Nos dois primeiros artigos, levantei a questão da automação e esbocei sua estrutura; no segundo, fiz uma digressão sobre a virtualização de rede, como a primeira abordagem para automatizar a configuração de serviços.
E agora é hora de desenhar um diagrama de rede físico.
Se você não está muito interessado no dispositivo das redes de data center, recomendo começar com um
artigo sobre elas .
Todas as edições:
As práticas descritas nesta série devem ser aplicáveis a uma rede de qualquer tipo, escala e variedade de fornecedores (não). No entanto, um exemplo universal da aplicação dessas abordagens não pode ser descrito. Portanto, vou me concentrar na arquitetura moderna da rede DC:
Klose Factory .
DCI fará em MPLS L3VPN.
Uma rede de sobreposição do host é executada sobre a rede física (pode ser OpenStack VXLAN ou Tungsten Fabric ou qualquer outra coisa que exija apenas conectividade IP básica da rede).
Nesse caso, obtemos um cenário relativamente simples para automação, porque temos muitos equipamentos configurados da mesma maneira.
Vamos escolher uma CD esférica no vácuo:
- Uma versão do design está em todo lugar.
- Dois fornecedores formando dois planos da rede.
- Um CD é como outro, como duas gotas de água.
Conteúdo
- Topologia física
- Encaminhamento
- Plano IP
- Laba
- Conclusão
- Links úteis
Permita que o nosso provedor de serviços LAN_DC, por exemplo, hospede vídeos de treinamento sobre sobrevivência em elevadores presos.
Nas megacidades, isso é muito popular, então há muitas máquinas físicas.
Primeiro, descreverei a rede aproximadamente como gostaria de vê-la. E então vou simplificá-lo para o laboratório.
Topologia física
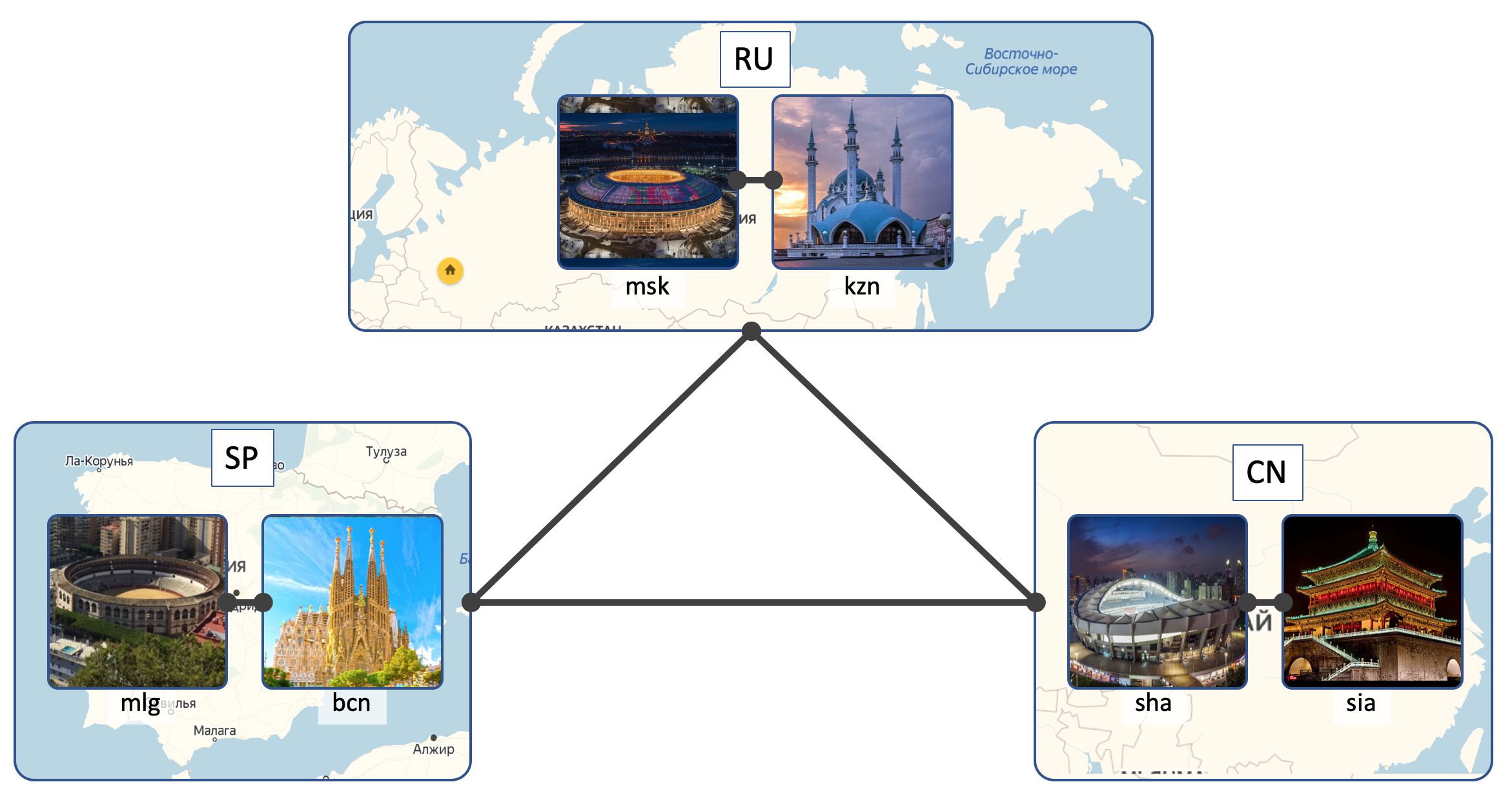
Localizações
LAN_DC terá 6 DCs:
- Rússia ( RU ):
- Moscovo ( msk )
- Kazan ( kzn )
- Espanha ( SP ):
- Barcelona ( bcn )
- Málaga ( mlg )
- China ( CN ):
- Xangai ( sha )
- Xian ( sia )
CC interna (Intra-DC)
Em todos os controladores de domínio, redes de conectividade interna idênticas baseadas na topologia Clos.
Que tipo de redes são Klose e por que elas estão em um
artigo separado.
Em cada CD há 10 racks com carros, eles serão numerados como
A ,
B ,
C E assim por diante.
Cada rack tem 30 carros. Eles não vão nos interessar.
Além disso, em cada rack, há um comutador no qual todas as máquinas estão conectadas - este é
o comutador Top of the Rack - ToR ou, em termos da fábrica da Klose, chamaremos de
Leaf .
 O esquema geral da fábrica.
O esquema geral da fábrica.Vamos
chamá- los de
XXX- folha Y , onde
XXX é a abreviação de três letras DC e
Y é o número de série. Por exemplo,
kzn-leaf11 .
Nos artigos, permito-me usar os termos Leaf e ToR de maneira bastante frívola, como sinônimos. No entanto, é preciso lembrar que não é assim.
ToR é um comutador montado em rack ao qual as máquinas se conectam.
