
As redes neurais na visão computacional estão se desenvolvendo ativamente, muitas tarefas ainda estão longe de serem resolvidas. Para se destacar em seu campo, basta seguir os influenciadores no Twitter e ler os artigos relevantes em arXiv.org. Mas tivemos a oportunidade de ir à Conferência Internacional sobre Visão Computacional (ICCV) 2019. Este ano, é realizado na Coréia do Sul. Agora queremos compartilhar com os leitores de Habr que vimos e aprendemos.
Muitos de nós da Yandex: desenvolvedores de veículos não tripulados, pesquisadores e os envolvidos nas tarefas de CV nos serviços chegaram. Mas agora queremos introduzir um ponto de vista um pouco subjetivo de nossa equipe - o laboratório de inteligência de máquinas (Yandex MILAB). Outros caras provavelmente olharam para a conferência de seu ângulo.
O que o laboratório fazRealizamos projetos experimentais relacionados à geração de imagens e músicas para fins de entretenimento. Estamos especialmente interessados em redes neurais que permitem alterar o conteúdo do usuário (para uma foto, essa tarefa é chamada manipulação de imagem).
Um exemplo do resultado do nosso trabalho da conferência YaC 2019.
Existem muitas conferências científicas, mas as principais conferências A * se destacam, onde geralmente são publicados artigos sobre as tecnologias mais interessantes e importantes. Não existe uma lista exata de conferências A *, aqui está um exemplo e incompleto: NeurIPS (anteriormente NIPS), ICML, SIGIR, WWW, WSDM, KDD, ACL, CVPR, ICCV, ECCV. Os três últimos são especializados no tópico CV.
Visão geral do ICCV: pôsteres, tutoriais, oficinas, stands
1075 trabalhos foram aceitos na conferência, os participantes foram 7.500. 103 pessoas vieram da Rússia, artigos de funcionários da Yandex, Skoltech, Samsung AI Center Moscow e Samara University. Este ano, não muitos pesquisadores de ponta visitaram o ICCV, mas aqui, por exemplo, Alexey (Alyosha) Efros, que sempre reúne muitas pessoas:

Em todas essas conferências, os artigos são apresentados na forma de pôsteres (
mais sobre o formato), e os melhores também na forma de breves relatórios.
Aqui está parte do trabalho da Rússia Nos tutoriais, você pode mergulhar em alguma área, assemelha-se a uma palestra em uma universidade. É lido por uma pessoa, geralmente sem falar sobre trabalhos específicos. Exemplo de um tutorial legal (
Michael Brown, Noções básicas sobre cores e o pipeline de processamento de imagens na câmera para o Computer Vision ):

Nas oficinas, pelo contrário, eles falam sobre artigos. Geralmente, esse é um trabalho em algum tópico restrito, histórias de líderes de laboratório sobre todo o trabalho mais recente dos alunos ou artigos que não foram aceitos na conferência principal.
As empresas patrocinadoras vêm ao ICCV com estandes. Este ano, Google, Facebook, Amazon e muitas outras empresas internacionais chegaram, além de um grande número de startups - coreanas e chinesas. Havia muitas startups especializadas em marcação de dados. Há apresentações nas bancas, você pode levar mercadorias e fazer perguntas. As empresas patrocinadoras têm festas para a caça. Eles conseguem se convencer dos recrutadores de que você está interessado e que você pode ser potencialmente entrevistado. Se você publicou um artigo (ou, além disso, fez uma apresentação com ele), iniciou ou terminou o doutorado - isso é uma vantagem, mas às vezes você pode concordar com uma posição, fazendo perguntas interessantes aos engenheiros da empresa.
Tendências
A conferência permite que você dê uma olhada em toda a área do currículo. Pelo número de pôsteres de um tópico específico, você pode avaliar a qualidade do tópico. Algumas conclusões imploram pelas palavras-chave:

Tiro zero, tiro único, tiro curto, auto-supervisionado e semi-supervisionado: novas abordagens para problemas estudados há muito tempo
As pessoas aprendem a usar os dados com mais eficiência. Por exemplo, no
FUNIT, você pode gerar expressões faciais de animais que não estavam no conjunto de treinamento (aplicando várias fotos de referência no aplicativo). As idéias do Deep Image Prior foram desenvolvidas e agora as redes
GAN podem ser treinadas em uma imagem - falaremos sobre isso mais adiante
nos destaques . Você pode usar a auto-supervisão para pré-treinamento (resolvendo um problema para o qual você pode sintetizar dados alinhados, por exemplo, para prever o ângulo de rotação de uma imagem) ou aprender ao mesmo tempo a partir de dados marcados e não marcados. Nesse sentido, a coroa da criação pode ser considerada um artigo
S4L: Aprendizagem semi-supervisionada auto-supervisionada . Mas o pré-treinamento no ImageNet
nem sempre ajuda.

