Para perguntas no estilo de "por quê?" Há um artigo antigo - Natural Geektimes - tornando o espaço mais limpo .
Muitos artigos, por razões subjetivas, alguns não gostam e outros, pelo contrário, é uma pena perder. Quero otimizar esse processo e economizar tempo.
O artigo acima propôs uma abordagem com scripts no navegador, mas eu realmente não gostei (apesar de ter usado antes) pelos seguintes motivos:
- Para diferentes navegadores no seu computador / telefone, você deve configurá-lo novamente, se possível.
- A filtragem rígida dos autores nem sempre é conveniente.
- O problema com autores cujos artigos não querem ser perdidos, mesmo que sejam publicados uma vez por ano, não está resolvido.
A filtragem por classificação de artigo incorporada no site nem sempre é conveniente, pois artigos altamente especializados, por todo o seu valor, podem receber uma classificação bastante modesta.
Inicialmente, eu queria gerar feed RSS (ou mesmo alguns), deixando apenas o interessante por lá. Mas, no final, descobriu-se que ler rss não era muito conveniente: em qualquer caso, para comentar / votar em um artigo / adicioná-lo aos favoritos, você deve acessar o navegador. Portanto, escrevi um bot para um telegrama que lança artigos interessantes para mim no PM. O próprio Telegram faz com que sejam belas visualizações, o que, em combinação com informações sobre o autor / classificação / visualizações, parece bastante informativo.
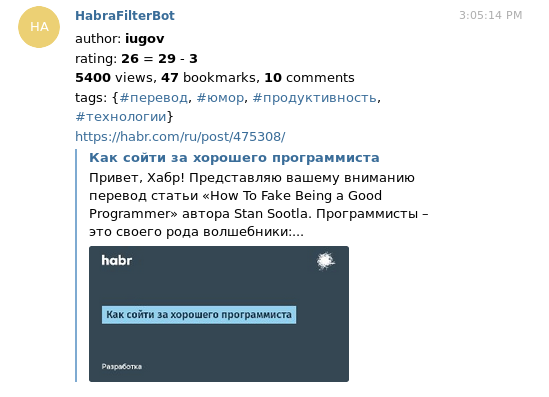
Sob o corte, detalhes como recursos de trabalho, processo de escrita e soluções técnicas.
Brevemente sobre o bot
Repositório: https://github.com/Kright/habrahabr_reader
Bot de telegrama: https://t.me/HabraFilterBot
O usuário define uma classificação adicional para tags e autores. Depois disso, um filtro é aplicado aos artigos - a classificação do artigo em Habré, a classificação do usuário do autor e a média das classificações do usuário por tags são adicionadas. Se a quantidade for maior que o valor limite definido pelo usuário, o artigo passará pelo filtro.
Um objetivo secundário de escrever um bot era obter diversão e experiência. Além disso, lembrei-me regularmente de que não era o Google e, portanto, muitas coisas foram feitas da maneira mais simples e primitiva possível. No entanto, isso não impediu que o processo de gravação do bot se esticasse por três meses.
Fora da janela era verão
Julho terminou e eu decidi escrever um bot. E não sozinho, mas com um amigo que dominava a scala e queria escrever algo nela. O começo parecia promissor - o código será visto como "equipe", a tarefa parecia fácil e eu pensei que em algumas semanas ou um mês o bot estará pronto.
Apesar de eu mesmo ter escrito código sobre a rocha nos últimos anos, geralmente ninguém vê ou olha para esse código: projetos de animais de estimação, verificação de algumas idéias, pré-processamento de dados, domínio de alguns conceitos do FP. Eu estava realmente interessado em como o código da equipe se parece, porque o código no rock pode ser escrito de maneiras muito diferentes.
O que poderia ter acontecido? No entanto, não vamos apressar as coisas.
Tudo o que acontece pode ser rastreado pelo histórico de confirmações.
Um amigo criou o repositório em 27 de julho, mas não fez mais nada, então comecei a escrever código.
