Oi
Em setembro deste ano (2019), foi realizada a eleição do governador de São Petersburgo. Todos os dados de votação estão disponíveis publicamente no site da comissão eleitoral, não quebraremos nada, mas apenas visualizamos as informações deste site
www.st-petersburg.vybory.izbirkom.ru da forma que precisamos, faremos uma análise muito simples e identificaremos algumas Padrões "mágicos".
Normalmente, para essas tarefas, eu uso o Google Colab. Este é um serviço que permite a execução de Jupyter Notebooks e, ao ter acesso gratuito à GPU (NVidia Tesla K80), agiliza significativamente a análise de dados e o processamento adicional. Eu precisava de algum trabalho preparatório antes de importar.
%%time !apt update !apt upgrade !apt install gdal-bin python-gdal python3-gdal
Outras importações.
import requests from bs4 import BeautifulSoup import numpy as np import pandas as pd import matplotlib.pyplot as plt import geopandas as gpd import xlrd
Descrição das bibliotecas usadas
- pedidos - módulo para um pedido para se conectar a um site
- BeautifulSoup - módulo para analisar documentos html e xml; permite acessar diretamente o conteúdo de qualquer tag em html
- numpy - um módulo matemático com um conjunto básico e necessário de funções matemáticas
- pandas - biblioteca de análise de dados
- matplotlib.pyplot - conjunto de módulos de métodos de construção
- geopandas - módulo para construção de um mapa eleitoral
- xlrd - módulo para leitura de arquivos de tabela
Chegou a hora de coletar os dados em si, parsim. O comitê eleitoral cuidou do nosso tempo e forneceu relatórios nas tabelas, é conveniente.
Então, isso é o que foi discutido. Os dados no Google Colab são coletados de maneira inteligente, mas não tanto.
Antes de criar vários gráficos e mapas, é bom ter uma idéia do que chamamos de "conjunto de dados".
