
Em um
artigo anterior, examinamos o cluster RabbitMQ para tolerância a falhas e alta disponibilidade. Agora vamos nos aprofundar no Apache Kafka.
Aqui, a unidade de replicação é uma partição. Cada tópico possui uma ou mais seções. Cada seção tem um líder com ou sem seguidores. Ao criar um tópico, o número de partições e a taxa de replicação são indicados. O valor usual é 3, o que significa três observações: um líder e dois seguidores.
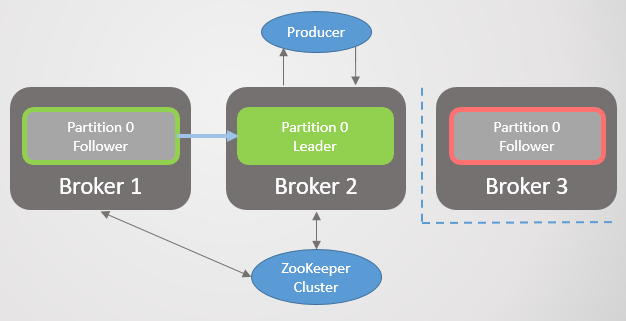
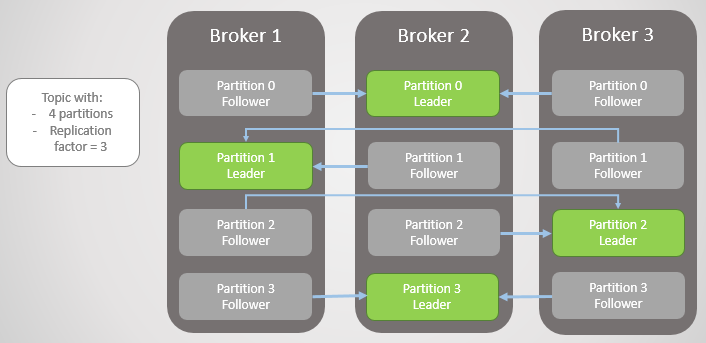 Fig. 1. Quatro seções são distribuídas entre três corretores
Fig. 1. Quatro seções são distribuídas entre três corretoresTodas as solicitações de leitura e gravação vão para o líder. Os seguidores enviam periodicamente solicitações ao líder para receber as mensagens mais recentes. Os consumidores nunca se voltam para os seguidores, estes existem apenas para redundância e tolerância a falhas.

Seção com falha
Quando um corretor cai, os líderes de várias seções geralmente falham. Em cada um deles, o seguidor de outro nó se torna o líder. De fato, esse nem sempre é o caso, pois o fator de sincronização também afeta: se há seguidores sincronizados e, se não, é permitida a transição para uma réplica não sincronizada. Mas, por enquanto, não vamos complicar.
O corretor 3 sai da rede - e para a seção 2 um novo líder no corretor 2 é eleito.
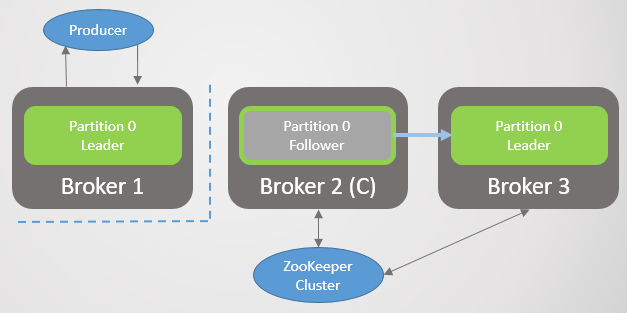
 Fig. 2. O corretor 3 morre e seu seguidor no corretor 2 é eleito como o novo líder da seção 2
Fig. 2. O corretor 3 morre e seu seguidor no corretor 2 é eleito como o novo líder da seção 2Então o corretor 1 sai e a seção 1 também perde seu líder, cuja função vai para o corretor 2.
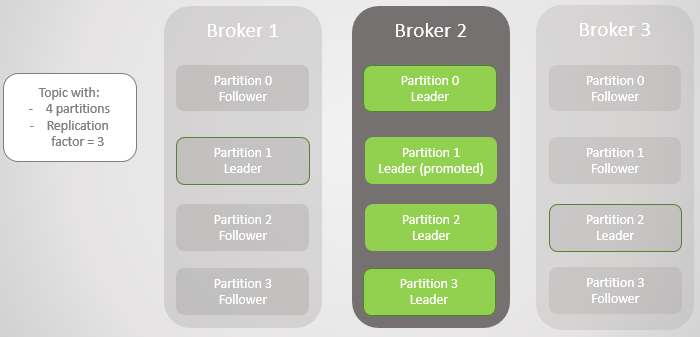 Fig. 3. Existe apenas um corretor restante. Todos os líderes estão no mesmo intermediário de redundância zero.