Leaf é o papel de um dispositivo em uma rede física ou de um switch de primeiro nível em termos de topologia do Clos.
Ou seja, Leaf! = ToR.
Portanto, o Leaf pode ser um switch EndofRaw, por exemplo.
No entanto, dentro da estrutura deste artigo, nos referiremos a eles como sinônimos.
Cada switch ToR, por sua vez, é conectado a quatro switches de agregação upstream -
Spine . Sob Spine'y alocou um rack no DC. Nós o
nomearemos da mesma maneira:
XXX -spine Y.No mesmo rack, haverá equipamentos de rede para conectividade entre roteadores DCs - 2 com MPLS a bordo. Mas, em geral, esses são os mesmos ToRs. Ou seja, do ponto de vista dos Spine-switches, não importa se existe um ToR comum com máquinas conectadas ou um roteador para DCI - uma coisa maldita.
Esses ToRs especiais são chamados
Edge-leaf . Vamos chamá-los de
XXX- edge Y.Será assim.

No diagrama acima da borda e da folha, eu realmente coloquei no mesmo nível.
As redes clássicas de três níveis nos ensinaram a considerar o uplink (o termo é realmente daqui), como links. E aqui acontece que o "uplink" do DCI diminui, o que de certa forma quebra a lógica usual. No caso de grandes redes, quando os data centers são divididos em unidades menores -
PODs (Ponto de Entrega),
Edge-PODs separados são alocados para DCI e acesso a redes externas.
Por conveniência, no futuro ainda vou desenhar Edge on Spine, embora tenhamos em mente que não há inteligência sobre Spine e diferenças ao trabalhar com Leaf e Edge-leaf comuns (embora possa haver nuances, mas em geral é assim).
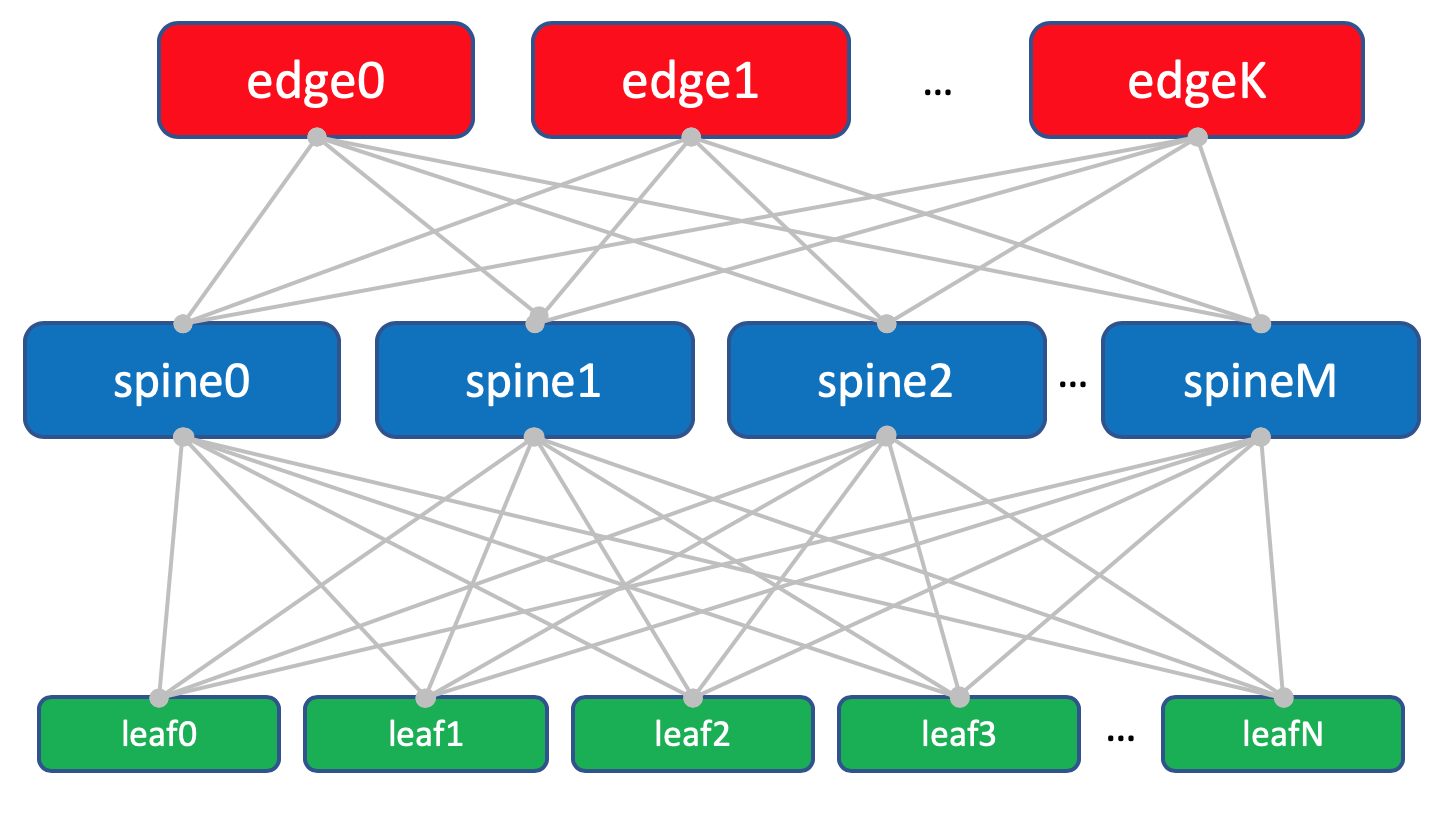 Layout de fábrica com folhas de borda.
Layout de fábrica com folhas de borda.Trinity Leaf, Spine e Edge formam uma rede ou fábrica de Underlay.
A tarefa da fábrica de rede (leia Underlay), como já determinamos na
edição anterior , é muito, muito simples - fornecer conectividade IP entre máquinas, tanto no mesmo DC quanto no meio.
É por isso que a rede é chamada de fábrica, assim como, por exemplo, uma fábrica de comutação dentro de caixas de rede modulares, que podem ser encontradas em mais detalhes no
SDSM14 .
Em geral, essa topologia é chamada de fábrica, porque a malha na tradução é uma malha. E é difícil não concordar:

Fábrica completamente L3. Sem VLANs, sem transmissão - estes são ótimos programadores em LAN_DC, eles podem escrever aplicativos que vivem no paradigma L3 e as máquinas virtuais não exigem Live Migration ao salvar o endereço IP.
E novamente: a resposta à pergunta por que a fábrica e por que L3 - em um
artigo separado.
