Olá, meu nome é Eugene. Trabalho na infraestrutura de pesquisa Yandex.Market. Quero contar à comunidade Habr sobre a cozinha interna do mercado - mas há algo a dizer. Primeiro de tudo, como a Pesquisa de mercado, os processos e a arquitetura funcionam. Como lidamos com situações de emergência: o que acontece se um servidor falhar? E se houver 100 desses servidores?
Você também aprenderá como implementamos novas funcionalidades em vários servidores imediatamente. E como testar serviços complexos diretamente na produção, sem causar transtornos aos usuários. Em geral, como funciona a busca pelo mercado, para que todos estejam bem.
Um pouco sobre nós: que problema resolvemos
Ao inserir texto, procurar produtos por parâmetros ou comparar preços em lojas diferentes, todas as solicitações chegam ao serviço de pesquisa. A pesquisa é o maior serviço do mercado.
Processamos todas as consultas de pesquisa: nos sites market.yandex.ru, beru.ru, serviço Supercheck, Yandex.Advisor e aplicativos móveis. Também incluímos ofertas de produtos nos resultados de pesquisa no yandex.ru.
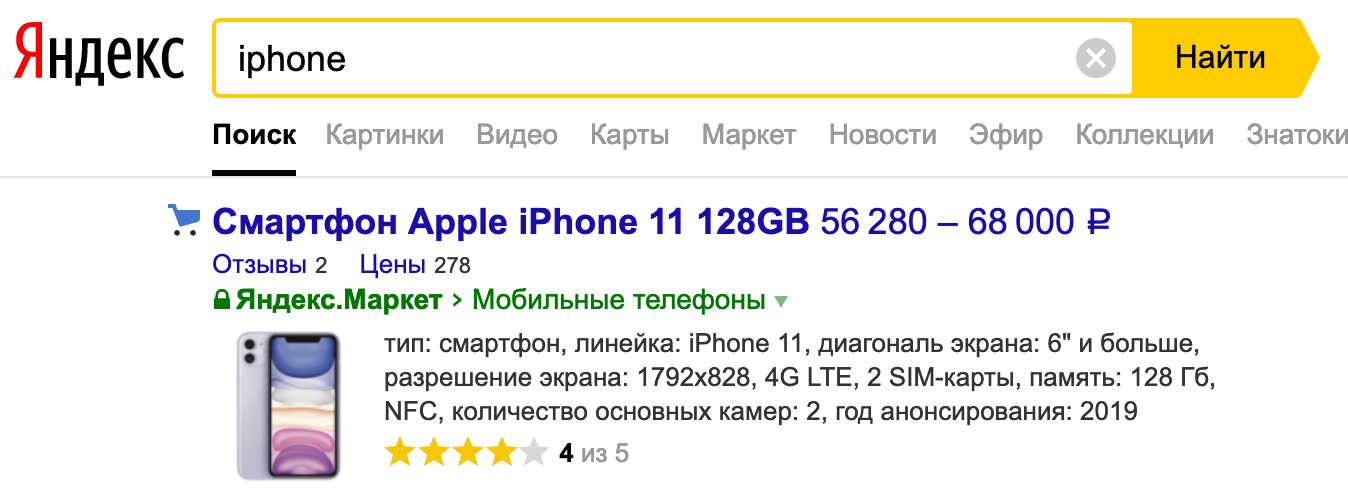
Por serviço de pesquisa, quero dizer não apenas pesquisar diretamente, mas também um banco de dados com todas as ofertas do mercado. A escala é a seguinte: mais de um bilhão de consultas de pesquisa são processadas por dia. E tudo deve funcionar rapidamente, sem interrupções e sempre produzir o resultado desejado.
O que é o que: arquitetura de mercado
Descreva brevemente a arquitetura atual do mercado. Convencionalmente, pode ser descrito pelo esquema abaixo:
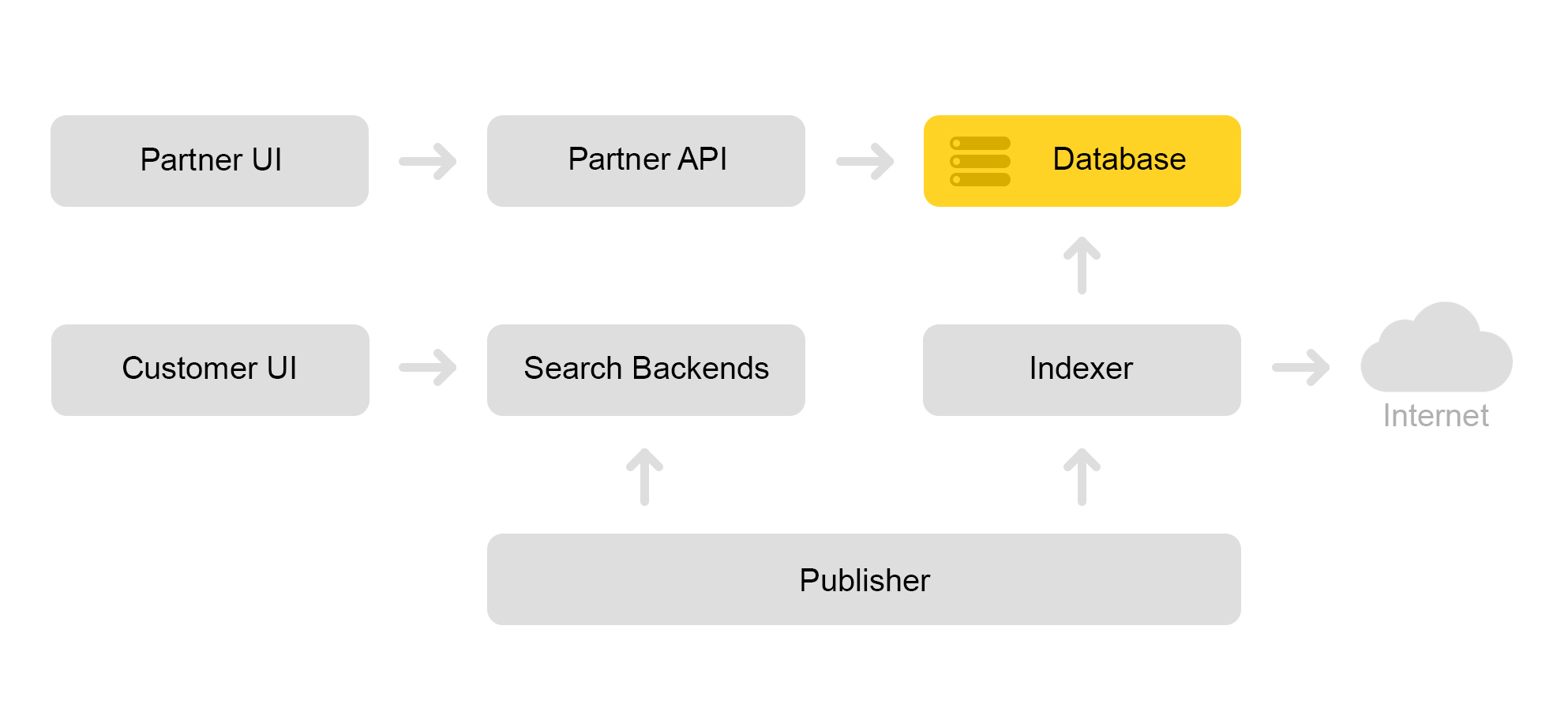
Digamos que uma loja parceira chegue até nós. Ele diz que eu quero vender um brinquedo: esse gato malvado com um squeaker. E um gato malvado sem um tweeter. E apenas um gato. Em seguida, a loja precisa preparar ofertas nas quais o mercado procura. A loja forma um xml especial com ofertas e comunica o caminho para esse xml por meio de uma interface de parceiro. Em seguida, o indexador baixa periodicamente esse xml, verifica erros e armazena todas as informações em um enorme banco de dados.
Existem muitos desses xml salvos. Um índice de pesquisa é criado a partir deste banco de dados. O índice é armazenado em formato interno. Após criar o índice, o serviço Layouts faz o upload para os mecanismos de pesquisa.
Como resultado, um gato malvado com um squeaker aparece no banco de dados e um índice de gato aparece no servidor.
