
Oi Habr. Recentemente, houve uma competição de Tinkoff e McKinsey. A competição foi realizada em duas etapas: a primeira - qualificação, no formato kaggle, ou seja, enviar previsões - faça uma avaliação da qualidade da previsão; o vencedor é aquele com a melhor pontuação. O segundo é o hackathon no local, em Moscou, que abriga as 20 melhores equipes da primeira etapa. Neste artigo, falarei sobre a fase de qualificação, onde consegui ocupar o primeiro lugar e ganhar o MacBook. A equipe na tabela de classificação foi chamada de "filhos de Lesha".
A competição foi realizada de 19 de setembro a 12 de outubro. Comecei a resolver exatamente uma semana antes do final e decidi quase em tempo integral.
Breve descrição do concurso:
No verão, surgiram histórias no aplicativo bancário Tinkoff (como no Instagram). Na história, você pode reagir como, não gostar, pular ou visualizar até o fim. A tarefa é prever a reação do usuário à história.
A competição é principalmente tabular, mas as próprias histórias têm texto e imagens.
Plano de história

Métrica
A previsão de reação pode levar um valor de -1 a 1, inclusive - quanto mais próximo de 1, maior a probabilidade de gostar. E com o valor -1, é melhor remover esta história dos olhos do usuário.
Para verificar a precisão das soluções, é utilizada uma fórmula, normalizada com o máximo resultado possível:
\ begin {array} {l} {\ text {weight (event)} = \ left \ {\ begin {array} {ll} {- 10} e {\ text {antipatia}} \\ {-0,1} e {\ text {skip}} \\ {0.1} & {\ text {view}} \\ {0.5} & {\ text {like}} \ end {array} \ right.} \\ [15pt] {\ text {Métrica} \ left (y _ {\ text {pred}} \ right) = \ sum_ {i = 1} ^ {n} \ left (\ text {weight} \ left (\ text {evento} _ {i} \ direita) \ cdot y _ {\ text {pred,} i} \ direita)} \ end {array}
Quais dados existem:
- Informações básicas do usuário
- Transações do usuário
- Informações sobre a história (json a partir da qual você pode construí-la)
- História das reações dos usuários às histórias.
A seguir, falarei detalhadamente sobre cada dado, como os processei e quais recursos (a seguir denominados recursos) extraímos.

o que é originalmente:
- ID do usuário
- produtos bancários anônimos que o usuário abriu (OPN), usa (UTL) ou fechou (CLS)
- sexo, idade binarizada, estado civil, primeira entrada no aplicativo
- job_title - o que as pessoas escrevem sobre si mesmas
- job_position_cd - título do trabalho de uma pessoa, como uma das 22 categorias
como recursos, usamos todos os itens acima, exceto job_title, porque assumimos que job_position_cd normalmente descreve a posição de uma pessoa.
Transações

o que é originalmente:
- ID do usuário
- dia, mês da transação
- valor da transação (binarizado em incrementos de 250)
- merchant_id - ID interno do banco da caixa registradora. Além disso não é usado.
- merchant_mcc
MCC - código da categoria do comerciante. Este é o código de serviço padronizado fornecido pelo destinatário. Esta informação está aberta, aqui está uma transcrição . Esses códigos podem ser convenientemente divididos em categorias, por exemplo: entretenimento, hotéis etc.
Para cada customer_id, comparamos os seguintes recursos:
- calcular a quantia de despesas, verificação média, desvio padrão
- número de transações
- Dividimos os códigos mcc em 20 categorias e calculamos quantas pessoas gastaram dinheiro nessa categoria. Obtenha 20 recursos
- obteremos outros 20 recursos dividindo as despesas na categoria pelo valor das despesas. I.e. obtenha a porcentagem de dinheiro gasto na categoria.
Histórias
No total, temos 959 histórias.
o que é originalmente:
json aparece assim:

Essa é uma árvore de elementos em que cada elemento é descrito por chaves: ['guid', 'type', 'description', 'properties', 'content']. O 'conteúdo' contém uma lista de filhos. A história consiste em páginas. O plano de fundo, o texto e as imagens são mostrados na página. Não tínhamos um construtor de histórias, e desenhar tudo isso é bastante difícil e não é um fato, o que ajudará bastante no futuro.