Análise dos dados da comissão eleitoral
Na cidade de São Petersburgo, existem 30 comissões territoriais; na 31ª coluna, nos referimos às assembleias de voto digitais.

Cada comissão territorial possui várias dezenas de PECs (comissões eleitorais anteriores).

O principal que nos interessa é a aparência em cada assembleia de voto e que tipo de dependências podemos observar. Vou desenvolver o seguinte:
- dependência de comparecimento e número de assembleias de voto;
- dependência da porcentagem de votos dos candidatos na participação;
- Dependência da participação no número de eleitores na delegacia.
A partir da tabela de dados simples, é bastante difícil rastrear como foram as eleições e tirar algumas conclusões, para que os gráficos sejam o nosso caminho.
Vamos construir o que criamos.
Dependência da participação e número de assembleias de voto Dependência da porcentagem de votos dos candidatos na participação
Dependência da porcentagem de votos dos candidatos na participação- "Verde" - votos para Amosov
- "Vermelho" - para Tikhonov
 Dependência da participação no número de eleitores na delegacia
Dependência da participação no número de eleitores na delegacia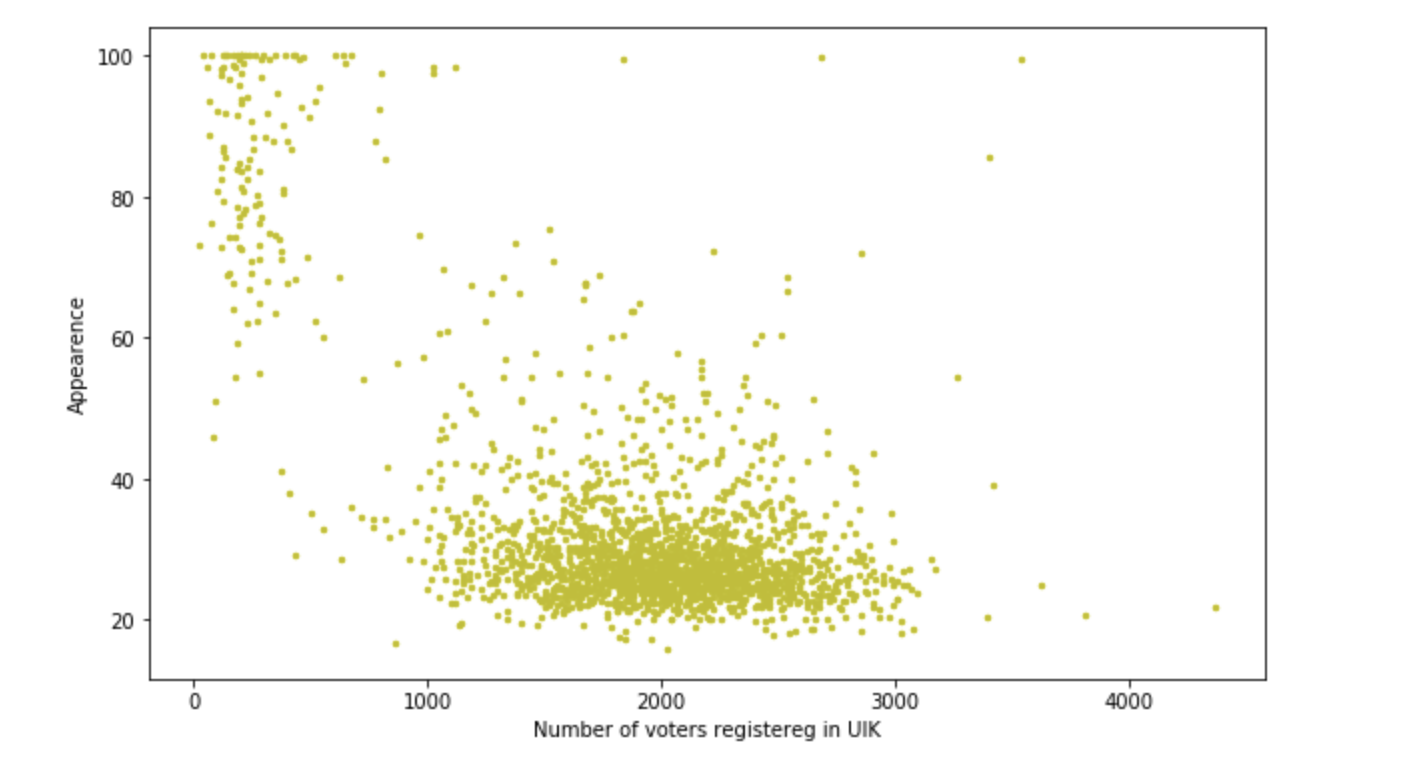
As construções são bastante toleráveis, mas no decorrer do trabalho, verificou-se que, em média, 400 pessoas no local e a porcentagem de Beglov é de 50 a 70, mas existem dois locais com uma afluência> 1200 pessoas e uma porcentagem de 90 + -0,2. É interessante que isso tenha acontecido nessas áreas. Alguns agitadores fantásticos funcionaram? Ou apenas dirigiu 10 ônibus e foi forçado a votar? De uma forma ou de outra, estamos empolgados, uma pequena investigação está sendo obtida. Mas ainda temos que comprar cartas. Vamos continuar.