Falarei sobre como procuramos um gato na parte sobre a arquitetura de pesquisa.
Arquitetura de pesquisa de mercado
Vivemos no mundo dos microsserviços: cada solicitação recebida para
market.yandex.ru causa muitas subconsultas e dezenas de serviços participam de seu processamento. O diagrama mostra apenas alguns:
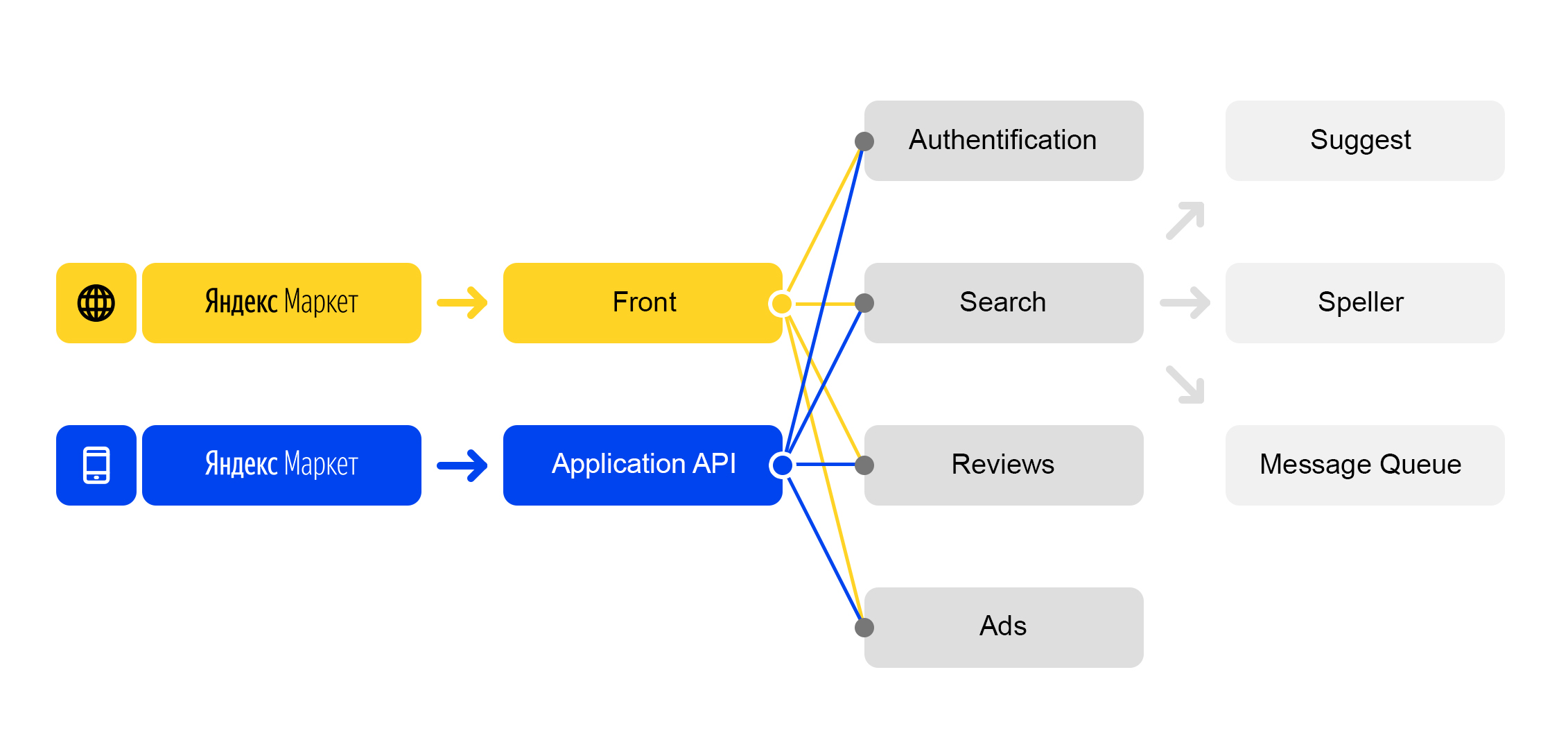 Esquema de processamento de solicitação simplificado
Esquema de processamento de solicitação simplificadoCada serviço tem uma coisa maravilhosa - seu próprio balanceador com um nome exclusivo:
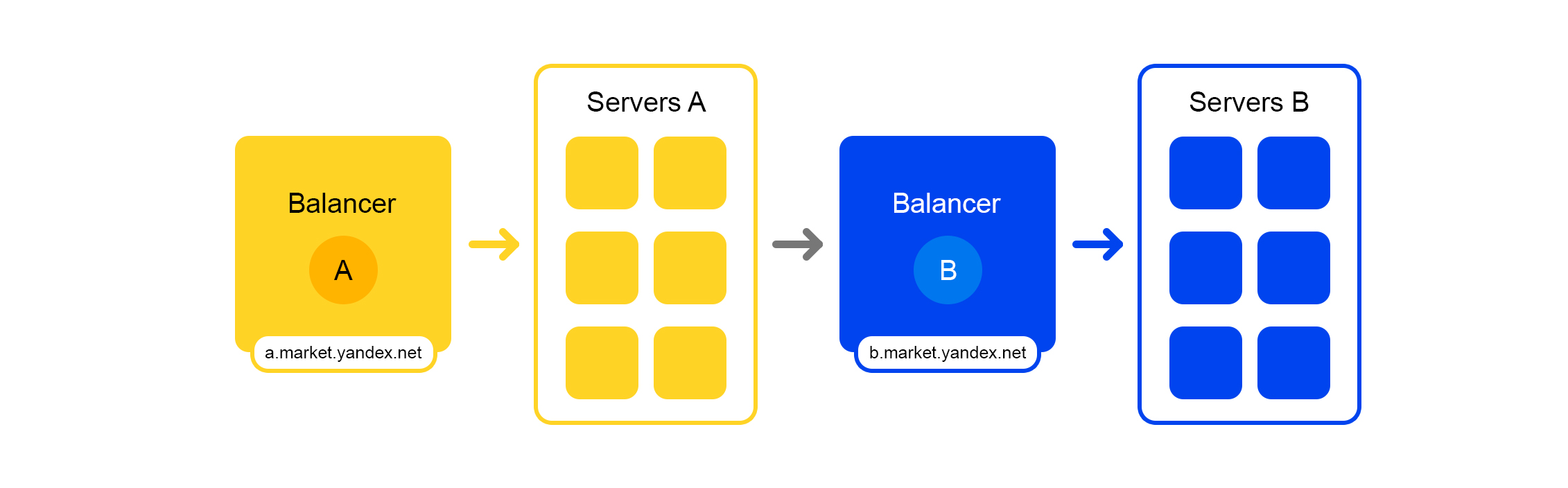
O balanceador nos oferece uma grande flexibilidade no gerenciamento do serviço: por exemplo, você pode desligar os servidores, o que geralmente é necessário para atualizações. O balanceador vê que o servidor está indisponível e redireciona automaticamente solicitações para outros servidores ou data centers. Quando você adiciona ou remove um servidor, a carga é redistribuída automaticamente entre os servidores.
O nome exclusivo do balanceador não depende do datacenter. Quando o serviço A faz uma solicitação para B, por padrão, o balanceador B redireciona a solicitação para o data center atual. Se o serviço estiver indisponível ou ausente no data center atual, a solicitação será redirecionada para outros data centers.
Um único FQDN para todos os datacenters permite que o serviço A geralmente se desconecte dos locais. Sua solicitação para o serviço B será sempre processada. Uma exceção é o caso quando o serviço está em todos os datacenters.
Mas nem tudo é tão fácil com este balanceador: temos um componente intermediário adicional. O balanceador pode estar instável e esse problema é resolvido por servidores redundantes. Também há um atraso adicional entre os serviços A e B. Mas, na prática, é inferior a 1 ms e, para a maioria dos serviços, isso não é crítico.
Combatendo o inesperado: serviços de pesquisa equilibrados e resilientes
Imagine que ocorreu um colapso: você precisa encontrar um gato com um squeaker, mas o servidor trava. Ou 100 servidores. Como sair? Vamos realmente deixar o usuário sem um gato?
