Hoje, queremos falar sobre o conceito Insight-Driven e como colocá-lo em prática usando DataOps e ModelOps. A abordagem orientada a insights é um tópico abrangente sobre o qual falamos em detalhes em nossa biblioteca recentemente criada de materiais úteis sobre gerenciamento de dados (o link estará abaixo). Na habratopica de hoje, vamos nos concentrar nos estágios principais do ciclo de vida dos modelos de aprendizado de máquina, como Este é um dos principais tópicos do conceito.

Qual é a essência da abordagem orientada por insights
Muitos especialistas têm falado sobre a importância do
Data-Driven por um longo tempo, o que, é claro, é absolutamente correto em geral, porque essa abordagem envolve a tomada de decisões de gerenciamento mais eficientes analisando os dados, e não apenas a experiência da intuição e da liderança pessoal. Os analistas da Forrester
observam que as empresas que dependem da análise de dados em suas atividades crescem, em média, 30% mais rápido que os concorrentes.
Mas todos entendemos que a empresa está avançando não na disponibilidade de dados como tal, mas na capacidade de trabalhar com eles - ou seja, em encontrar insights que podem ser monetizados e pelos quais vale a pena acumular, processar e analisar dados. Portanto, estamos falando especificamente sobre a abordagem Insight-Driven, como uma versão mais avançada do Data-Driven.
Na maioria das vezes, quando se trata de trabalhar com dados, a maioria dos especialistas significa principalmente informações estruturadas dentro da empresa; no entanto, há pouco tempo, falamos sobre por que a grande maioria dos negócios não usa cerca de 80% dos dados potencialmente disponíveis. O Insight-Driven apenas cria a base para complementar a imagem com informações não estruturadas externas, bem como os resultados da interpretação dos dados para procurar dependências implícitas entre eles.
O link prometido para uma biblioteca completa de materiais sobre gerenciamento de dados , onde há o vídeo mencionado sobre dados não utilizados.
DevOps + DataOps + ModelOps
As práticas orientadas a insights são baseadas em DevOps, DataOps e ModelOps. Vamos falar sobre por que uma combinação dessas práticas específicas é capaz de garantir a implementação completa da abordagem.
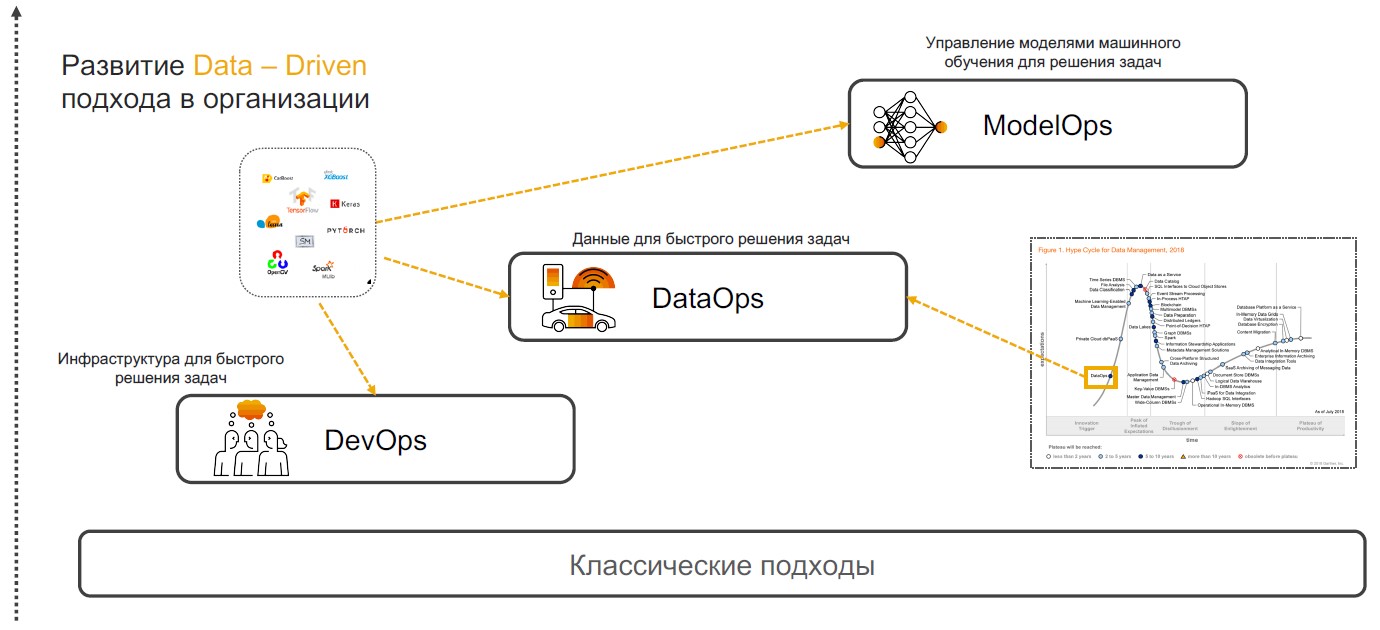 DevOps + DataOps
DevOps + DataOps . O DevOps envolve reduzir o tempo de lançamento do produto, suas atualizações e minimizar o custo de suporte adicional por meio do uso de ferramentas para controle de versão, integração contínua, teste e monitoramento e gerenciamento de lançamento. Se adicionarmos a essas práticas uma compreensão de quais dados estão dentro da empresa, como gerenciar seu formato e estrutura, marcar, rastrear qualidade, transformação, agregação e ter a capacidade de analisar e visualizar rapidamente, obtemos o
DataOps . O foco dessa abordagem é a implementação de cenários usando modelos de aprendizado de máquina que fornecem suporte à decisão, pesquisa e previsão de insight.
