Apresento a você a tradução de outro relatório do HaxeUp Sessions 2019 Linz , acredito que seja um bom complemento para o anterior , porque continua o tema das mudanças no Haxe ocorridas em 2019, bem como uma pequena conversa sobre seu futuro.
Um pouco sobre o autor do relatório: Aurel Bili se reuniu com Haxe , participando de vários atolamentos de jogos, e ele continua a participar deles (por exemplo, aqui está o jogo do último Ludum Dare 45 ).

Atualmente, Aurel está concluindo os estudos no Imperial College London, o que implica estágios obrigatórios. O primeiro estágio que ele realizou foi em um escritório remoto, o caminho para o qual demorou muito tempo. Portanto, ele esperava que a próxima prática fosse possível passar remotamente.

Aconteceu que a Fundação Haxe por um longo tempo não conseguiu encontrar um funcionário para o cargo de desenvolvedor do compilador. Aurel decidiu tentar a sorte e enviou uma carta solicitando trabalho remoto. Ele teve sorte - foi aceito em um estágio de seis meses com a oportunidade de trabalhar em Londres.
Ao configurar o dispositivo, foi acordado o conjunto de tarefas nas quais Aurel estava envolvido (embora nem tudo tenha sido realizado).

O que ele fez?
Primeiramente, a documentação , que estava em um estado triste: todas as alterações na sintaxe, novos recursos da linguagem e compilador foram descritos, seções sobre strings, literais e constantes foram complementadas.
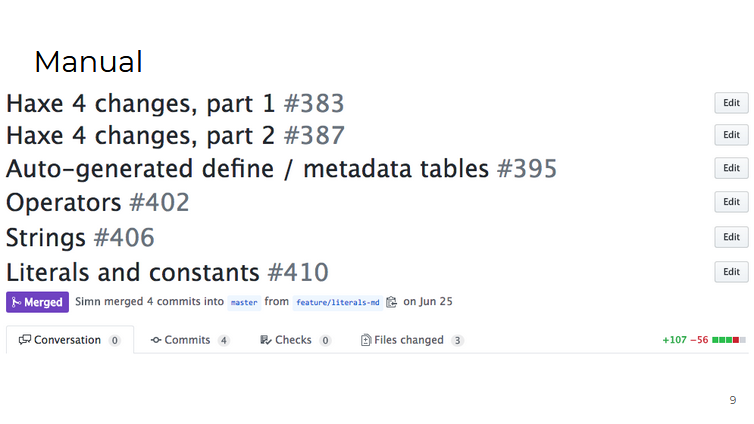
Toda a documentação foi traduzida do LaTeX para o Markdown !
Em segundo lugar, a formatação do código da biblioteca padrão foi reduzida para um único estilo (já que pessoas diferentes com estilos diferentes de design de código trabalharam nele por mais de 10 anos). Assim, no repositório do compilador Haxe, Aurel ficou em sétimo lugar no número de linhas de código adicionadas :)
Em terceiro lugar, Aurel também trabalhou na biblioteca e compilador padrão:
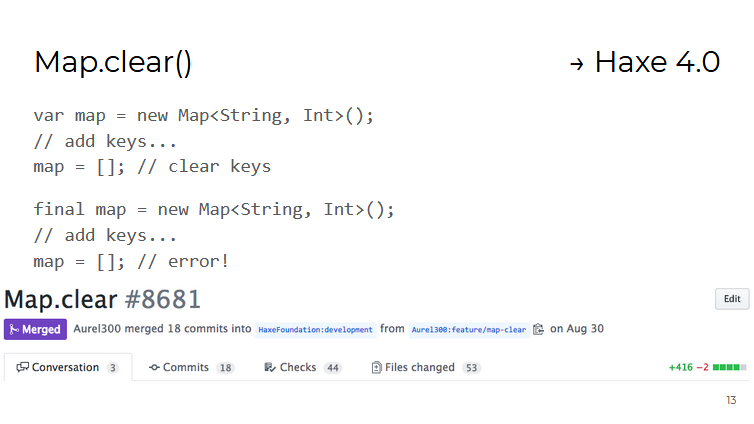
Por exemplo, o container Map possui um novo método clear() que remove todos os valores armazenados. Isso foi feito principalmente para a conveniência de trabalhar com contêineres criados como variáveis final (ou seja, eles não podem receber um novo valor, mas podem ser modificados):
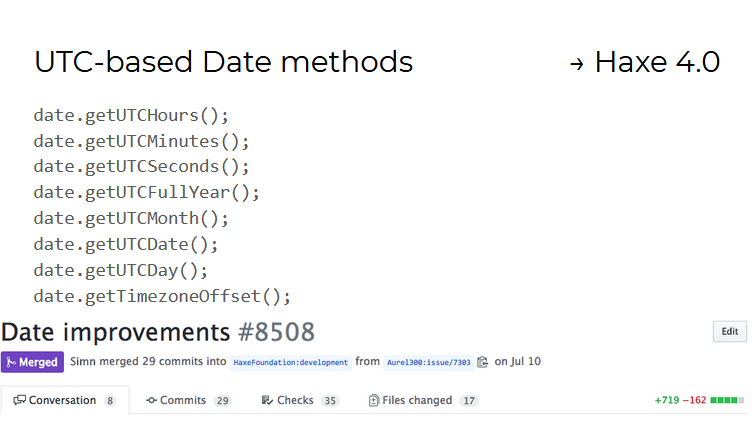
Para objetos do tipo Date , métodos para trabalhar com datas no formato UTC (horário universal universal) apareceram. O trabalho neles mostrou o quão difícil é implementar uma única API que funcione igualmente em todos os 11 idiomas / plataformas suportados pelo Haxe.
No compilador antigo, as definições e metatags foram definidas no OCaml, mas agora são descritas no formato JSON, o que deve simplificar a análise por utilitários externos (por exemplo, para gerar automaticamente a documentação):