A situação é terrível, mas estamos prontos para isso. Eu vou te dizer em ordem.
A infraestrutura de pesquisa está localizada em vários datacenters:
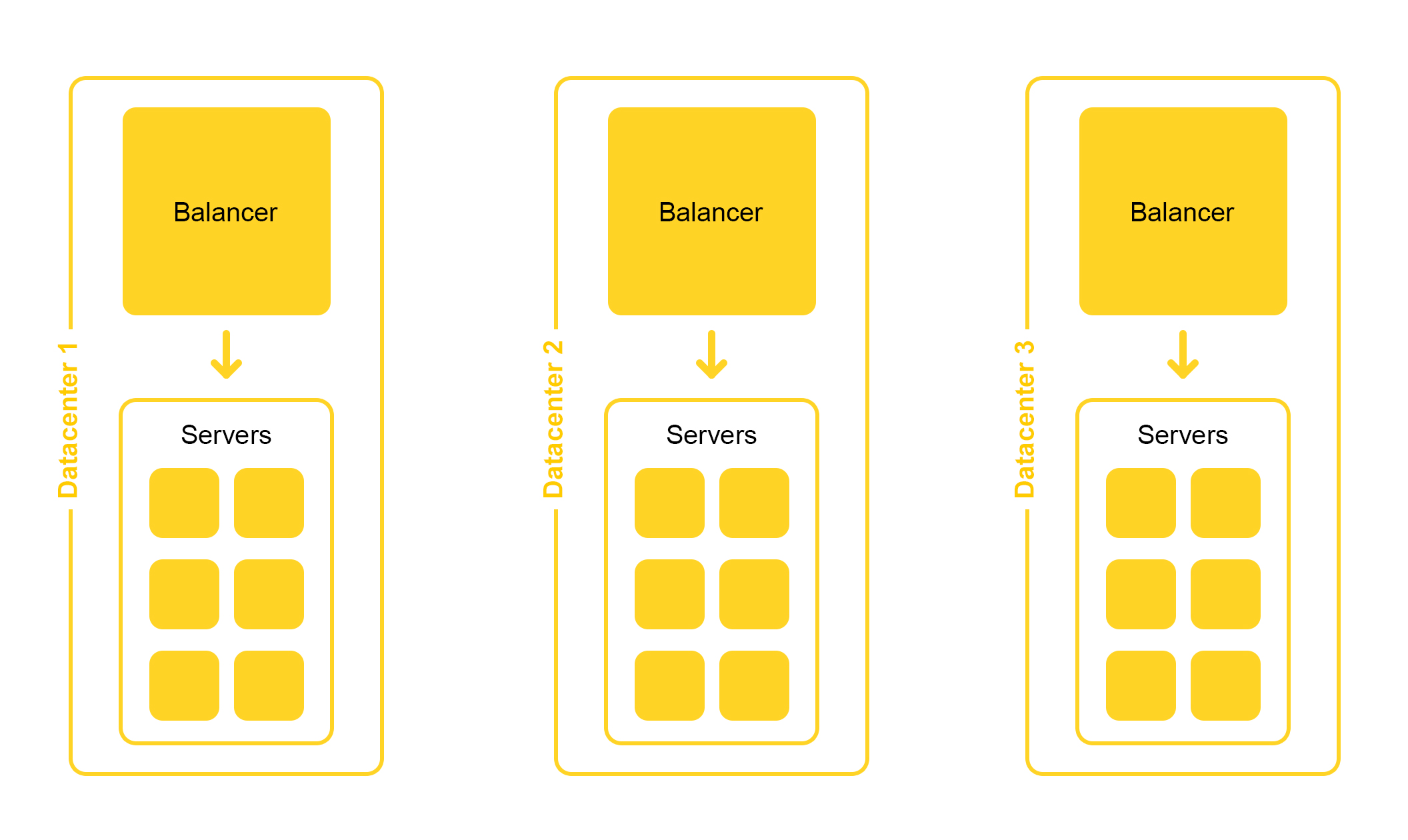
Ao projetar, criamos a possibilidade de desativar um data center. A vida é cheia de surpresas - por exemplo, uma escavadeira pode cortar um cabo subterrâneo (sim, era assim). As capacidades nos demais data centers devem ser suficientes para suportar o pico de carga.
Considere um único data center. Em cada data center, o mesmo esquema de balanceadores:
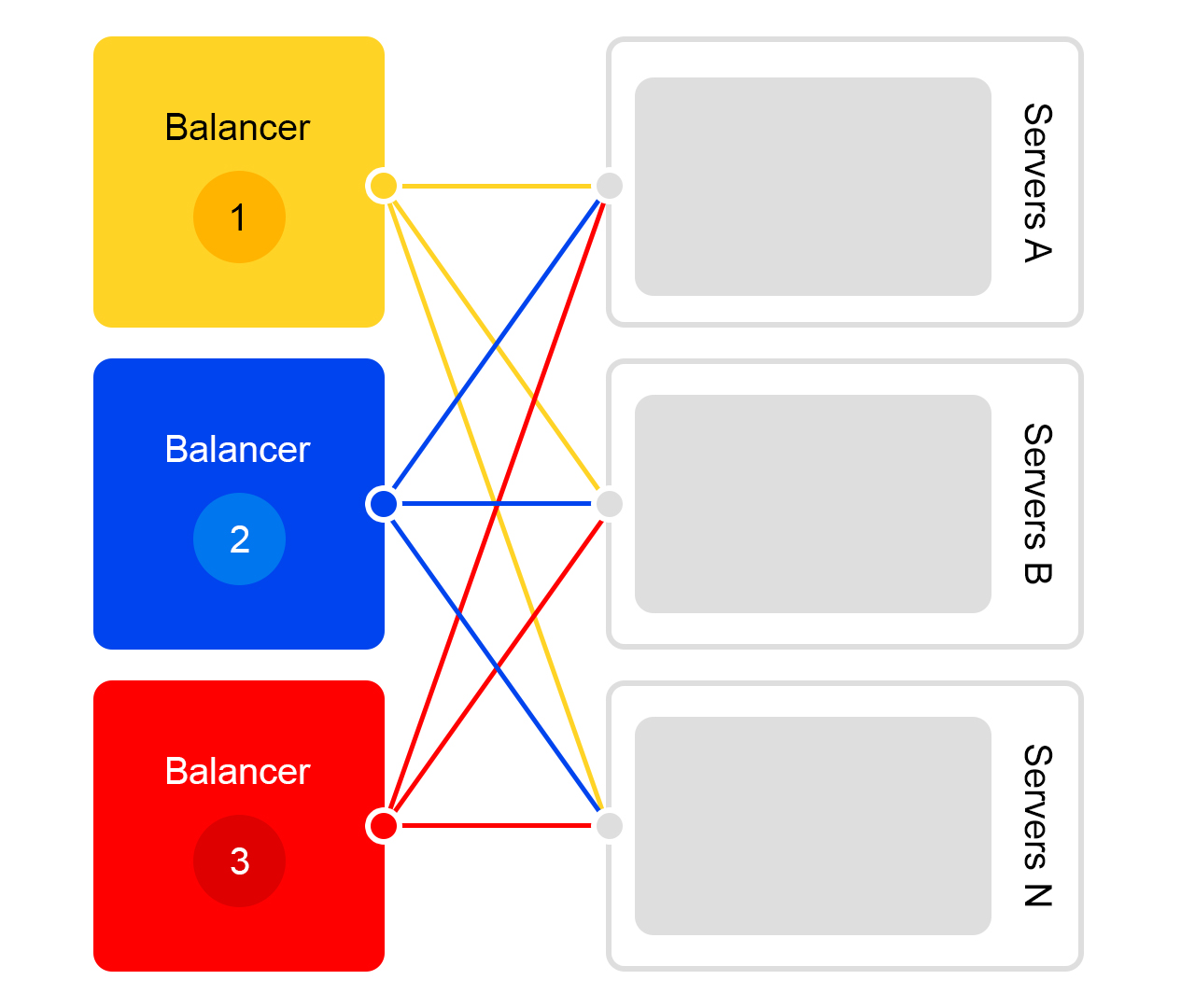
Um balanceador é pelo menos três servidores físicos. Essa redundância é feita para garantir a confiabilidade. Os balanceadores trabalham no HAProx.
