Foto de Dugan Arnett no Boston Globe
Você ainda está procurando um novo apartamento? Pronto para fazer a última tentativa? Se assim for - siga-me e eu mostro como chegar à linha de chegada.
Breve introdução e referências
É a terceira parte do ciclo direcionada para explicar como você pode encontrar o apartamento ideal no mercado imobiliário. Em poucas palavras, a idéia principal - encontre a melhor oferta entre os apartamentos em Ecaterimburgo, onde eu morava antes. Mas acho que a mesma ideia pode ser considerada no contexto de outra cidade.
Se você não leu as partes anteriores, seria uma boa ideia lê-las Parte1 e Parte2 .
Além disso, você pode descobrir notebooks Ipython por lá .
Essa parte tinha que ser muito menor do que as anteriores, mas o diabo está em detalhes.
Consequências
Como resultado de todas as ações, obtivemos um modelo de ML (floresta aleatória) que funciona muito bem. Não é tão bom quanto esperávamos (a pontuação está acima de 87%), mas para dados reais, é bom o suficiente. E ... deixe-me ser honesto, que pensamentos sobre resultado tiveram um efeito estranho em mim. Eu queria mais pontos, a diferença entre o resultado esperado e a previsão real era menor que 3%. Otimismo misturado com ganância subiu à minha cabeça

Eu quero mais ouro precisão
É amplamente conhecido que, se você deseja melhorar algo, provavelmente haverá abordagens opostas. Geralmente, parece uma escolha entre:
- Evolução vs revolução
- Quantidade versus qualidade
- Extensivo vs intensivo
E devido à falta de vontade de mudar de cavalo no meio do caminho, decidi usar o RF (Random Forest) adicionando alguns novos recursos.
Parecia uma ideia: "só precisamos de mais recursos" para melhorar a pontuação. Pelo menos foi o que pensei.
Per aspera ad astra (através de dificuldades para as estrelas)
Vamos tentar pensar nos recursos relacionados, que podem influenciar o preço de um apartamento. Existem características de apartamento como varanda ou idade da casa e características geográficas como distância da estação de metrô / ônibus mais próxima. O que poderia ser o próximo para a mesma abordagem com RF?
Idéia # 1. Distância ao centro
Poderíamos reutilizar longitude e latitude (coordenadas planas). Com base nessas informações, poderíamos contar a distância do centro da cidade. A mesma idéia foi usada para os distritos, quanto mais longe ficamos do centro, mais barato deveria ser. E adivinhem ... funciona! Não é um crescimento tão grande ( + 1% da pontuação), mas é melhor que nada.
Existe apenas um problema, a mesma ideia não faz sentido para os distritos que estão muito distantes. Se você morasse fora de uma cidade, saberia que existem outras regras para o preço.
Não será fácil para a interpretação se extrapolarmos essa abordagem.
Idéia # 2. Perto do metro
O metrô tem uma influência significativa no preço. Especialmente quando colocado em uma zona de curta distância. Mas o significado de "uma curta distância" não é claro. Cada pessoa pode interpretar esse parâmetro de maneiras diferentes. Eu poderia definir o limite manualmente, mas um aumento de pontuação não seria superior a 0,2%
Ao mesmo tempo, ele não funciona com flat da idéia anterior. Não há metrô nas proximidades.
Idéia # 3. Racionalidade e equilíbrio do mercado
O equilíbrio do mercado é uma combinação de demanda e oferta. Adam Smith falou sobre isso. Obviamente, o mercado pode ser exagerado. Mas, em geral, essa ideia funciona bem. Pelo menos para casas que em processo de construção.
Em outras palavras - quanto mais concorrentes você tiver, menor a probabilidade de as pessoas comprarem seu apartamento (outras coisas são iguais). E isso produz uma suposição - "se ao meu redor forem colocados outros apartamentos, preciso diminuir o preço para obter mais compradores".
E parece uma conclusão bastante lógica, não é?
Então contei apartamentos SIMILARES próximos a cada um deles, na mesma casa e em um raio de 200 metros. As medidas foram tomadas para a data de venda. Qual resultado você esperaria obter? Apenas 0,1% na validação cruzada. Triste, mas é verdade.
Repensando
Sair É ... às vezes, dar um passo atrás e dar dois passos adiante.
- uma pessoa sábia desconhecida
Ok, um ataque frontal não funciona. Vamos considerar esta situação de outro ângulo.
Suponhamos que você seja uma pessoa que queira comprar um apartamento próximo ao rio, longe da cidade barulhenta. Você tem três variantes de anúncio semelhantes entre si e que têm o mesmo preço (mais ou menos). Métricas formais que, descrevendo flat, não oferecem nada sobre o ambiente, são apenas métricas em uma tela. Mas há algo importante.