Fig. 3. Existe apenas um corretor restante. Todos os líderes estão no mesmo intermediário de redundância zero.Quando o broker 1 retorna à rede, ele adiciona quatro seguidores, fornecendo alguma redundância para cada seção. Mas todos os líderes ainda permaneceram no corretor 2.
 Fig. 4. Os líderes permanecem no broker 2
Fig. 4. Os líderes permanecem no broker 2Quando o broker 3 aumenta, retornamos a três réplicas por seção. Mas todos os líderes ainda estão no corretor 2.
 Fig. 5. Posicionamento desequilibrado dos líderes após a restauração dos corretores 1 e 3
Fig. 5. Posicionamento desequilibrado dos líderes após a restauração dos corretores 1 e 3Kafka tem uma ferramenta para melhorar o reequilíbrio de líderes do que o RabbitMQ. Lá, era necessário usar um plug-in ou script de terceiros que alterava as políticas para migrar o nó principal, reduzindo a redundância durante a migração. Além disso, para grandes filas teve que aturar inacessibilidade durante a sincronização.
Kafka tem um conceito de "pistas preferidas" para o papel de liderança. Quando as seções de tópico são criadas, Kafka tenta distribuir uniformemente os líderes pelos nós e marca esses primeiros líderes como preferidos. Com o tempo, devido a reinicializações do servidor, falhas e falhas de conectividade, os líderes podem acabar em outros nós, como no caso extremo descrito acima.
Para corrigir isso, o Kafka oferece duas opções:
- A opção auto.leader.rebalance.enable = true permite ao nó do controlador reatribuir automaticamente líderes de volta às réplicas preferidas e, assim, restaurar a distribuição uniforme.
- Um administrador pode executar o script kafka-preferred-replica-election.sh para reatribuir manualmente.
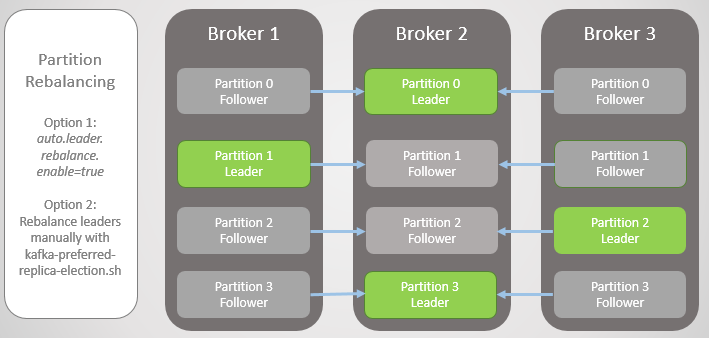 Fig. 6. Réplicas após reequilíbrio
Fig. 6. Réplicas após reequilíbrioFoi uma versão simplificada da falha, mas a realidade é mais complexa, embora não haja nada muito complicado aqui. Tudo se resume a réplicas sincronizadas (réplicas em sincronização, ISR).
Réplicas sincronizadas (ISR)
ISR é um conjunto de réplicas de uma partição que é considerada "sincronizada" (em sincronização). Existe um líder, mas pode não haver seguidores. Um seguidor é considerado sincronizado se ele tiver feito cópias exatas de todas as mensagens de líder antes da expiração do intervalo
replica.lag.time.max.ms .
O seguidor é removido do conjunto ISR se:
- não solicitou amostragem para o intervalo replica.lag.time.max.ms (considerado morto)
- não teve tempo para atualizar para o intervalo replica.lag.time.max.ms (considerado lento)
Os seguidores fazem solicitações de busca no intervalo
replica.fetch.wait.max.ms , que por padrão é de 500 ms.
Para explicar claramente o objetivo do ISR, é necessário examinar as confirmações do produtor (produtor) e alguns cenários de falha. Os produtores podem escolher quando um corretor envia uma confirmação:
- acks = 0, a confirmação não é enviada
- acks = 1, a confirmação é enviada depois que o líder escreve uma mensagem no log local
- acks = all, a confirmação é enviada após todas as réplicas no ISR terem gravado uma mensagem nos logs locais
Na terminologia Kafka, se o ISR salvou a mensagem, ela é "confirmada". Acks = all é a opção mais segura, mas também um atraso adicional. Vejamos dois exemplos de falha e como as diferentes opções de 'acks' interagem com o conceito ISR.
Acks = 1 e ISR
Neste exemplo, veremos que, se o líder não esperar que cada mensagem de todos os seguidores seja salva, se o líder falhar, os dados poderão ser perdidos. Ir a um seguidor não sincronizado pode ser ativado ou desativado configurando
unclean.leader.election.enable .
Neste exemplo, o fabricante está definido como acks = 1. A seção é distribuída pelos três corretores. O Broker 3 está atrasado, sincronizado com o líder oito segundos atrás e agora está atrasado por 7456 mensagens. O corretor 1 está apenas um segundo atrás. Nosso produtor envia uma mensagem e recebe rapidamente uma resposta, sem sobrecarga para seguidores lentos ou mortos que o líder não espera.