30 de julho
Resumidamente: escrevi analisando feeds RSS de Habr.
com.github.pureconfig para ler arquivos de configuração typesafe diretamente nas classes de caso (acabou sendo muito conveniente)scala-xml para ler xml: como eu originalmente queria escrever minha implementação para fita rss e fita rss no formato xml, usei esta biblioteca para analisar. Na verdade, a análise de rss também apareceu.scalatest para testes. Mesmo para pequenos projetos, escrever testes economiza tempo - por exemplo, ao depurar a análise de xml, é muito mais fácil fazer o download para um arquivo, gravar testes e corrigir erros. Quando um bug apareceu mais tarde com a análise de algum html estranho com caracteres utf-8 inválidos, tornou-se novamente mais conveniente colocá-lo em um arquivo e adicionar um teste.- atores de Akka. Objetivamente, eles não eram necessários, mas o projeto foi escrito por diversão, eu queria experimentá-los. Como resultado, estou pronto para dizer que gostei. Pode-se olhar para a idéia de POO do outro lado - existem atores que trocam mensagens. O que é mais interessante - é possível (e necessário) escrever código de forma que a mensagem não chegue ou não possa ser processada (de modo geral, quando a conta está sendo executada em um único computador, as mensagens não devem ser perdidas). No começo, eu estava desesperado e havia um lixo no código com atores se inscrevendo, mas no final consegui criar uma arquitetura bastante simples e elegante. O código dentro de cada ator pode ser considerado de thread único; quando o ator trava, o Akka o reinicia - um sistema bastante tolerante a falhas é obtido.
9 de agosto
Eu adicionei o projeto scala-scrapper para analisar páginas html do Habr (para obter informações como classificação de artigos, número de favoritos etc.).
E Gatos. Aqueles que estão na rocha.
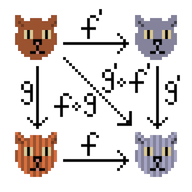
Depois, li um livro sobre bancos de dados distribuídos, gostei da ideia de CRDT (tipo de dados replicado sem conflitos, https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type , habr ), então filmei a classe de tipo do semigrupo comutativo para informações sobre o artigo sobre Habré.
De fato, a ideia é muito simples - temos contadores que mudam monotonamente. O número de promotores está crescendo suavemente, o número de vantagens também (no entanto, assim como o número de desvantagens). Se eu tiver duas versões de informações sobre um artigo, você poderá "mesclá-las em uma" - considere o estado do contador que é mais relevante.
Um semigrupo significa que dois objetos com informações sobre um artigo podem ser mesclados em um. Comutativo significa que você pode mesclar A + B e B + A, o resultado não depende da ordem e, como resultado, a versão mais recente permanece. A propósito, a associatividade também está aqui.
Por exemplo, por design, o rss após a análise forneceu informações ligeiramente atenuadas sobre o artigo - sem métricas, como o número de visualizações. Um ator especial pegou informações sobre os artigos e correu para as páginas html para atualizá-las e mesclar com a versão antiga.
De um modo geral, como o akka, não havia necessidade disso, era possível armazenar updateDate para o artigo e adotar um mais novo sem fusões, mas fui conduzido por uma estrada de aventura.
12 de agosto
Comecei a me sentir mais livre e, por interesse, tornei cada conversa um ator separado. Teoricamente, um ator por si só pesa cerca de 300 bytes e pode ser criado pelo menos por milhões, portanto, essa é uma abordagem completamente normal. Parece-me uma solução bastante interessante:
Um ator foi a ponte entre o servidor de telegrama e o sistema de mensagens em Akka. Ele simplesmente recebeu mensagens e as enviou para o ator de bate-papo desejado. O bate-papo do ator em resposta poderia enviar algo de volta - e foi enviado de volta aos telegramas. O que foi muito conveniente - esse ator acabou sendo o mais simples possível e continha apenas a lógica da resposta às mensagens. A propósito, informações sobre novos artigos chegavam a todos os bate-papos, mas, novamente, não vejo nenhum problema nisso.
Em geral, o bot já estava trabalhando, respondendo às mensagens, mantendo uma lista de artigos enviados ao usuário, e eu já pensei que o bot estava quase pronto. Eu terminei lentamente pequenos chips, como normalizar os nomes dos autores e tags (substituindo "sd f" por "s_d_f").
Havia apenas um pequeno, mas - o estado não persistiu em lugar algum.
Tudo deu errado
Você deve ter notado que eu escrevi o bot principalmente sozinho. Portanto, o segundo participante ingressou no desenvolvimento e as seguintes alterações apareceram no código:
- Para armazenar o estado apareceu mongoDB. Ao mesmo tempo, os logs quebraram no projeto, porque por alguma razão os monga começaram a enviá-los por spam e algumas pessoas simplesmente os desativaram globalmente.
- A ponte ator no telegrama foi transformada além do reconhecimento e começou a analisar as próprias mensagens.