Os regulares extraem todo o texto e o tamanho da fonte correspondente. Extraímos os seguintes recursos:
- número de páginas, links, elementos totais
- tamanho médio da fonte do texto
- número de elementos de texto
- "volume do texto" é uma heurística para considerar cuidadosamente o tamanho do texto, dependendo do tamanho da fonte.
Código de contagem de volumedef get_text_amount(all_text, font_sizes): assert len(all_text) == len(font_sizes) lengths = np.array(list(map(len, all_text))) sizes = (np.array(font_sizes) / 100)**2 return (lengths * sizes).sum()
- Agora vamos pegar o texto inteiro. Usando dostoevsky , definimos a semântica do texto: ['neutro', 'negativo', 'pular', 'discurso', 'positivo']. E adicione isso como 5 recursos
Reacções

o que é originalmente:
- ID do usuário e histórico
- o tempo
- reação
Processamos o tempo e adicionamos recursos como recursos:
- dia da semana
- hora, minuto
Em seguida, um grupo de recursos será adicionado com base nos dados das reações, mas, por enquanto, vamos batalhar com esse arsenal de recursos para formar uma linha de base.
A melhor abordagem usada por todo o topo é a seguinte: reduzimos o problema a uma classificação multiclasse, ou seja, prever a probabilidade de cada reação. Consideramos a expectativa de uma avaliação para esta história :
Binarizar :
- nossa resposta para o objeto que pode assumir valor
Modelo
Do começo ao fim, usei o CatBoost. Isso se deve ao fato de que o CatBoost pronto para compilar cria estatísticas úteis para recursos categóricos. E estatísticas sobre o usuário - quanto ele está inclinado a quais reações e estatísticas sobre a história - como elas geralmente não reagem, são os recursos mais poderosos nesta tarefa.
Como o CatBoost funciona com recursos categóricos está bem explicado na documentação .
TLDR:
- gera várias permutações de dados
- vai em ordem e constrói a codificação de destino média (mte) nos objetos que ele já viu
brevemente sobre mte em nosso exemplotomamos o valor do sinal, por exemplo, um de customer_id, consideramos a porcentagem de casos em que esse cliente reagiu como, não gosta, pulou ou visualizou. Temos 4 números. Substituímos customer_id por esses 4 números e os usamos como sinais. Fazemos isso para cada customer_id.
Resultado atual
Com os recursos atuais, com uma catbust não otimizada, na tabela de classificação pública da época, eu ocupava o 11º lugar com um resultado de 0,31209
Recursos assassinos
Em algum momento, surgiu uma hipótese de que o aplicativo pode mostrar histórias com mais ou menos frequência, dependendo de como o usuário reagiu a ele anteriormente. Vamos então adicionar recursos que dirão:
- Quantas vezes o usuário viu o histórico correspondente no passado / futuro, durante o mês / dia / hora / total
- tempo desde a última visualização da mesma história
- tempo após o qual o usuário na próxima vez olha para a mesma história
- de fato, o usuário carrega várias histórias ao mesmo tempo em um segundo, geralmente em torno de 5-7. Chame esse conjunto de histórias de grupo . Eu adicionei esse número de histórias no grupo como um recurso, o que deu um grande aumento na qualidade.
Obviamente, esses recursos não podem ser usados na produção, porque eles não serão brega no momento da aplicação do modelo, mas na competição todos os meios são bons.
Então, diz-se - feito. Obteve 0,35657 na tabela de classificação.
Otimização de modelo
Analisei os parâmetros usando otimização bayesiana
Interessante, podemos mencionar o parâmetro max_ctr_complexity, responsável pelo número máximo de recursos categóricos que podem ser combinados. Exemplo sob o spoiler.
Trecho da documentaçãoSuponha que os objetos no conjunto de treinamento pertençam a duas características categóricas: o gênero musical (“rock”, “indie”) e o estilo musical (“dance”, “classical”). Esses recursos podem ocorrer em diferentes combinações. O CatBoost pode criar um novo recurso que é uma combinação dos listados (“dance rock”, “rock clássico”, “indie de dança” ou “indie clássico”).
Observações interessantes
O CatBoost pode ser treinado na GPU, isso acelera significativamente o aprendizado, mas também introduz muitas restrições, especialmente em relação aos recursos categóricos. Nesta tarefa, o treinamento na GPU deu um resultado muito pior do que na CPU.