Você também pode perceber que em projetos grandes, o servidor de compilação começa a usar muita memória.
Para resolver esse problema, Simon Kraevsky e Aurel desenvolveram o formato binário hxb, usado para serializar o AST digitado. Agora, o servidor de compilação pode carregar o módulo na memória, trabalhar com ele até que seja necessário e, em seguida, descarregá-lo da memória para um arquivo no formato hxb e liberar a memória ocupada.

A especificação do formato hxb está disponível em um repositório separado e sua implementação atual no compilador (com serializador / desserializador) fica em uma ramificação Haxe separada . O trabalho sobre esse recurso ainda não foi concluído e talvez seja exibido no Haxe 4.1.

O quarto e principal foco do trabalho de Aurel durante o estágio foi a criação de uma nova API de sistema assíncrono - asys.

A necessidade de sua criação se deve ao fato de a API existente não fornecer maneiras fáceis de executar operações do sistema de forma assíncrona. Por exemplo, para trabalhar com arquivos de forma assíncrona, você precisará criar um encadeamento separado no qual as operações necessárias serão executadas e controlar manualmente seu estado. Além disso, a API atual não possui toda a funcionalidade para trabalhar com soquetes UDP, que estão em bibliotecas padrão em outros idiomas, não há suporte para soquetes IPC.

Ao criar e implementar uma nova API, surgem muitas perguntas:
Como projetar uma API? Talvez valha a pena tomar um existente como exemplo? Afinal, não queremos criar tudo do zero, porque isso levará mais tempo e poderá não ser do gosto do resto da equipe e causar muito debate.
E, como já mencionado, o problema real do Haxe é a implementação de uma única API para todas as plataformas suportadas.

A API Node.js. foi escolhida como uma amostra. É bem pensado, suporta as funções necessárias do sistema e é adequado para a criação de aplicativos de servidor.

Mas, ao mesmo tempo, a API do Node.js. é uma API Javascript sem digitação forte. Por exemplo, funções do módulo fs para trabalhar com o sistema de arquivos podem assumir como caminhos cadeias de caracteres ou objetos como Buffer e até URL . E isso não é tão bom para Haxe.