 Fig. 7. ISR com três réplicas
Fig. 7. ISR com três réplicasO Broker 2 falha e o fabricante recebe um erro de conexão. Após a transição da liderança para o intermediário 1, perdemos 123 mensagens. O seguidor no broker 1 fazia parte do ISR, mas não estava totalmente sincronizado com o líder quando caiu.
 Fig. 8. Em caso de falha, as mensagens são perdidas
Fig. 8. Em caso de falha, as mensagens são perdidasNa configuração
bootstrap.servers , o fabricante lista vários corretores, e ele pode perguntar a outro corretor que se tornou o novo líder da seção. Ele então estabelece uma conexão com o broker 1 e continua a enviar mensagens.
 Fig. 9. O envio de mensagens é retomado após uma pequena pausa
Fig. 9. O envio de mensagens é retomado após uma pequena pausaO corretor 3 fica ainda mais longe. Faz solicitações de busca, mas não pode sincronizar. Isso pode ser devido a uma conexão de rede lenta entre corretores, um problema de armazenamento etc. Ele é removido do ISR. Agora o ISR consiste em uma réplica - o líder! O fabricante continua a enviar mensagens e receber confirmação.
 Fig. 10. O seguidor no broker 3 é removido do ISR
Fig. 10. O seguidor no broker 3 é removido do ISRO corretor 1 cai e o papel do líder passa para o corretor 3 com a perda de 15286 mensagens! O fabricante recebe uma mensagem de erro de conexão. Ir ao líder fora do ISR só foi possível devido à configuração
unclean.leader.election.enable = true . Se estiver definido como
false , a transição não teria ocorrido e todas as solicitações de leitura e gravação seriam rejeitadas. Nesse caso, estamos aguardando o retorno do broker 1 com seus dados intocados na réplica, que novamente assumirá a liderança.
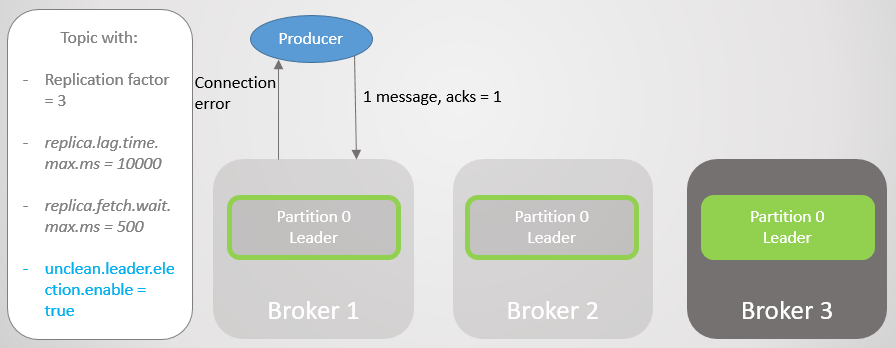 Fig. 11. Corretor 1 cai. Se ocorrer uma falha, um grande número de mensagens será perdido
Fig. 11. Corretor 1 cai. Se ocorrer uma falha, um grande número de mensagens será perdidoO fabricante estabelece uma conexão com o último corretor e vê que ele agora é o líder da seção. Ele começa a enviar mensagens para o corretor 3.
 Fig. 12. Após uma breve pausa, as mensagens são novamente enviadas para a seção 0
Fig. 12. Após uma breve pausa, as mensagens são novamente enviadas para a seção 0Vimos que, além de breves interrupções para estabelecer novas conexões e procurar um novo líder, o fabricante enviava constantemente mensagens. Essa configuração fornece acessibilidade por meio de consistência (segurança de dados). Kafka perdeu milhares de mensagens, mas continuou a aceitar novas entradas.
Acks = all e ISR
Vamos repetir esse cenário novamente, mas com
acks = all . Atraso no intermediário 3 em média quatro segundos. O fabricante envia uma mensagem com
acks = all e agora não recebe uma resposta rápida. O líder espera até que todas as mensagens no ISR armazenem a mensagem.
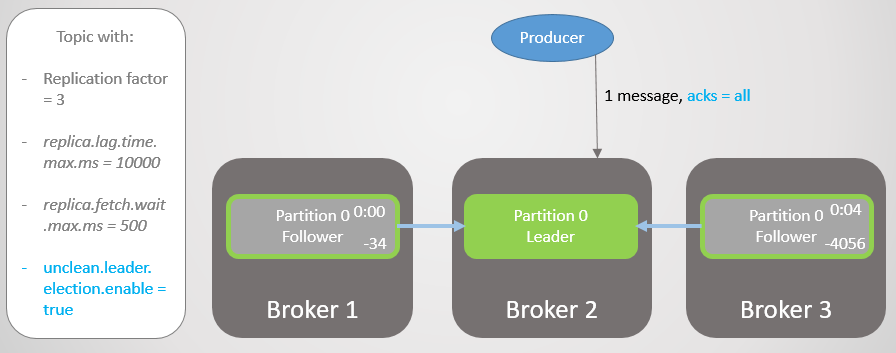 Fig. 13. ISR com três réplicas. Um é lento, causando um atraso na gravação
Fig. 13. ISR com três réplicas. Um é lento, causando um atraso na gravaçãoApós quatro segundos de atraso adicional, o broker 2 envia uma confirmação. Todas as réplicas agora estão totalmente atualizadas.