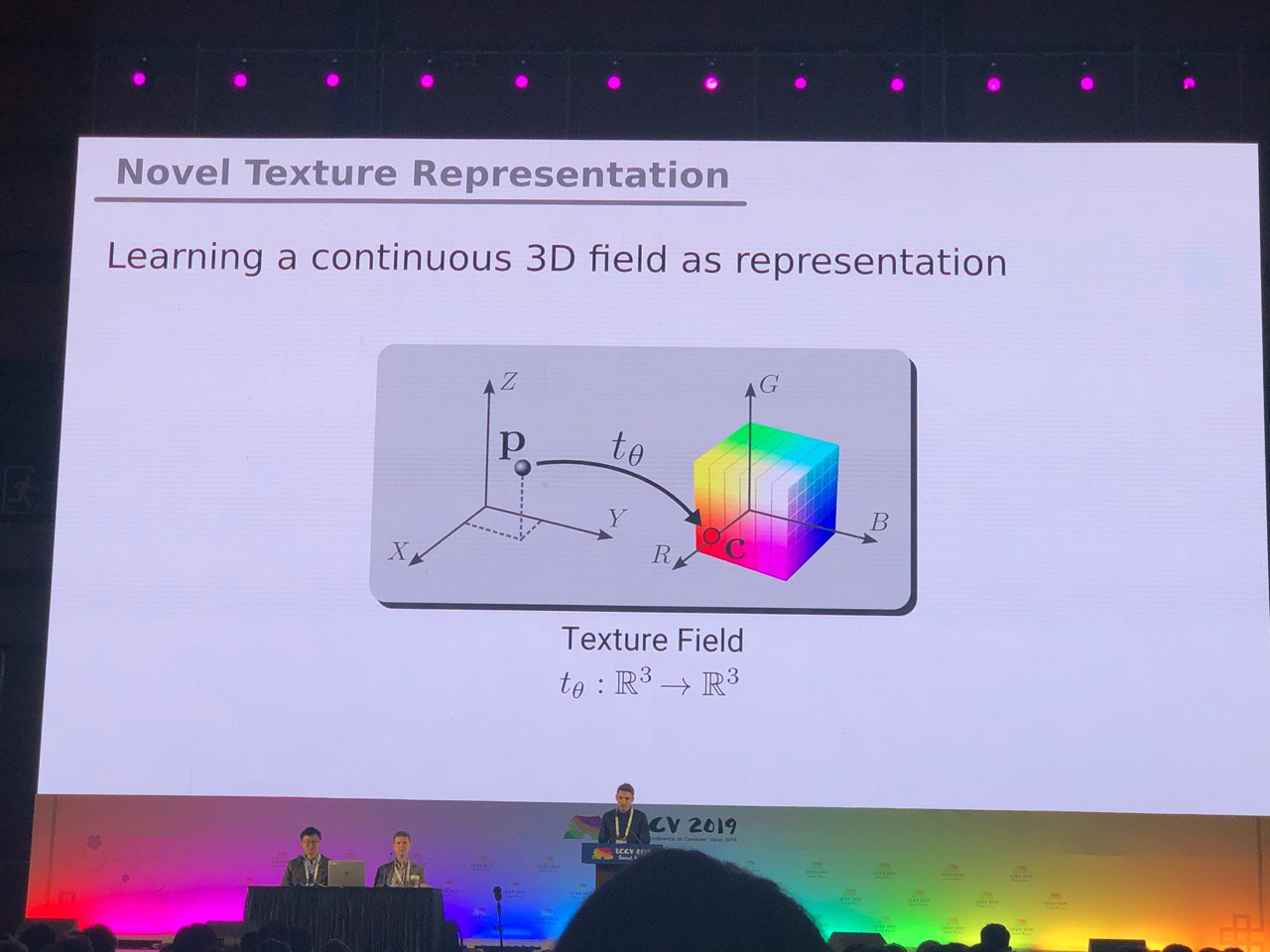
3D e 360 °
As tarefas, geralmente resolvidas para fotos (segmentação, detecção), exigem pesquisas adicionais para modelos 3D e vídeos panorâmicos. Vimos muitos artigos sobre a conversão de RGB e
RGB-D para 3D. Algumas tarefas, como determinar a pose de uma pessoa (estimativa de pose), são resolvidas mais naturalmente se formos para modelos tridimensionais. Mas até agora não há consenso sobre exatamente como representar modelos 3D - na forma de uma grade, uma nuvem de pontos,
voxels ou
SDF . Aqui está outra opção:
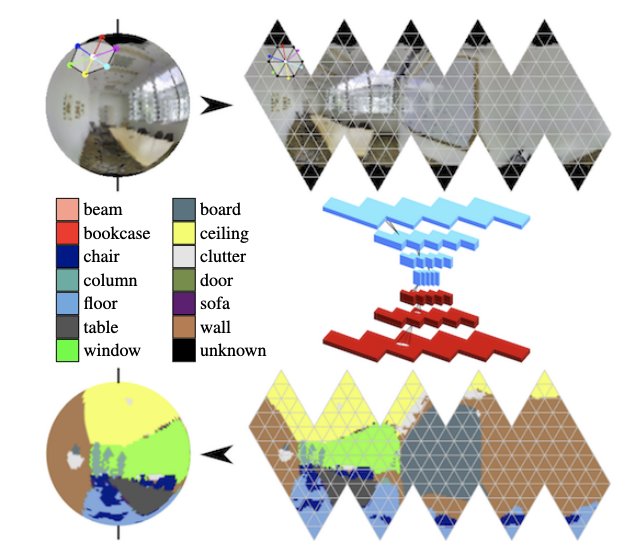
Nos panoramas, as convoluções na esfera estão se desenvolvendo ativamente (consulte
Segmentação semântica com reconhecimento de orientação nas esferas de icosaedro ) e a busca por objetos-chave no quadro.
Definição de postura e previsão de movimentos humanos
Para determinar a pose em 2D, já existe sucesso - agora o foco mudou para o trabalho com várias câmeras e em 3D. Por exemplo, você pode determinar o esqueleto através da parede, acompanhando as alterações no sinal Wi-Fi à medida que ele passa pelo corpo humano.
Muito trabalho foi feito na área de detecção de ponto-chave manual. Novos conjuntos de dados apareceram, incluindo aqueles baseados em vídeo com diálogos de duas pessoas - agora você pode prever gestos com as mãos por áudio ou texto de uma conversa! O mesmo progresso foi feito nas tarefas de avaliação do olhar.