ModelOps . Assim que a empresa começa a usar ativamente os modelos de aprendizado de máquina, torna-se necessário gerenciá-los, monitorar métricas de qualidade, treinar novamente, comparar, atualizar e versão. ModOps é um conjunto de práticas e abordagens que simplificam o gerenciamento do ciclo de vida desses modelos. É usado por empresas que lidam com um grande número de modelos em várias áreas da empresa, por exemplo, serviços de streaming.
A implementação da abordagem orientada por insights em uma empresa não é uma tarefa trivial. Mas para aqueles que ainda gostariam de começar a trabalhar com ele, diremos como fazer isso.
Pesquisa e preparação de dados
A implementação de práticas orientadas a insights começa com a pesquisa e preparação de dados. Mais tarde, eles são analisados e usados para construir modelos de MOs, mas os casos são determinados previamente em que algoritmos inteligentes podem ser úteis.
Definição de tarefas . Nesta fase, a empresa estabelece metas de negócios, por exemplo, aumentar o lucro no mercado. Em seguida, as métricas de negócios estão determinadas a alcançá-las, como um aumento no número de novos clientes, o tamanho da verificação média e a porcentagem de conversão. Portanto, existem cenários nos quais já é possível procurar dados relevantes.
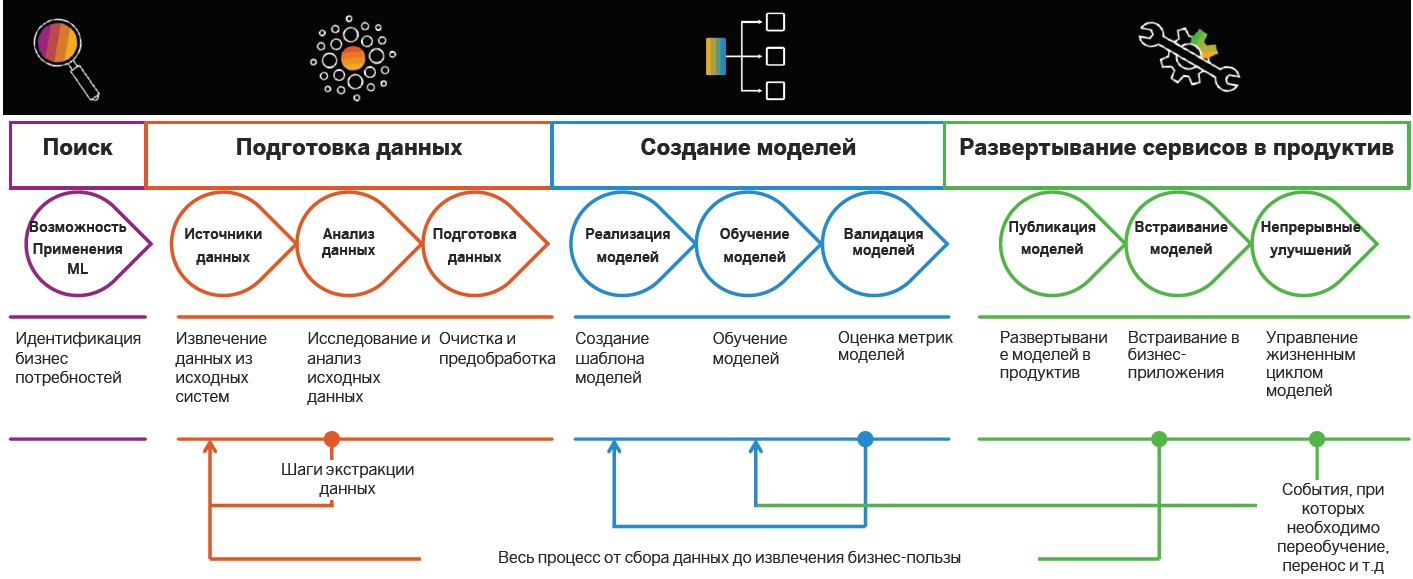 Fornecimento e análise de dados
Fornecimento e análise de dados . Quando as metas e orientações para recuperação de dados são definidas, chega a hora de analisar as fontes. Este e os estágios subsequentes do desenvolvimento de cenários inteligentes relacionados à preparação
levam de 70 a 80% dos orçamentos das empresas na implementação. O fato é que a qualidade do conjunto de dados afeta a precisão dos modelos projetados de aprendizado de máquina. Mas as informações necessárias costumam ser "dispersas" em vários sistemas - elas podem estar em bancos de dados relacionais, como MS SQL, Oracle, PostgreSQL, na plataforma Hadoop e em muitas outras fontes. E, nesta fase, você precisa entender onde estão os dados relevantes e como coletá-los.
Frequentemente, os analistas descarregam e processam tudo manualmente, o que diminui bastante os processos e aumenta o risco de erros. Na SAP, oferecemos a nossos clientes a implementação de um meta-sistema que se conecta às fontes certas e coleta dados mediante solicitação.