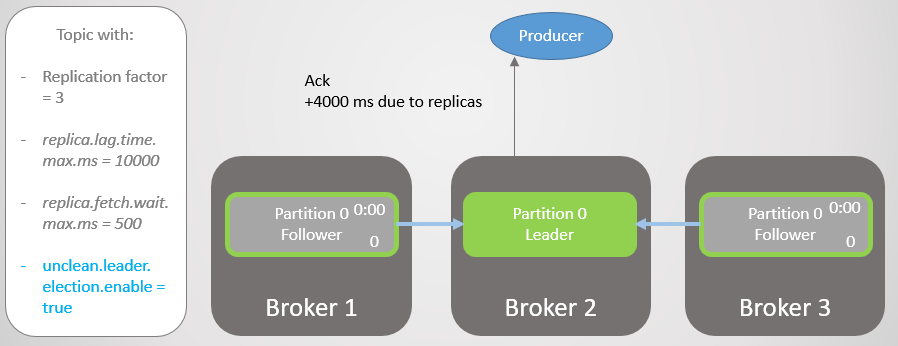 Fig. 14. Todas as réplicas salvam mensagens e a confirmação é enviada
Fig. 14. Todas as réplicas salvam mensagens e a confirmação é enviadaO Broker 3 está agora ainda mais atrasado e está sendo removido do ISR. O atraso é reduzido significativamente porque não há réplicas lentas deixadas no ISR. O corretor 2 agora está aguardando apenas o corretor 1 e ele tem um atraso médio de 500 ms.
 Fig. 15. A réplica no broker 3 é removida do ISR
Fig. 15. A réplica no broker 3 é removida do ISRO corretor 2 cai e a liderança passa para o corretor 1 sem perder as mensagens.
 Fig. 16. O corretor 2 está caindo
Fig. 16. O corretor 2 está caindoO fabricante encontra um novo líder e começa a enviar mensagens para ele. O atraso ainda é reduzido, porque agora o ISR consiste em uma réplica! Portanto, a opção
acks = all não adiciona redundância.
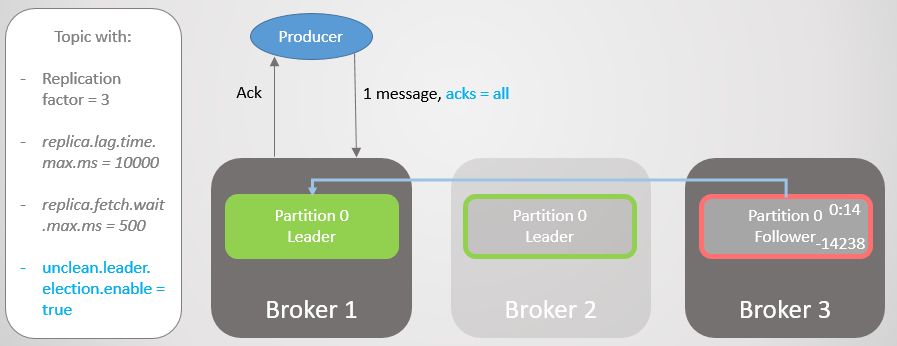 Fig. 17. A réplica no broker 1 assume a liderança sem perder mensagens
Fig. 17. A réplica no broker 1 assume a liderança sem perder mensagensEntão o corretor 1 cai e a liderança passa para o corretor 3 com a perda de 14.238 mensagens!
 Fig. 18. O Broker 1 morre e a transição da liderança com configuração impura leva à extensa perda de dados
Fig. 18. O Broker 1 morre e a transição da liderança com configuração impura leva à extensa perda de dadosNão foi possível definir a opção
unclean.leader.election.enable como
true . Por padrão, é
falso . Definir
acks = all com
unclean.leader.election.enable = true fornece acessibilidade com alguma segurança de dados adicional. Mas, como você pode ver, ainda podemos perder mensagens.
Mas e se quisermos aumentar a segurança dos dados? Você pode definir
unclean.leader.election.enable = false , mas isso não necessariamente nos protege da perda de dados. Se o líder ficou duro e levou os dados com ele, as mensagens ainda serão perdidas, além da acessibilidade, até que o administrador recupere a situação.
É melhor garantir a redundância de todas as mensagens e recusar a gravação. Então, pelo menos do ponto de vista do corretor, a perda de dados é possível apenas com duas ou mais falhas simultâneas.