Você também pode destacar um grande conjunto de trabalhos relacionados à previsão de movimento humano (por exemplo,
Previsão de movimento humano por meio de pintura espacial e temporal ou
Previsão estruturada ajuda a modelagem de movimento humano em 3D ). A tarefa é importante e, com base nas conversas com os autores, é mais frequentemente usada para analisar o comportamento dos pedestres na direção autônoma.
Manipular pessoas em fotos e vídeos, provadores virtuais
A principal tendência é alterar as imagens faciais em termos de parâmetros interpretados. Idéias:
busca profunda em uma imagem, mudança de expressão por renderização de face (
PuppetGAN ), alteração de parâmetros de
avanço (por exemplo,
idade ). As transferências de estilo passaram do título do tópico para a aplicação do trabalho. Outra história - provadores virtuais, eles quase sempre funcionam mal,
aqui está um exemplo de uma demonstração.


Geração de esboço / gráfico
O desenvolvimento da idéia “Deixe a grade gerar algo com base na experiência anterior” tornou-se diferente: “Vamos mostrar à grade qual opção nos interessa”.
O SC-FEGAN permite que você faça a pintura guiada: o usuário pode desenhar parte do rosto na área apagada da imagem e obter a imagem restaurada, dependendo da renderização.

Em um dos 25 artigos da Adobe para ICCV, dois GANs são combinados: um desenha um esboço para o usuário, o outro gera uma imagem foto-realista a partir do esboço (
página do projeto ).