A descrição de um apartamento é uma excelente oportunidade.
Uma descrição simples pode fornecer tudo o que você precisa. Pode contar uma história sobre apartamento, sobre vizinhos e oportunidades surpreendentes relacionadas a esse local específico. E em algum momento uma descrição poderia fazer mais sentido do que números chatos.
Mas na vida real é um pouco diferente da nossa expectativa. Deixe-me mostrar o que vai / não vai funcionar e por quê.
O que não vai funcionar e por quê?
Expectativas - "Uau! Eu posso tentar classificar o texto e encontrar apartamentos 'bons' e 'ruins'. Usarei o mesmo método que geralmente é usado para a análise de sentimentos".
Realidade - "Não, você não fará isso. As pessoas não escrevem nada de ruim contra o apartamento. Pode haver um encobrimento de uma situação real ou mentira"
Expectativas - "Ok. Então eu posso tentar encontrar padrões e encontrar o público-alvo para um apartamento. Por exemplo, pode ser pessoas idosas ou estudantes".
Realidade - "Não, você não fará isso. Às vezes, um anúncio faz menção a diferentes idades e grupos sociais, é apenas marketing"
O que provavelmente funcionaria e por que
Algumas palavras - chave - existem palavras que apontam para coisas ou momentos específicos relacionados ao apartamento. Por exemplo, quando é um estúdio, o preço seria mais baixo. Em geral, os verbos são inúteis, mas substantivos e advérbios podem dar mais contexto.
A fonte alternativa de informação - Usar a descrição para preencher valores vazios ou NaN mais corretos. Às vezes, a descrição contém mais informações do que características formais do anúncio.
Eu suspeito que, com base na preguiça humana, preencha campos não obrigatórios, como "varanda". Colocar tudo na descrição parece uma idéia mais preferível
Eu pulo a descrição do processo típico de tokenização / lematização / stemming. Além disso, acredito que existem autores capazes de descrevê-lo melhor do que eu.
Embora eu ache que deveria haver uma menção ao conjunto de ferramentas usado para extrair recursos. Em poucas palavras, parece.

separando-> correspondência por parte do discurso
Após o pré-processamento do texto do anúncio, recebi um conjunto de palavras em russo como estas.

O texto original é colocado https://pastebin.com/Pxh8zVe3
Tentei usar a abordagem do Word2Vec, mas não havia um dicionário especial para apartamentos e propagandas, então a imagem geral parecia estranha
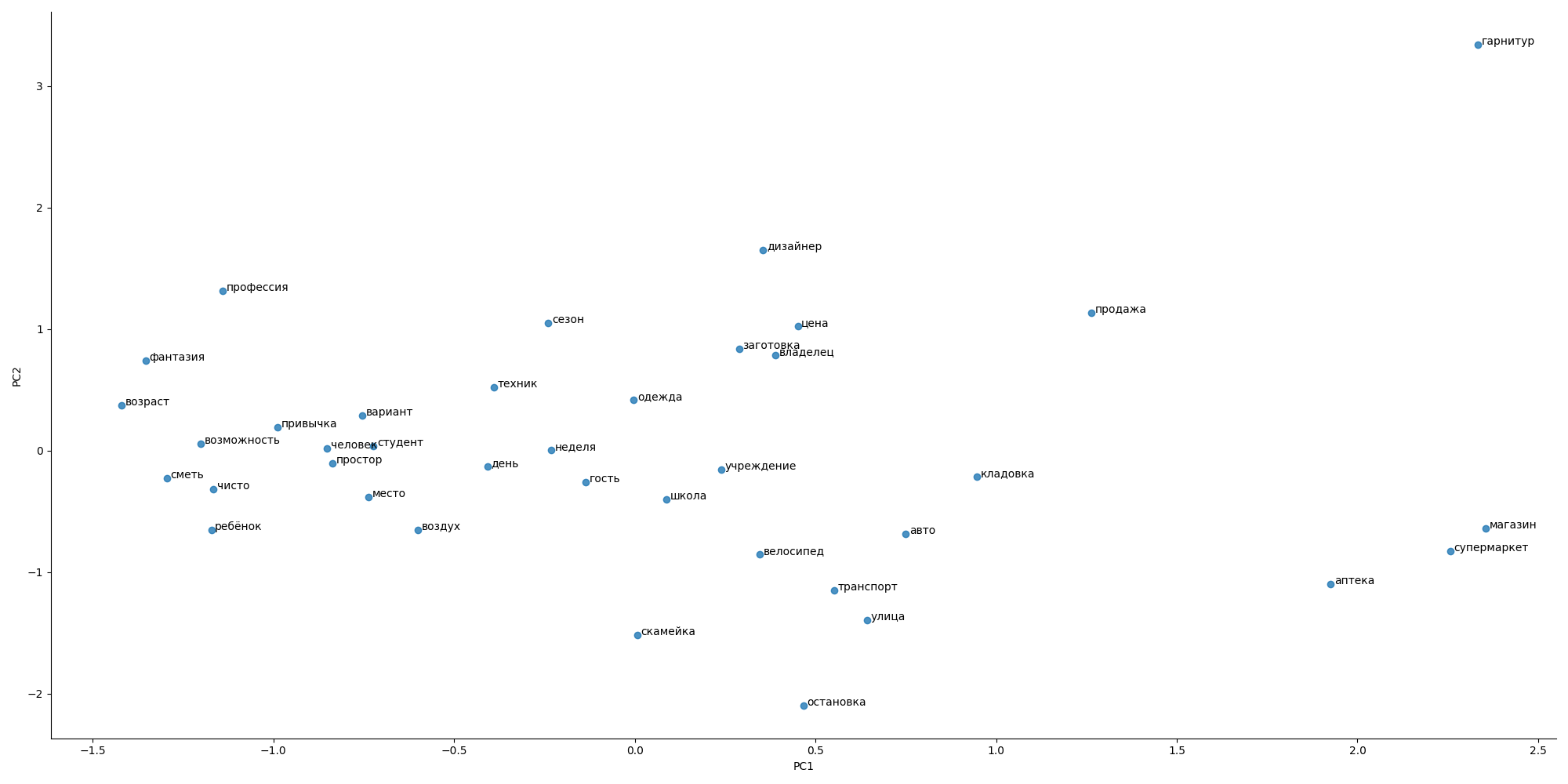
a distância entre as palavras não é adequada às expectativas
Portanto, eu o mantive o mais simples possível e decidi criar várias novas colunas para o conjunto de dados
Um pouco menos de conversa, um pouco mais de ação