Acks = all, min.insync.replicas e ISR
Com a
configuração do tópico
min.insync.replicas, aumentamos a segurança dos dados. Vamos examinar a última parte do último cenário mais uma vez, mas desta vez com
min.insync.replicas = 2 .
Portanto, o broker 2 tem um líder de réplica e o seguidor no broker 3 é removido do ISR.
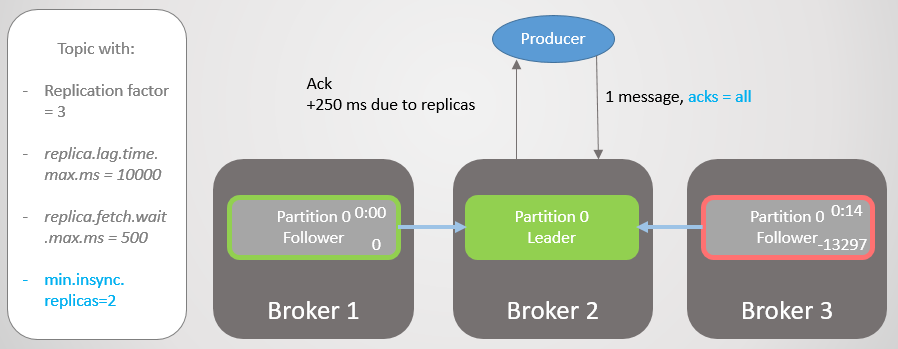 Fig. 19. ISR de duas réplicas
Fig. 19. ISR de duas réplicasO corretor 2 cai e a liderança passa para o corretor 1 sem perder mensagens. Mas agora o ISR consiste em apenas uma réplica. Isso não corresponde ao número mínimo para recebimento de registros e, portanto, o broker responde à tentativa de gravar com o erro
NotEnoughReplicas .
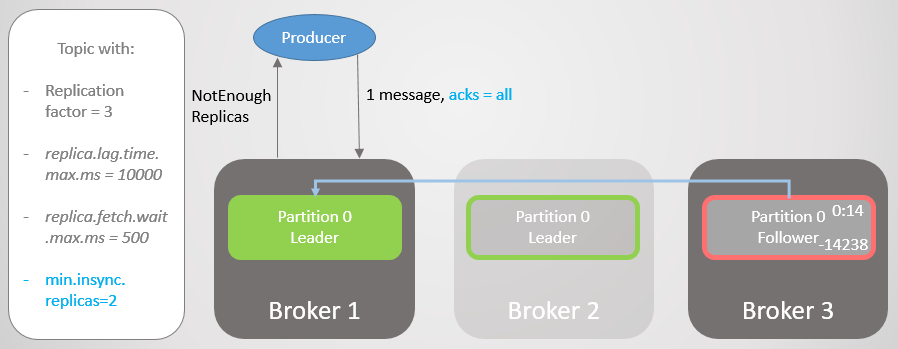 Fig. 20. O número de ISRs é um menor que o especificado em min.insync.replicas
Fig. 20. O número de ISRs é um menor que o especificado em min.insync.replicasEssa configuração sacrifica a disponibilidade por consistência. Antes de confirmar uma mensagem, garantimos que ela seja gravada em pelo menos duas réplicas. Isso dá ao fabricante muito mais confiança. Aqui, a perda de mensagens é possível apenas se duas réplicas falharem simultaneamente em um curto intervalo, até que a mensagem seja replicada para um seguidor adicional, o que é improvável. Mas se você é superparanóico, pode definir a taxa de replicação para 5 e
min.insync.replicas para 3. Em seguida, três corretores ao mesmo tempo devem cair ao mesmo tempo para perder o registro! Obviamente, por essa confiabilidade, você pagará um atraso adicional.
Quando a acessibilidade é necessária para segurança dos dados
Como
no RabbitMQ , às vezes a acessibilidade é necessária para a segurança dos dados. Você precisa pensar sobre isso:
- Um editor pode simplesmente retornar um erro e um serviço ou usuário superior tentar novamente mais tarde?
- Um editor pode salvar uma mensagem localmente ou em um banco de dados para tentar novamente mais tarde?
Se a resposta for não, a otimização da acessibilidade melhora a segurança dos dados. Você perderá menos dados se escolher a disponibilidade em vez de descartar a gravação. Assim, tudo se resume a encontrar um equilíbrio, e a decisão depende da situação específica.
O significado de ISR
O pacote ISR permite que você escolha o equilíbrio ideal entre segurança e latência de dados. Por exemplo, para garantir que a maioria das réplicas esteja acessível em caso de falha, minimizando o impacto de réplicas inativas ou lentas em termos de atraso.
Nós mesmos escolhemos o valor de
replica.lag.time.max.ms de acordo com nossas necessidades. Em essência, esse parâmetro significa que atraso estamos prontos para aceitar com
acks = all . O valor padrão é dez segundos. Se isso for muito longo para você, você pode reduzi-lo. A frequência das alterações no ISR aumentará, pois os seguidores serão mais frequentemente excluídos e adicionados.
