Há não muito tempo, vimos como as experiências A / B na Pesquisa são organizadas. O chefe da equipe de desenvolvimento da versão iOS do Yandex. O navegador Andrei Sikerin
sav42 na última reunião da CocoaHeads Russia também falou sobre a infraestrutura de testes A / B, apenas em seu projeto.
- Olá, meu nome é Andrey Sikerin, estou desenvolvendo o Yandex.Browser para iOS. Quero lhe dizer qual é a plataforma de experiência do navegador para iOS, como aprendemos a usá-la, suportou seus recursos mais avançados, como diagnosticar e depurar os recursos lançados usando o sistema de experiência e também qual é a fonte da entropia e onde moeda é armazenada.
Então, vamos começar. No Navegador para iOS, nunca rolamos o recurso para os usuários de uma só vez. Primeiro, realizamos testes A / B, analisamos as métricas técnicas e do produto para entender como o recurso rolado afeta o usuário, quer ele goste ou não, quer esbanje algumas métricas técnicas. Para isso, usamos análises. Nossa análise é mais ou menos assim:
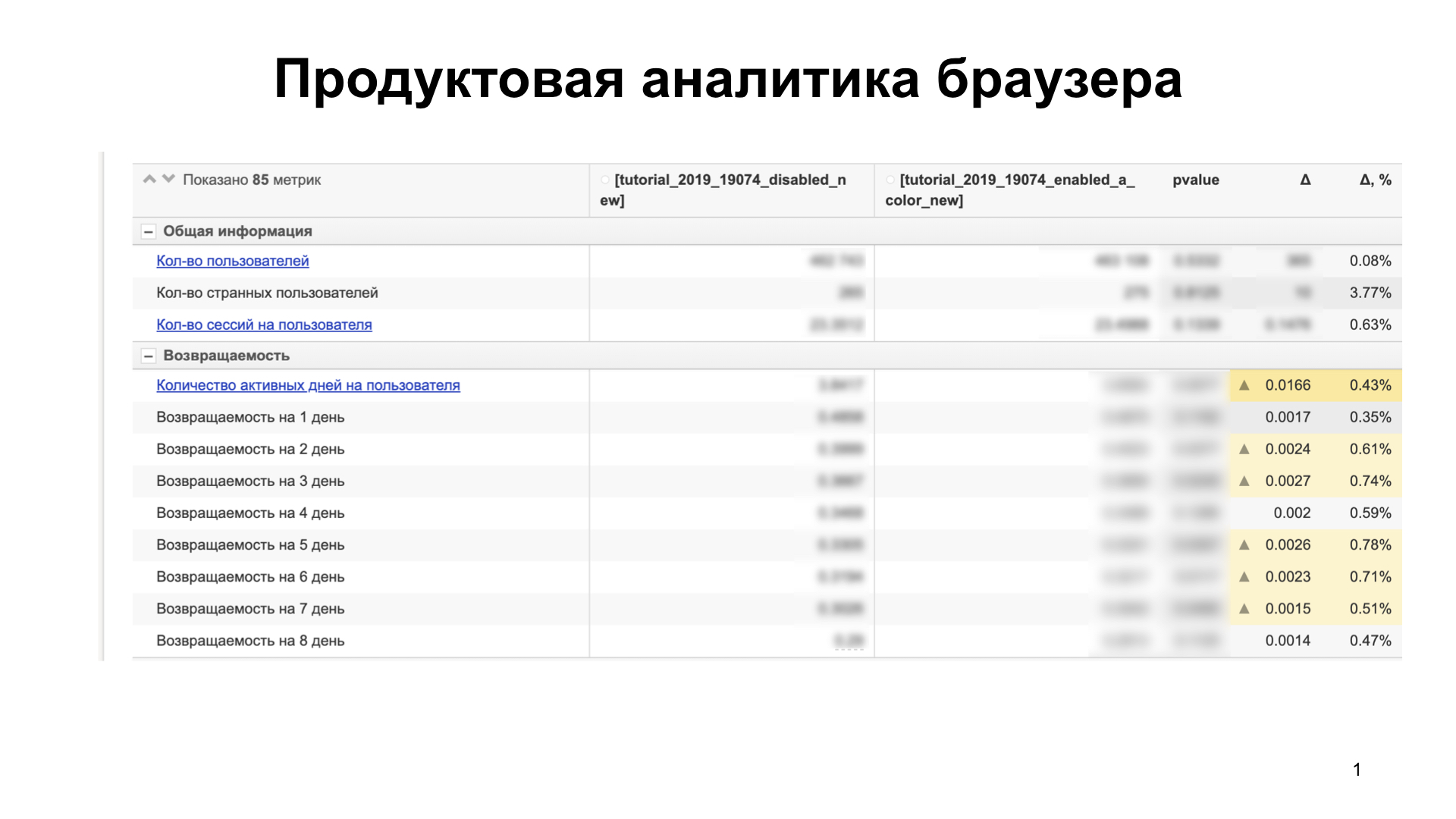
Existem cerca de 85 métricas. Nós comparamos vários grupos de usuários. Suponha que isso aumente nossas métricas - por exemplo, a capacidade do produto de reter usuários (retenção) - e não desperdice outros que não estão no slide. Isso significa que os usuários gostam do recurso e podem ser transferidos para um grande grupo de usuários.
Se, no entanto, desperdiçamos alguma coisa, entendemos o porquê. Construímos hipóteses, as confirmamos. Se desenharmos métricas técnicas - isso é um bloqueador. Nós os corrigimos e executamos o experimento novamente. E assim até pintarmos tudo. Assim, lançamos um recurso que não é uma fonte de regressão.
Vamos falar sobre o sistema de experimentos original que usamos. Ela já estava bastante desenvolvida. Então eu direi o que não nos convinha.