Escolhemos o HAProx devido ao seu alto desempenho, pequenos requisitos de recursos e ampla funcionalidade. Dentro de cada servidor, nosso software de pesquisa funciona.
A probabilidade de falha de um servidor é pequena. Mas se você tiver muitos servidores, a probabilidade de pelo menos uma queda aumentar.
É o que acontece na realidade: os servidores estão travando. Portanto, você deve monitorar constantemente o status de todos os servidores. Se o servidor parar de responder, ele será desconectado automaticamente do tráfego. Para isso, o HAProxy possui uma verificação de integridade interna. Ele vai para todos os servidores com solicitação HTTP “/ ping” uma vez por segundo.
Outro recurso do HAProxy: agent-check permite carregar todos os servidores uniformemente. Para fazer isso, o HAProxy se conecta a todos os servidores e eles retornam seu peso, dependendo da carga atual de 1 a 100. O peso é calculado com base no número de solicitações na fila de processamento e na carga do processador.
Agora, sobre encontrar um gato. As consultas do formulário
/ pesquisa? Texto = zangado + gato chegam para
pesquisar . Para que a pesquisa seja rápida, o índice de gatos inteiro deve ser colocado na RAM. Mesmo a leitura de um SSD não é rápida o suficiente.
Era uma vez, a base da oferta era pequena e havia RAM suficiente para um servidor. À medida que o banco de dados da proposta cresceu, tudo deixou de se encaixar nessa RAM e os dados foram divididos em duas partes: shard 1 e shard 2.

Mas sempre acontece: qualquer solução, mesmo uma boa, gera outros problemas.
O balanceador ainda foi para qualquer servidor. Mas na máquina em que a solicitação veio, havia apenas metade do índice. O resto estava em outros servidores. Portanto, o servidor teve que ir para alguma máquina vizinha. Após o recebimento dos dados dos dois servidores, os resultados foram combinados e reorganizados.
Como o balanceador distribui solicitações de maneira uniforme, todos os servidores estavam envolvidos na reorganização, e não apenas na transmissão de dados.
O problema ocorreu se o servidor vizinho não estivesse disponível. A solução foi especificar vários servidores com prioridades diferentes como o servidor "vizinho". Primeiro, a solicitação foi enviada aos servidores no rack atual. Se nenhuma resposta foi recebida, a solicitação foi enviada a todos os servidores neste data center. E por último, mas não menos importante, a solicitação foi para outros data centers.
À medida que o número de propostas aumentou, os dados foram divididos em quatro partes. Mas esse não era o limite.
Agora, uma configuração de oito shards é usada. Além disso, para economizar ainda mais memória, o índice foi dividido na parte da pesquisa (pela qual a pesquisa ocorre) e na parte do trecho (que não está envolvida na pesquisa).
Um servidor contém informações sobre apenas um shard. Portanto, para executar uma pesquisa no índice completo, é necessário pesquisar em oito servidores que contêm shards diferentes.
Os servidores estão agrupados em clusters. Cada cluster contém oito mecanismos de pesquisa e um trecho.
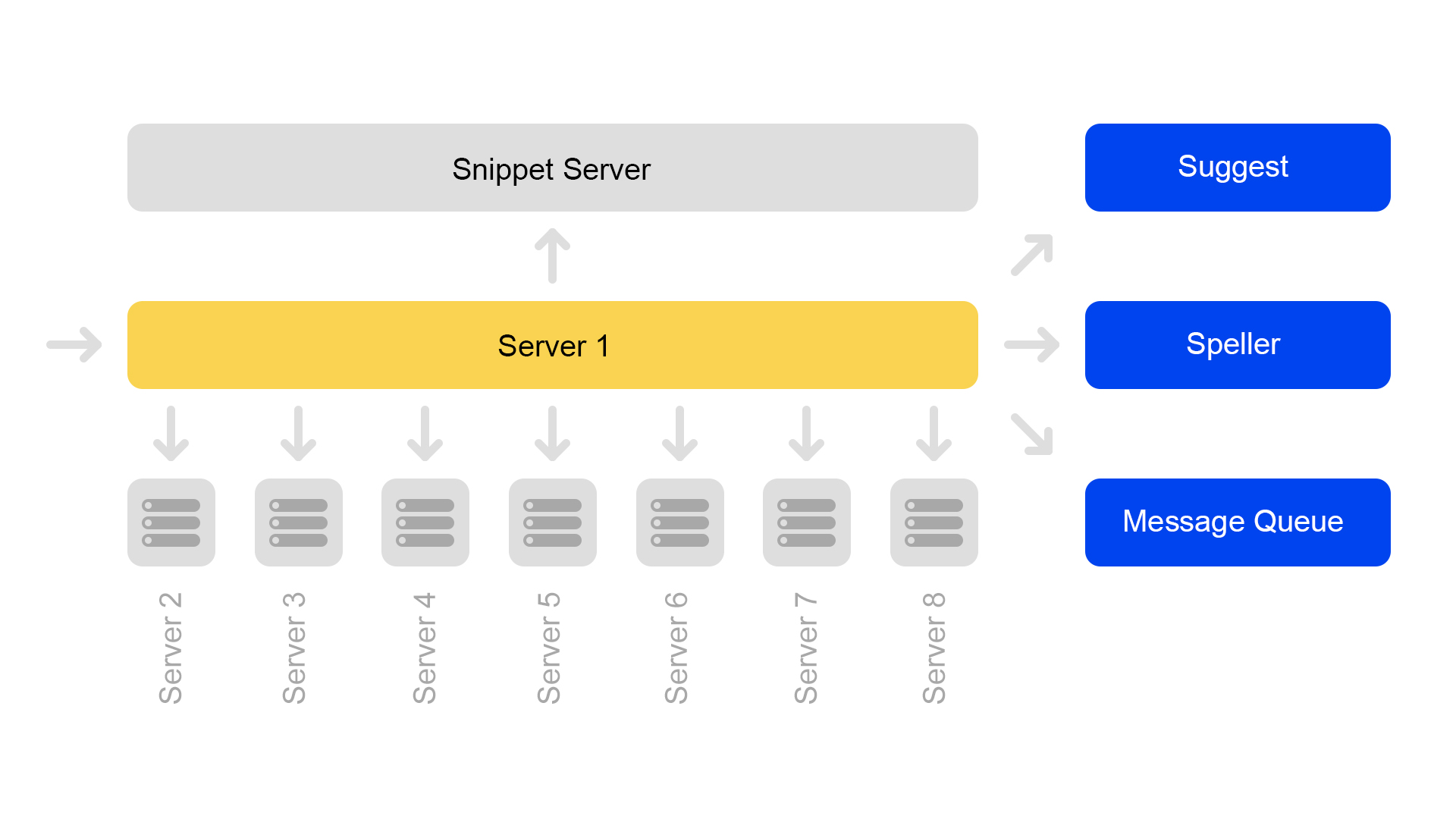
O banco de dados de valores-chave com dados estáticos está em execução no servidor de snippet. Eles são necessários para a emissão de documentos, por exemplo, uma descrição de um gato com um squeaker. Os dados são retirados especialmente em um servidor separado, para não carregar a memória dos mecanismos de pesquisa.
Como os IDs de documento são exclusivos apenas na estrutura de um índice, pode surgir uma situação em que não há documentos nos trechos. Bem, ou em um ID, haverá outro conteúdo. Portanto, para que a pesquisa funcione e a pesquisa ocorra, surgiu a necessidade da consistência de todo o cluster. Falarei sobre como monitoramos a consistência um pouco mais tarde.
A própria pesquisa está organizada da seguinte forma: uma consulta de pesquisa pode chegar a qualquer um dos oito servidores. Digamos que ele veio ao servidor 1. Este servidor processa todos os argumentos e entende o que e como procurar. Dependendo da solicitação recebida, o servidor pode fazer solicitações adicionais a serviços externos para obter as informações necessárias. Uma solicitação pode ser seguida por até dez solicitações para serviços externos.