O RabbitMQ é apenas uma coleção de espelhos que precisam ser replicados. Os espelhos lentos introduzem um atraso adicional, e a resposta dos espelhos mortos pode ser esperada antes da expiração dos pacotes que verificam a disponibilidade de cada nó (net tick). Os ISRs são uma maneira interessante de evitar esses problemas com maior latência. Mas corremos o risco de perder redundância, uma vez que o ISR só pode ser reduzido a um líder. Para evitar esse risco, use a configuração
min.insync.replicas .
Garantia de conectividade do cliente
Nas configurações de
bootstrap.servers do fabricante e do consumidor, você pode especificar vários intermediários para conectar clientes. A idéia é que, quando você desconecta um nó, existem vários nós sobressalentes com os quais o cliente pode abrir uma conexão. Estes não são necessariamente líderes de seção, mas simplesmente um trampolim para a inicialização. O cliente pode perguntar a eles em qual nó o líder da seção de leitura / gravação está localizado.
No RabbitMQ, os clientes podem se conectar a qualquer host, e o roteamento interno envia uma solicitação sempre que necessário. Isso significa que você pode instalar um balanceador de carga na frente do RabbitMQ. O Kafka exige que os clientes se conectem ao host que hospeda o líder da partição correspondente. Nessa situação, o balanceador de carga não é entregue. A lista
bootstrap.servers é crítica para que os clientes possam acessar os nós corretos e localizá-los após uma falha.
Arquitetura de consenso Kafka
Até o momento, não consideramos como o cluster descobre a queda do corretor e como um novo líder é escolhido. Para entender como o Kafka funciona com partições de rede, primeiro você precisa entender a arquitetura de consenso.
Cada cluster Kafka é implantado com o cluster Zookeeper - é um serviço de consenso distribuído que permite que o sistema chegue a consenso em um determinado estado com prioridade de consistência sobre a disponibilidade. A aprovação de operações de leitura e gravação requer o consentimento da maioria dos nós do Zookeeper.
O Zookeeper armazena o status do cluster:
- Lista de tópicos, seções, configuração, réplicas de líderes atuais, réplicas preferidas.
- Membros do cluster. Cada intermediário entra em um cluster do Zookeeper. Se ele não receber ping por um determinado período de tempo, o Zookeeper gravará o broker inacessível.
- A escolha de nós primários e secundários para o controlador.
O nó do controlador é um dos corretores Kafka responsável por eleger líderes de réplicas. O tratador envia ao controlador notificações de associação ao cluster e alterações de tópico, e o controlador deve agir de acordo com essas alterações.
Por exemplo, considere um novo tópico com dez seções e um coeficiente de replicação 3. O controlador deve selecionar o líder de cada seção, tentando distribuir de maneira ideal os líderes entre os intermediários.
Para cada seção, o controlador:
- atualiza informações no Zookeeper sobre ISR e o líder;
- envia um comando LeaderAndISRCommand para cada broker que publica uma réplica desta seção, informando os brokers sobre o ISR e o líder.
Quando um corretor com um líder cai, Zookeeper envia uma notificação ao controlador e ele seleciona um novo líder. Novamente, o controlador atualiza o Zookeeper primeiro e envia um comando para cada corretor, notificando-os sobre uma mudança na liderança.
Cada líder é responsável pelo recrutamento de ISRs. A
configuração replica.lag.time.max.ms determina quem irá para lá. Quando o ISR muda, o líder passa as novas informações ao Zookeeper.
O tratador é sempre informado de quaisquer alterações, para que, em caso de falha, o gerenciamento se mova suavemente para o novo líder.
 Fig. 21. Kafka de consenso
Fig. 21. Kafka de consensoProtocolo de replicação
Compreender os detalhes da replicação ajuda a entender melhor os possíveis cenários de perda de dados.
Solicitações de amostra, Offset de log (LEO) e Highwater Mark (HW)
Consideramos que os seguidores enviam periodicamente solicitações de busca ao líder. O intervalo padrão é 500 ms. Isso difere do RabbitMQ, pois, no RabbitMQ, a replicação é iniciada não pelo espelho da fila, mas pelo assistente. O mestre empurra as mudanças para os espelhos.
O líder e todos os seguidores mantêm os rótulos Log End Offset (LEO) e Highwater (HW). A marca LEO armazena o deslocamento da última mensagem na réplica local e o HW armazena o deslocamento da última confirmação. Lembre-se de que, para o status de confirmação, a mensagem deve ser salva em todas as réplicas do ISR. Isso significa que o LEO geralmente está um pouco à frente do HW.