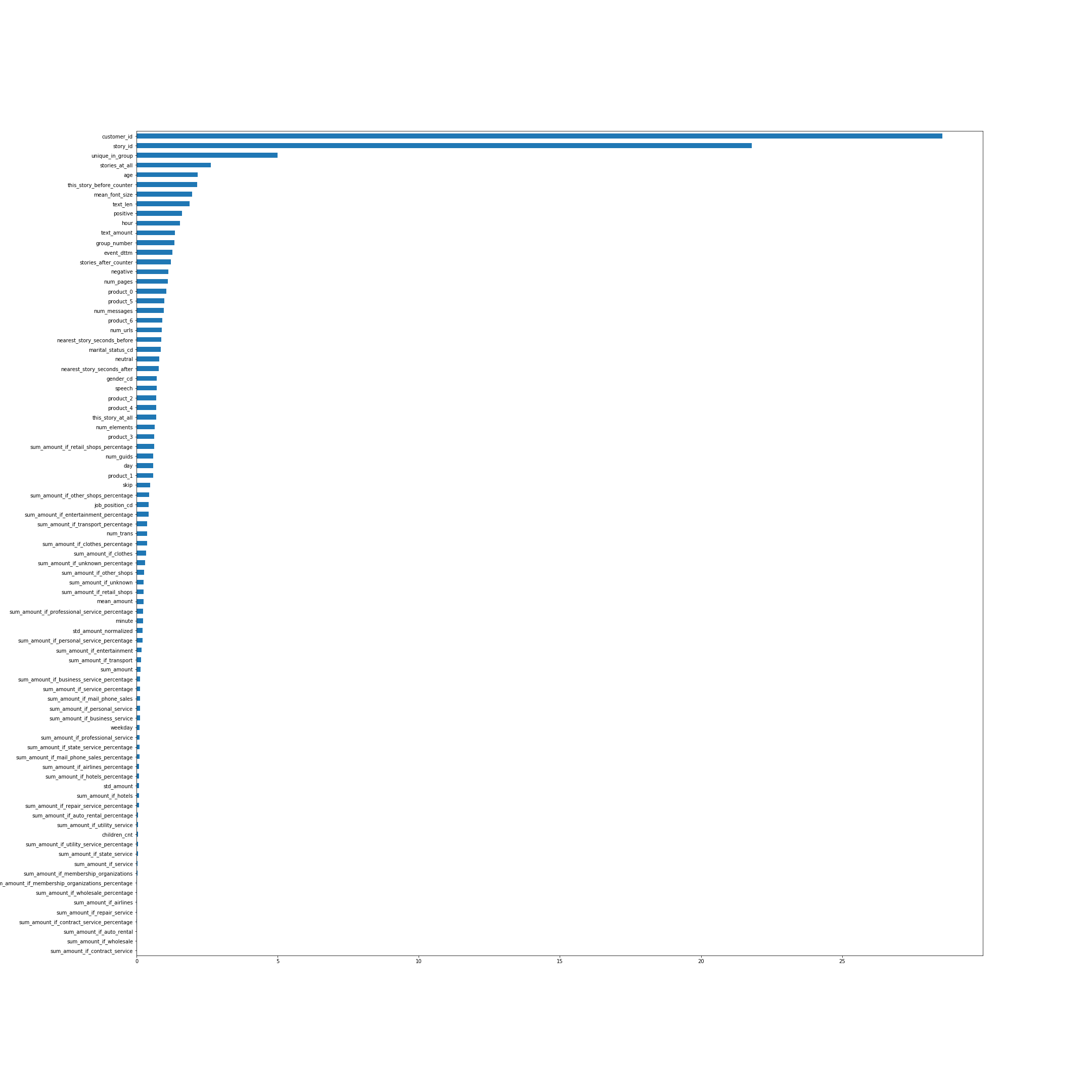
A importância dos recursos de acordo com o CatBoost. De várias maneiras, os nomes dos recursos falam por si, mas alguns, não os mais óbvios do topo, explicarei:
- unique_in_group - o número de histórias no grupo. (Dentro do grupo, eles são sempre únicos, no momento em que o recurso foi criado, eu não sabia disso)
- stories_at_all - o número de histórias que uma pessoa visualizou no futuro e no passado.
- this_story_before_counter - quantas vezes as pessoas assistiram a essa história antes.
- quantidade_de texto - essa heurística com o volume do texto.
- group_number - número de série do grupo.