Hora de sujar as mãos e fazer algumas coisas práticas. Descubra novos recursos. Vários fatores importantes foram separados por uma influência no preço.
impacto positivo
- móveis - às vezes as pessoas podiam deixar uma cama, uma lavadora e assim por diante.
- luxo - apartamentos com itens luxuosos como jacuzzi ou um interior exclusivo
- controle de vídeo - faz com que as pessoas se sintam seguras, frequentemente o considera uma vantagem
impacto negativo
- dormitório - sim, às vezes é um apartamento em um dormitório. Não é tão popular, mas significativamente mais barato que um apartamento médio
- pressa - quando as pessoas correm para vender seu apartamento, geralmente estão prontas para diminuir o preço.
- estúdio - como eu disse antes - eles são mais baratos que seus análogos planos.
Vamos colecioná-los em algo universal
df3 = pd.read_csv('flats3.csv') positive_impact = ['', 'luxury',''] negative_impact = ['studio', 'rush','dorm'] geo_features = ['metro','num_of_stops_1km','num_of_shops_1km','num_of_kindergarden_1km', 'num_of_medical_1km','center_distance'] flat_features=['total_area', 'repair','balcony_y', 'walls_y','district_y', 'age_y'] competitors_features = ['distance_200m', 'same_house'] cols = ['cost'] cols+=flat_features cols+=geo_features cols+=competitors_features cols+=positive_impact cols+=negative_impact df3 = df3[cols]
impacto geral
é apenas uma combinação de características negativas e positivas. Inicialmente, para cada apartamento, é igual a 0. Por exemplo, estúdio com controle de vídeo ainda terá impacto geral igual a 0 ( 1 [positivo] –1 [negativo] = 0 )
df3['impact'] = 0 for i, row in df3.iterrows(): impact = 0 for positive in positive_impact: if row[positive]: impact+=1 for negative in negative_impact: if row[negative]: impact-=1 df3.at[i, 'impact'] = impact
Ok, temos dados, novos recursos e destino antigo com 10% de erro médio para previsão. Faça alguma operação típica como fizemos antes
y = df3.cost X = df3.drop(columns=['cost']) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Abordagem antiga (amplo crescimento de recursos)
Faremos um novo modelo baseado em idéias antigas
data = [] max_features = int(X.shape[1]/2) for x in range(1,20): regressor = RandomForestRegressor(verbose=0, n_estimators=128, max_features=max_features, max_depth=x, random_state=42) model = regressor.fit(X_train, y_train) score = do_cross_validation(X, y, model) data.append({'max_depth':x,'score':score}) data = pd.DataFrame(data) f, ax = plot.subplots(figsize=(10, 10)) sns.lineplot(x="max_depth", y="score", data=data) max_result = data.loc[data['score'].idxmax()] ax.set_title(f'Max score - {max_result.score}\nDepth {max_result.max_depth} ')
E o resultado foi um pouco ... inesperado.