Quando um líder recebe uma mensagem, ele a salva localmente. O seguidor faz uma solicitação de busca, passando seu LEO. O líder envia um pacote de mensagens começando com este LEO e também transmite o HW atual. Quando o líder recebe informações de que todas as réplicas salvaram a mensagem em um determinado deslocamento, ele move a marca HW. Somente o líder pode mover o HW e, portanto, todos os seguidores saberão o valor atual nas respostas à sua solicitação. Isso significa que os seguidores podem ficar atrás do líder nos relatórios e no conhecimento de HW. Os consumidores recebem mensagens apenas até o HW atual.
Observe que "persistente" significa gravado na memória, não no disco. Para desempenho, o Kafka sincroniza com o disco em um intervalo especificado. O RabbitMQ também possui esse intervalo, mas enviará a confirmação ao editor somente depois que o mestre e todos os espelhos tiverem gravado a mensagem no disco. Os desenvolvedores Kafka, por razões de desempenho, decidiram enviar uma confirmação assim que a mensagem foi gravada na memória. Kafka conta com redundância para compensar o risco de armazenamento de curto prazo de mensagens confirmadas apenas na memória.
Falha no Líder
Quando um líder cai, Zookeeper notifica o controlador e ele seleciona uma nova réplica de líder. O novo líder define uma nova marca HW em conformidade com o seu LEO. Em seguida, os seguidores recebem informações sobre o novo líder. Dependendo da versão do Kafka, o seguidor escolherá um dos dois cenários:
- Trunca o log local para o famoso HW e envia uma mensagem para o novo líder após esta marca.
- , HW , . , .
:
- , ISR, Zookeeper, . ISR, «», . , . Kafka , . , , HW . , acks=all .
- . , . , , , , , .
c
, : HW ( ). , RabbitMQ . . , « ». . .
Kafka — , , RabbitMQ, . . Kafka — , . . Kafka HW ( ) , . , , , LEO.
ISR . , , , ISR. .
Kafka , RabbitMQ, , . Kafka , .
:
- 1. , Zookeeper.
- 2. , Zookeeper.
- 3. , Zookeeper.
- 4. , Zookeeper.
- 5. Kafka, Zookeeper.
- 6. Kafka, Zookeeper.
- 7. Kafka Kafka.
- 8. Kafka Zookeeper.
.
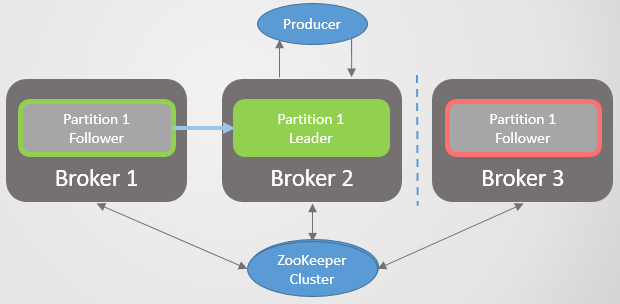
1. , Zookeeper
 . 22. 1. ISR
. 22. 1. ISR3 1 2, Zookeeper. 3 .
replica.lag.time.max.ms ISR . , ISR, . Zookeeper , .
 . 23. 1. ISR, replica.lag.time.max.ms
. 23. 1. ISR, replica.lag.time.max.ms(split-brain) , RabbitMQ. .
2. , Zookeeper
 . 24. 2.
. 24. 2., Zookeeper. , ISR , , . , . , . Zookeeper , .
 . 25. 2. ISR
. 25. 2. ISR3. , Zookeeper
Zookeeper, . ISR. Zookeeper , , .
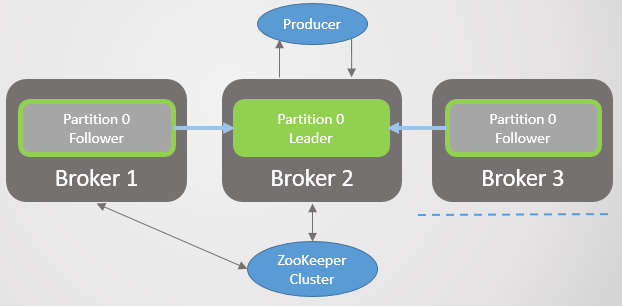 . 26. 3.
. 26. 3.4. , Zookeeper
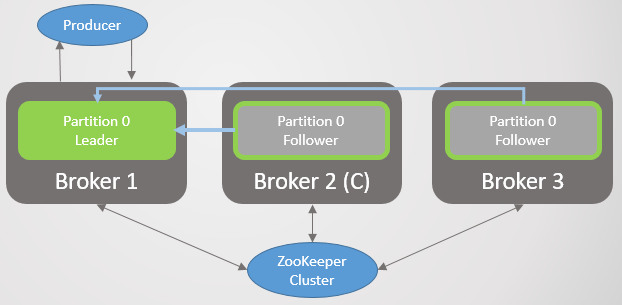 . 27. 4.
. 27. 4.Zookeeper, .
 . 28. 4. Zookeeper
. 28. 4. ZookeeperZookeeper . . ,
acks=1 . , ISR . Zookeeper, , .
acks=all , ISR , . ISR, - .