Assim, você pode catalogar todas as tabelas, pools externos com dados não estruturados e outras fontes - definir tags (incluindo hierárquicas) e coletar rapidamente informações relevantes. Condicionalmente, se as informações sobre um cliente estiverem em bancos de dados diferentes, será suficiente indicar essas entidades. Na próxima vez que precisar de um "conjunto de dados do cliente", você escolherá uma vitrine pronta.
Depois que as fontes de dados são identificadas, você pode seguir
para o rastreamento e criação de perfil de qualidade de dados . Esta operação é necessária para entender o número de lacunas, valores exclusivos e verificar a qualidade geral dos dados. Por tudo isso, você pode criar painéis com regras e acompanhar quaisquer alterações.
Transformação de dados . O próximo passo é o trabalho direto com dados que devem resolver as tarefas. Para fazer isso, os dados são limpos: verificado, deduplicado, preenchido os espaços. Esse processo pode ser simplificado com a programação baseada em fluxo. Nesse caso, estamos lidando com uma sequência de operações - um pipeline. Sua saída pode ser enviada para uma interface gráfica ou outro sistema para trabalhos subseqüentes. Aqui, os manipuladores de dados são montados como um construtor (e dependendo do cenário). Pode ser um processamento periódico ou de streaming ou um serviço REST.

O conceito de programação baseada em fluxo é adequado para resolver uma ampla gama de tarefas: desde prever vendas e avaliar a qualidade do serviço até encontrar os motivos da rotatividade de clientes. Existem duas ferramentas para pesquisar e preparar dados no SAP. O primeiro é o
SAP Data Intelligence para analistas de dados. Diferentemente de plataformas semelhantes, esta solução trabalha com dados distribuídos e não requer centralização - fornece um ambiente unificado para a implementação, publicação, integração, dimensionamento e suporte de modelos. A segunda ferramenta é o
SAP Agile Data Preparation , um pequeno serviço de preparação de dados direcionado a analistas e usuários de negócios. Possui uma interface simples que ajuda a coletar um conjunto de dados, filtrar, processar e mapear informações. Ele pode ser publicado em uma vitrine para a transferência de BI de autoatendimento - sistemas de autoatendimento para criar cenários analíticos (eles não exigem conhecimento aprofundado no campo da ciência de dados).
Criação de modelo
Após a preparação, é a vez de criar modelos de aprendizado de máquina. Aqui se destacam: pesquisa, prototipagem e produtividade. A última etapa inclui a implementação de pipelines para treinamento e aplicação de modelos.