Primeiro, ele é baseado no sistema experimental Chromium e não era totalmente suportado no iOS. Em segundo lugar, foi originalmente capaz de implementar recursos para diferentes grupos de usuários e tinha um sistema de filtro no qual era possível definir requisitos para dispositivos. Ou seja - a versão do aplicativo em que o recurso está disponível, a localidade do dispositivo - digamos que queremos uma experiência apenas para a localidade russa. A versão do iOS na qual esse recurso estará disponível ou a data em que esse experimento será válido - por exemplo, se queremos realizar um experimento apenas até alguma data. Em geral, havia muitas tags e era bastante conveniente.
O próprio sistema de experimentos consiste em um arquivo que contém descrições das configurações dos experimentos. Ou seja, para um experimento, pode haver várias configurações ao mesmo tempo. Este arquivo é um arquivo de texto, é compilado no protobuf e disposto no servidor.
Cada configuração consiste em grupos. Existe um experimento, possui várias configurações e em cada uma delas existem vários grupos. O recurso no código é anexado ao nome do grupo ativo da configuração ativa. Pode parecer bastante complicado, mas agora vou explicar em detalhes o que é.

Como isso funciona tecnicamente? Um arquivo com descrições de todas as configurações é carregado no servidor. Na inicialização, é baixado pelo navegador do servidor e salvo no disco. Na próxima vez que iniciarmos, decodificamos esse arquivo o primeiro da cadeia de inicialização do aplicativo. E para cada experiência única, encontramos uma configuração que estará ativa.
A configuração adequada às condições especificadas e descritas nela pode se tornar ativa. Se houver várias configurações ativas que atendam às condições especificadas, a configuração que será maior no arquivo será ativada.
Além da configuração ativa, uma moeda é lançada. A moeda é lançada localmente, e de acordo com essa moeda de uma certa maneira, que discutirei mais adiante, o grupo ativo do experimento é selecionado. E é precisamente ao nome do grupo ativo do experimento que estamos anexados no código, verificando se nosso recurso está disponível ou não.
Uma característica fundamental deste sistema é que ele não armazena nada por si só. Ou seja, ela não possui armazenamento no disco. Cada lançamento - pegamos o arquivo, começamos a calculá-lo, encontramos a configuração ativa. Dentro da configuração, de acordo com a moeda, encontramos o grupo ativo e o sistema do experimento diz: este grupo está selecionado. Ou seja, tudo é calculado, nada é armazenado.