No início da geração de imagens, os gráficos não eram necessários, mas agora eles foram transformados em um recipiente de conhecimento sobre a cena. O prêmio de Menções Honrosas do ICCV de Melhor Artigo também foi concedido ao artigo
Especificando Atributos e Relações de Objetos na Geração de Cena Interativa . Em geral, você pode usá-los de diferentes maneiras: gerar gráficos a partir de figuras ou figuras e textos a partir de gráficos.
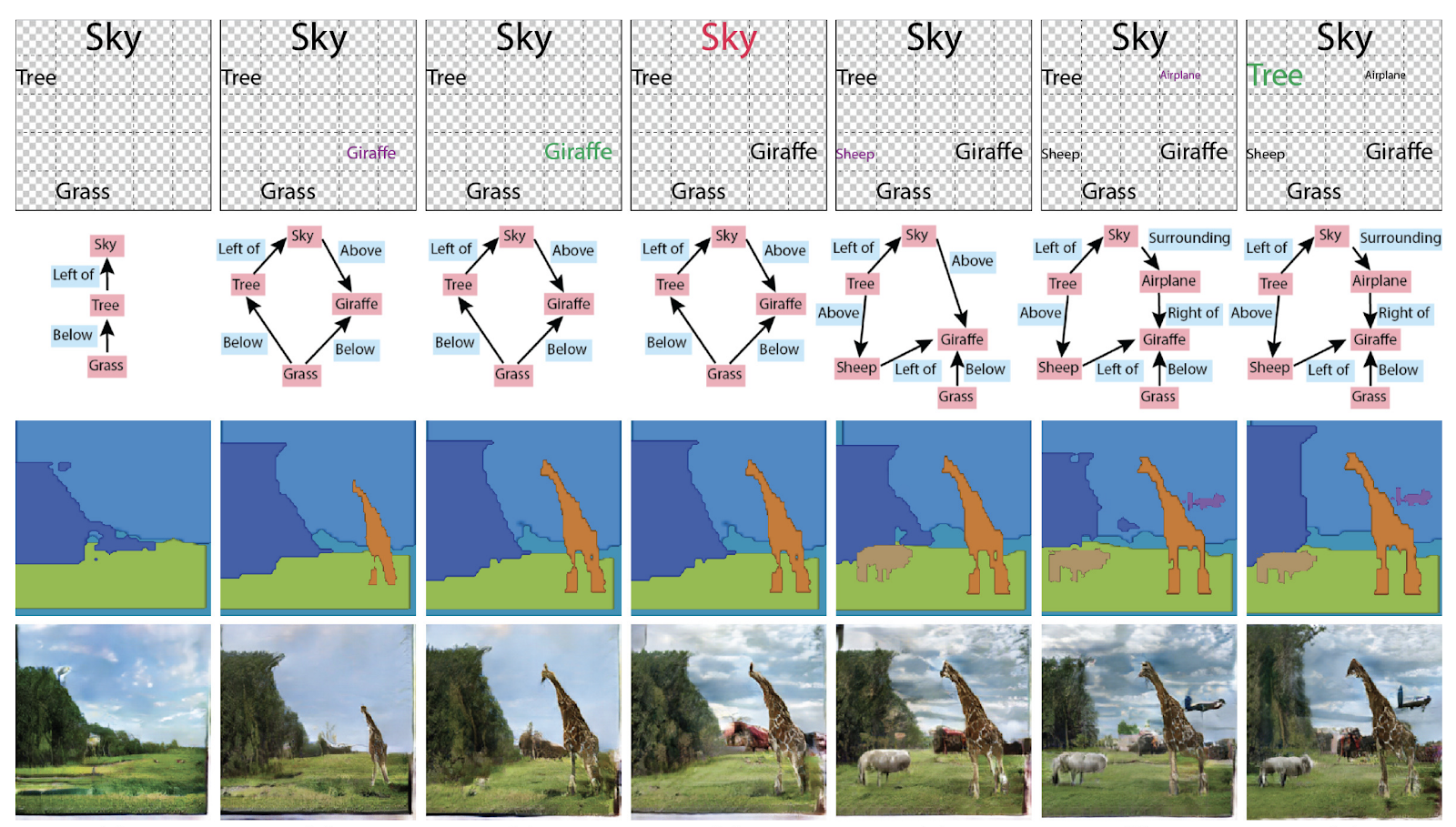
Re-identificação de pessoas e máquinas, contando o número de multidões (!)
Muitos artigos são dedicados a rastrear pessoas e
reidentificar pessoas e máquinas. Mas o que nos surpreendeu foi um monte de artigos sobre como contar pessoas no meio da multidão e todos da China.
Mas o Facebook, pelo contrário, anonimamente a foto. Além disso, ele faz isso de uma maneira interessante: ensina a rede neural a gerar um rosto sem detalhes únicos - semelhantes, mas não tanto, a ponto de serem detectados corretamente pelos sistemas de reconhecimento facial.

Proteção Contra Ataques Adversários
Com o desenvolvimento de aplicativos de visão computacional no mundo real (em veículos não tripulados, no reconhecimento de rostos), a questão da confiabilidade de tais sistemas surge com mais frequência. Para fazer pleno uso do CV, você precisa ter certeza de que o sistema é resistente a ataques adversários - portanto, não havia menos artigos sobre proteção contra eles do que sobre os próprios ataques. Muito trabalho consistiu em explicar as previsões da rede (mapa de saliências) e medir a confiança no resultado.
Tarefas combinadas
Na maioria das tarefas com um objetivo, as possibilidades de melhorar a qualidade estão quase esgotadas; uma das novas áreas de maior crescimento da qualidade é ensinar as redes neurais a resolver vários problemas semelhantes ao mesmo tempo. Exemplos:
- previsão de ações + previsão de fluxo óptico,
- apresentação de vídeo + representação da língua (
VideoBERT ),
-
super-resolução + HDR .
E havia artigos sobre segmentação, determinando a postura e a reidentificação dos animais!