Pesquisa e prototipagem . Atualmente, existem muitos frameworks e bibliotecas temáticas disponíveis. Os líderes em frequência de uso são o TensorFlow e o PyTorch, cuja popularidade no ano passado
cresceu 243%. A plataforma SAP permite o uso de qualquer uma dessas estruturas e pode ser complementada de maneira flexível com bibliotecas como CatBoost da Yandex, LightGBM da Microsoft, scikit-learn e pandas. Você ainda pode usar o
HANA DataFrame na biblioteca hanaml. Essa API imita pandas, e o HANA permite processar grandes quantidades de dados usando a "computação lenta".
Para modelos de prototipagem, oferecemos o Jupyter Lab. Esta é uma ferramenta de código aberto para profissionais de ciência de dados. Nós o incorporamos ao ecossistema SAP, enquanto expandimos a funcionalidade. O Jupyter Lab trabalha na plataforma Data Intelligence e, devido à biblioteca sapdi integrada, pode conectar-se a qualquer fonte de dados conectada nas etapas anteriores, monitorar experimentos e métricas de qualidade para análises adicionais.
Separadamente, deve-se observar que blocos de anotações, conjuntos de dados,
pipelines de treinamento e
inferência , bem como serviços para implantação de modelos, devem ser consistentes. Para combinar todos esses objetos, use o script ML (objeto com versão).
Modelo de treinamento . Existem duas opções para trabalhar com scripts de ML. Existem modelos que não precisam ser treinados. Por exemplo, no SAP Data Intelligence, oferecemos sistemas de reconhecimento facial, tradução automática, OCR (reconhecimento óptico de caracteres) e outros. Todos eles trabalham fora da caixa. Por outro lado, existem aqueles modelos que precisam ser treinados e produtivos. Esse treinamento pode ocorrer no próprio cluster de Inteligência de Dados e em recursos de computação externos que são conectados apenas pela duração dos cálculos.
"Sob o capô" no SAP Data Intelligence está a plataforma Kubernetes, portanto todos os operadores estão vinculados a contêineres de encaixe. Para trabalhar com o modelo, basta descrever o arquivo de janela de encaixe e anexar tags a ele para as bibliotecas e versões usadas.
Outra maneira de criar modelos é com o AutoML. Estes são sistemas automatizados de MO. Essas ferramentas são desenvolvidas por
H2O ,
Microsoft ,
Google, etc. Eles trabalham nessa direção
no MIT . Mas os engenheiros da universidade não se concentram na incorporação e na produtividade. A SAP também possui um sistema AutoML que se concentra em resultados rápidos. Ela trabalha no HANA e tem acesso direto aos dados - eles não precisam ser movidos ou modificados em nenhum lugar. Agora, estamos desenvolvendo uma solução que se concentra na qualidade dos modelos - anunciaremos um lançamento mais tarde.
Gerenciamento do ciclo de vida . As condições mudam, as informações ficam desatualizadas e, portanto, a precisão dos modelos MO diminui com o tempo. Assim, tendo acumulado novos dados, podemos treinar novamente o modelo e refinar os resultados. Por exemplo, um grande produtor de bebidas
usa informações de preferência do consumidor em 200 países diferentes para treinar sistemas inteligentes. A empresa leva em consideração o gosto das pessoas, a quantidade de açúcar, o teor calórico das bebidas e até os produtos que as marcas concorrentes oferecem nos mercados-alvo. Os modelos MO determinam automaticamente quais das centenas de produtos a empresa aceitará melhor em uma determinada região.
 Reutilizando Componentes Baseados em Agentes no SAP Data Hub
Reutilizando Componentes Baseados em Agentes no SAP Data HubMas os modelos de versão e atualização também precisam ser feitos à medida que novos algoritmos e atualizações de componentes de hardware são lançadas. Sua implementação pode melhorar a precisão e a qualidade dos modelos usados no trabalho.
Orientado para o crescimento dos negócios
A abordagem para gerenciar os estágios do ciclo de vida dos modelos de aprendizado de máquina descritos acima é, de fato, uma estrutura universal que permite que uma empresa se torne orientada por insights e use o trabalho com dados como um fator essencial para o crescimento dos negócios. As organizações que incorporam esse conceito sabem mais, crescem mais rápido e, em nossa opinião, trabalham muito mais interessantes nessa tecnologia de ponta!
Saiba mais sobre como criar o conceito Insight-Driven em nossa
biblioteca de materiais úteis de gerenciamento de dados , onde coletamos vídeos, folhetos úteis e acessos de avaliação aos sistemas SAP.