De fato, deixe-me mostrar um arquivo com descrições de experimentos. O navegador possui esse recurso - Tradutor. Ela desenrolou em um experimento. O arquivo começa com o bloco de estudo. A configuração de qualquer experimento começa com este bloco. O experimento é chamado de tradutor. Pode haver vários desses blocos de estudo com esse nome. E dentro do bloco de estudo, existem muitos blocos experimentais aos quais são atribuídos nomes diferentes. Nesse caso, vemos o grupo de experiências ativado. E há um bloco de filtro que, de fato, descreve sob quais condições essa configuração pode se tornar ativa, ou seja, seus critérios.
Existem duas tags aqui - channel e ya_min_version. Canal significa vista de montagem. BETA é indicado aqui, o que significa que essa configuração no arquivo pode se tornar ativa apenas para os assemblies que enviamos ao TestFlight. Para a compilação da App Store, essa configuração pelo critério do canal não pode se tornar ativa.
ya_min_version significa que, com a versão mínima do aplicativo 19.3.4.43, essa configuração pode se tornar ativa. Na verdade, nesta versão do aplicativo, o recurso já adquiriu um formulário que você pode ativá-lo.
Esta é a descrição mais simples do grupo de configuração da experiência do tradutor. Pode haver muitos desses blocos de estudo em um arquivo. Usando tags no bloco de filtro, as definimos para diferentes canais, para montagens internas, para montagens BETA, para vários critérios.
Aqui está um grupo de experimentos chamado enabled e ele possui uma etiqueta de peso de probabilidade, o peso do grupo de experimentos. Este é um número inteiro não negativo usado para determinar o grupo ativo no momento em que a moeda aparece.
Vamos imaginar que essa configuração no slide se tornou ativa. Ou seja, realmente instalamos o aplicativo com beta público e realmente temos a versão 19.3.4.43 em diante. Como é lançada a moeda? Uma moeda é um número aleatório gerado localmente de zero a um.
Para que durante o próximo lançamento caiamos no mesmo grupo, ele será armazenado em disco. Enquanto vamos considerar isso. Em seguida, mostrarei como garantir que ele não seja armazenado. A moeda é jogada fora. Suponha que 0,5 seja jogado fora. Essa moeda é escalada em um segmento de zero à soma dos grupos de experimentos. Nesse caso, temos um grupo ativado, seu peso é 1000, ou seja, a soma de todos os grupos será 1000. "0,5" é escalado para 500. Consequentemente, todos os grupos de experimentos dividem o intervalo de zero à quantidade de experimentos e lacunas. E o grupo se torna ativo em cujo intervalo o valor escalado da moeda indicará.
Podemos perguntar o nome do grupo ativo de experimentos no código e, assim, determinar a acessibilidade - precisamos ativar o recurso ou não.
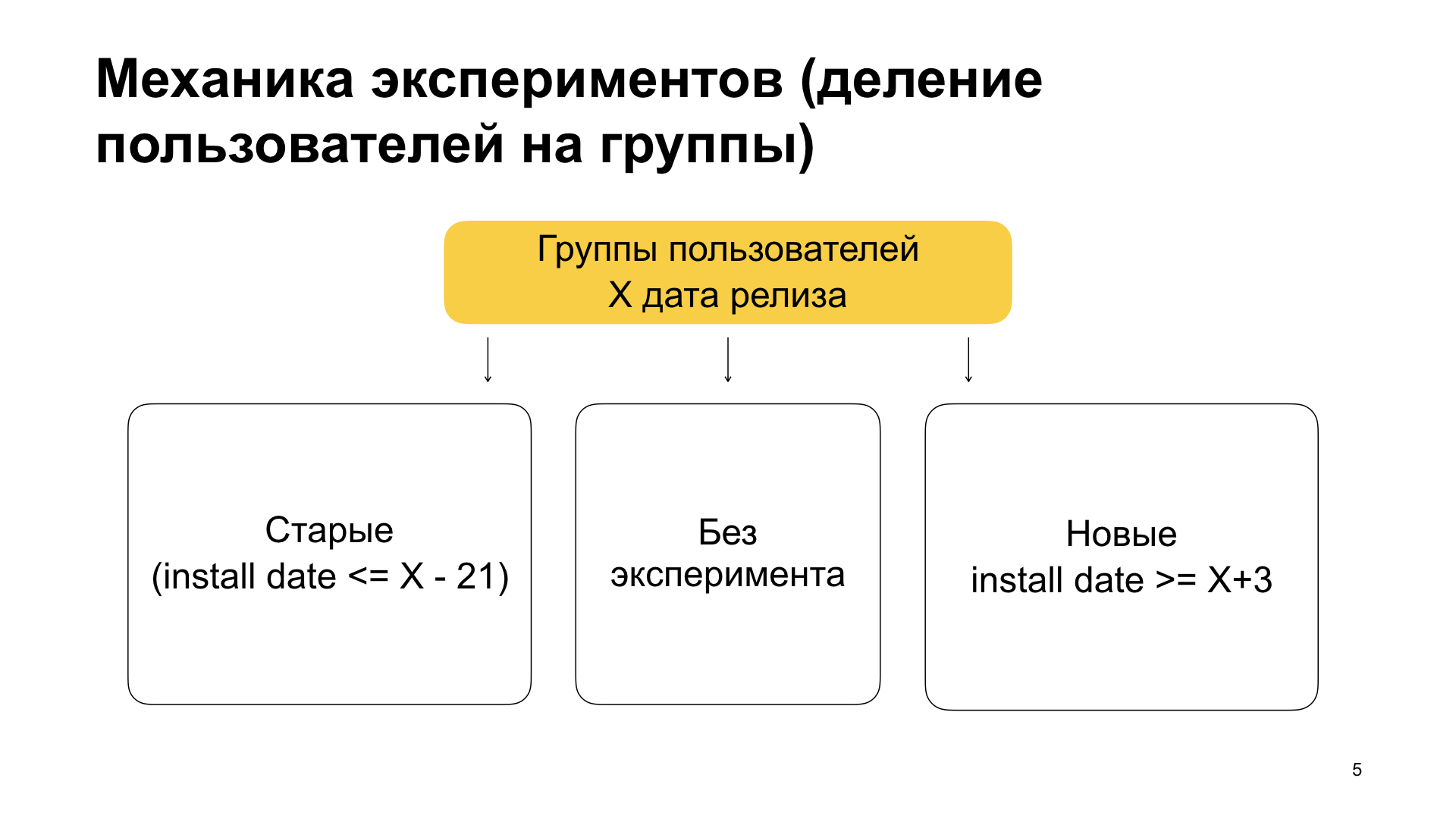
Além disso, veremos configurações experimentais mais complexas que usamos na produção. Em primeiro lugar, é claro que é estúpido lançar um recurso para 100%; usamos isso apenas para beta ou para montagem interna. Para produção, usamos a seguinte mecânica.
Dividimos os usuários em três grupos - usuários antigos, usuários sem experiência e novos usuários. No significado, isso significa o seguinte. Usuários antigos são aqueles que já usaram nosso aplicativo e instalaram o aplicativo com recursos sobre a versão antiga. Ou seja, eles já usaram, não tinham recursos, se acostumaram a tudo e, de repente, atualizam o aplicativo, no qual há algum tipo de experimento, nova funcionalidade. Então - usuários sem experiência e novos usuários. Novos são aqueles que colocam o aplicativo limpo. Ou seja, eles nunca usaram o Yandex.Browser, de repente decidiram usá-lo e instalaram o aplicativo.
Como conseguimos essa partição? No bloco de filtro, definimos as condições para as tags min_install_date e max_install_date. Suponha que X seja 14 de março de 2019 - esta é a data de lançamento da construção do recurso. Em seguida, max_install_date para usuários antigos será X menos 21 dias, antes do lançamento do assembly com recursos. Se o aplicativo tiver uma data de instalação, é altamente provável que seu primeiro lançamento tenha sido anterior ao lançamento. E antes do lançamento, havia uma versão sem recursos. E se agora ele possui, condicionalmente, uma versão com recursos, significa que ele recebeu o aplicativo com a ajuda de uma atualização.
E para novos usuários, definimos min_install_date. Nós o expomos como X mais alguns dias. Isso significa: se ele tiver uma data de instalação, ou seja, ele executou o primeiro lançamento após a data de lançamento da versão com recursos, ele teve uma instalação limpa. Ele agora tem uma versão com recursos, mas a data de instalação foi posterior a esta versão com recursos.
Assim, dividimos os usuários em antigos, sem experimentos e novos. Fazemos isso porque vemos: o comportamento dos usuários antigos é diferente do comportamento dos novos usuários. Portanto, não podemos pintar em um grupo com usuários antigos, mas pintar em um grupo com novos usuários, ou vice-versa. Se fizermos um experimento em toda a massa, podemos não ver isso.