Após coletar as informações necessárias, uma pesquisa começa no banco de dados de ofertas. Para fazer isso, são feitas subconsultas para todos os oito servidores no cluster.
Depois de receber as respostas, os resultados são combinados. No final, para gerar o problema, você pode precisar de várias outras subconsultas no servidor de snippet.
As consultas de pesquisa no cluster são:
/ shard1? Text = angry + cat . Além disso, subconsultas no formato:
/ status são feitas constantemente entre todos os servidores no cluster uma vez por segundo.
A solicitação
/ status detecta uma situação quando o servidor não está disponível.
Ele também controla que em todos os servidores a versão do mecanismo de pesquisa e a versão do índice são as mesmas, caso contrário, haverá dados inconsistentes dentro do cluster.
Apesar de um servidor de trechos processar solicitações de oito mecanismos de pesquisa, seu processador é muito pouco carregado. Portanto, agora transferimos dados do snippet para um serviço separado.
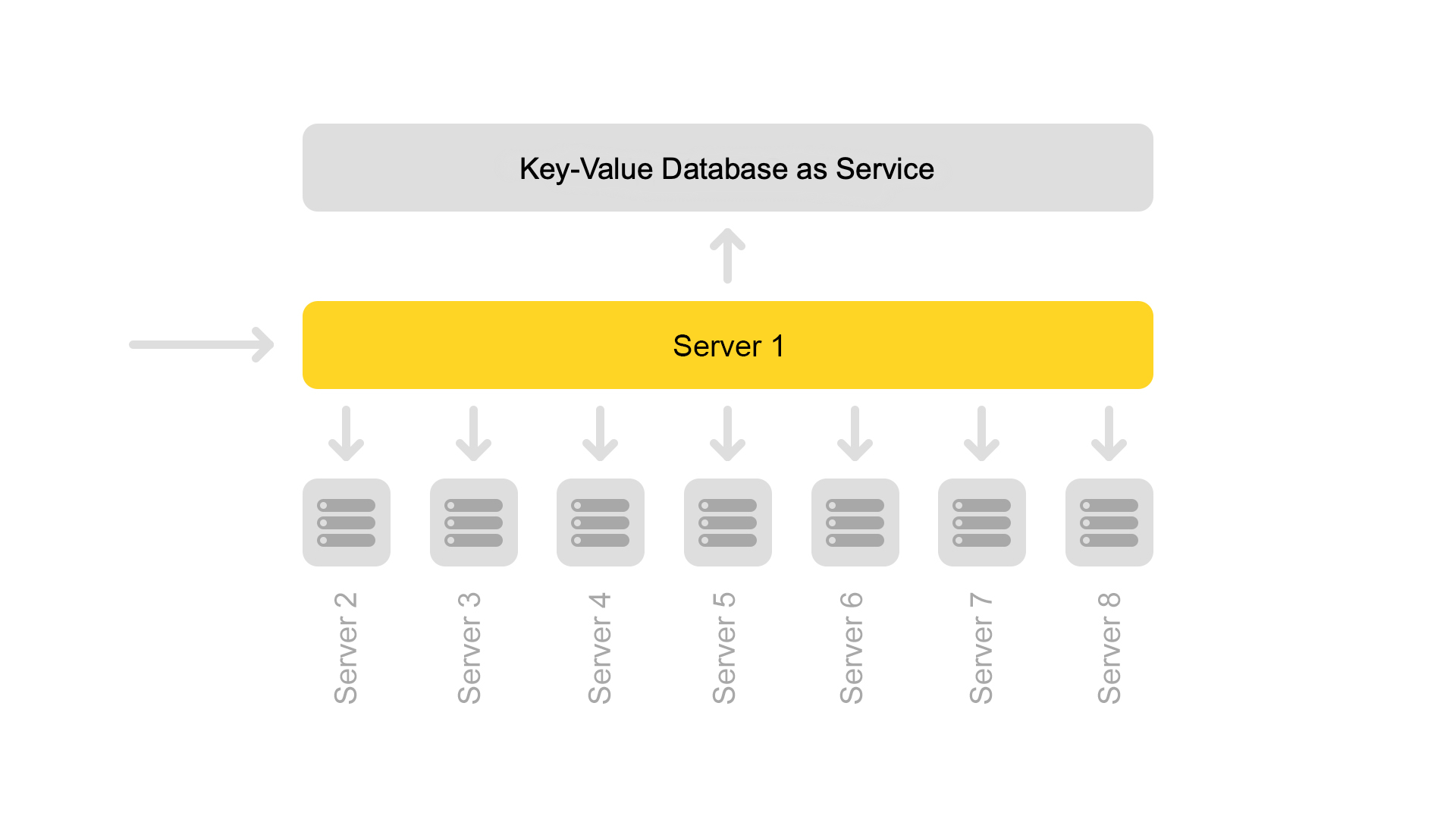
Para transferir dados, introduzimos chaves universais para documentos. Agora a situação é impossível quando uma chave retorna o conteúdo de outro documento.
Mas a transição para outra arquitetura ainda não está completa. Agora queremos nos livrar do servidor de trechos dedicados. E, geralmente, afaste-se da estrutura do cluster. Isso nos permitirá continuar a escalar facilmente. Um bônus adicional é uma economia significativa de ferro.
E agora para as histórias de terror com um final feliz. Considere vários casos de indisponibilidade do servidor.
Terrível aconteceu: um servidor não está disponível
Digamos que um servidor não esteja disponível. Os outros servidores do cluster podem continuar respondendo, mas os resultados da pesquisa estarão incompletos.
Por meio de uma verificação de status, os servidores vizinhos entendem que um está indisponível. Portanto, para manter a integridade, todos os servidores no cluster começam a responder à solicitação
/ ping para o balanceador de que também estão indisponíveis. Acontece que todos os servidores do cluster morreram (o que não é o caso). Essa é a principal desvantagem do nosso esquema de cluster - portanto, queremos nos afastar dele.
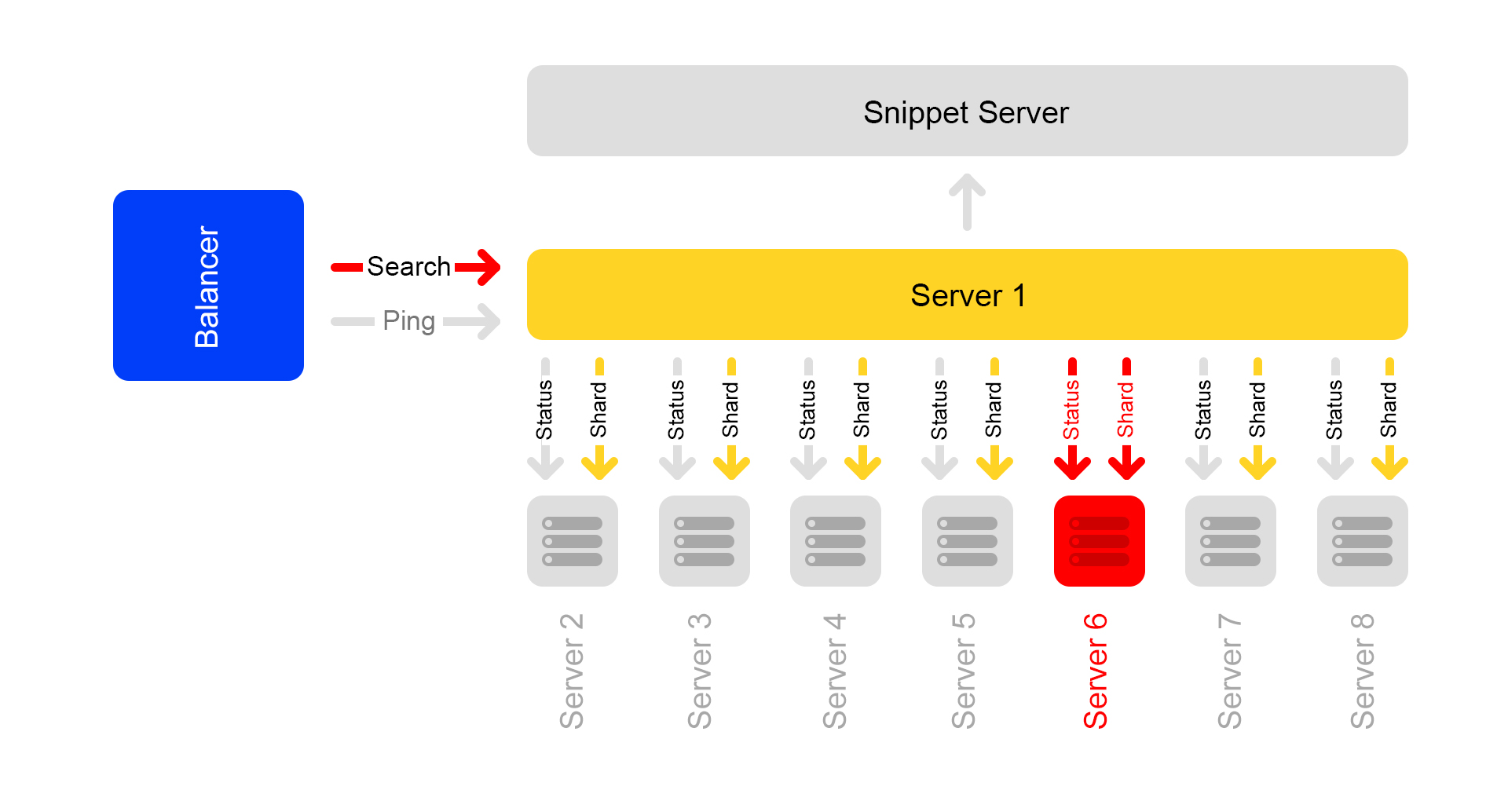
Solicitações que terminaram com um erro, o balanceador pergunta novamente em outros servidores.