- closest_story_seconds_before / after - essencialmente este é o tempo até o próximo grupo ser exibido.
A imagem é clicável.
Vejamos a distribuição das reações ao longo do tempo:

I.e. em algum momento, a distribuição das reações varia muito.
Em seguida, quero obter alguma confirmação de que a distribuição no teste é a mesma que no final da amostra de treinamento. Vamos enviar como previsão todos, obtemos o resultado 0,00237. Prevemos todos na última parte do trem - obtemos cerca de 0,009, na primeira parte - cerca de -0,22. Portanto, a distribuição no teste provavelmente é a mesma do final do trem e definitivamente não se parece com a parte principal. Isso gera a hipótese de que, se a distribuição for corrigida em nossas previsões, o resultado na tabela de classificação melhorará bastante, porque as distribuições no trem e no teste são diferentes.
Previsões de Threshhold
Na última etapa da obtenção das previsões finais, adicione um thrashhold:
No último modelo, eu tinha algo em torno de 66% das unidades, se binarizado com uma lixeira igual a 0. Aconteceu que, de fato, uma diminuição no número de +1 deu um forte aumento na qualidade. Apenas as três últimas premissas foram avaliadas, então enviei as previsões do melhor modelo com diferentes lixeiras, de modo que a porcentagem mais uma fosse de cerca de 62, 58 e 54.
Como resultado, em uma tabela pública de líderes, meu melhor resultado foi 0,37970 .
Resultados da Competição
sobre classificações públicas / privadasComo é habitual nas competições de aprendizado de máquina, quando você envia previsões ao sistema, o resultado é avaliado apenas para parte de toda a amostra de teste. Geralmente cerca de 30%. Os resultados desta parte estão refletidos no ranking público. Para o restante do teste, o resultado final é avaliado, que é exibido após o final da competição em uma tabela de classificação privada.
No final da competição no ranking público, a situação era a seguinte:
- 0.382 - HereCould BeYourAdvertising
- 0.379 - Filhos de Lesha
- 0.372 - Jardineiros
- 0.35 - preguiçoso e akulov
Em uma tabela de classificação privada, segundo a qual os resultados finais foram considerados, tive sorte e, por algum motivo, os caras caíram de quarto para quarto. Aqui está a posição final.
- 0.45807 filhos de Lesha
- 0.45264 Jardineiros
- 0.44136 Zhuk
- 0,43704 Aqui, pode ser o seu anúncio
- 0.43474 lazy & akulov
O que não deu certo
- Tentei traduzir todo o texto da história em um vetor usando o texto rápido, depois agrupei os vetores e usei o número do cluster como um recurso categórico. Esse recurso foi o principal (depois de story_id e customer_id) na importância do recurso do CatBoost, mas por alguma razão foi estável e piorou significativamente o resultado da validação.
- Graças aos clusters, pudemos encontrar histórias relacionadas à Copa do Mundo e estavam presentes apenas no conjunto de treinamento.
No entanto, a ejeção desses objetos do conjunto de dados não melhorou o resultado. - por padrão, o CatBoost gera permutações aleatórias de objetos e considera sinais de recursos categóricos baseados neles. Mas podemos dizer ao katbust que temos tempo nos dados - has_time = True. Depois, ele será executado em ordem, sem misturar o conjunto de dados. Nesse problema, apesar de termos tempo, o resultado com has_time foi consideravelmente pior.
No caso geral, se houver tempo, mas isso não deve ser levado em consideração ao construir a codificação de destino médio, o modelo usará informações sobre as respostas corretas do futuro e poderá treiná-lo novamente. Aparentemente, nesse problema, isso não teve muito efeito e era mais importante passar várias vezes em diferentes permutações. - Havia uma ideia de atribuir mais peso aos objetos no final do trem, ou seja, levar em conta mais objetos com a distribuição correta de reações. Mas tanto na validação quanto na tabela de classificação pública, isso deu um resultado pior.
- Você pode levar em consideração diferentes reações com pesos diferentes durante o treinamento. Embora isso não tenha melhorado para mim, ajudou algumas equipes.
Conclusões
A competição acabou sendo interessante, porque reuniu muitos componentes, como dados tabulares, textos e imagens. Havia muito espaço para pesquisa, muito com o qual ainda podia ser experimentado. Em geral, eu não precisava me cansar.
Obrigado aos organizadores do concurso!
Todo o código é publicado no github .