Vamos olhar para esse experimento. Vemos a seguinte configuração do experimento - Tradutor para a App Store, novos usuários. Estudo de bloco, tradutor de nomes, grupo enabled_new. O prefixo new significa que descrevemos a configuração para muitos usuários novos. Peso 500 (se a soma de todos os pesos for 1000, a potência deste conjunto é 50%). Control_new, peso 500, este é o segundo grupo. E o mais interessante são os filtros para o canal STABLE, ou seja, para montagens montadas para produção. Versão na qual o recurso apareceu: 19.4.1. E aqui está a tag min_install_date. Aqui, no formato de hora Unix, ele é criptografado em 18 de abril de 2019. Isso ocorre alguns dias após o lançamento da versão 19.4.1.
Há mais uma parte aqui, além do novo prefixo, ele está ativado e controlado. Aqui está o prefixo de controle; não é acidental. Além do fato de dividirmos os usuários em novos e antigos, dividimos em grupos dentro do experimento em várias partes.
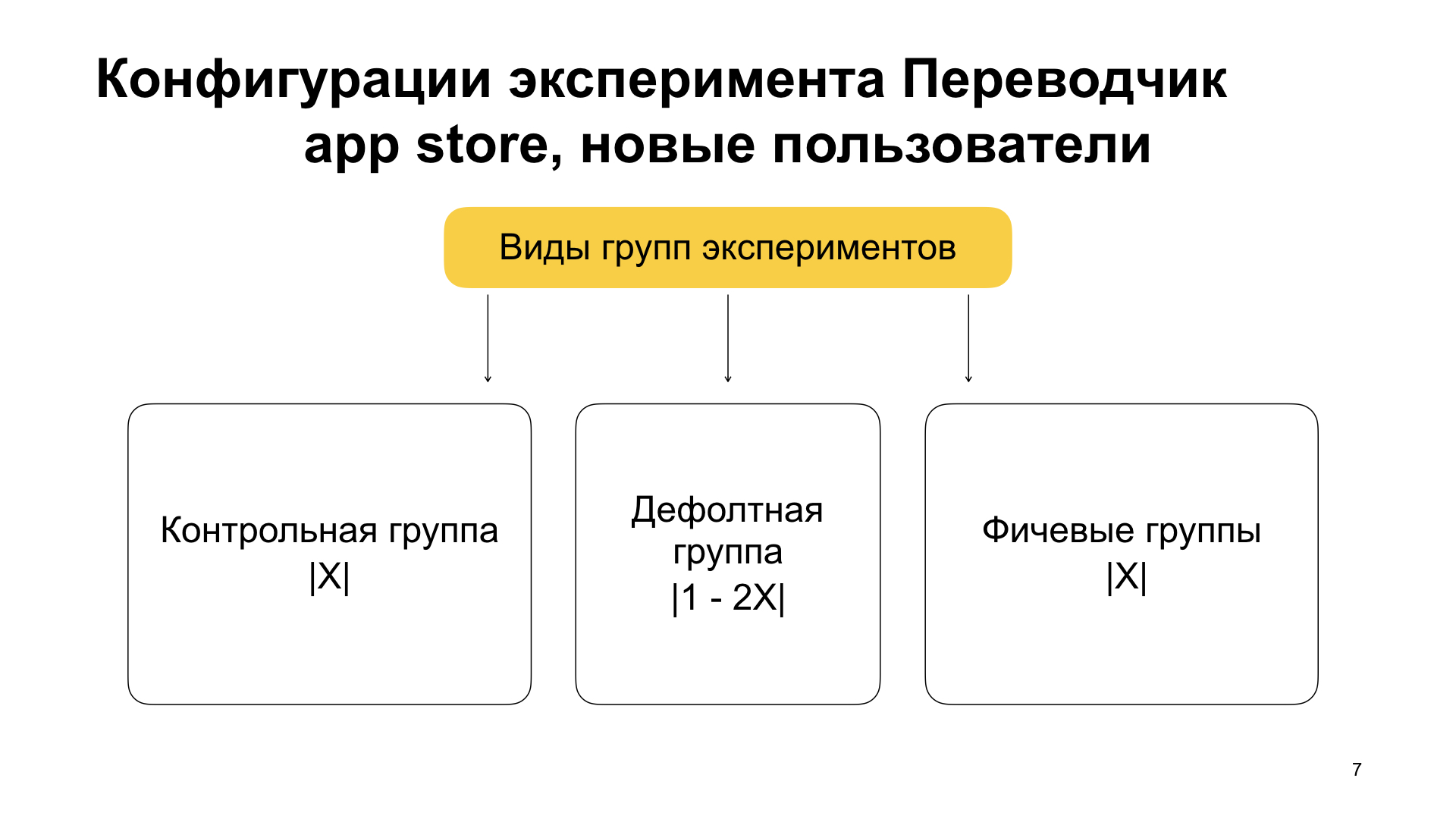
A primeira parte dos usuários é um grupo de controle, que possui o prefixo de controle. Não há recursos nele. Ela tem um peso X. Ela também tem um grupo de recursos, geralmente chamado de ativado. Ele também tem um peso X, e isso é importante: aí o recurso deve ser ativado. E há um grupo padrão que tem um peso de 1 menos 2X (1000 menos 2X, pois 1000 é o valor do peso total de todos os grupos na mesma configuração, o que é aceito por padrão). O grupo padrão também não inclui nenhum recurso. Ele simplesmente armazena os usuários que permaneceram depois de divididos em controles e recursos. Você também pode executar novamente o experimento, se necessário.