Além disso, o balanceador para de enviar tráfego do usuário para servidores mortos, mas continua a verificar seu status.
Quando o servidor fica disponível, ele começa a responder ao
/ ping . Assim que as respostas normais aos pings dos servidores mortos começam a chegar, os balanceadores começam a enviar o tráfego do usuário para lá. O cluster é restaurado, aplausos.
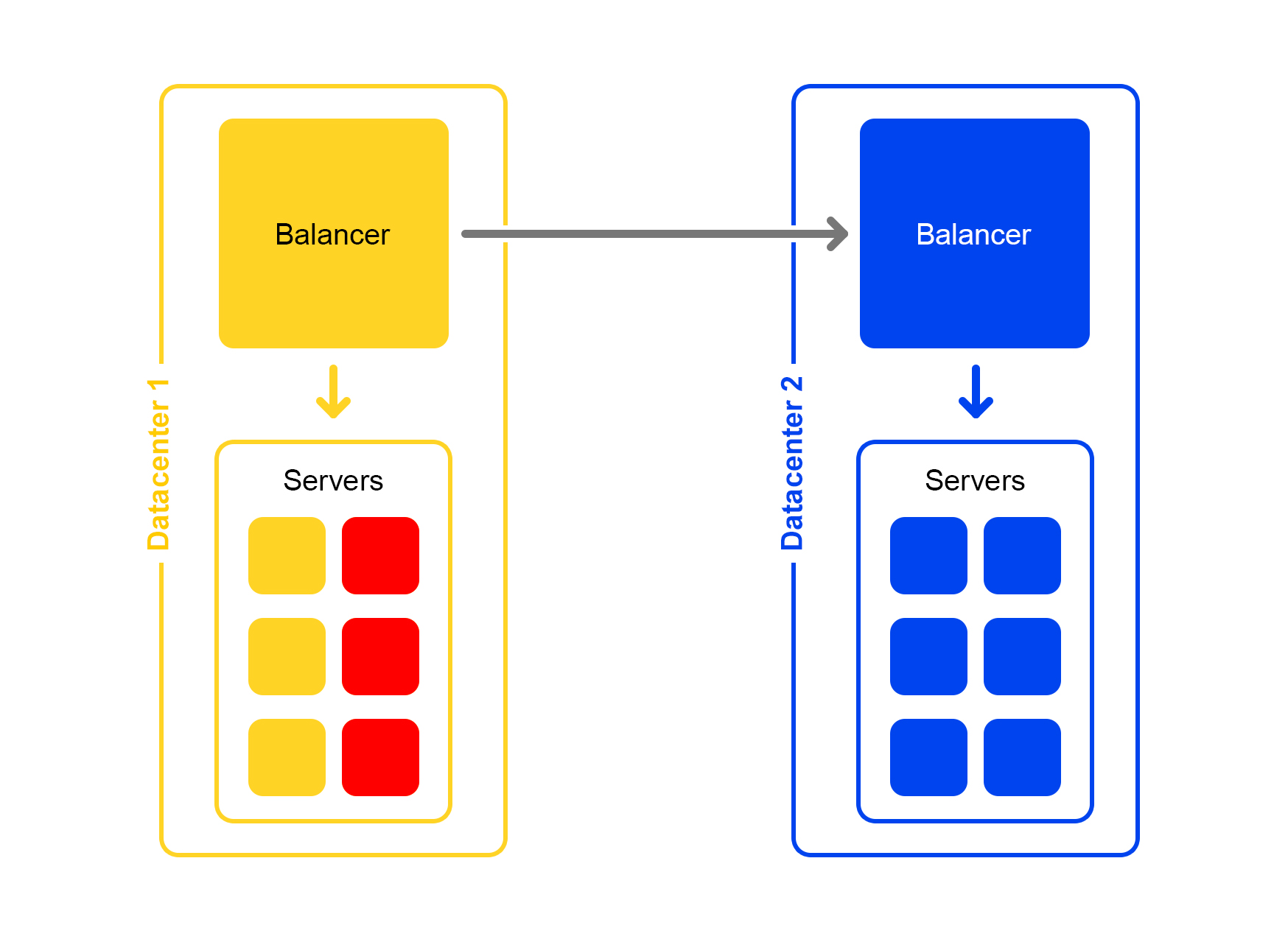
Pior ainda: muitos servidores indisponíveis
Uma parte significativa dos servidores no data center é reduzida. O que fazer, para onde correr? O balanceador vem em socorro novamente. Cada balanceador mantém constantemente na memória o número atual de servidores ativos. Ele sempre considera a quantidade máxima de tráfego que o data center atual pode suportar.
Quando muitos servidores no datacenter caem, o balanceador entende que esse datacenter não pode processar todo o tráfego.
Em seguida, o excesso de tráfego começa distribuído aleatoriamente para outros data centers. Tudo funciona, todo mundo está feliz.
Como fazemos: lançamentos
Agora, sobre como publicamos as alterações feitas no serviço. Aqui seguimos o caminho da racionalização de processos: a implantação de uma nova versão é quase completamente automatizada.
Quando um certo número de alterações é acumulado no projeto, uma nova versão é criada automaticamente e sua montagem é iniciada.