Representação visual e trabalho com geopandas
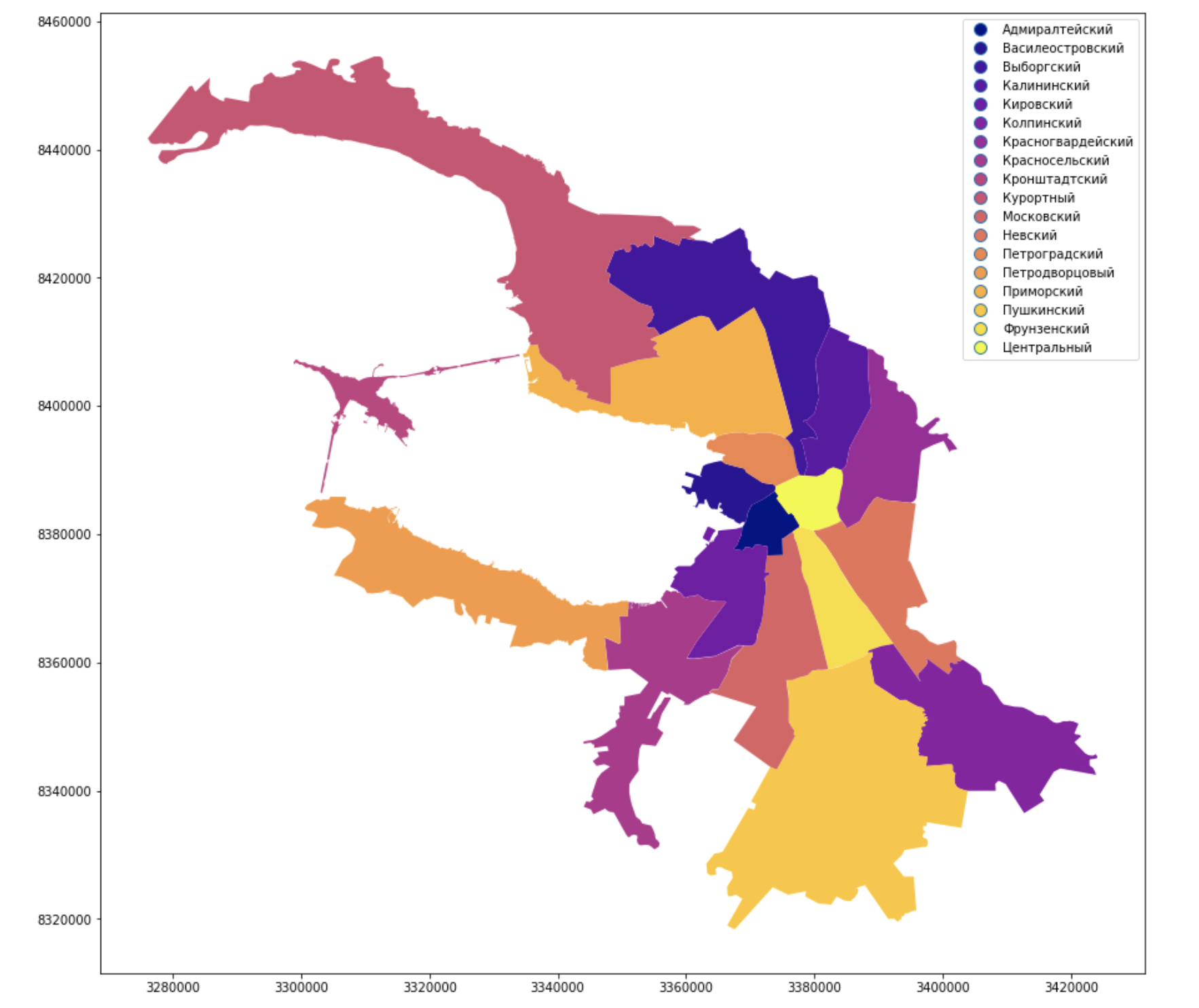
Eles pintaram os distritos administrativos da cidade e os assinaram, parece familiar, parece com Peter, mas o Neva ainda não é suficiente.