Vamos ver, digamos, a configuração para usuários antigos. Veremos um grupo de recursos e controle aqui. enabled_old - em destaque. control_old, - control, 10%. default_old - padrão, 80%.
Observe o filtro, ya_min_version 19.4.1, max_install_date 28 de março de 2019. Esta é uma data anterior à data de lançamento. Portanto, essa é uma configuração com uma lista de usuários que receberam a versão 19.4.1 após a atualização. Eles usaram o aplicativo e agora usam a nova versão.
Por que são necessários grupos de recursos e controle? Nas análises que mostrei no primeiro slide, comparamos o grupo de controle e o grupo de recursos. Eles devem ter o mesmo poder para que as métricas de seus produtos possam ser comparadas.
Assim, comparamos os grupos de controle e recursos em análises para diferentes grupos de usuários, antigos e novos. Se pintarmos tudo, rolamos o recurso em 100%.

Como um desenvolvedor de código trabalha com esse sistema? Ele conhece os nomes dos grupos de recursos, a data em que o recurso precisa ser ativado e escreve alguma camada de acesso, este é um pseudocódigo, solicitando um grupo ativo pelo nome do experimento. Pode não ser. Na verdade, todas as configurações podem não se adequar às condições do dispositivo. Então a string vazia retornará.
Depois disso, se o nome do grupo ativo estiver em destaque, será necessário ativar o recurso, caso contrário, desative-o. Além disso, essa função já é usada no código, que inclui funcionalidade no código do navegador.

Então, convivemos com esse sistema de experimentos por vários anos. Tudo estava bem, mas revelou várias deficiências. A primeira desvantagem dessa abordagem é que é impossível adicionar novos grupos de experimentos sem corrigir o código. Ou seja, se é improvável que o nome do experimento mude para um recurso, é possível adicionar mais alguns grupos adicionais. Mas seu código de acessibilidade de recursos não conhece esses grupos, porque você não o previu com antecedência. Portanto, é necessário rolar a versão, experimentar essa versão, o que é um problema. Ou seja, é necessário, alterando o código, reconstruir e postar na App Store.
Segundo, você não pode distribuir partes de um recurso ou dividi-lo em partes depois de iniciar o experimento. Ou seja, se você de repente decidiu que alguns dos recursos poderiam ser implementados e alguns ainda permanecessem no experimento, não seria possível fazê-lo; era necessário pensar com antecedência e dividir esse recurso em dois e aceitá-los independentemente no experimento.
Terceiro, você não pode configurar um recurso ou comparar configurações. No Translator, por exemplo, há um parâmetro - tempo limite para a API do tradutor. Ou seja, se não conseguimos traduzir em alguns milissegundos, dizemos que, tente novamente, um erro, sem sorte.
É impossível definir esse tempo limite no experimento, porque precisamos corrigir os grupos e imediatamente com antecedência, vamos ter os seguintes grupos com antecedência - enabled_with_300_ms, enabled_with_600_ms em cujos nomes o valor do parâmetro é codificado. Mas é impossível definir o parâmetro numericamente de alguma forma. Se ainda não pensamos nisso, não podemos mais comparar várias configurações.
Quarto, analistas e desenvolvedores são obrigados a concordar com nomes de grupos com antecedência. Ou seja, para que um desenvolvedor comece a desenvolver um recurso, ele geralmente começa, de fato, com a política de disponibilidade desse recurso. E ele precisa saber os nomes dos grupos de recursos. E para isso, o analista deve explicar a mecânica do experimento - se vamos dividir os usuários em novos e antigos ou se todos estarão no mesmo grupo sem divisão.
Ou poderia ser um experimento inverso. Por exemplo, podemos considerar imediatamente que o recurso está ativado, mas podemos desativá-lo. Isso não é muito interessante para o analista, porque o recurso não está pronto. Ele determinará a mecânica do experimento quando estiver pronto. E o desenvolvedor precisa dos nomes dos grupos e da mecânica do experimento com antecedência, caso contrário, ele precisará constantemente fazer alterações no código.
Consultamos e decidimos que era o suficiente para suportar. Assim, o projeto Make Experiments Great Again nasceu.

A ideia principal deste projeto é a seguinte. Se anteriormente estávamos anexados a um código, um código aos nomes dos grupos ativos que o analista nos passou, agora adicionamos duas entidades adicionais. Este recurso (Recurso) e parâmetro de recurso (FeatureParam). E assim, o programador inventa recursos e parâmetros de recursos independentemente, escolhendo identificadores para eles, escolhendo valores padrão para eles e programando a disponibilidade de recursos para eles.
Depois disso, ele passa esses identificadores para o analista, e o analista, pensando na mecânica dos experimentos, os especifica de maneira especial nos grupos de experimentos, usando a tag feature_association. Se esse grupo se tornar ativo, lembre-se de ativar ou desativar o recurso com o identificador tal e tal e defina os parâmetros com esses identificadores.