Destaques
Quase todos os artigos eram conhecidos com antecedência, o texto estava disponível no arXiv.org. Portanto, a apresentação de trabalhos como Everybody Dance Now, FUNIT, Image2StyleGAN parece bastante estranha - esses são trabalhos muito úteis, mas não são novos. Parece que o processo clássico de publicação científica está falhando aqui - a ciência está se desenvolvendo muito rápido.
É muito difícil determinar os melhores trabalhos - existem muitos, os assuntos são diferentes. Vários artigos receberam
prêmios e referências .
Queremos destacar trabalhos que são interessantes em termos de manipulação de imagens, pois esse é o nosso tópico. Eles se mostraram bastante novos e interessantes para nós (não pretendemos ser objetivos).
SinGAN (prêmio de melhor artigo) e InGAN
SinGAN:
página do projeto ,
arXiv ,
código .
InGAN:
página do projeto ,
arXiv ,
código .
O desenvolvimento da idéia do Deep Image Prior por Dmitry Ulyanov, Andrea Vedaldi e Victor Lempitsky. Em vez de treinar a GAN em um conjunto de dados, as redes aprendem com fragmentos da mesma imagem para lembrar as estatísticas dentro dela. A rede treinada permite editar e animar fotos (SinGAN) ou gerar novas imagens de qualquer tamanho a partir das texturas da imagem original, mantendo a estrutura local (InGAN).
SinGAN:

InGAN:

Vendo o que um GAN não pode gerar
Página do projeto .
As redes neurais geradoras de imagens geralmente recebem um vetor de ruído aleatório como entrada. Em uma rede treinada, muitos vetores de entrada formam um espaço, pequenos movimentos ao longo dos quais levam a pequenas mudanças na imagem. Usando a otimização, você pode resolver o problema inverso: encontre um vetor de entrada adequado para uma imagem do mundo real. O autor mostra que quase nunca é possível encontrar uma imagem completamente correspondente em uma rede neural quase nunca. Alguns objetos na imagem não são gerados (aparentemente, devido à grande variabilidade desses objetos).
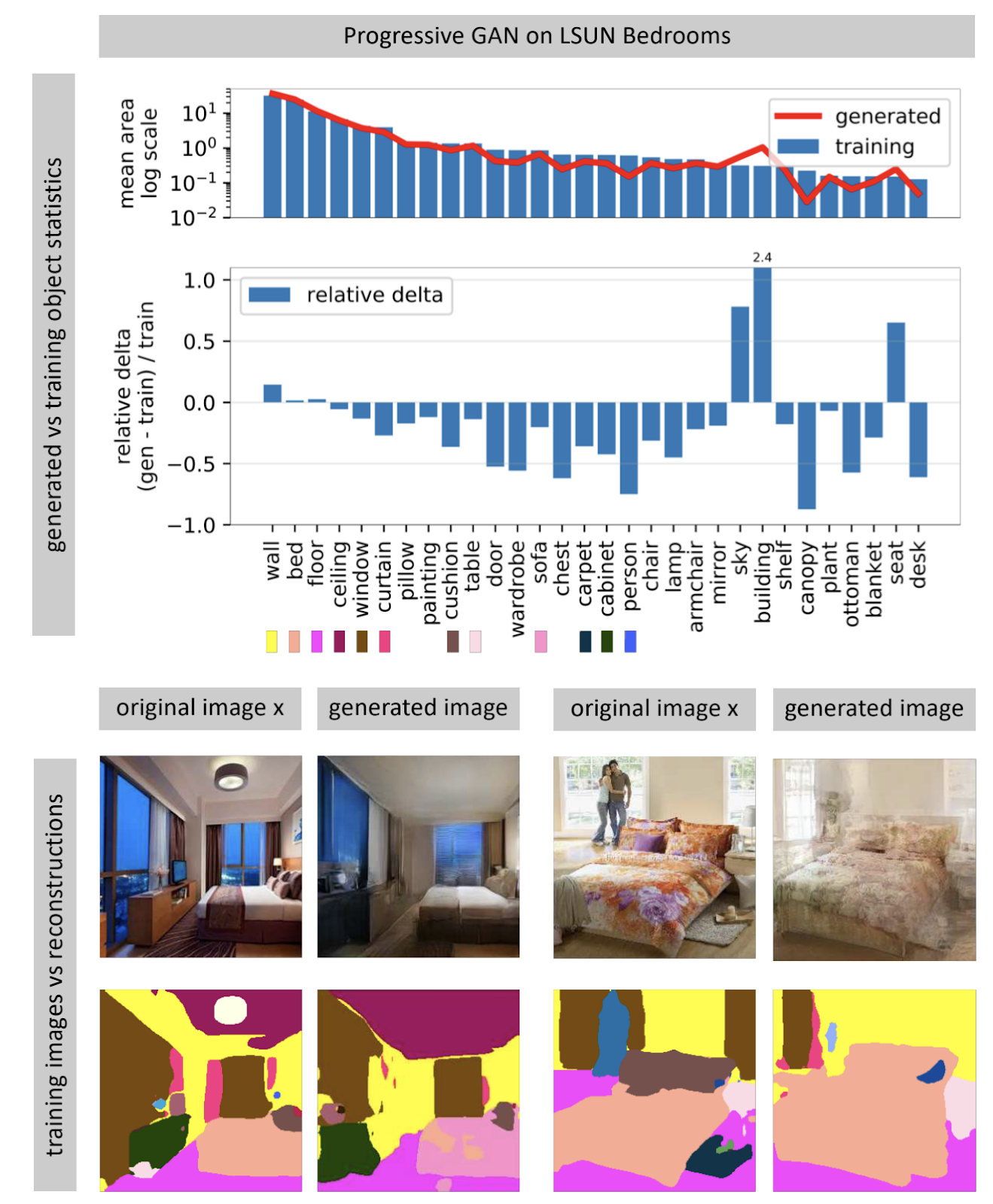
O autor propõe que o GAN não cubra todo o espaço das imagens, mas apenas alguns subconjuntos recheados de buracos, como queijo. Quando tentamos encontrar fotos do mundo real, sempre falhamos, porque a GAN ainda gera fotos não muito reais. Você pode superar as diferenças entre imagens reais e geradas apenas alterando o peso da rede, ou seja, treinando-a novamente para uma foto específica.