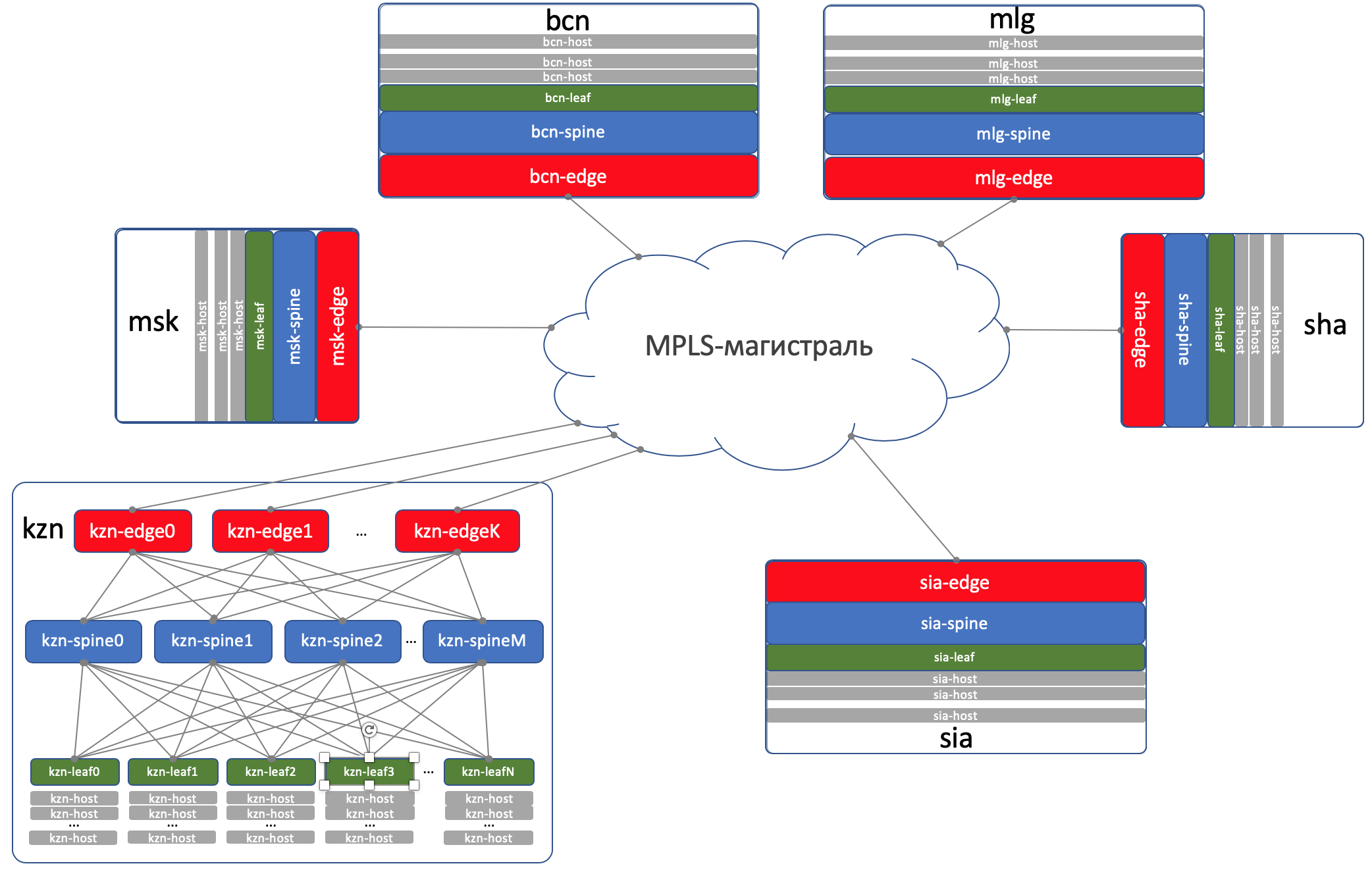
DCI - Interconexão de Data Center (Inter-DC)
O DCI será organizado usando Edge-Leaf, ou seja, eles são nosso ponto de saída para a rodovia.
Para simplificar, assumimos que os controladores de domínio estejam conectados por links diretos.
Excluímos a conectividade externa da consideração.
Estou ciente de que toda vez que removo um componente, simplifico bastante a rede. E com a automação de nossa rede abstrata, tudo ficará bem, mas muletas aparecerão na rede real.
Isso é verdade. No entanto, o objetivo desta série é pensar e trabalhar em abordagens, e não heroicamente resolver problemas imaginários.
No Edge-Leafs, o underlay é colocado na VPN e transmitido pelo backbone MPLS (o mesmo link direto).
Aqui está um esquema de nível superior.
Encaminhamento
Para roteamento dentro do controlador de domínio, usaremos o BGP.
No tronco MPLS OSPF + LDP
Para o DCI, ou seja, a organização da conectividade na parte inferior é BGP L3VPN sobre MPLS.
 Esquema geral de roteamento
Esquema geral de roteamentoNão há OSPF e ISIS na fábrica (protocolo de roteamento proibido na Federação Russa).
E isso significa que não haverá descoberta automática e cálculos de caminho mais curto - apenas manual (de fato automático - estamos aqui sobre automação) configurações de protocolo, vizinhança e políticas.
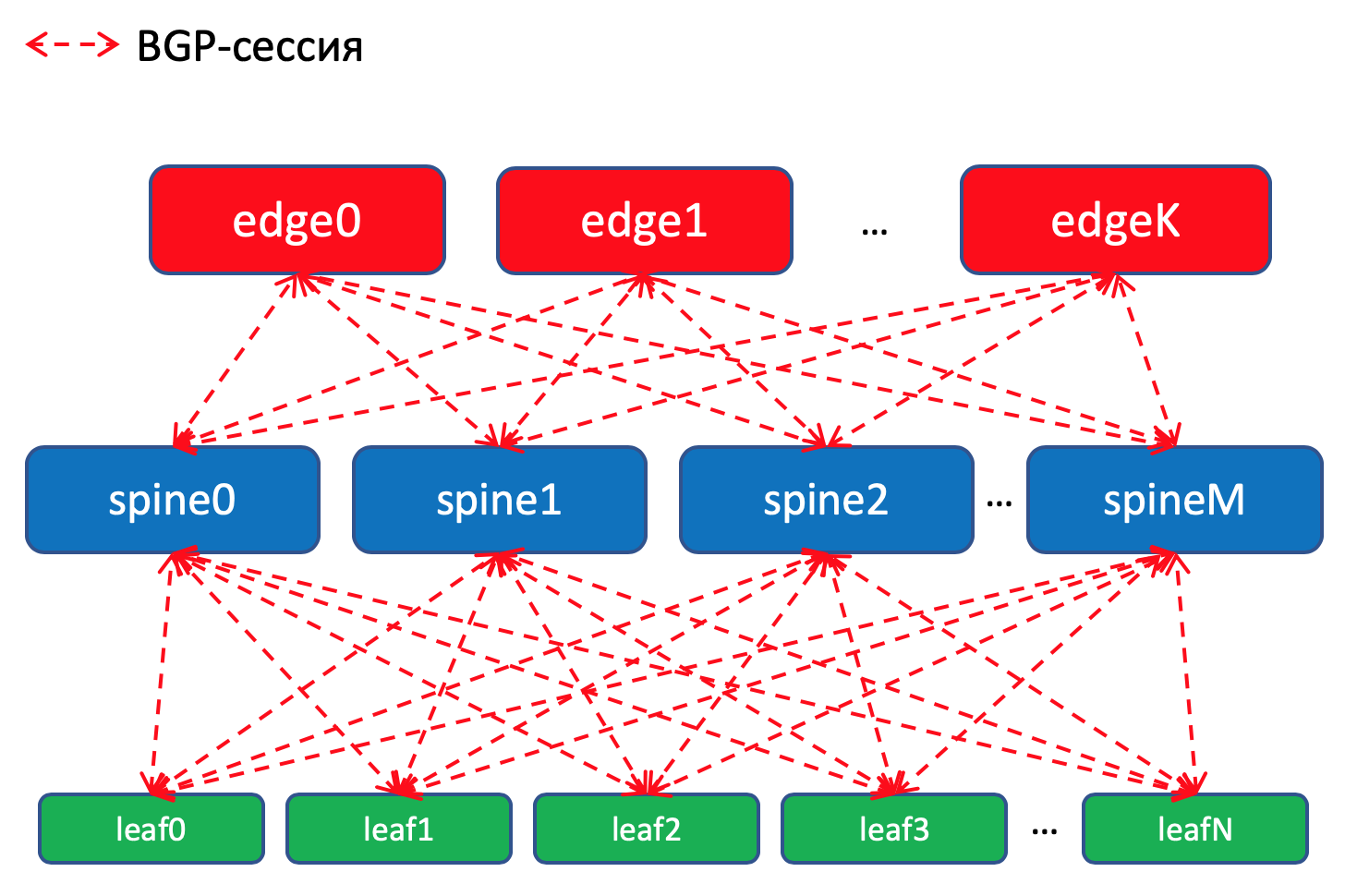 Esquema de roteamento BGP dentro do DCPor que bgp?