Como é o arquivo de configuração da experiência? Aqui, examinamos o grupo de experimentos. Nome ativado, uma tag opcional feature_association é adicionada, nessa tag de comando enable_feature ou disable_feature, e identificadores são adicionados.
Há também um bloco param, do qual pode haver vários. Aqui também existe um nome de tempo limite e o valor que precisa ser definido é adicionado.

Como isso se parece no código? O programador declara as entidades das classes Feature e FeatureParam. E ele grava valores dessas primitivas na camada de acesso ao recurso. Em seguida, ele passa esse identificador para o analista e, já no arquivo de configuração, define os identificadores no bloco do grupo de experimentos usando a tag feature_association. Assim que o grupo de experimentos se torna ativo, os valores dos recursos e parâmetros com esses identificadores no código são definidos no arquivo. Se não houver parâmetros e recursos no grupo, serão utilizados os valores padrão indicados no código.
Parece que isso nos deu? Primeiro, ao adicionar um novo grupo, o analista não precisa solicitar ao programador que adicione um novo grupo de recursos ao código, porque a camada de acesso a dados opera com identificadores que não mudam quando um novo grupo é adicionado ao sistema experimental.
Em segundo lugar, publicamos o momento em que os programadores criam esses identificadores de recursos e parâmetros de recursos, com o tempo em que o analista desenvolve a mecânica do experimento. O analista se desenvolve quando o recurso está pronto, e o programador cria esses identificadores quando escreve o código, no início.
Também permite dividir o recurso em pedaços. Suponha que exista um recurso chamado Tradutor, que inclua, de fato, o Tradutor. E há um recurso do TranslateServiceAPITimeout, que inclui funcionalidade adicional que pode definir um tempo limite personalizado para a API do tradutor. Assim, podemos realizar dois grupos de experimentos, nos quais o tradutor está ativado, mas ao mesmo tempo comparamos qual valor é melhor: 300 milissegundos ou 600.
. . (FeatureParam).
, , , . , , . , , . . ?

, : Feature FeatureParam. Feature FeatureParam . , Feature FeatureParam, , . . - , , .
-, Feature&FeatureParam. , «», , , . FeatureParam , , API — 300 600 ?
. . - , . public beta, . , .
, : .

