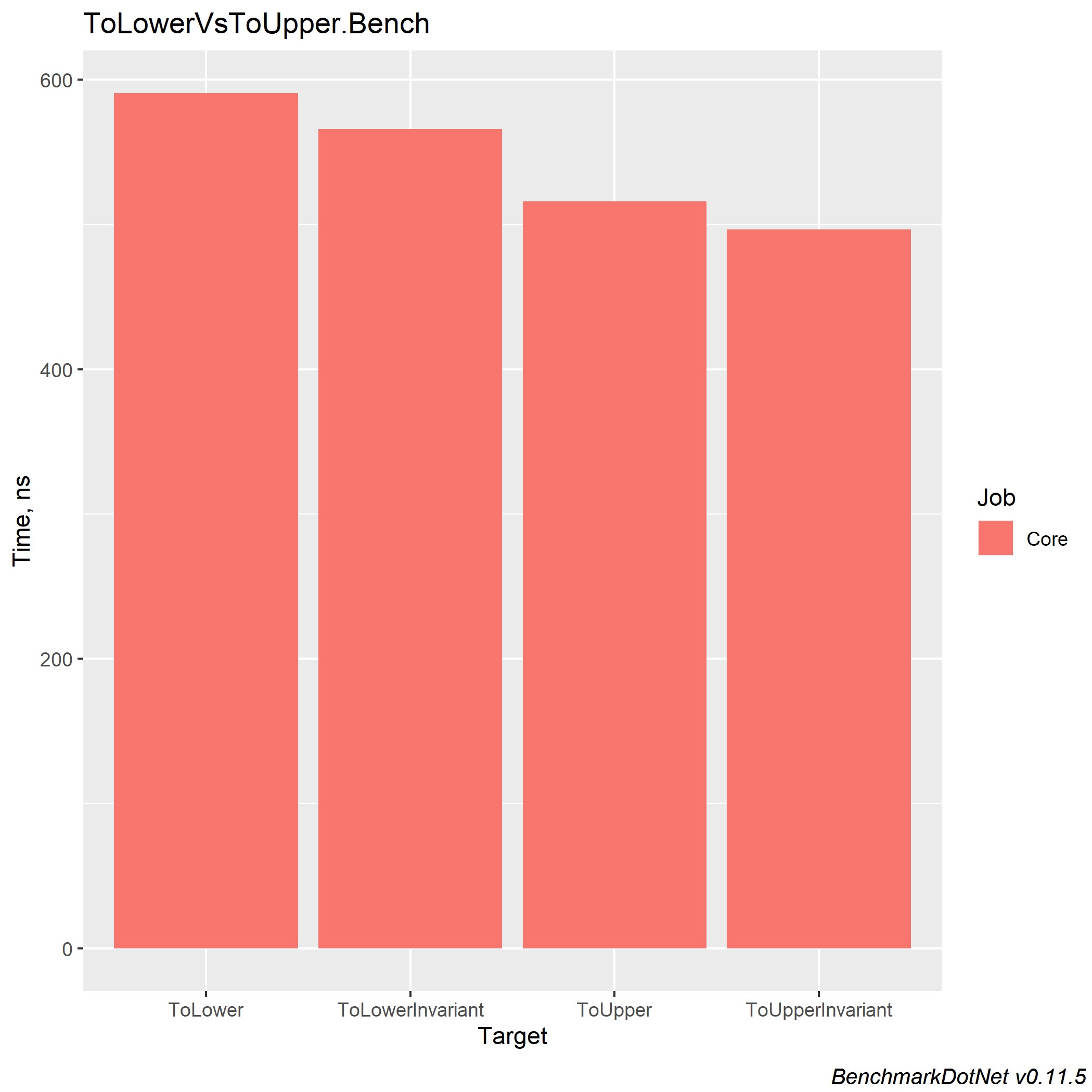
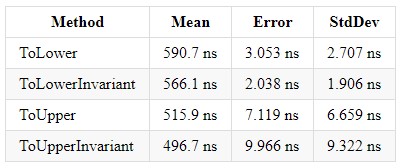
No .NET Core 3.0, o ganho para cada um desses métodos é ~ x2 e equilibra as implementações entre si.