Esquema de roteamento BGP dentro do DCPor que bgp?Existe
uma RFC inteira chamada Facebook e Arista sobre esse assunto, que explica como construir redes
muito grandes de data centers usando BGP. Lê quase como uma arte, recomendo para uma noite lânguida.
E uma seção inteira no meu artigo é dedicada a isso. Para onde estou
enviando você .
Mas, em resumo, nenhum IGP é adequado para redes de grandes centros de dados, onde milhares de dispositivos de rede contam.
Além disso, o uso do BGP em qualquer lugar permite que você não use o suporte de vários protocolos diferentes e a sincronização entre eles.
De coração, em nossa fábrica, que com um alto grau de probabilidade não crescerá rapidamente, a OSPF seria suficiente para os olhos. Na verdade, esses são os problemas dos megascalers e dos titãs das nuvens. Mas vamos imaginar alguns problemas de que precisamos e usaremos o BGP, como Peter Lapukhov legou.
Políticas de roteamento
Nos comutadores Leaf, importamos para prefixos BGP as interfaces Underlay com redes.
Teremos uma sessão BGP entre
cada par Leaf-Spine, na qual esses prefixos de Underlay serão anunciados em uma rede de poças.

Dentro de um data center, distribuiremos os detalhes importados para o ToRe. No Edge-Leafs, nós os agregaremos e os anunciaremos em controladores remotos e os reduziremos a ToRs. Ou seja, cada ToR saberá exatamente como chegar a outro ToR no mesmo CD e onde é o ponto de entrada para chegar ao ToR em outro CD.
No DCI, as rotas serão transmitidas como VPNv4. Para fazer isso, no Edge-Leaf, a interface da fábrica será colocada em VRF, vamos chamá-lo de UNDERLAY, e o bairro com Spine no Edge-Leaf surgirá dentro do VRF e entre os Edge-Leafs na família VPNv4.
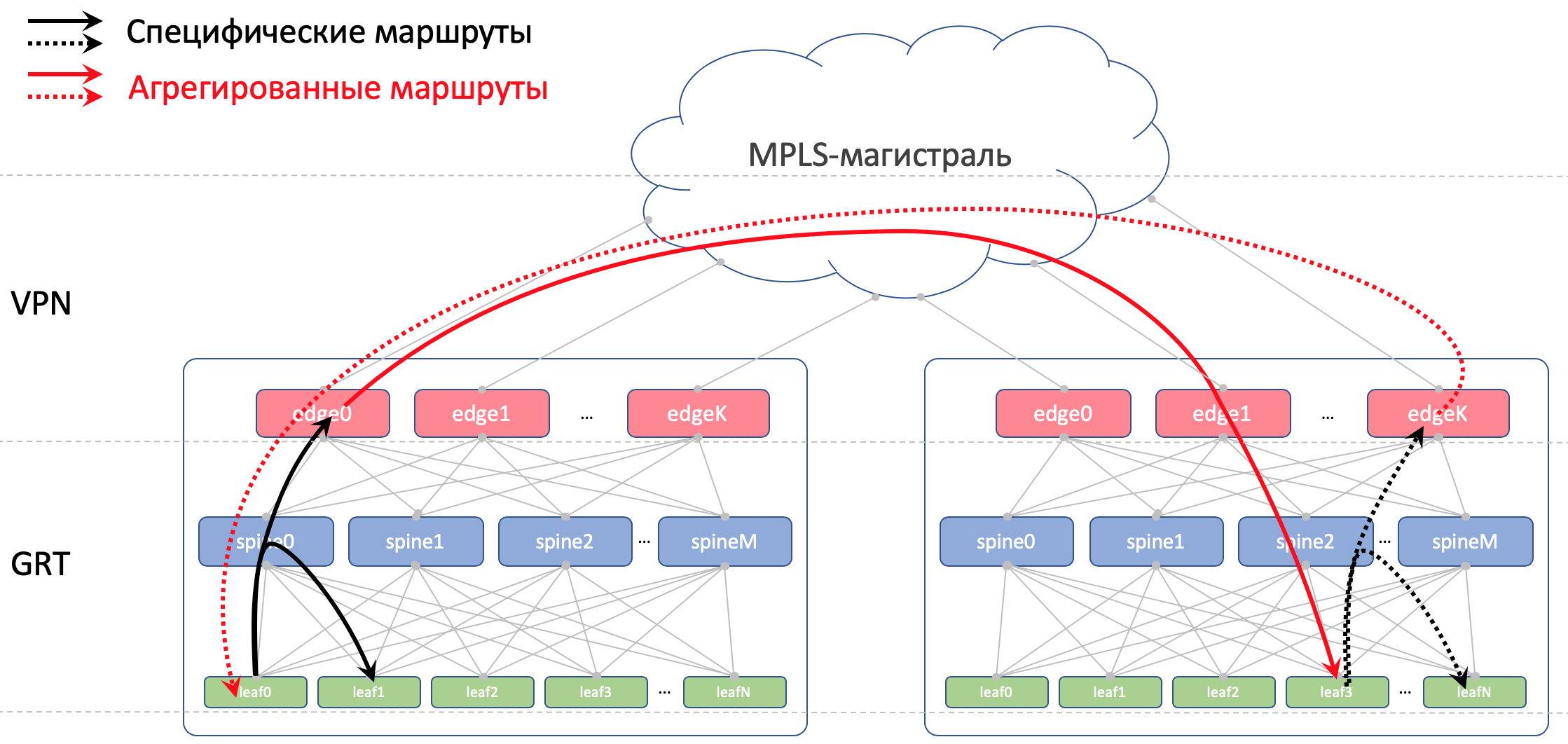
E também proibiremos o anúncio de rotas recebidas de espinhos, de volta a eles.