Quando a rede é treinada novamente para uma foto específica, você pode tentar realizar várias manipulações com esta imagem. No exemplo abaixo, uma janela foi adicionada à foto e a rede gerou reflexões adicionalmente no conjunto da cozinha. Isso significa que a rede após o treinamento para a fotografia não perdeu a capacidade de ver a conexão entre os objetos da cena.

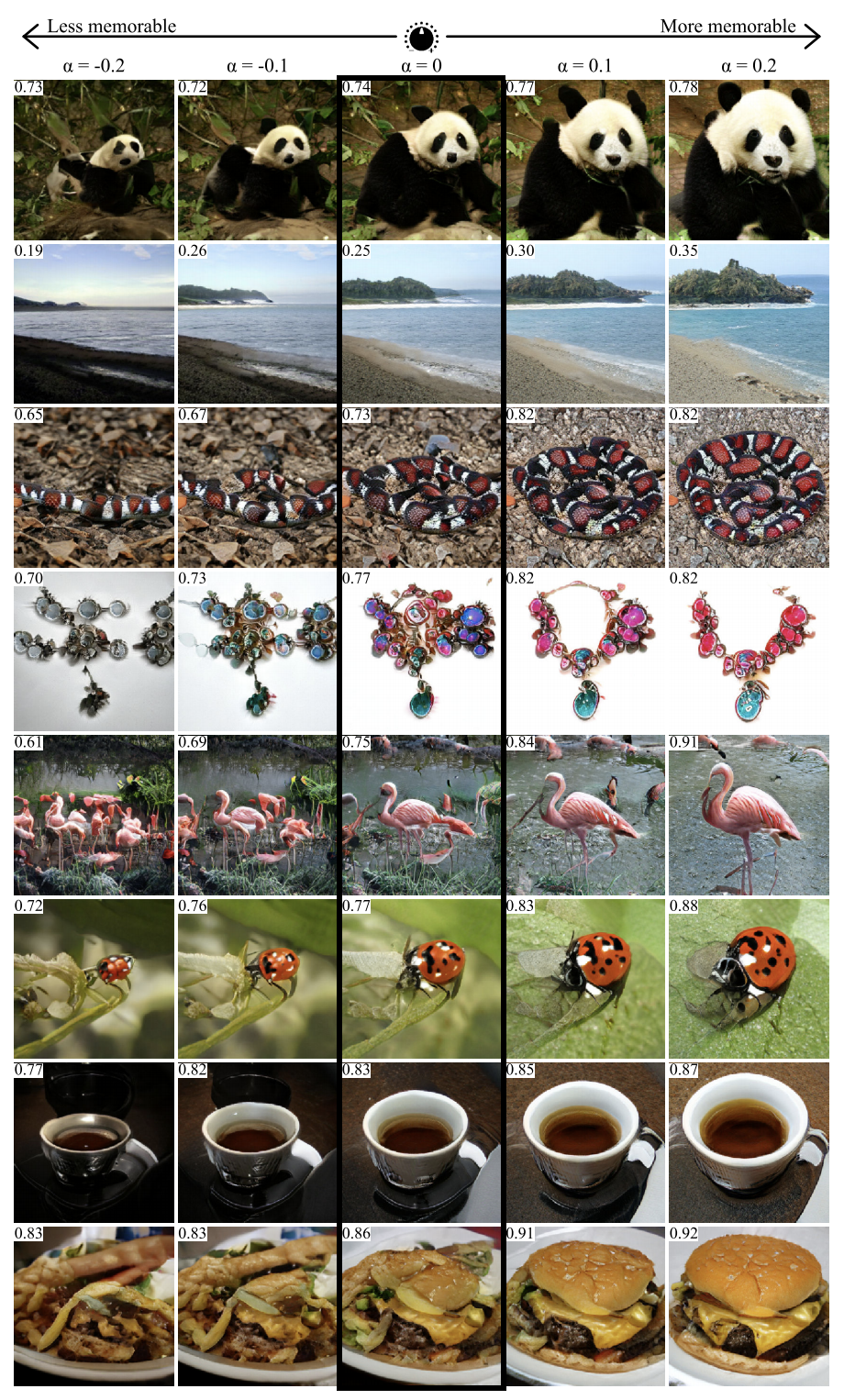
GANalyze: Em direção a definições visuais de propriedades da imagem cognitiva
Página do projeto ,
arXiv .
Usando a abordagem deste trabalho, você pode visualizar e analisar o que a rede neural aprendeu. Os autores propõem o treinamento da GAN para criar imagens para as quais a rede gerará determinadas previsões. Várias redes foram usadas como exemplos no artigo, incluindo o MemNet, que prevê a memorização de fotos. Aconteceu que, para uma melhor memorização, o objeto na foto deve:
- estar mais perto do centro
- ter uma forma redonda ou quadrada e estrutura simples,
- estar em um fundo uniforme,
- conter olhos expressivos (pelo menos para fotos de cães),
- seja mais brilhante, mais rico, em alguns casos - mais vermelho.
Liquid Warping GAN: Uma Estrutura Unificada para Imitação de Movimento Humano, Transferência de Aparência e Síntese de Novas Visões
Página do projeto ,
arXiv ,
código .