? , , .
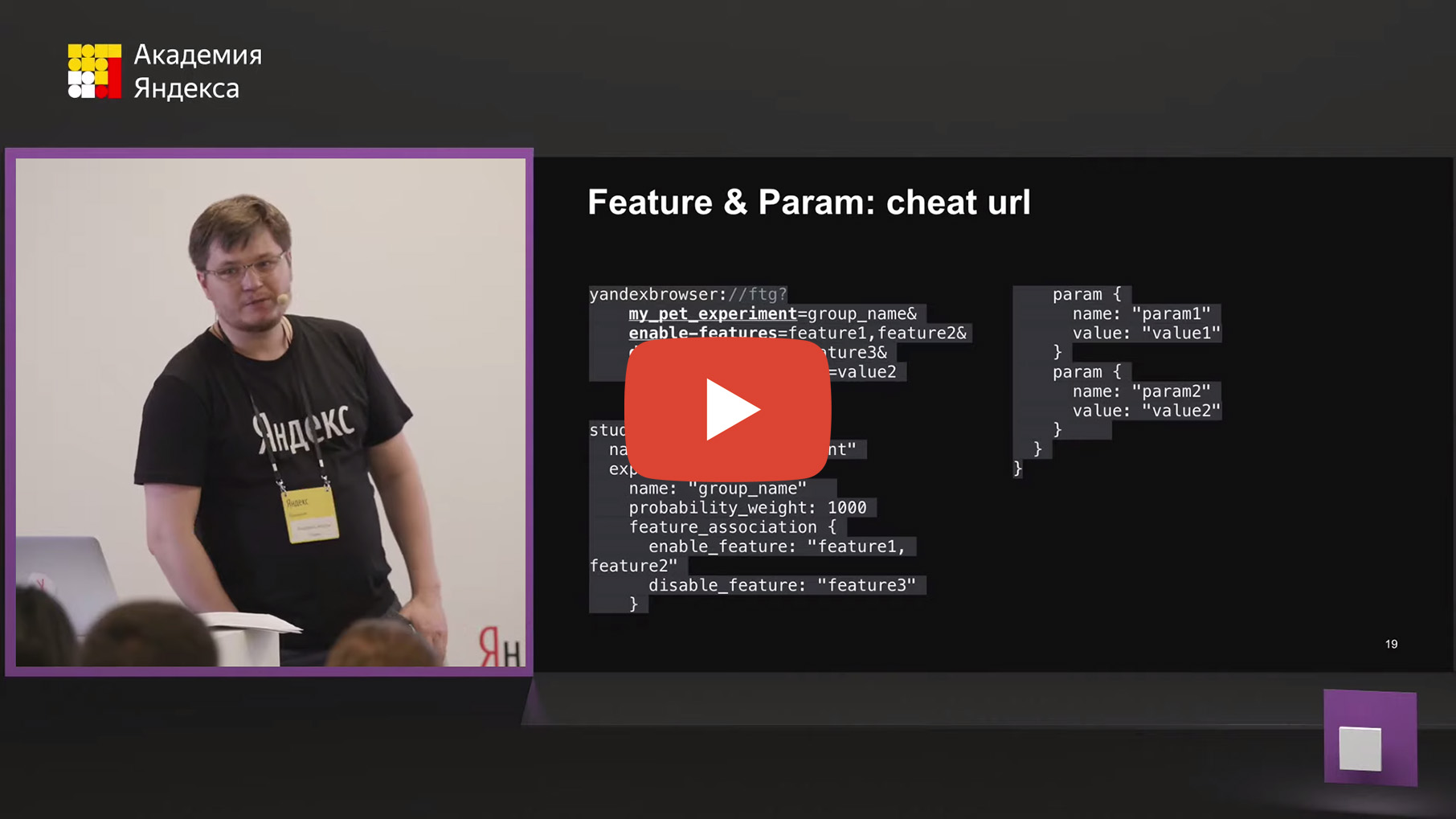
: . URL, , .
: browser://version — show-variations-cmd. : cheat-, . : .
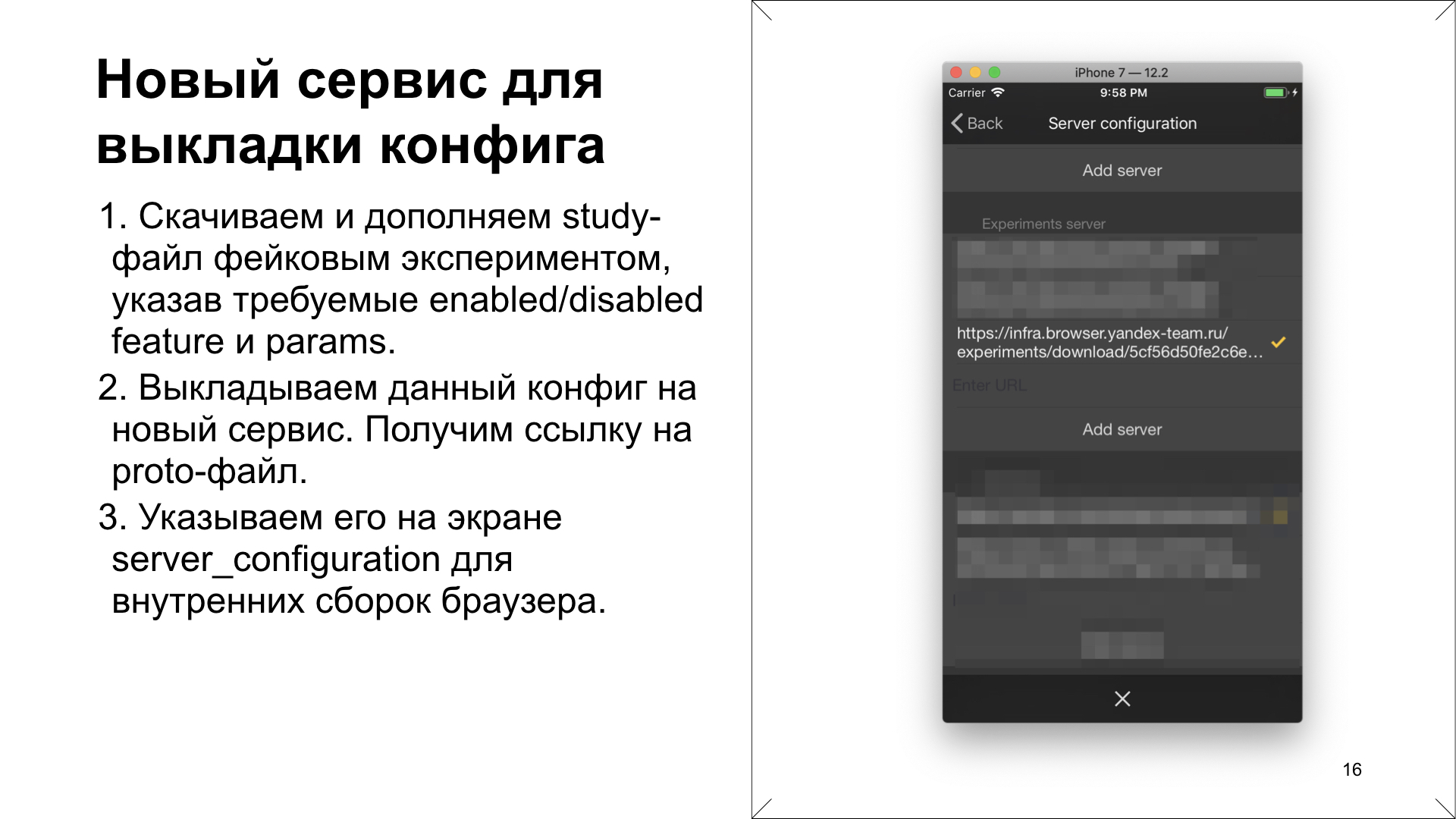
. , . proto- - , study-, . , . Feature&FeatureParam, . , , . , , Feature&FeatureParam .
. proto- . . , . , , .

O segundo Feature&FeatureParam? Chromium, . Chromium browser://version, show-variations-cmd.
: enabled-features, force-fieldtrials force-fieldtrials-params, . , . ? , . , Feature1 trial1. Feature2 trial2. Feature3 .
trial1 group1. trial2 group2. force-fieldtrials-params, , trial1 group1, p1 v1, p2 v2. trial2 group2, p3 v3, p4 v4.
, . Chromium, iOS. , .
. --force-fieldtrials=translator/enabled_new/ enabled_new translator.
--force-fieldtrial-params==translator.enablew_new:timeout/5000, translator enabled_new, , , translator, enabled_new timeout, 5 000 .
--enabled-features=TranslateServiceAPITimeout<translator , - translator translator , , , TranslateServiceAPITimeout. , , , , .