. , , , HW, , . . , . , , .
 . 29. 4. 1
. 29. 4. 15. Kafka, Zookeeper
Kafka, Zookeeper. ISR, , .
 . 30. 5. ISR
. 30. 5. ISR6. Kafka, Zookeeper
 . 31. 6.
. 31. 6., Zookeeper.
acks=1 .
 . 32. 6. Kafka Zookeeperreplica.lag.time.max.ms
. 32. 6. Kafka Zookeeperreplica.lag.time.max.ms , ISR , , Zookeeper, .
, Zookeeper , .
 . 33. 6.
. 33. 6., . 60 . .
 . 34. 6.
. 34. 6., . , Zookeeper , . HW .
 . 35. 6.
. 35. 6.,
acks=1 min.insync.replicas 1. , , , , — , . ,
acks=1 .
, , ISR . - . , ,
acks=all , ISR . . —
min.insync.replicas = 2 .
7. Kafka Kafka
, Kafka . , 6. .
8. Kafka Zookeeper
Zookeeper Kafka. , Zookeeper, . , , , Kafka.
, , , . , , , .
- Zookeeper,
acks=1 . Zookeeper .
acks=all .
min.insync.replicas , , 6.
, Kafka:
- , acks=1
- (unclean) , ISR, acks=all
- Zookeeper, acks=1
- , ISR . , acks=all . , min.insync.replicas=1 .
- . , . .
, , . —
acks=all min.insync.replicas 1.
RabbitMQ Kafka
. RabbitMQ . , . RabbitMQ. , . . , ( ) .
Kafka . . . , . , , . , - , . , .
RabbitMQ Kafka . , RabbitMQ . :
- fsync a cada poucas centenas de milissegundos
- Os espelhos podem ser detectados somente após a vida útil dos pacotes que verificam a disponibilidade de cada nó (tick de rede). Se o espelho diminuir a velocidade ou cair, isso adiciona um atraso.
Kafka conta com o fato de que, se a mensagem estiver armazenada em vários nós, você poderá confirmar as mensagens assim que elas estiverem na memória. Por esse
motivo , existe o risco de perder mensagens de qualquer tipo (mesmo
acks = all ,
min.insync.replies = 2 ) no caso de uma falha simultânea.
No geral, o Kafka demonstra melhor desempenho e foi originalmente projetado para clusters. O número de seguidores pode ser aumentado para 11, se necessário, para confiabilidade. Um fator de replicação 5 e um número mínimo de réplicas em um estado sincronizado de
min.insync.replicas = 3 tornará a perda de mensagens um evento muito raro. Se sua infraestrutura for capaz de fornecer essa taxa de replicação e um nível de redundância, você poderá escolher esta opção.
O agrupamento RabbitMQ é bom para filas pequenas. Mas mesmo pequenas filas podem crescer rapidamente com alto tráfego. Depois que as filas ficarem grandes, você terá que fazer uma escolha difícil entre disponibilidade e confiabilidade. O agrupamento RabbitMQ é mais adequado para situações não típicas em que as vantagens da flexibilidade do RabbitMQ superam qualquer uma das desvantagens de agrupá-lo.
Um dos antídotos para a vulnerabilidade de grandes filas do RabbitMQ é quebrá-los em muitos menores. Se você não precisar de pedidos completos de toda a fila, mas apenas de mensagens relevantes (por exemplo, mensagens de um cliente específico) ou nada, então esta opção é aceitável: veja meu projeto
Rebalanser para dividir a fila (o projeto ainda está em estágio inicial).
Por fim, não se esqueça de vários bugs nos mecanismos de cluster e replicação do RabbitMQ e do Kafka. Com o tempo, os sistemas se tornaram mais maduros e estáveis, mas nem uma única mensagem estará 100% protegida contra perdas! Além disso, acidentes em grande escala acontecem nos data centers!
Se eu perdi alguma coisa, cometi um erro ou você não concorda com nenhum dos pontos, sinta-se à vontade para escrever um comentário ou entre em contato comigo.
As pessoas costumam me perguntar: “O que escolher, Kafka ou RabbitMQ?”, “Qual plataforma é melhor?”. A verdade é que realmente depende da sua situação, experiência atual, etc. Não me atrevo a expressar minha opinião, pois será muita simplificação recomendar qualquer plataforma para todos os casos de uso e possíveis limitações. Escrevi esta série de artigos para que você possa formar sua própria opinião.
Eu quero dizer que ambos os sistemas são líderes neste campo. Talvez eu seja um pouco tendencioso, porque, a partir da experiência de meus projetos, estou mais inclinado a apreciar coisas como ordem e confiabilidade garantidas de mensagens.
Vejo outras tecnologias que carecem dessa confiabilidade e do pedido garantido, depois analiso o RabbitMQ e o Kafka - e entendo o valor incrível desses dois sistemas.