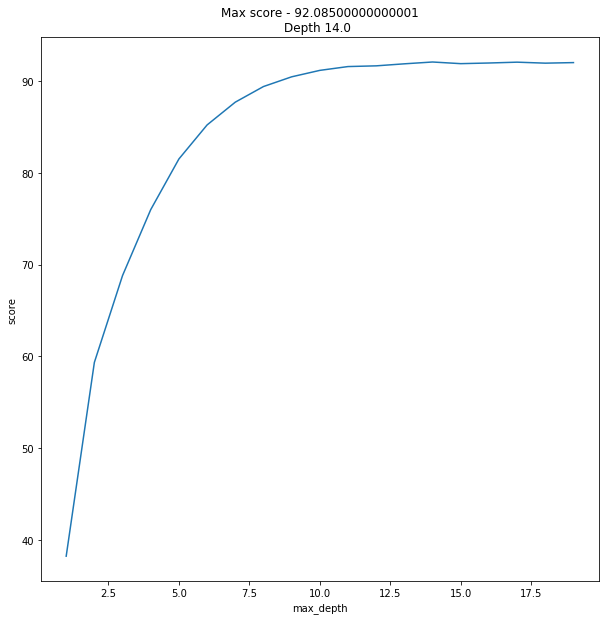
92% é resultado esmagador. Quero dizer, dizer que fiquei chocado seria um eufemismo.
Mas por que funcionou tão bem? Vamos dar uma olhada nos novos recursos.
regressor = RandomForestRegressor(random_state=42, max_depth=max_result.max_depth, n_estimators=128, max_features=max_features) rf3 = regressor.fit(X_train, y_train) feat_importances = pd.Series(rf3.feature_importances_, index=X.columns) feat_importances.nlargest(X.shape[1]).plot(kind='barh')
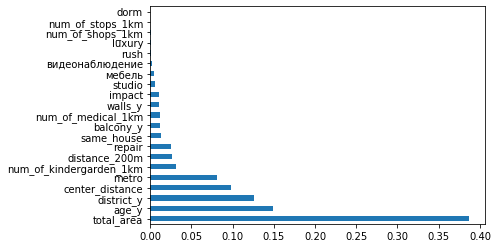
Importância de todos os recursos para o nosso modelo
A importância não fornece informações sobre a contribuição dos recursos (ou seja, uma história diferente), apenas mostra como o modelo ativo usa um ou outro recurso. Mas para a situação atual, parece informativo. Alguns dos novos recursos são mais importantes que os anteriores, outros quase inúteis.
Nova abordagem (trabalho intensivo com dados)
Bem ... a linha de chegada está cruzada, o resultado é alcançado. Poderia ser melhor?
Resposta curta - "Sim, poderia"
- Primeiro, poderíamos reduzir a profundidade de uma árvore. Isso levará a um tempo menor para treinamento e previsão também.
- Segundo, poderíamos aumentar um pouco a previsão.
Nos dois momentos, usaremos o XGBoost . Às vezes, as pessoas preferem usar outros boosters como LightGBM ou CatBoost , mas minha humilde opinião - a primeira é boa o suficiente quando você tem muitos dados, a segunda é melhor se você trabalha com variáveis categóricas. E como um bônus - o XGBoost parece mais rápido
from xgboost import XGBRegressor,plot_importance data = [] for x in range(3,10): regressor = XGBRegressor(verbose=0, reg_lambda=10, n_estimators=1000, objective='reg:squarederror', max_depth=x, random_state=42) model = regressor.fit(X_train, y_train) score = do_cross_validation(X, y, model) data.append({'max_depth':x,'score':score}) data = pd.DataFrame(data) f, ax = plot.subplots(figsize=(10, 10)) sns.lineplot(x="max_depth", y="score", data=data) max_result = data.loc[data['score'].idxmax()] ax.set_title(f'Max score-{max_result.score}\nDepth {max_result.max_depth} ')

O resultado é melhor que o anterior.
Obviamente, não é a grande diferença entre a Random Forest e o XGBoost. E cada um deles pode ser usado como uma boa ferramenta para resolver nosso problema com previsão. Depende de você.
Conclusão
O resultado foi alcançado? Definitivamente sim.
A solução está disponível lá e pode ser usada gratuitamente por qualquer pessoa. Se você estiver interessado na avaliação de um apartamento usando essa abordagem, não hesite em entrar em contato comigo.
Como protótipo, ele colocou lá
Obrigado pela leitura! .