O Node.js, por sua vez, usa a biblioteca libuv escrita em C. Trabalhar com a API libuv diretamente do Haxe não seria tão conveniente: por exemplo, para renomear o arquivo de forma assíncrona, você precisaria criar adicionalmente objetos como uv_loop_t (estrutura para gerenciamento loop de evento no libuv) e uv_fs_t (estrutura para descrever uma solicitação ao sistema de arquivos):

Como resultado, as APIs Node.js e libuv foram integradas da seguinte maneira (usando o interpretador de macro eval e o método de rename como exemplo):
- eles pegaram o método API do Node.js, o converteram no Haxe, tentando padronizar os tipos de argumentos e se livrar dos argumentos redundantes para o Haxe. Por exemplo, argumentos de caminho (do tipo
FilePath ) são abstratos sobre cadeias:

- Em seguida, criei os ligadores OCaml para este método:

- OCaml e C vinculados (usando CFFI - C Foreign Function Interface):

- e finalmente escreveu C-binders para chamar funções libuv C do OCaml:

Da mesma forma, isso foi feito para o HashLink e o Neko (por enquanto, a API asys é implementada apenas para essas três plataformas). Como você pode imaginar, foi preciso muito trabalho.
Aurel mostrou alguns aplicativos pequenos que demonstram como a API do asys funciona.
O primeiro exemplo é uma demonstração de leitura assíncrona do conteúdo de um arquivo. Até o momento, o código chama explicitamente métodos para inicializar o libuv ( hl.Uv.init() ) e iniciar o ciclo do aplicativo ( hl.Uv.run() ), devido ao fato de que o trabalho na API não foi concluído (mas no futuro) eles serão adicionados automaticamente):
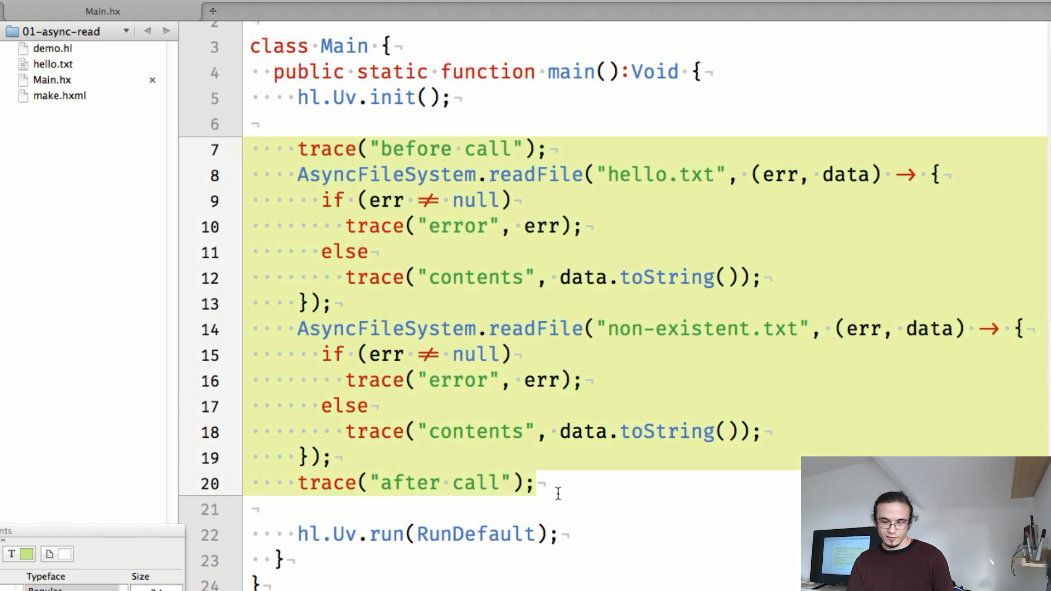
O resultado do código mostrado:
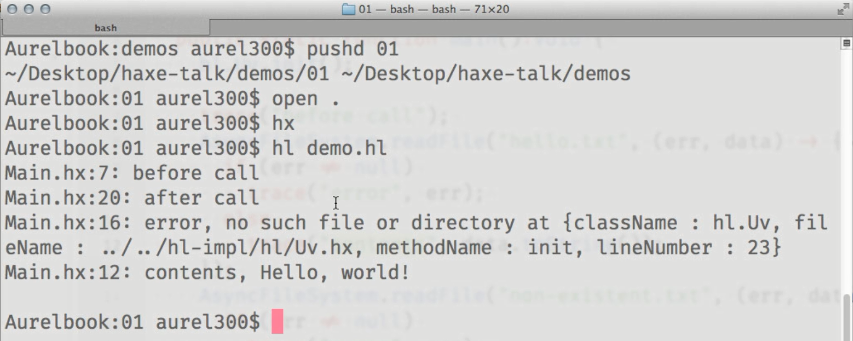
Vimos que os resultados dos métodos chamados AsyncFileSystem.readFile() são exibidos no console após o rastreamento de "após chamada", que é chamado no código depois de tentar ler o conteúdo dos arquivos.
O segundo exemplo é uma demonstração de operação assíncrona com endereços DNS e IP.
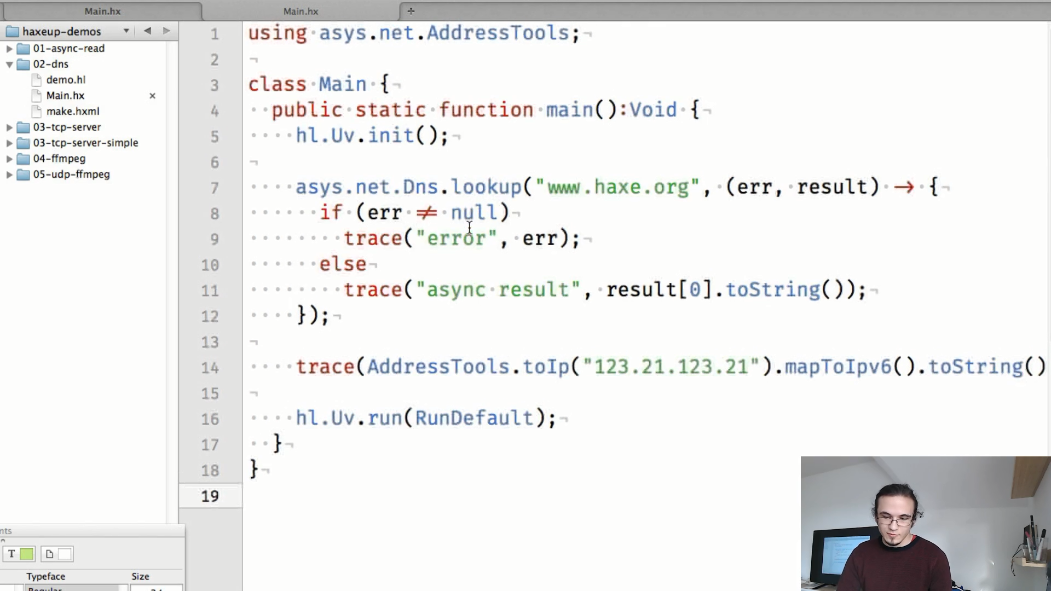
Na nova API, será muito mais fácil determinar o nome do host, bem como métodos auxiliares para trabalhar com endereços IP.
O terceiro exemplo é um servidor de eco TCP simples, que requer apenas três linhas de código para criar:

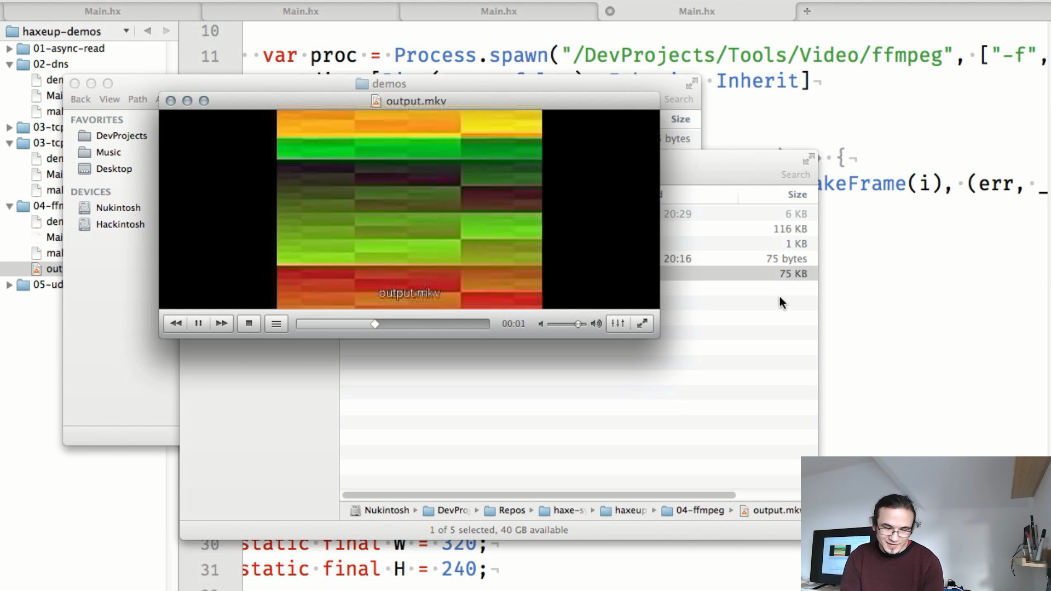
Um quarto exemplo é uma demonstração da troca de informações entre processos:
o método estático makeFrame() neste exemplo cria imagens png separadas:

e no método main , iniciamos o processo ffmpeg, para o qual transferiremos os quadros gerados em makeFrame() :
e a saída será um arquivo de vídeo:
E o quinto exemplo é o fluxo de vídeo UDP. Aqui, como no exemplo anterior, o processo ffmpeg é iniciado, mas desta vez ele reproduz o vídeo e envia seus dados para o fluxo de saída padrão. Também é criado um soquete UDP que converterá os dados do processo ffmpeg.

E finalmente, dividimos os dados recebidos do ffmpeg em "partes" menores e os convertemos para a porta especificada:
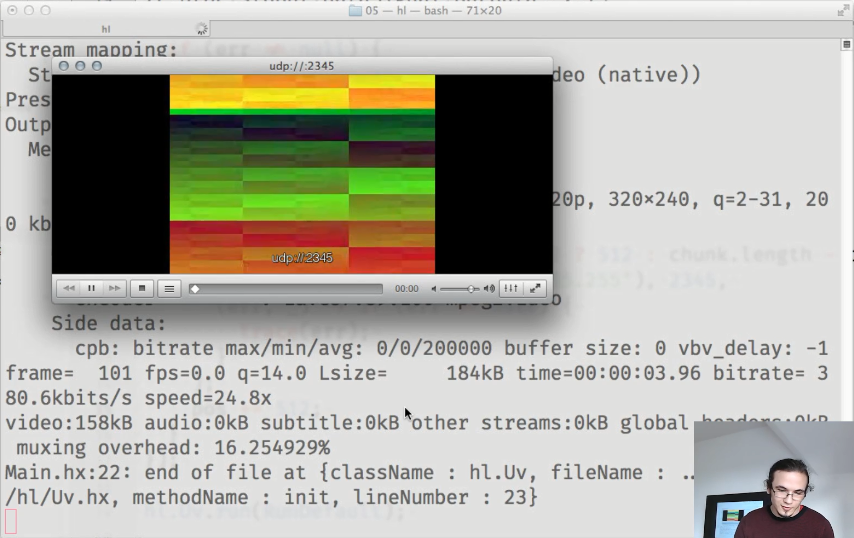
E, como resultado, obtemos um fluxo de vídeo de trabalho:
Resumindo o acima, a nova API asys inclui:
- métodos para trabalhar com o sistema de arquivos, incluindo novas funções que não estavam na biblioteca padrão (por exemplo, para alterar permissões), bem como versões assíncronas de todas as funções disponíveis na antiga biblioteca padrão
- suporte para operação assíncrona com soquetes TCP / UDP / IPC
- métodos para trabalhar com DNS (até agora 2 métodos:
lookup e reverse ) - bem como métodos para trabalho assíncrono com processos.