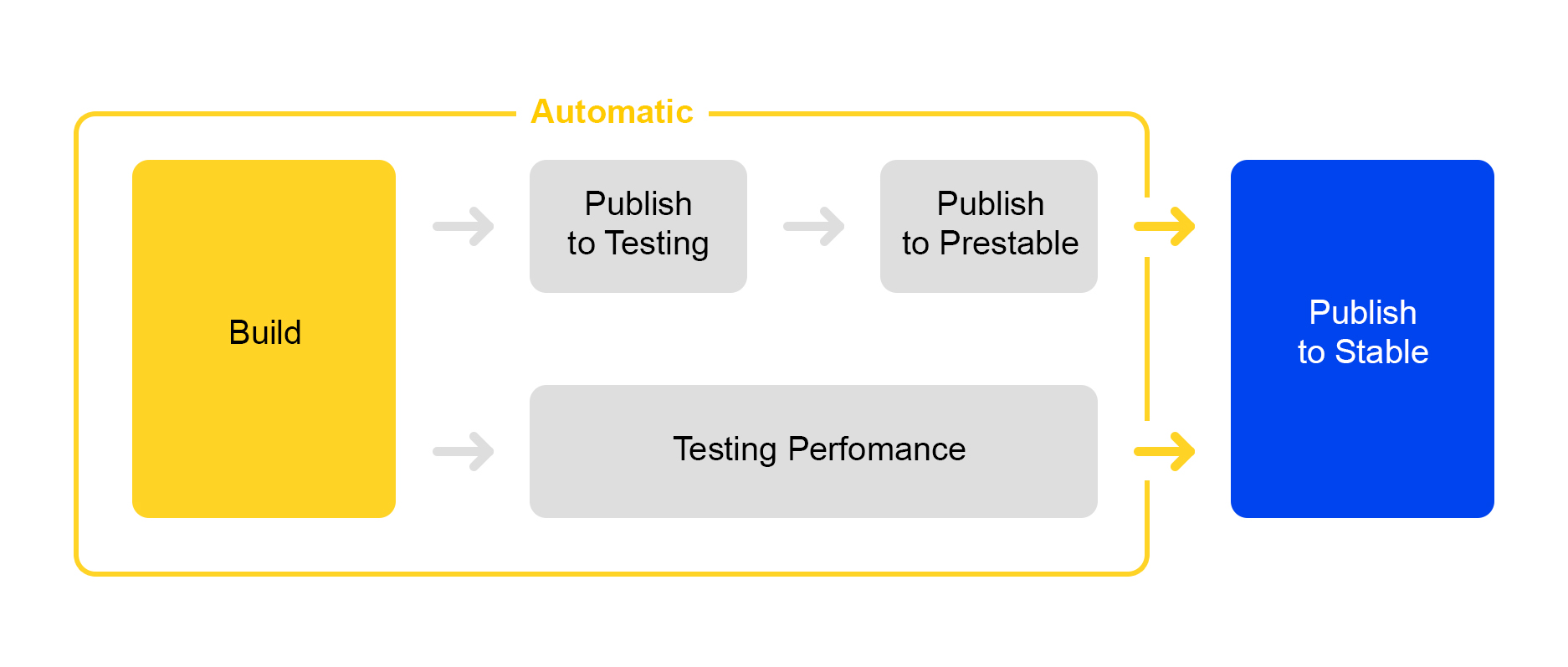
Em seguida, o serviço é implementado para teste, onde a estabilidade é verificada.
Ao mesmo tempo, o teste de desempenho automático é iniciado. Ele está envolvido em um serviço especial. Não vou falar sobre ele agora - sua descrição é digna de um artigo separado.
Se a publicação em teste for bem-sucedida, a publicação da versão no prestable será iniciada automaticamente. Prestable é um cluster especial para o qual o tráfego normal do usuário é direcionado. Se ele retornar um erro, o balanceador fará uma solicitação novamente na produção.
Em prestáveis, os tempos de resposta são medidos e comparados com a liberação anterior na produção. Se tudo estiver bem, a pessoa se conectará: verifica os gráficos e os resultados dos testes de carga e começa a lançar a produção.
Tudo de bom para o usuário: teste A / B
Nem sempre é óbvio se as alterações no serviço trarão benefícios reais. Para medir a utilidade da mudança, as pessoas criaram testes A / B. Falarei um pouco sobre como isso funciona na pesquisa Yandex.Market.
Tudo começa com a adição de um novo parâmetro CGI que inclui novas funcionalidades. Seja nosso parâmetro:
market_new_functionality = 1 . Em seguida, no código, ative esta funcionalidade com o sinalizador:
If (cgi.experiments.market_new_functionality) {
Nova funcionalidade é lançada na produção.
Existe um serviço dedicado para automatizar o teste A / B,
descrito aqui em detalhes. Uma experiência é criada no serviço. A parcela de tráfego é definida, por exemplo, 15%. O interesse é definido não para solicitações, mas para usuários. O horário do experimento, por exemplo, uma semana, também é indicado.
Vários experimentos podem ser iniciados ao mesmo tempo. Nas configurações, você pode especificar se a interseção com outras experiências é possível.
Como resultado, o serviço adiciona automaticamente o argumento
market_new_functionality = 1 a 15% dos usuários. Ele também calcula automaticamente as métricas selecionadas. Após o experimento, os analistas analisam os resultados e tiram conclusões. Com base nas descobertas, é tomada a decisão de lançar em produção ou refinamento.
Mão ágil do mercado: testes de produção
Muitas vezes acontece que é necessário verificar a operação de novas funcionalidades na produção, mas não há certeza de como ela se comportará em condições de "combate" sob carga pesada.
Existe uma solução: os sinalizadores nos parâmetros CGI podem ser usados não apenas para testes A / B, mas também para testar novas funcionalidades.
Criamos uma ferramenta que permite alterar instantaneamente a configuração em milhares de servidores sem expor o serviço a riscos. É chamado "Stop Crane". A ideia original era a capacidade de desativar rapidamente algumas funcionalidades sem layout. Então a ferramenta se expandiu e se tornou mais complexa.
O esquema do serviço é apresentado abaixo:
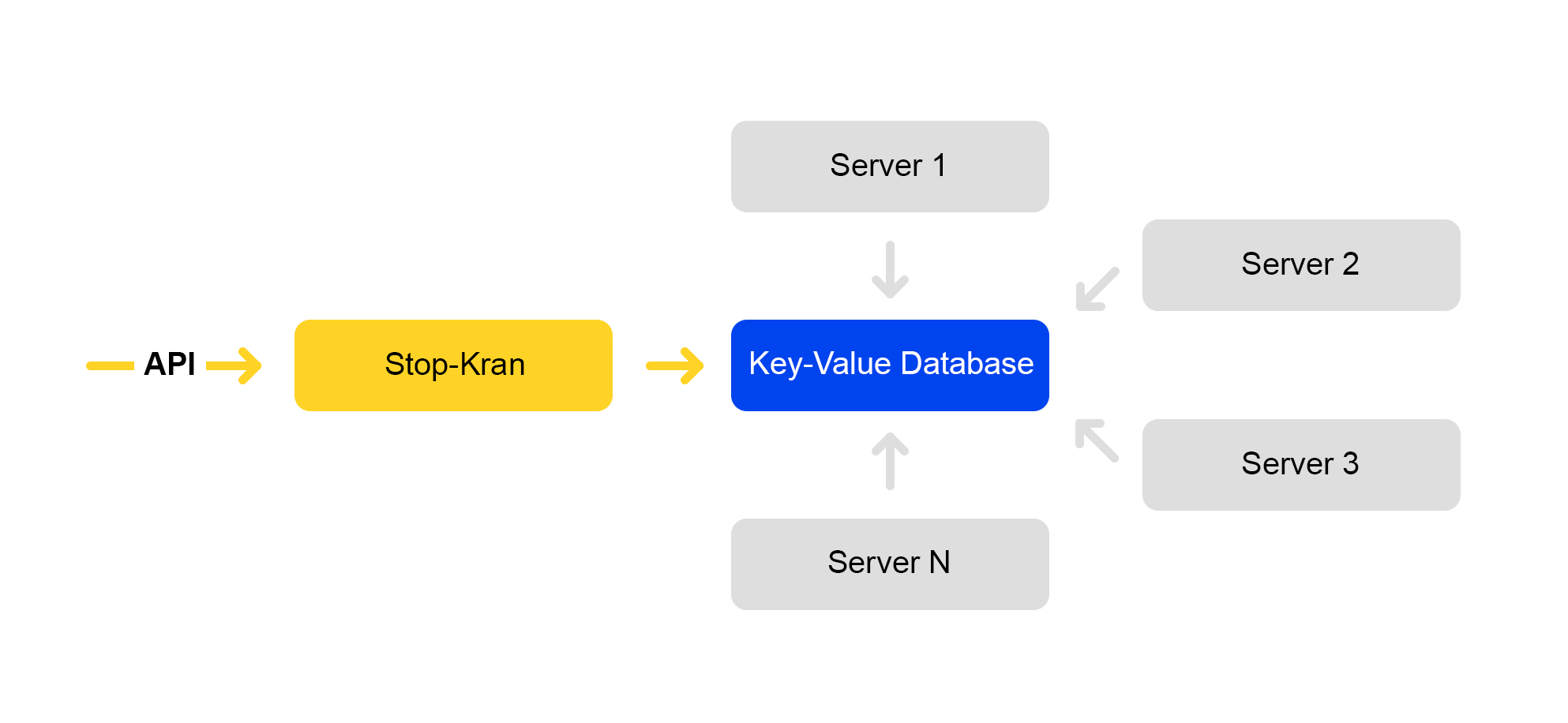
A API define valores de sinalizador. O serviço de gerenciamento armazena esses valores em um banco de dados. Todos os servidores acessam o banco de dados uma vez a cada dez segundos, distribuem os valores dos sinalizadores e aplicam esses valores a cada solicitação.