No Leaf and Spine, não importaremos Loopbacks. Precisamos deles apenas para determinar o ID do roteador.
Mas no Edge-Leafs nós o importamos para o BGP Global. Entre os endereços de loopback, o Edge Leafs estabelecerá uma sessão BGP na família de VPN IPv4 entre si.
Entre os dispositivos EDGE, teremos um backbone OSPF + LDP. Tudo em uma zona. Configuração extremamente simples.
Aqui está uma imagem do roteamento.
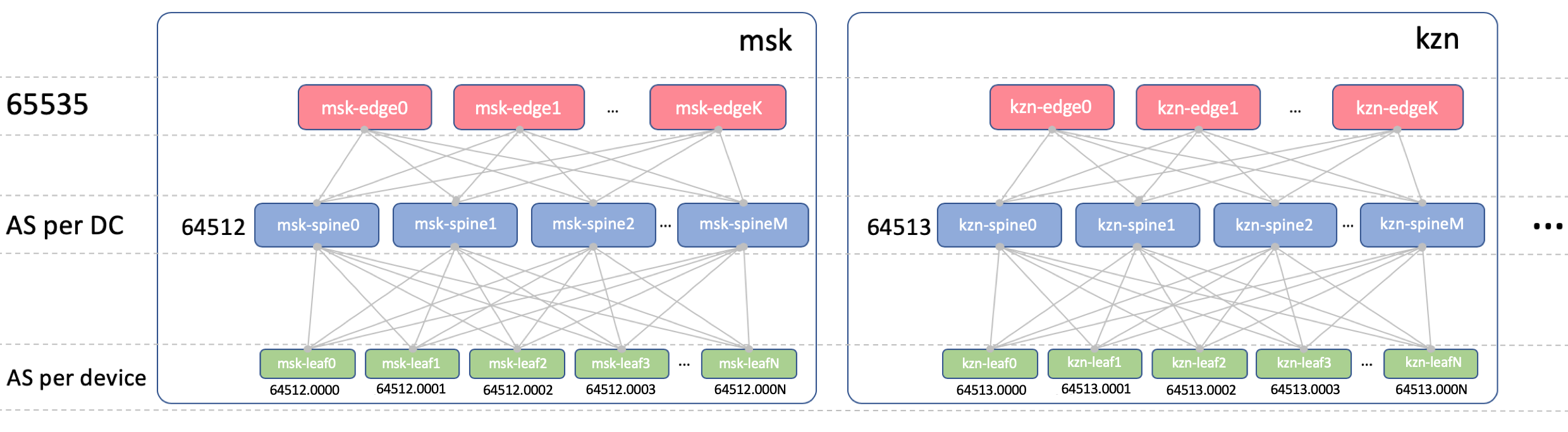
BGP ASN
Edge-Leaf ASN
No Edge-Leafs, haverá um ASN em todos os CDs. É importante que exista iBGP entre as folhas de bordo e que não nos deparemos com as nuances do eBGP. Que seja 65535. Na realidade, poderia ser um número público AS.
Spine ASN
Na Spine, teremos um ASN por DC. Vamos começar aqui a partir do primeiro número do intervalo AS privado - 64512, 64513 E assim por diante.
Por que o ASN está em DC?
Decompomos esta questão em duas:
- Por que os mesmos ASNs estão em todos os espinhos do mesmo controlador de domínio?
- Por que eles são diferentes em diferentes CDs?
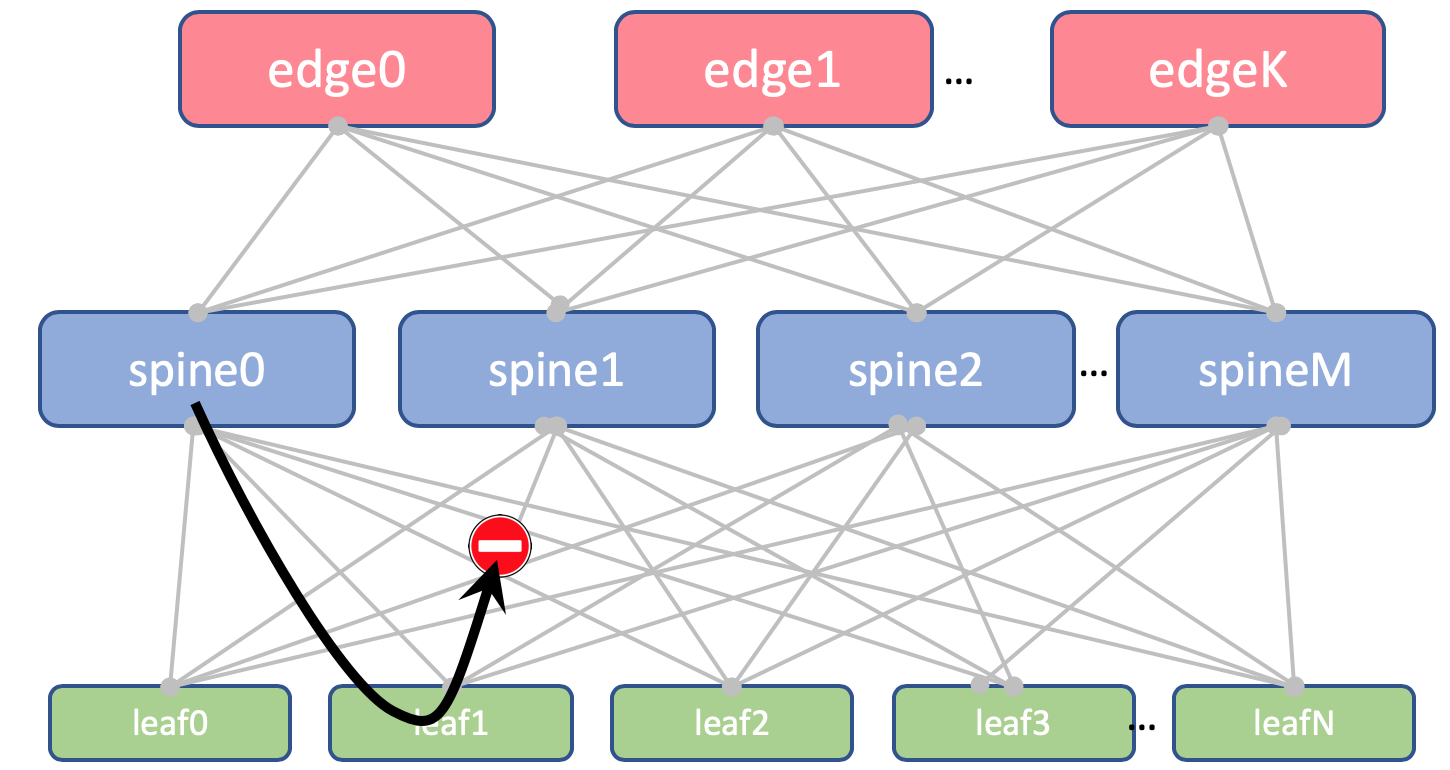
Por que os mesmos ASNs em todos os espinhos de um DCAqui está a aparência da rota Anderlay do AS-Path no Edge-Leaf:
[leafX_ASN, spine_ASN , edge_ASN]Se você tentar anunciar de volta ao Spine, ele será descartado porque o AS (Spine_AS) já está na lista.
