Redash começou recentemente a mudar de um sistema de execução de tarefas para outro. Ou seja, eles começaram a transição do aipo para a RQ. No primeiro estágio, apenas as tarefas que não executam solicitações diretamente foram transferidas para a nova plataforma. Entre essas tarefas estão o envio de e-mails, descobrindo quais solicitações devem ser atualizadas, registrando eventos do usuário e outras tarefas de suporte.

Depois de implantar tudo isso, percebeu-se que os funcionários da RQ exigem muito mais recursos de computação para resolver o mesmo volume de tarefas que o Celery costumava resolver.
O material, cuja tradução publicamos hoje, é dedicado à história de como Redash descobriu a causa do problema e lidou com ele.
Algumas palavras sobre as diferenças entre o aipo e o RQ
Aipo e RQ têm o conceito de responsáveis pelo processo. Lá e lá para a organização da execução paralela de tarefas usando a criação de garfos. Quando o trabalhador do aipo é iniciado, vários processos de bifurcação são criados, cada um dos quais autonomamente processa tarefas. No caso do RQ, a instância do trabalhador contém apenas um subprocesso (conhecido como "burro de carga"), que executa uma tarefa e é destruído. Quando o trabalhador baixa a próxima tarefa da fila, ele cria um novo "cavalo de batalha".
Ao trabalhar com o RQ, você pode obter o mesmo nível de paralelismo que ao trabalhar com o Celery, simplesmente executando mais processos de trabalho. No entanto, há uma diferença sutil entre o aipo e o RQ. No Celery, um trabalhador cria muitas instâncias de subprocessos na inicialização e as usa repetidamente para concluir muitas tarefas. E no caso da RQ, para cada trabalho, você precisa criar um novo garfo. Ambas as abordagens têm seus prós e contras, mas aqui não falaremos sobre isso.
Medição de desempenho
Antes de começar a criar um perfil, decidi medir o desempenho do sistema descobrindo quanto tempo o contêiner do trabalhador precisa processar 1000 trabalhos. Decidi me concentrar na tarefa
record_event , pois esta é uma operação leve comum. Para medir o desempenho, usei o comando
time . Isso exigiu algumas alterações no código do projeto:
- Para medir o desempenho da execução de 1000 tarefas, decidi usar o modo em lote RQ, no qual, após o processamento das tarefas, o processo é encerrado.
- Eu queria evitar influenciar minhas medições com outras tarefas que poderiam ter sido agendadas para o período em que eu estava medindo o desempenho do sistema. Então mudei
record_event para uma fila separada chamada benchmark , substituindo @job('default') por @job('benchmark') . Isso foi feito pouco antes da record_event em tasks/general.py .
Agora era possível iniciar as medições. Para começar, eu queria saber quanto tempo leva para iniciar e parar um trabalhador sem carga. Esse tempo pode ser subtraído dos resultados finais obtidos posteriormente.
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m14.728s user 0m6.810s sys 0m2.750s
Foram necessários 14,7 segundos para inicializar o trabalhador no meu computador. Eu lembro disso
Em seguida, coloquei 1000
record_event teste
record_event na fila de
benchmark :
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]"
Depois disso, iniciei o sistema da mesma maneira que antes e descobri quanto tempo leva para processar 1000 trabalhos.
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 1m57.332s user 1m11.320s sys 0m27.540s
Subtraindo 14,7 segundos do que aconteceu, descobri que 4 trabalhadores processam 1000 tarefas em 102 segundos. Agora vamos tentar descobrir por que isso é assim. Para fazer isso, enquanto os trabalhadores estiverem ocupados, os pesquisaremos usando
py-spy .
Criação de perfil
Adicionamos outras 1.000 tarefas à fila (isso deve ser feito devido ao fato de que durante as medições anteriores todas as tarefas foram processadas), executamos os trabalhadores e os espionamos.
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]" $ docker-compose exec worker bash -c 'nohup ./manage.py rq workers 4 benchmark & sleep 15 && pip install py-spy && rq info -u "redis://redis:6379/0" | grep busy | awk "{print $3}" | grep -o -P "\s\d+" | head -n 1 | xargs py-spy record -d 10 --subprocesses -o profile.svg -p' $ open -a "Google Chrome" profile.svg
Eu sei que a equipe anterior foi muito longa. Idealmente, para melhorar sua legibilidade, valeria a pena dividi-lo em fragmentos separados, dividindo-o nos locais onde são encontradas sequências de caracteres
&& . Mas os comandos devem ser executados sequencialmente na mesma sessão
docker-compose exec worker bash , para que tudo fique exatamente assim. Aqui está uma descrição do que esse comando faz:
- Lança 4 trabalhadores em lote em segundo plano.
- Aguarda 15 segundos (é necessário aproximadamente o máximo para concluir o download).
- Instala o
py-spy . - Executa
rq-info e descobre o PID de um dos trabalhadores. - Registra informações sobre o trabalho do trabalhador com o PID recebido anteriormente por 10 segundos e salva os dados no arquivo
profile.svg
Como resultado, o seguinte cronograma ardente foi obtido.