No Stop Crane, você pode definir dois tipos de valores:
1) Expressões condicionais. Aplique quando um dos valores for executado. Por exemplo:
{ "condition":"IS_DC1", "value":"3", }, { "condition": "CLUSTER==2 and IS_BERU", "value": "4!" }
O valor "3" será aplicado quando a solicitação for processada no local DC1. E o valor é "4" quando a solicitação é processada no segundo cluster para o site beru.ru.
2) valores incondicionais. Eles são usados por padrão se nenhuma das condições for atendida. Por exemplo:
valor, valor!Se o valor terminar com um ponto de exclamação, ele recebe uma prioridade mais alta.
O analisador dos parâmetros CGI analisa a URL. Em seguida, aplica os valores do toque de parada.
Aplicam-se valores com as seguintes prioridades:
- Maior prioridade do toque de parada (ponto de exclamação).
- O valor da consulta.
- O valor padrão é do toque de parada.
- O valor padrão no código.
Existem muitos sinalizadores indicados em valores condicionais - eles são suficientes para todos os cenários conhecidos por nós:
- Data center.
- Ambiente: produção, teste, sombra.
- Local: mercado, beru.
- Número do cluster.
Com essa ferramenta, você pode ativar a nova funcionalidade em um grupo de servidores (por exemplo, apenas em um datacenter) e testar a funcionalidade dessa funcionalidade sem nenhum risco específico para todo o serviço. Mesmo se você cometeu um erro sério em algum lugar, tudo começou a cair e o data center inteiro caiu, os balanceadores redirecionarão as solicitações para outro data center. Os usuários finais não notarão nada.
Se você perceber um problema, poderá retornar imediatamente o valor anterior do sinalizador e as alterações serão revertidas.
Este serviço tem suas desvantagens: os desenvolvedores adoram muito e muitas vezes tentam incluir todas as alterações no Stop Crane. Estamos tentando combater o uso indevido.
A abordagem Stop Crane funciona bem quando você já possui um código estável, pronto para ser lançado na produção. Ao mesmo tempo, você ainda tem dúvidas e deseja verificar o código em condições de "combate".
No entanto, a torneira não é adequada para testes durante o desenvolvimento. Para os desenvolvedores, existe um cluster separado chamado "cluster de sombra".
Teste Encoberto: Cluster de Sombra
As solicitações de um dos clusters são duplicadas no cluster de sombra. Mas o balanceador ignora completamente as respostas desse cluster. O esquema de seu trabalho é apresentado abaixo.
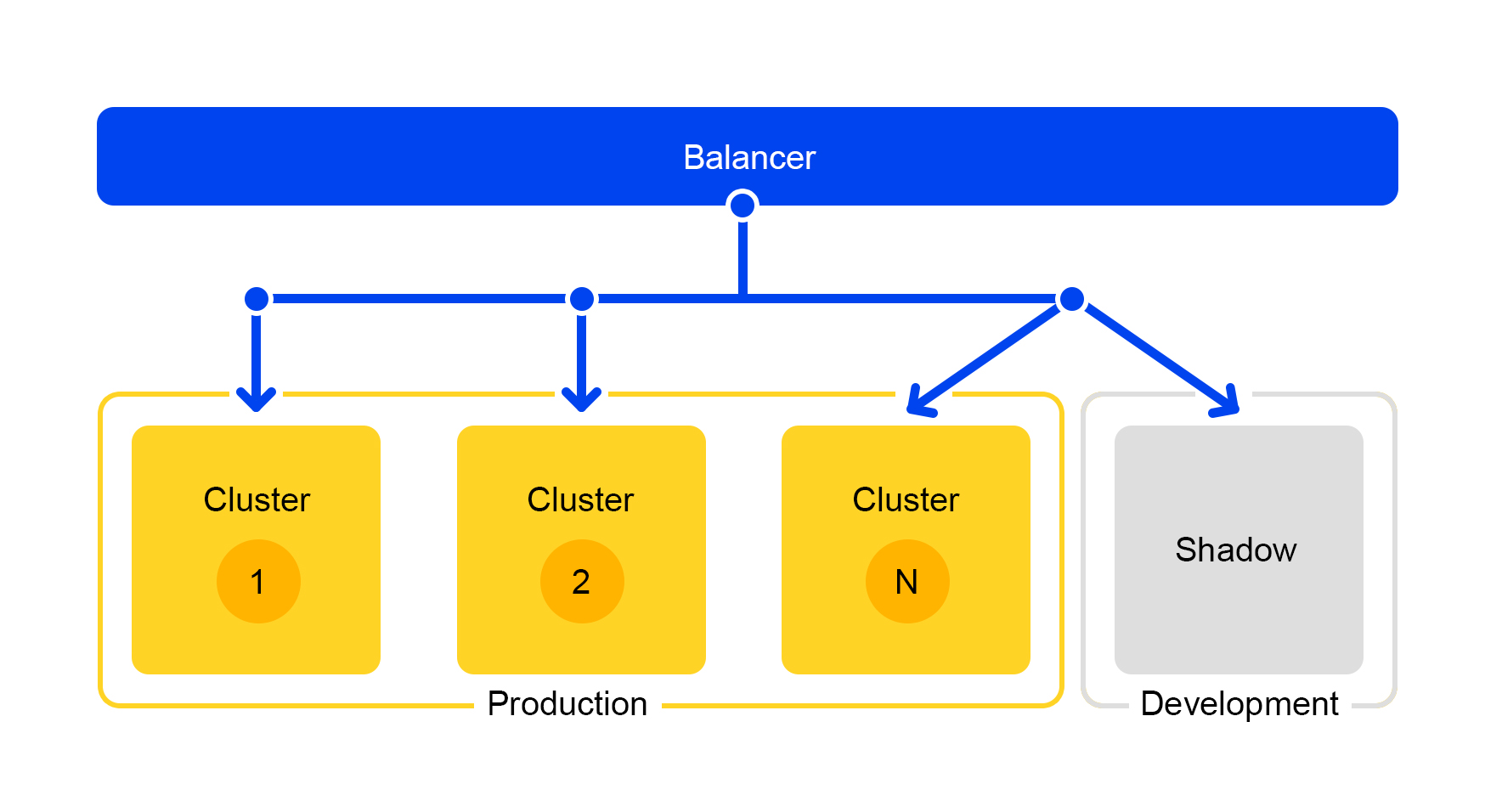
Temos um cluster de teste que está em condições reais de "combate". O tráfego normal de usuários voa para lá. O hardware nos dois clusters é o mesmo, para que você possa comparar desempenho e erros.
E como o balanceador ignora completamente as respostas, os usuários finais não verão as respostas do cluster de sombra. Portanto, não é assustador cometer um erro.
Conclusões
Então, como criamos uma pesquisa de mercado?
Para que tudo corra bem, separamos a funcionalidade em serviços separados. Portanto, você pode dimensionar apenas os componentes que precisamos e simplificá-los. É fácil fornecer um componente separado para outra equipe e compartilhar responsabilidades por trabalhar nele. E uma economia significativa de ferro com essa abordagem é uma vantagem óbvia.
O cluster de sombra também nos ajuda: você pode desenvolver serviços, testá-los no processo e, ao mesmo tempo, não incomodar o usuário.
Bem, e verifique a produção, é claro. Precisa alterar a configuração em mil servidores? Fácil, use um guindaste de parada. Assim, você pode implantar imediatamente uma solução complexa pronta e reverter para uma versão estável, se surgirem problemas.
Espero ter conseguido mostrar como tornamos o mercado rápido e estável com uma base cada vez maior de ofertas. Como resolver problemas do servidor, lidar com um grande número de solicitações, melhorar a flexibilidade do serviço e fazer isso sem interromper os processos de trabalho.