No entanto, dentro do CD, estamos completamente satisfeitos que as rotas do Underlay que subiram ao Edge não serão capazes de descer. Toda a comunicação entre os hosts no DC deve ocorrer dentro do nível da coluna vertebral.
Ao mesmo tempo, as rotas agregadas de outros controladores de domínio, em qualquer caso, atingirão livremente os ToRs - em seu caminho AS haverá apenas ASN 65535 - o número de AS Edge-Leafs, porque foi neles que eles foram criados.
Por que são diferentes em diferentes DCTeoricamente, podemos precisar arrastar Loopbacks e algumas máquinas virtuais de serviço entre os controladores de domínio.
Por exemplo, em um host, executaremos um Route Reflector ou
o mesmo VNGW (Virtual Network Gateway), que será bloqueado com o ToR via BGP e anunciará seu loopback, que deve estar disponível em todos os controladores de domínio.
Então, aqui está a aparência do seu AS-Path:
[VNF_ASN, leafX_DC1_ASN, spine_DC1_ASN , edge_ASN, spine_DC2_ASN , leafY_DC2_ASN]E aqui não deve haver ASNs duplicados em nenhum lugar.
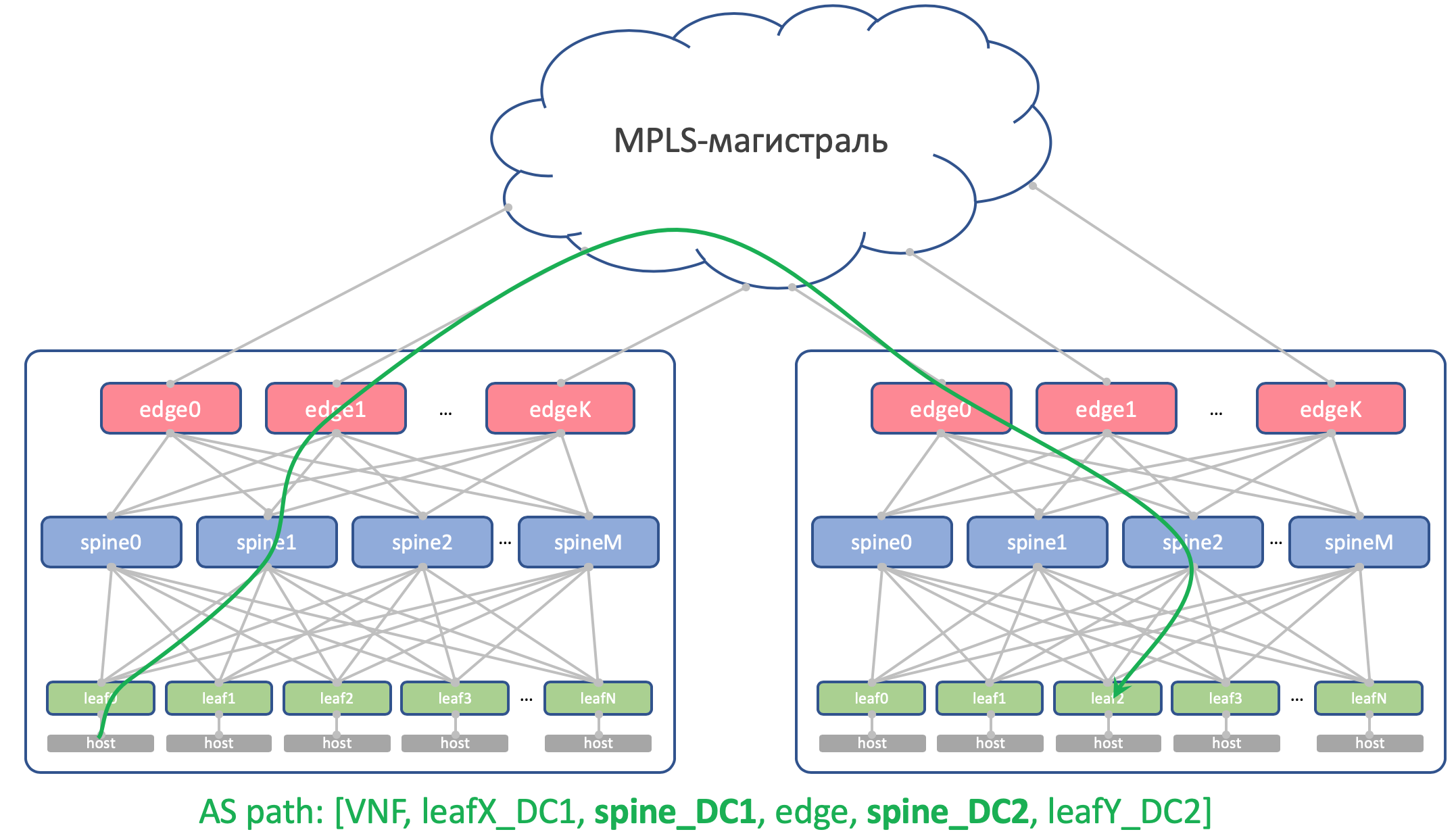
Ou seja, Spine_DC1 e Spine_DC2 devem ser diferentes, assim como leafX_DC1 e leafY_DC2, que é exatamente o que estamos abordando.
Como você provavelmente sabe, existem hacks que permitem aceitar rotas com ASNs repetidos, apesar do mecanismo de prevenção de loopback da Cisco. E tem usos até bastante legítimos. Mas essa é uma violação potencial na resiliência da rede. E eu pessoalmente caí nele algumas vezes.
E se tivermos a oportunidade de não usar coisas perigosas, vamos usá-lo.
Asn da folha
Teremos um ASN individual em cada switch Leaf em toda a rede.
Fazemos isso pelos motivos acima: AS-Path sem loops, configuração BGP sem marcadores.