(cheat urls). , , , , , , . . . .
yandexbrowser:// (.), , . . my_pet_experiment=group_name. , enable-features=, , disable-features=, . , &.
(cheat url), . , , , . , , . filter, my_pet_experiment , . 1000, feature_association, , .
, . , , . , — my_pet_experiment — , , . , , study .
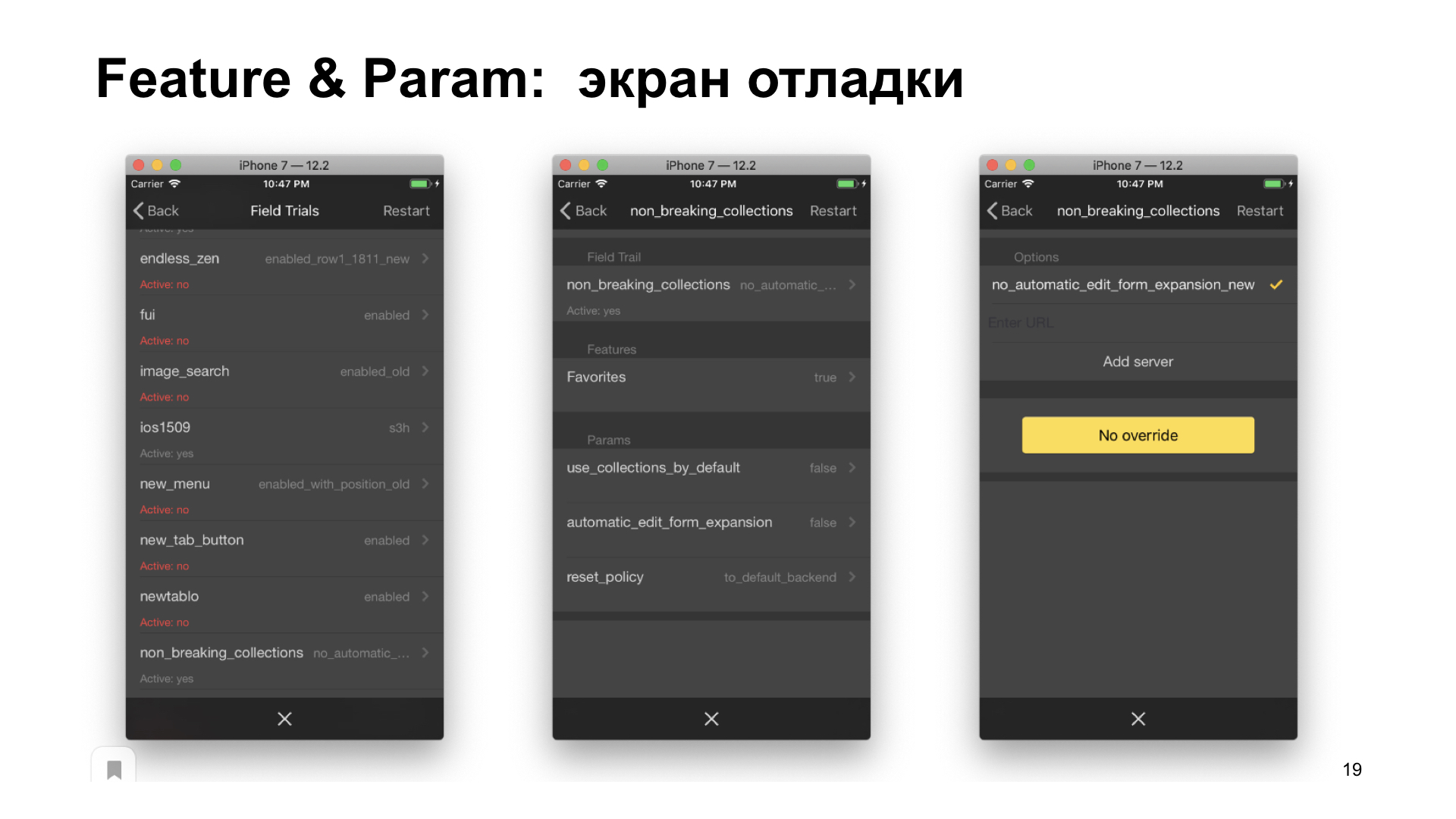
, . — , . . , .
, .

, , , , . , . , .
. . , , ? , . , ?
. .

, . , , UUID, application Identifier, . . hash .
? ? , , UUID, . ? , , . . ? hash hash , . ,
Google, An Efficient Low-Entropy Provider.
, — UUID, , , . , , Chromium.
, , ? ? :
- : , -. .
- . , , , .
- Testável. Você deve ter mecanismos que permitam redefinir os valores de grupos, recursos, parâmetros ou outras entidades necessárias.
- Um em que diferentes primitivas são usadas para análise e programação.
- Expansível. Você deve ver como ele funciona e adaptá-lo às suas necessidades (consulte o serviço de variação do Chromium ).
O sistema Chromium, que estamos expandindo no Yandex.Browser para iOS, possui esses critérios. Conduza seus experimentos, analise-os e aprimore os aplicativos. Obrigada