- Os atores das conversas estavam bêbados sem piedade, em vez deles parecia um ator que escondia em si todas as informações sobre todas as conversas ao mesmo tempo. Para cada espirro, esse ator entrava em mongu. Bem, sim, é difícil enviá-lo a todos os atores do bate-papo ao atualizar informações sobre um artigo (somos como o Google, milhões de usuários aguardam um milhão de artigos em um bate-papo para todos), mas é normal entrar em um monga toda vez que você atualiza um bate-papo. Como entendi muito mais tarde, a lógica de trabalho dos chats também foi completamente cortada e algo inoperante apareceu.
- Não há nenhum rastro das classes.
- Uma lógica doentia apareceu nos atores com suas assinaturas, levando a uma condição de raça.
- Estruturas de dados com campos do tipo
Option[Int] transformados em Int com valores padrão mágicos do tipo -1. Mais tarde, percebi que o mongoDB armazena json e não há nada de errado em armazenar Option ali, ou pelo menos analisar -1 como None, mas naquela época eu não sabia disso e acreditava na palavra "é necessário". Esse código não foi escrito por mim e eu não me preocupei em alterá-lo por enquanto. - Descobri que meu endereço IP público tem a propriedade de mudar e toda vez que eu precisava adicioná-lo ao mongue da lista de permissões. Comecei o bot localmente, o monga estava em algum lugar nos servidores monga como empresa.
- De repente, a normalização de tags e formatação de mensagens para um telegrama desapareceu. (Hmm, por que faria isso?)
- Gostei que o estado do bot esteja armazenado em um banco de dados externo e, após a reinicialização, continue funcionando como se nada tivesse acontecido. No entanto, esta foi a única vantagem.
A segunda pessoa não estava com pressa e todas essas mudanças apareceram em uma grande pilha já no início de setembro. Não apreciei imediatamente a escala do dano resultante e comecei a entender o banco de dados, porque nunca tinha lidado com eles antes. Só então eu percebi quanto código de trabalho foi cortado e quantos bugs foram adicionados em troca.
Setembro
No começo, pensei que seria útil dominar Mongu e fazer tudo bem. Então comecei lentamente a entender que organizar a comunicação com o banco de dados também é uma arte na qual você pode fazer corridas e apenas erros. Por exemplo, se duas mensagens do tipo /subscribe chegarem do usuário e, em resposta a cada uma, criaremos uma entrada no prato, porque no momento do processamento dessas mensagens, o usuário não está assinado. Eu suspeitava que a comunicação com o monga na forma existente não fosse escrita da melhor maneira. Por exemplo, as configurações do usuário foram criadas no momento em que ele se inscreveu. Se ele tentasse alterá-los antes do fato da assinatura ... o bot não respondeu, porque o código no ator subiu ao banco de dados para as configurações, não pôde encontrar e travou. Para a pergunta - por que não criar as configurações conforme necessário, descobri que não há nada para alterá-las se o usuário não tiver se inscrito ... O sistema de filtragem de mensagens foi de alguma forma tornado óbvio e, mesmo depois de uma análise minuciosa do código, eu não conseguia entender se ele foi originalmente concebido ou há um erro.
Não havia uma lista de artigos enviados para o bate-papo, mas foi sugerido que eu mesmo os escrevesse. Isso me surpreendeu - em geral, não me opunha a arrastar todo tipo de peças para o projeto, mas seria lógico extrair essas coisas e parafusá-las. Mas não, o segundo participante parece ter esquecido tudo, mas disse que a lista dentro do bate-papo é supostamente uma péssima decisão, e você precisa criar um prato com eventos como "o artigo x foi enviado ao usuário x". Em seguida, se o usuário solicitasse o envio de novos artigos, era necessário enviar uma solicitação ao banco de dados, qual dos eventos selecionaria eventos relacionados ao usuário, ainda obteria uma lista de novos artigos, os filtraria, enviaria ao usuário e lançaria eventos sobre ele no banco de dados.
O segundo participante sofreu em algum lugar na direção das abstrações, quando o bot não apenas receberá artigos de Habr e enviará não apenas para telegramas.
De alguma forma, implementei os eventos na forma de um tablet separado na segunda quinzena de setembro. Não é o ideal, mas o bot pelo menos funcionou e começou a me enviar artigos novamente, e eu lentamente descobri o que estava acontecendo no código.