Pipeline para gerar fotos de pessoas a partir de uma foto. Os autores mostram exemplos bem-sucedidos de transferir o movimento de uma pessoa para outra, transferir roupas entre as pessoas e gerar novas perspectivas de uma pessoa - tudo a partir de uma fotografia. Diferentemente dos trabalhos anteriores, aqui, para criar condições, não são usados pontos-chave em 2D (pose), mas uma malha 3D do corpo (pose + forma). Os autores também descobriram como transferir informações da imagem original para a imagem gerada (Liquid Warping Block). Os resultados parecem decentes, mas a resolução da imagem resultante é de apenas 256x256. Para comparação, o vid2vid, que apareceu há um ano, é capaz de gerar uma resolução de 2048x1024, mas precisa de até 10 minutos de gravação de vídeo como um conjunto de dados.

FSGAN: Troca de Agnóstico de Rosto e Reencenação
Página do projeto ,
arXiv .
A princípio, parece que nada de incomum: deepfake com qualidade mais ou menos normal. Mas a principal conquista do trabalho é a substituição de rostos em uma imagem. Ao contrário dos trabalhos anteriores, era necessário treinamento em uma variedade de fotografias de uma pessoa em particular. O pipeline acabou por ser complicado (reconstituição e segmentação, exibir interpolação, pintura, mistura) e com muitos hacks técnicos, mas o resultado vale a pena.