O trabalho na API asys ainda não foi concluído; no momento, existem alguns problemas com o coletor de lixo ao trabalhar com a biblioteca libuv. O Pull Request com as alterações correspondentes ainda não foi incorporado ao ramo principal do Haxe; os comentários sobre ele recebem opiniões sobre os nomes de novos métodos, suas assinaturas e documentação.
Como já mencionado, o suporte à API asys é implementado apenas para HashLink, Eval e Neko (na forma de três solicitações pull separadas). Aurel já formou um plano sobre como adicionar suporte para a nova API para C ++ e Lua. A implementação para outras plataformas exigirá pesquisa adicional.

É possível que a API asys esteja disponível no Haxe 4.1 (mas apenas em algumas plataformas).
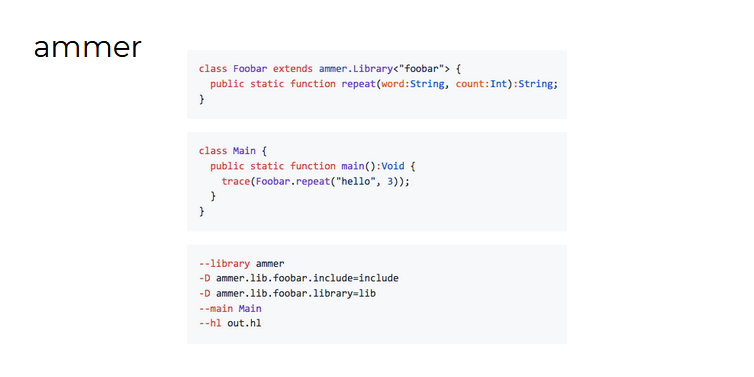
Aurel também falou sobre seu projeto paralelo - a biblioteca ammer (que, no entanto, está associada ao seu trabalho na Fundação Haxe).

O objetivo da Ammer é automatizar a criação de binders para bibliotecas C, para que possam ser usados no HashLink e no HXCPP (em outubro de 2018, Lars Duse designou uma taxa para resolver esse problema).
Por que essa tarefa foi relevante? O fato é que, embora o processo de criação de ligantes para o HashLink e o HXCPP seja semelhante, para cada plataforma, você precisará escrever seu próprio código de cola.
Aurel fez aproximadamente a mesma coisa quando integrou a biblioteca libuv no Haxe - para Eval, Neko e HashLink, ele teve que escrever o mesmo código que diferia apenas em detalhes (chamadas de função, diferenças no trabalho da FFI, etc.):

Um trabalho semelhante foi necessário para ser feito no lado Haxe, para que funções nativas pudessem ser chamadas a partir dele:

E a idéia do ammer é pegar a versão Haxe da API, não cheia de informações redundantes, e fazer com que esse código funcione de alguma forma para todas as plataformas:

O que o ammer agora é necessário para usar bibliotecas externas C:
- crie a especificação Haxe para a biblioteca, que é essencialmente uma externa à biblioteca usada
- escrever código do aplicativo
- compilar o projeto especificando caminhos para arquivos de cabeçalho e arquivos da biblioteca C
- ...
- lucro
Sob o capô, o ammer faz o seguinte:
- corresponde aos tipos, dependendo da plataforma de destino
- gera automaticamente o código C para chamar funções nativas
- gera um makefile usado para criar arquivos hdll, ndll

A Ammer atualmente suporta:
- funções simples
- define'y a partir dos arquivos de cabeçalho (no código Hax, eles podem ser acessados como constantes)
- ponteiros
Suporte planejado:
- retornos de chamada (eles ainda estão em falta)
- e estruturas (muito necessárias para trabalhar com a C-API)

Agora, o ammer trabalha com C ++, HashLink e Eval. E Aurel tem certeza de que pode adicionar suporte para outras plataformas de sistema.