Agora você pode voltar primeiro e lembrar que o repositório não foi originalmente criado por mim. O que poderia ter acontecido? Minha solicitação de pool foi rejeitada. Descobri que eu tinha um código de acesso, que não sabia trabalhar em equipe e tinha que editar bugs na curva de implementação atual e não modificá-lo para um estado utilizável.
Fiquei chateado, olhei para o histórico de confirmações, a quantidade de código escrito. Eu olhei para os momentos que foram originalmente bem escritos e depois quebrados ...
F * rk it
Lembrei-me do artigo Você não é o Google .
Eu pensei que ninguém realmente precisa de uma idéia sem implementação. Eu pensei que eu quero ter um bot de trabalho que funcione em uma única cópia em um único computador como um simples programa java. Eu sei que meu bot funcionará por meses sem reiniciar, pois no passado eu escrevi esses bots. Se ele cair repentinamente e não enviar o próximo artigo ao usuário, o céu não cairá sobre a terra e nada de catastrófico acontecerá.
Por que preciso de uma janela de encaixe, mongoDB e outro culto à carga de software "sério", se o código não funciona estupidamente ou funciona de maneira torta?
Bifurquei o projeto e fiz tudo como queria.
Na mesma época, mudei de emprego e faltava muito tempo livre. De manhã, acordei exatamente no trem, voltei tarde da noite e não queria mais fazer nada. Não fiz nada por um tempo, superei o desejo de terminar o bot e comecei a reescrever lentamente o código enquanto dirigia para o trabalho pela manhã. Não posso dizer que foi produtivo: sentar em um trem trêmulo com um laptop no colo e espiar o excesso de pilhas do telefone não é muito conveniente. No entanto, o tempo para escrever o código passou despercebido e o projeto começou a se mover lentamente para um estado de funcionamento.
Em algum lugar no fundo, havia um worm de dúvida que o mongoDB queria usar, mas eu pensei que havia desvantagens visíveis além das vantagens do armazenamento em estado “confiável”:
- O banco de dados se torna outro ponto de falha.
- O código está ficando mais difícil, e vou escrever por mais tempo.
- O código se torna lento e ineficiente; em vez de alterar o objeto na memória, as alterações são enviadas ao banco de dados e recuadas, se necessário.
- Existem restrições sobre o tipo de armazenamento de eventos em uma placa separada, os quais estão associados aos recursos do banco de dados.
- Na versão de teste do monga, existem algumas restrições e, se você as encontrar, precisará iniciar e configurar o mongu para alguma coisa.
Eu bebi Mongu, agora o estado do bot é simplesmente armazenado na memória do programa e, de tempos em tempos, é salvo em um arquivo na forma de json. Talvez nos comentários eles escrevam que eu estou errado, porque é aqui que você deve usá-lo etc. Mas este é o meu projeto, a abordagem com o arquivo é o mais simples possível e funciona de maneira transparente.
Joguei valores mágicos como -1 e retornei a Option normal, adicionei o armazenamento de uma placa de hash com os artigos enviados de volta ao objeto com informações de bate-papo. Adicionada remoção de informações sobre artigos com mais de cinco dias, para não armazenar tudo em sequência. Ele trouxe o log em condição de trabalho - os logs em quantidades razoáveis são gravados no arquivo e no console. Foram adicionados vários comandos de administração, como salvar estado ou obter estatísticas como o número de usuários e artigos.
Corrigi um monte de pequenas coisas: por exemplo, os artigos agora indicam o número de visualizações, curtidas, desgostos e comentários no momento em que o filtro do usuário foi passado. Em geral, é incrível quantas pequenas coisas precisavam ser consertadas. Eu mantive uma lista, anotei todas as “rugosidade” lá e as corrigi o mais longe possível.
Por exemplo, adicionei a capacidade de definir todas as configurações diretamente em uma mensagem:
/subscribe /rating +20 /author a -30 /author s -20 /author p +9000 /tag scala 20 /tag akka 50
E o comando /settings exibe neste formulário, você pode pegar um texto e enviar todas as configurações para um amigo.
Parece um pouco, mas existem dezenas de nuances semelhantes.
Filtragem de artigos implementada na forma de um modelo linear simples - o usuário pode definir uma classificação adicional para autores e tags, além de um valor limite. Se a soma da classificação do autor, a classificação média das tags e a classificação real do artigo for maior que o valor limite, o artigo será mostrado ao usuário. Você pode solicitar ao bot artigos com o comando / new ou assinar o bot e ele lançará artigos no PM a qualquer hora do dia.