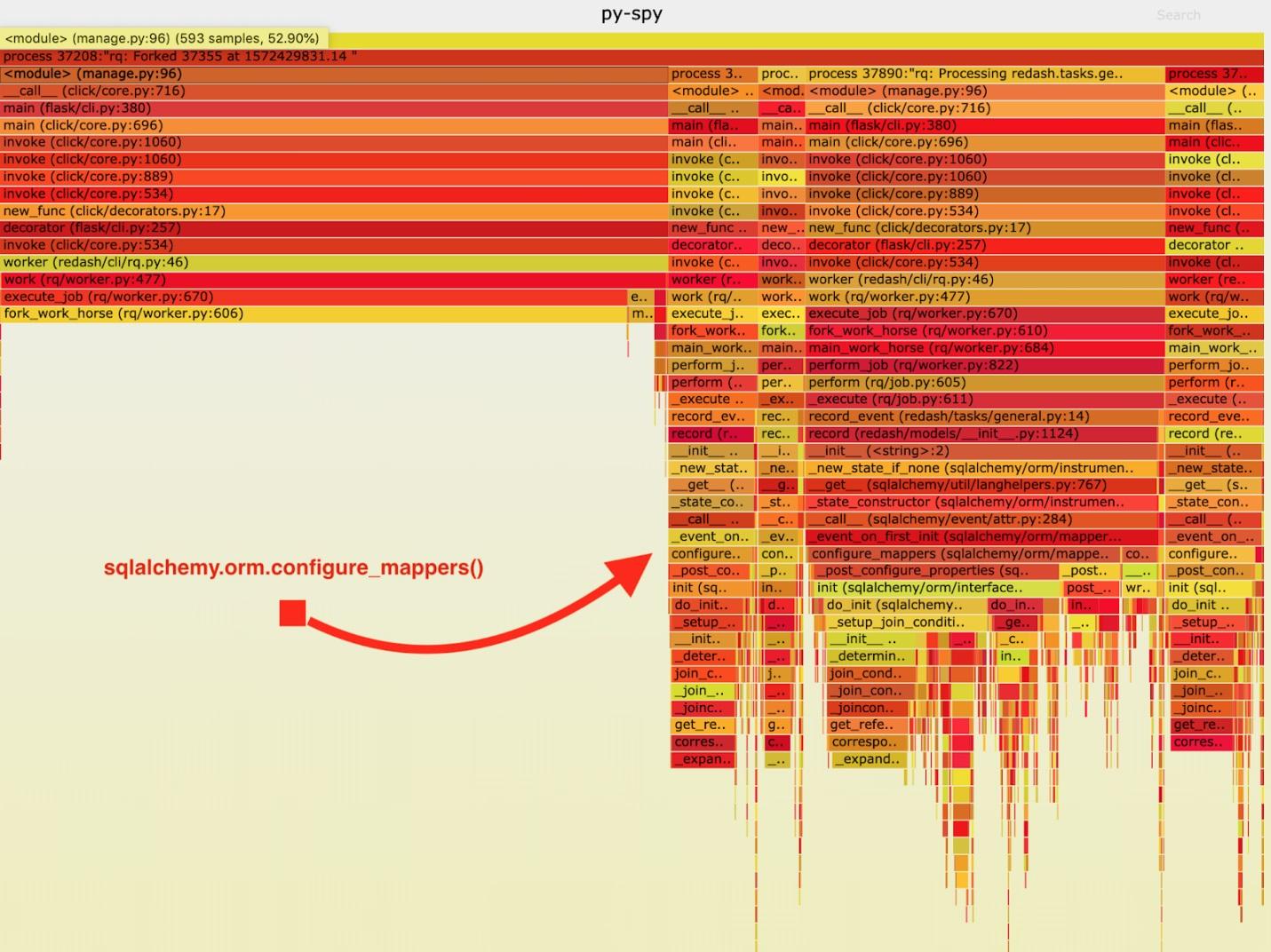 Visualização de dados coletados pelo py-spy
Visualização de dados coletados pelo py-spyApós analisar esses dados, notei que a tarefa
record_event gasta muito tempo executando-a em
sqlalchemy.orm.configure_mappers . Isso acontece durante cada tarefa. A partir da documentação, aprendi que, no momento que me interessa, as relações de todos os mapeadores criados anteriormente são inicializadas.
Não é absolutamente necessário que tais coisas aconteçam com cada garfo. Podemos inicializar o relacionamento uma vez no trabalhador pai e evitar repetir essa tarefa nos “cavalos de trabalho”.
Como resultado, adicionei uma chamada ao
sqlalchemy.org.configure_mappers() ao código antes de iniciar o "cavalo de batalha" e fiz as medições novamente.
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)] $ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark" real 0m39.348s user 0m15.190s sys 0m10.330s
Se você subtrair 14,7 segundos desses resultados, melhoramos o tempo necessário para 4 trabalhadores processarem 1000 tarefas de 102 segundos para 24,6 segundos. Esta é uma melhoria de desempenho quádrupla! Graças a essa correção, conseguimos quadruplicar os recursos de produção do RQ e manter a mesma largura de banda do sistema.
Sumário
De tudo isso, concluí a seguinte: vale lembrar que o aplicativo se comporta de maneira diferente se for o único processo e se for garfo. Se durante cada tarefa for necessário resolver algumas tarefas oficiais difíceis, é melhor resolvê-las antecipadamente, tendo feito isso uma vez antes da conclusão do garfo. Tais coisas não são detectadas durante o teste e o desenvolvimento, portanto, tendo percebido que algo está errado com o projeto, medindo sua velocidade e chegando ao fim, procurando as causas dos problemas com seu desempenho.
Caros leitores! Você encontrou problemas de desempenho em projetos Python que poderia resolver analisando cuidadosamente um sistema em funcionamento?