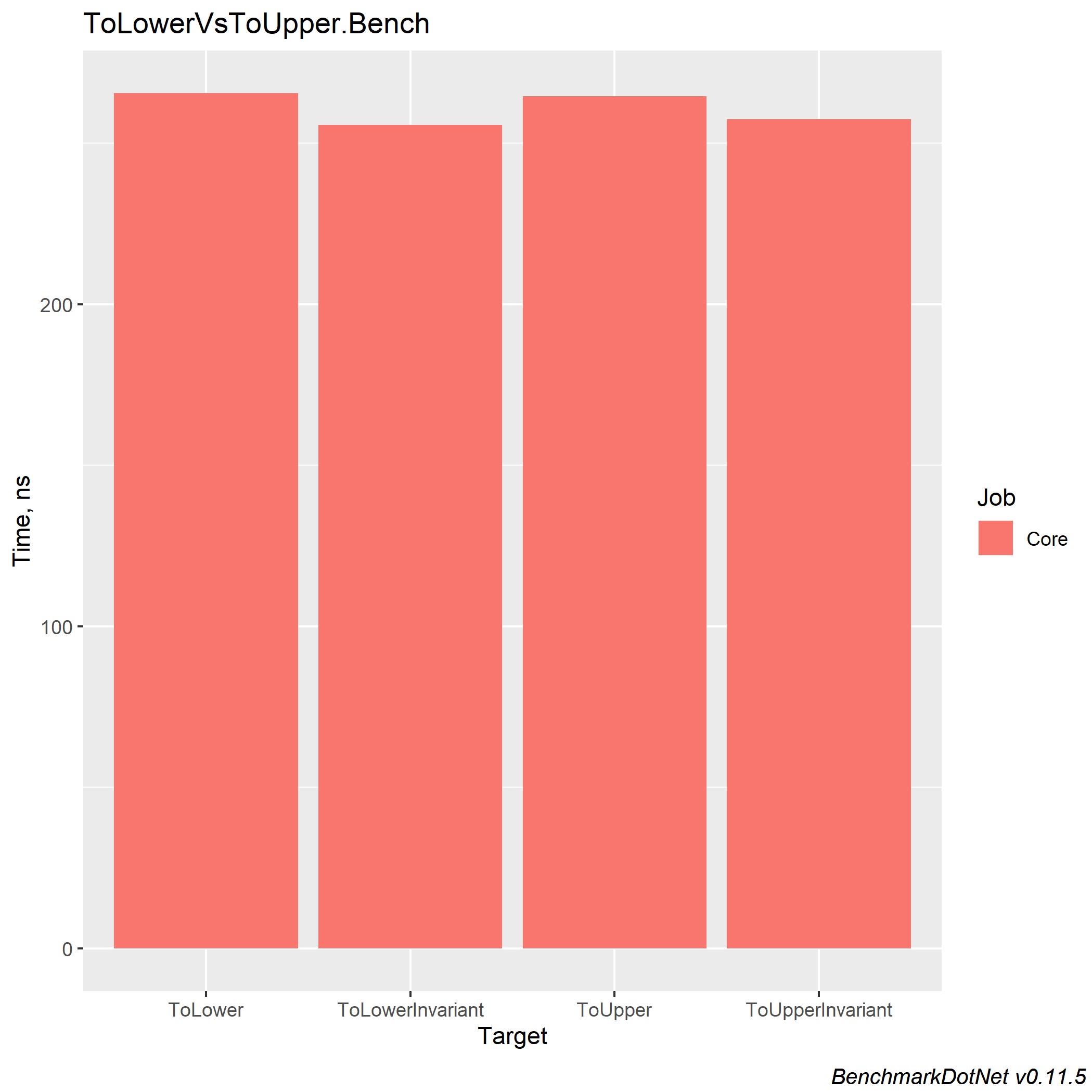
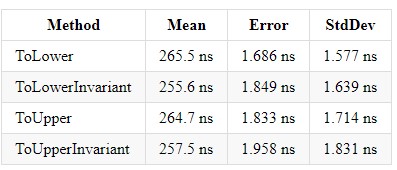
Compilação de camadas
No meu último artigo, descrevi brevemente essa funcionalidade, gostaria de corrigir e complementar minhas palavras. A compilação multinível acelera o tempo de inicialização da sua solução, mas você sacrifica que partes do seu código serão compiladas em uma versão mais otimizada em segundo plano, o que pode levar a uma pequena sobrecarga. Com o advento do NET Core 3.0, o tempo de criação de projetos com compilação de camadas permitiu diminuir e corrigir bugs relacionados a essa tecnologia. Anteriormente, essa tecnologia causava erros nas primeiras solicitações no ASP.NET Core e congelava durante a primeira compilação no modo de compilação multinível. Atualmente, ele está ativado por padrão no .NET Core 3.0, mas você pode desativá-lo conforme desejado. Se você está na posição de líder de equipe, sênior, intermediário ou é o chefe do departamento, deve entender que o rápido desenvolvimento do projeto aumenta o valor da equipe e essa tecnologia permitirá economizar o tempo dos desenvolvedores e o tempo de trabalho do projeto.
Subir de nível .NET
Atualize seu .NET Framework / .NET Core. Freqüentemente, cada nova versão oferece um aumento adicional no desempenho e adiciona novos recursos.
Mas quais são exatamente os benefícios? Vejamos alguns deles:
- No .NET Core 3.0, foram introduzidas imagens R2R que reduzirão o tempo de inicialização dos aplicativos .NET Core.
- A versão 2.2 introduziu a compilação de camadas, graças à qual os programadores gastam menos tempo lançando um projeto.
- Suporte para o novo .NET Standard.
- Suporte para a nova versão da linguagem de programação.
- A otimização, a cada nova versão, é otimizada pelas bibliotecas base Collection / Struct / Stream / String / Regex e muito mais. Se você atualizar do .NET Framework para o .NET Core, obterá um grande aumento de desempenho imediatamente. Por exemplo, anexo um link a uma parte das otimizações adicionadas no .NET Core 3.0: https://devblogs.microsoft.com/dotnet/performance-improvements-in-net-core-3-0/

Conclusão
Ao escrever código, você deve prestar atenção a vários aspectos do seu projeto e usar as funções da sua linguagem e plataforma de programação para obter o melhor resultado. Ficarei feliz se você compartilhar seu conhecimento relacionado à otimização no .NET.
Link do Github