Número de eleitores
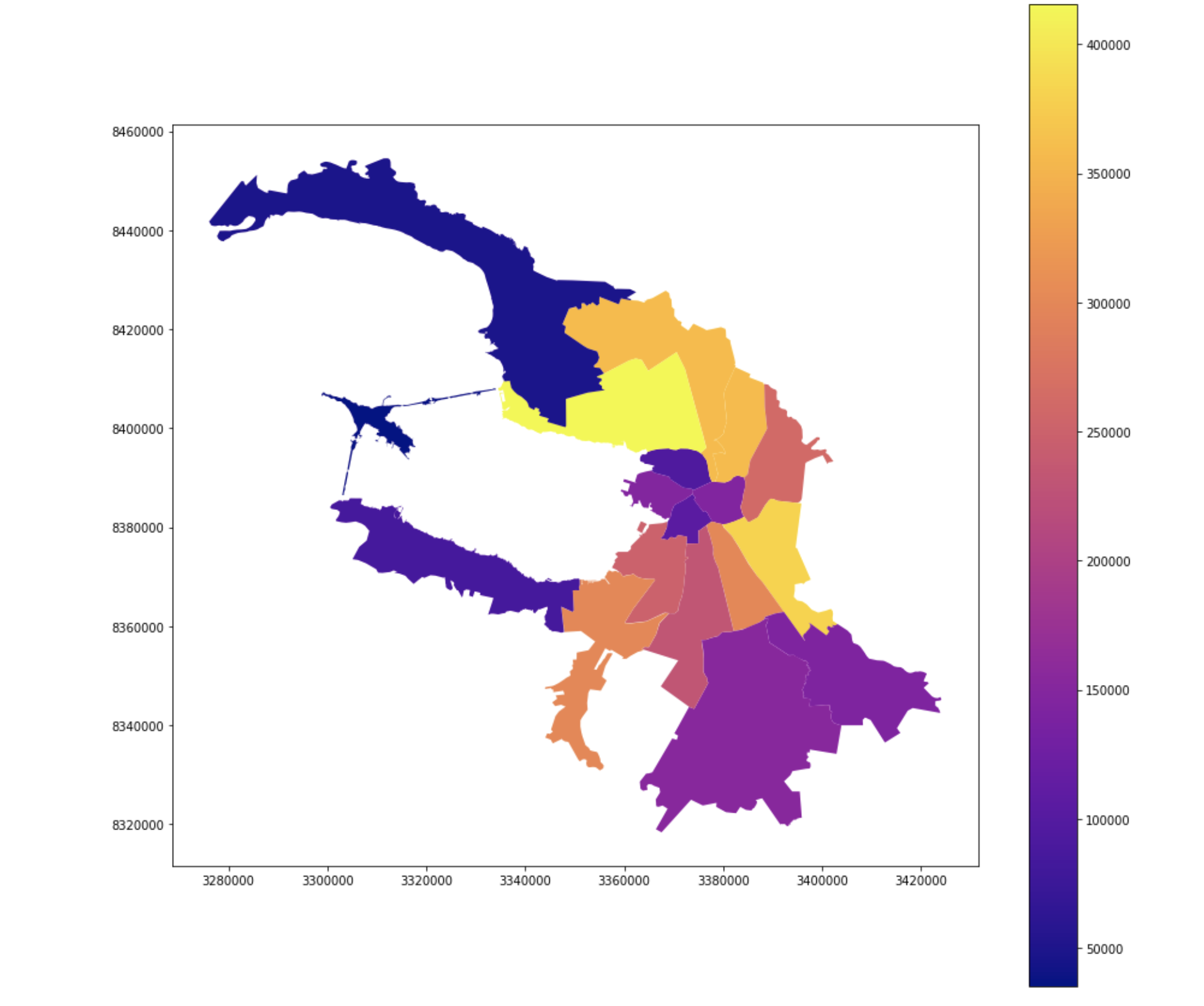 Participação
Participação

Conclusão
Você pode se divertir com os dados por um longo tempo, usá-los em diferentes campos e, é claro, obter algum benefício, pois eles existem. Ferramentas de visualização de geolocalização simples e sofisticadas podem fazer grandes coisas. Escreva sobre o seu sucesso nos comentários!