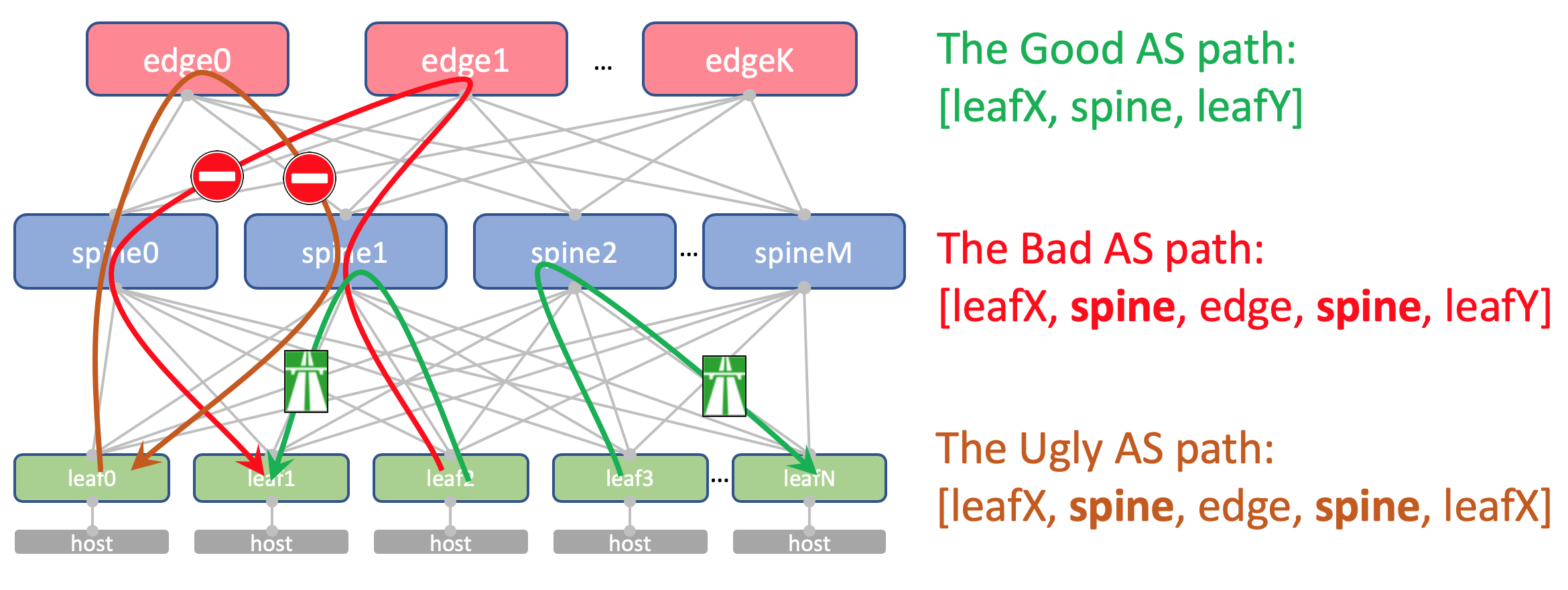
Para que as rotas entre Leafs passem sem obstáculos, o AS-Path deve se parecer com o seguinte:
[leafX_ASN, spine_ASN, leafY_ASN]onde leafX_ASN e leafY_ASN seria bom ser diferente.
Isso também é necessário para a situação com o anúncio do loopback do VNF entre controladores de domínio:
[VNF_ASN, leafX_DC1_ASN , spine_DC1_ASN, edge_ASN, spine_DC2_ASN, leafY_DC2_ASN ]Usaremos o ASN de 4 bytes e o geraremos com base no número do ASN e do comutador de folhas da Spine, ou seja, assim:
Spine_ASN.0000X .
Aqui está uma foto com o ASN.
Plano IP
Basicamente, precisamos alocar endereços para as seguintes conexões:
- Underlay os endereços de rede entre o ToR e a máquina. Eles devem ser únicos em toda a rede para que qualquer máquina possa se comunicar com outra. Ótimo para 10/8 . Para cada rack / 26 com uma margem. Alocaremos / 19 para DC e / 17 para a região.
- Endereços de link entre Leaf / Tor e Spine.
Gostaria de atribuí-los algoritmicamente, ou seja, calcular a partir dos nomes dos dispositivos que precisam ser conectados.
Que seja ... 169.254.0.0/16.
Ou seja, 169.254.00X.Y / 31 , onde X é o número da coluna, Y é a rede P2P / 31.
Isso permitirá que você execute até 128 racks e até 10 Spine no DC. Os endereços de link podem (e serão) repetidos de DC para DC. - Organizaremos a articulação Spine - Edge-Leaf nas sub-redes 169.254.10X.Y / 31 , onde da mesma maneira X é o número da coluna, Y é a rede P2P / 31.
- Vincule endereços do Edge-Leaf ao backbone do MPLS. Aqui a situação é um pouco diferente - o lugar de conectar todas as peças em uma torta, para que a reutilização dos mesmos endereços não funcione - você precisa selecionar a próxima sub-rede livre. Portanto, tomaremos 192.168.0.0/16 como base e extrairemos os livres.
- Endereços de loopback. Dê a eles todo o intervalo 172.16.0.0/12 .
- Folha - a / 25 por CC - os mesmos 128 racks. Aloque por / 23 para a região.
- Spine - by / 28 no CD - até 16 Spine. Aloque por / 26 para a região.
- Edge-Leaf - por / 29 no DC - até 8 caixas. Aloque por / 27 para a região.
Se no CD não tivermos o suficiente dos intervalos selecionados (mas eles não estarão lá - fingimos ser hiper-skeylerostvo), basta selecionar o próximo bloco.
Aqui está uma foto com endereçamento IP.

Loopbacks:
| Prefixo | Função do dispositivo | Região | DC |
| 172.16.0.0/23 | orla | | |
| 172.16.0.0/27 | ru | |
| 172.16.0.0/29 | msk |
| 172.16.0.8/29 | kzn |
| 172.16.0.32/27 | sp | |
| 172.16.0.32/29 | bcn |
| 172.16.0.40/29 | mlg |
| 172.16.0.64/27 | cn | |
| 172.16.0.64/29 | sha |
| 172.16.0.72/29 | sia |
| 172.16.2.0/23 | coluna vertebral | | |
| 172.16.2.0/26 | ru | |
| 172.16.2.0/28 | msk |
| 172.16.2.16/28 | kzn |
| 172.16.2.64/26 | sp | |
| 172.16.2.64/28 | bcn |
| 172.16.2.80/28 | mlg |
| 172.16.2.128/26 | cn | |
| 172.16.2.128/28 | sha |
| 172.16.2.144/28 | sia |
| 172.16.8.0/21 | folhagem | | |
| 172.16.8.0/23 | ru | |
| 172.16.8.0/25 | msk |
| 172.16.8.128/25 | kzn |
| 172.16.10.0/23 | sp | |
| 172.16.10.0/25 | bcn |
| 172.16.10.128/25 | mlg |
| 172.16.12.0/23 | cn | |
| 172.16.12.0/25 | sha |
| 172.16.12.128/25 | sia |
Underlay:
| Prefixo | Região | DC |
| 10.0.0.0/17 | ru | |
| 10.0.0.0/19 | msk |
| 10.0.32.0/19 | kzn |
| 10.0.128.0/17 | sp | |
| 10.0.128.0/19 | bcn |
| 10.0.160.0/19 | mlg |
| 10.1.0.0/17 | cn | |
| 10.1.0.0/19 | sha |
| 10.1.32.0/19 | sia |
Laba
Dois fornecedores. Uma rede ADSM.