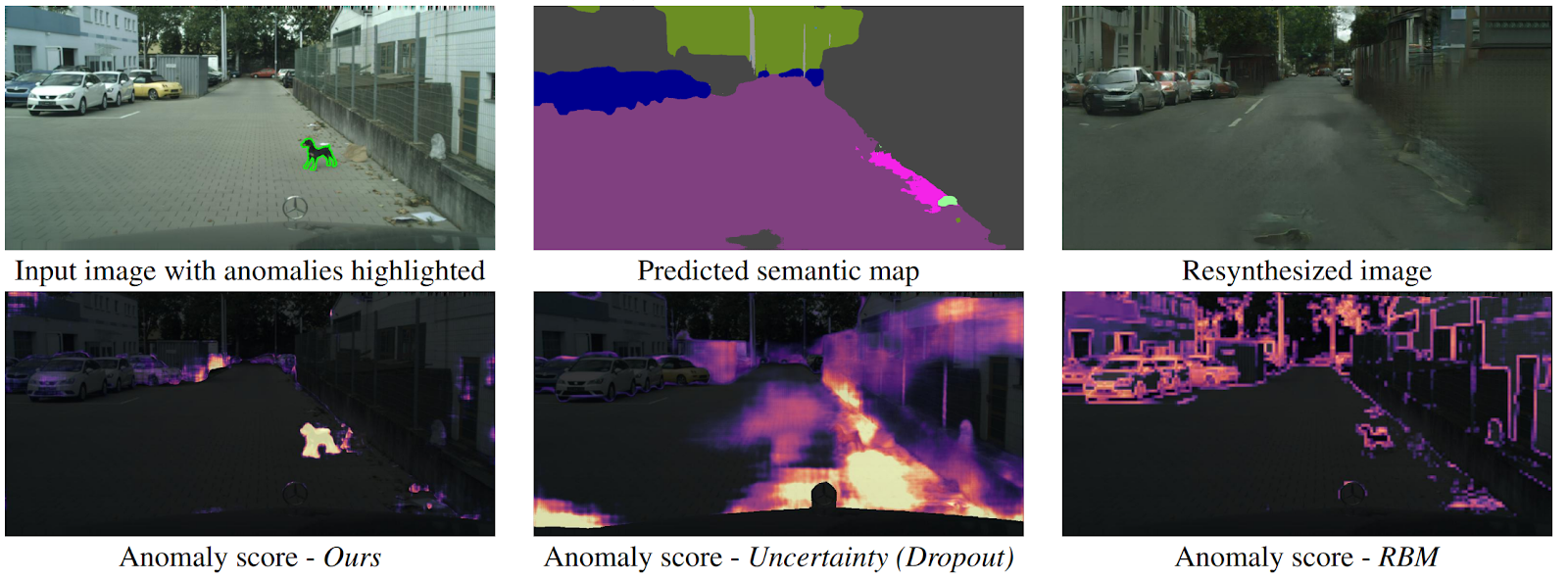
Detectando o inesperado via ressíntese de imagens
arXiv .
Como um drone pode entender que um objeto apareceu repentinamente na frente dele e não se enquadra em nenhuma classe de segmentação semântica? Existem vários métodos, mas os autores oferecem um algoritmo novo e intuitivo que funciona melhor que seus antecessores. A segmentação semântica é prevista a partir da imagem de entrada da estrada. Ele é alimentado no GAN (pix2pixHD), que tenta restaurar a imagem original apenas do mapa semântico. Anomalias que não caem em nenhum dos segmentos diferem significativamente na origem e na imagem gerada. Em seguida, três imagens (inicial, segmentação e reconstruída) são enviadas para outra rede, que prevê anomalias. O conjunto de dados para isso foi gerado a partir do conhecido conjunto de dados Cityscapes, alterando acidentalmente as classes na segmentação semântica. Curiosamente, nesse cenário, um cachorro parado no meio da estrada, mas segmentado corretamente (o que significa que há uma classe para ele), não é uma anomalia, pois o sistema conseguiu reconhecê-lo.
Conclusão
Antes da conferência, é importante saber quais são seus interesses científicos, quais discursos gostaria de fazer e com quem conversar. Então tudo será muito mais produtivo.
O ICCV é principalmente de rede. Você entende que existem instituições e cientistas de ponta, começa a entender isso, a conhecer pessoas. E você pode ler artigos sobre o arXiv - e, a propósito, é muito legal que você não possa ir a lugar algum em busca de conhecimento.
Além disso, na conferência, você pode mergulhar profundamente em tópicos que não estão perto de você, veja as tendências. Bem, escreva uma lista de artigos para ler. Se você é um estudante, esta é uma oportunidade para você se familiarizar com um cientista em potencial, se você é do setor, depois com um novo empregador e se a empresa se mostrar.
Inscreva-se em
@loss_function_porn ! Este é um projeto pessoal: estamos juntos com a
karfly . Todo o trabalho que gostamos durante a conferência, postamos aqui:
@loss_function_live .