Para demonstrar os recursos do ammer, Aurel mostrou um pequeno aplicativo que executa o interpretador Lua:
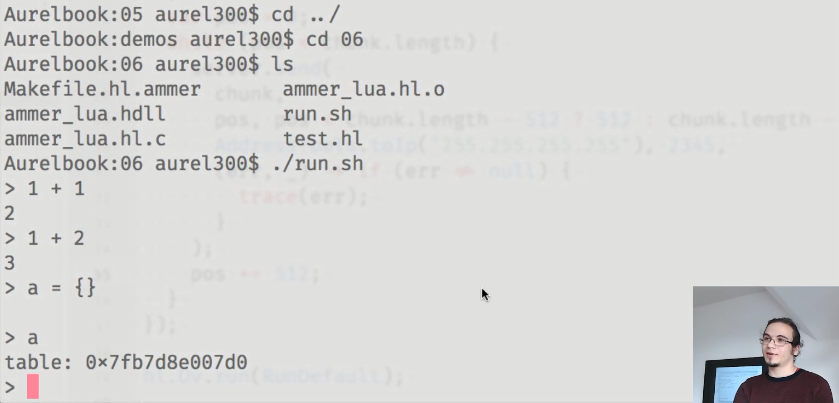
Os ligantes utilizados são os seguintes:
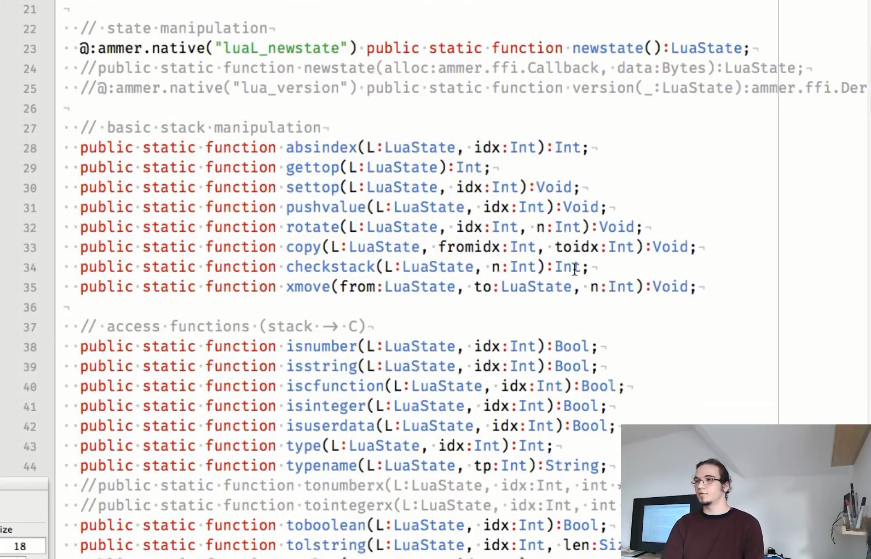
Como você pode ver, alguns métodos são comentados, porque eles usam retornos de chamada, cujo suporte ainda não foi realizado, mas Aurel espera que ele conserte isso em breve.

Então, para que ammer pode ser usado:
- incorporando uma máquina virtual Lua
- criando aplicativos em SDL
- a automação do trabalho com o libuv é possível (como mostrado anteriormente, agora é preciso muito código escrito à mão para trabalhar com o libuv)
- e, é claro, simplificará bastante o uso de muitas outras bibliotecas C úteis (como OpenAL, Dear-imgui, etc.)

Embora o estágio de Aurel na Fundação Haxe tenha terminado, ele planeja continuar trabalhando com a Haxe, como sua educação universitária ainda não foi concluída e ele ainda precisa escrever seu trabalho final. Aurel já sabe no que será dedicado - melhorar o trabalho do coletor de lixo no HashLink. Bem, será interessante!