Juniper + Arista. Ubuntu Boa e velha Eva.
A quantidade de recursos em nosso virtual em Miran ainda é limitada, portanto, para a prática, usaremos uma rede tão simplificada até o limite.
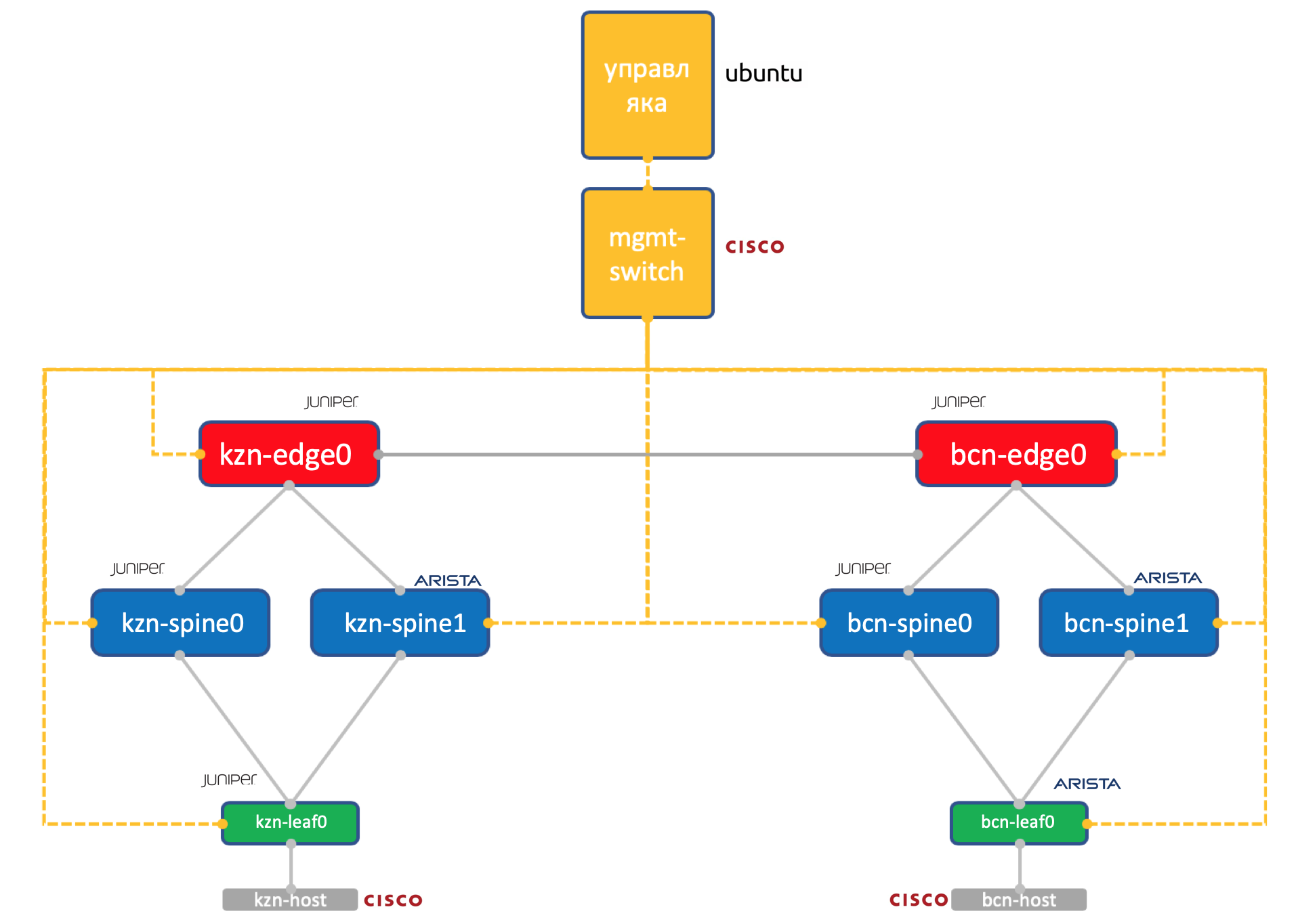
Dois data centers: Kazan e Barcelona.
- Dois espinhos em cada um: Juniper e Arista.
- Um toro (Leaf) em cada um - Juniper e Arista, com um host conectado (vamos usar a Cisco IOL leve para isso).
- Um nó Edge-Leaf (apenas Juniper até o momento).
- Um switch da Cisco para governar todos eles.
- Além das caixas de rede, uma máquina virtual de gerenciamento foi lançada. Executando o Ubuntu.
Ele tem acesso a todos os dispositivos, sistemas IPAM / DCIM, vários scripts Python, ansible e qualquer outra coisa que possamos precisar estará girando nele.
A configuração completa de todos os dispositivos de rede que tentaremos reproduzir usando a automação.
Conclusão
Também aceita? Sob cada artigo para fazer uma breve conclusão?
Por isso, escolhemos a rede Klose de
três níveis dentro do DC, porque esperamos muito tráfego Leste-Oeste e queremos ECMP.
Dividimos a rede em físico (underlay) e virtual (overlay). Nesse caso, a sobreposição começa no host - simplificando, assim, os requisitos para a subjacência.
Escolhemos o BGP como o protocolo de roteamento para redes não retransmitidas por sua escalabilidade e flexibilidade de políticas.
Teremos nós separados para a organização do DCI - Edge-leaf.
Haverá OSPF + LDP no tronco.
O DCI será implementado com base no MPLS L3VPN.
Para links P2P, calcularemos os endereços IP algoritmicamente com base nos nomes dos dispositivos.
Os Lupbacks serão atribuídos pela função dos dispositivos e sua localização sequencialmente.
Prefixos de subjacência - somente nos comutadores Leaf, sequencialmente, com base em sua localização.
Suponha que não temos o equipamento instalado no momento.
Portanto, nossos próximos passos serão colocá-los nos sistemas (IPAM, inventário), organizar o acesso, gerar uma configuração e implantá-la.
No próximo artigo, trataremos do Netbox, o sistema de gerenciamento de inventário e espaço IP no controlador de domínio.
Obrigado
- Andrey Glazkov, também conhecido como @glazgoo, para revisão e edição
- Alexander Klimenko, também conhecido como @ v00lk, para revisão e edição
- Artyom Chernobay para KDPV