De um modo geral, tive uma ideia para cada artigo desenhar mais sinais (hubs, número de comentários, marcadores, dinâmica das alterações de classificação, quantidade de texto, figuras e código no artigo, palavras-chave) e o usuário para mostrar o voto ok / não ok em cada artigo e para cada usuário treinar o modelo, mas fiquei com preguiça.
Além disso, a lógica do trabalho não será tão óbvia. Agora eu posso colocar manualmente uma classificação de +9000 para o PatientZero e, com uma classificação de limiar de +20, eu garantirei o recebimento de todos os seus artigos (a menos que, é claro, eu coloquei -100500 para todas as tags).
A arquitetura resultante era bastante simples:
- Um ator que armazena o estado de todos os chats e artigos. Carrega seu estado de um arquivo em disco e, de tempos em tempos, salva-o novamente, cada vez em um novo arquivo.
- Um ator que ocasionalmente acessa o feed rss aprende sobre novos artigos, analisa os links, analisa e envia esses artigos para o primeiro ator. Além disso, ele às vezes solicita ao primeiro ator uma lista de artigos, seleciona aqueles que não têm mais de três dias, mas não são atualizados há muito tempo, e os atualiza.
- Um ator que se comunica com um telegrama. Ainda levei a análise de mensagens completamente aqui. De uma maneira boa, quero dividi-lo em dois - para que um analise as mensagens recebidas e o segundo lide com problemas de transporte, como encaminhar mensagens não enviadas. Agora não há reenvio, e a mensagem que não foi alcançada devido a um erro será simplesmente perdida (exceto que será marcada nos logs), mas até agora isso não causa problemas. Talvez surjam problemas se um monte de pessoas se inscrever no bot e eu atingir o limite para o envio de mensagens).
O que eu gostei - graças a akka, a queda dos atores 2 e 3 em geral não afeta o desempenho do bot. Talvez alguns artigos não sejam atualizados a tempo ou algumas mensagens não cheguem ao telegrama, mas Akka reinicia o ator e tudo continua a funcionar mais. Eu salvo as informações que o artigo é mostrado ao usuário somente quando o ator do telegrama responde que ele entregou a mensagem com sucesso. A pior coisa que me ameaça é enviar uma mensagem várias vezes (se for entregue, mas a confirmação for perdida de alguma maneira desconhecida). Em princípio, se o primeiro ator não mantivesse o estado em si mesmo, mas se comunicasse com algum tipo de banco de dados, ele também poderia cair em silêncio e voltar à vida. Eu também poderia tentar a persistência do akka para restaurar o estado dos atores, mas a implementação atual me convém com sua simplicidade. Não que meu código trava com frequência - pelo contrário, dediquei muito esforço para tornar isso impossível. Mas a merda acontece, e a capacidade de dividir o programa em partes isoladas - atores parecia realmente conveniente e prático para mim.
Adicionado circle-ci para saber imediatamente quando o código for quebrado. Pelo menos que o código parou de compilar. Inicialmente, eu queria adicionar travis, mas mostrava apenas meus projetos sem os bifurcados. Em geral, essas duas coisas podem ser usadas livremente em repositórios abertos.
Sumário
Já é novembro. O bot está escrito, usei-o nas últimas duas semanas e gostei. Se você tem idéias para melhorias - escreva. Não vejo o objetivo de gerar receita: deixe funcionar e envie artigos interessantes.
Link para o bot: https://t.me/HabraFilterBot
Github: https://github.com/Kright/habrahabr_reader
Pequenas conclusões:
- Mesmo um projeto pequeno pode levar muito tempo.
- Você não é o Google. Não faz sentido atirar em um pardal com um canhão. Uma solução simples também pode funcionar.
- Projetos de animais de estimação são muito adequados para experimentar novas tecnologias.
- Os bots de telegrama são escritos de maneira bastante simples. Se não fosse por “trabalho em equipe” e experimentos com tecnologias, o bot teria sido escrito em uma semana ou duas.
- O modelo do ator é uma coisa interessante que combina bem com a resiliência de vários threads e códigos.
- Parece-me que sinto por que a comunidade de código aberto adora garfos.
- Os bancos de dados são bons, pois o estado do aplicativo não depende mais das falhas / reinicializações do aplicativo, mas o trabalho com o banco de dados complica o código e impõe restrições à estrutura dos dados.