
1. Introdução
O reator de E / S ( loop de evento single-threaded) é um padrão para escrever software altamente carregado usado em muitas soluções populares:
Neste artigo, consideraremos os detalhes do reator de E / S e o princípio de sua operação, escreveremos uma implementação para menos de 200 linhas de código e forçaremos um servidor HTTP simples a processar mais de 40 milhões de solicitações / min.
Prefácio
- O artigo foi escrito com o objetivo de ajudar a entender o funcionamento do reator de E / S e, portanto, perceber os riscos ao usá-lo.
- Para dominar o artigo, você precisa conhecer o básico da linguagem C e ter pouca experiência no desenvolvimento de aplicativos de rede.
- Todo o código é escrito em C estritamente de acordo com (com cuidado: PDF longo ) o padrão C11 para Linux e está disponível no GitHub .
Por que isso é necessário?
Com a crescente popularidade da Internet, os servidores da web precisavam processar um grande número de conexões ao mesmo tempo e, portanto, foram tentadas duas abordagens: bloquear a E / S em um grande número de threads do sistema operacional e a E / S não-bloqueadora em combinação com um sistema de notificação de eventos, também chamado de "sistema seletor "( epoll / kqueue / IOCP / etc).
A primeira abordagem envolveu a criação de um novo encadeamento do SO para cada conexão de entrada. Sua desvantagem é a baixa escalabilidade: o sistema operacional precisará fazer muitas transições de contexto e chamadas de sistema . São operações caras e podem levar à falta de RAM livre com um número impressionante de conexões.
A versão modificada aloca um número fixo de encadeamentos (conjunto de encadeamentos), impedindo o sistema de interromper anormalmente a execução, mas ao mesmo tempo apresenta um novo problema: se no momento determinado o conjunto de encadeamentos for bloqueado por operações de leitura longas, outros soquetes que já poderão receber dados não será capaz de fazer isso.
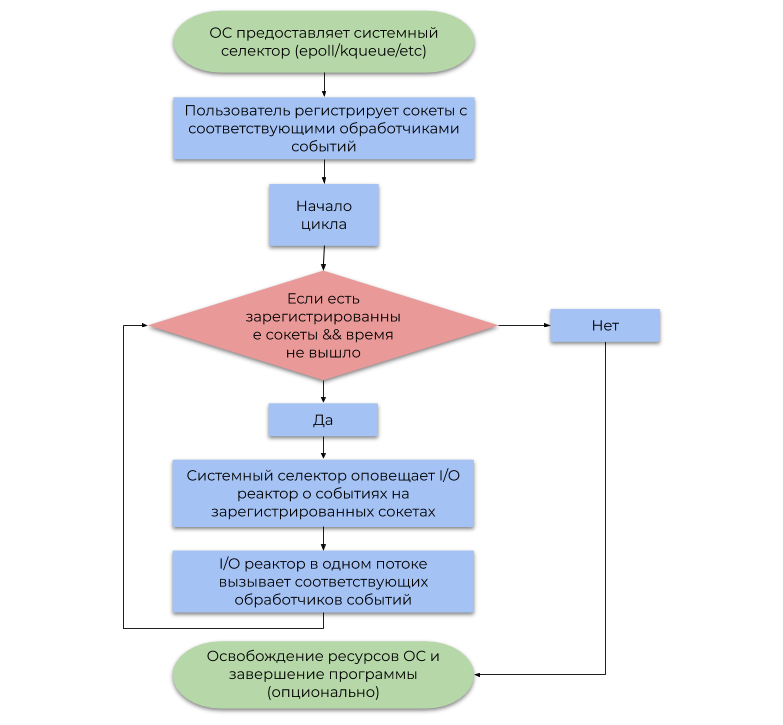
A segunda abordagem usa o sistema de notificação de eventos (seletor de sistema) fornecido pelo sistema operacional. Este artigo discute o tipo mais comum de seletor de sistema com base em alertas (eventos, notificações) sobre a prontidão para operações de E / S, em vez de alertas sobre sua conclusão . Um exemplo simplificado de seu uso pode ser representado pelo seguinte fluxograma:

A diferença entre essas abordagens é a seguinte:
- As operações de bloqueio de E / S suspendem o fluxo do usuário até o sistema operacional desfragmentar adequadamente os pacotes IP recebidos no fluxo de bytes ( TCP , recebendo dados) ou liberando espaço suficiente nos buffers de gravação internos para envio subsequente via NIC (envio de dados).
- Depois de um tempo, o seletor de sistema notifica o programa que o sistema operacional já desfragmentou pacotes IP (TCP, recebendo dados) ou que espaço suficiente nos buffers internos de gravação já está disponível (enviando dados).
Resumindo, reservar o encadeamento do SO para cada E / S é um desperdício de poder de computação, porque, na realidade, os encadeamentos não estão ocupados com trabalho útil (o termo "interrupção do software" tem suas raízes). O seletor de sistema resolve esse problema, permitindo que o programa do usuário consuma recursos da CPU muito mais economicamente.
Modelo de E / S do reator
Um reator de E / S atua como uma camada entre o seletor do sistema e o código do usuário. O princípio de sua operação é descrito pelo seguinte fluxograma:
- Deixe-me lembrá-lo de que um evento é uma notificação de que um determinado soquete é capaz de executar uma operação de E / S sem bloqueio.
- Um manipulador de eventos é uma função chamada pelo reator de E / S quando um evento é recebido, que executa uma operação de E / S sem bloqueio.
É importante observar que, por definição, o reator de E / S é de rosca única, mas nada impede o uso do conceito em um ambiente de rosca múltipla em relação a 1 reator stream: 1, utilizando assim todos os núcleos da CPU.
Implementação
Colocamos a interface pública no arquivo reactor.h e a implementação em reactor.c . reactor.h consistirá nas seguintes declarações:
Mostrar anúncios em reactor.h typedef struct reactor Reactor; typedef void (*Callback)(void *arg, int fd, uint32_t events); Reactor *reactor_new(void); int reactor_destroy(Reactor *reactor); int reactor_register(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg); int reactor_deregister(const Reactor *reactor, int fd); int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg); int reactor_run(const Reactor *reactor, time_t timeout);
A estrutura de E / S do reator consiste em um descritor de arquivo seletor de epoll e uma tabela de hash GHashTable , que cada soquete mapeia para CallbackData (uma estrutura de um manipulador de eventos e um argumento do usuário).
Mostrar reator e retorno de chamada struct reactor { int epoll_fd; GHashTable *table;
Observe que usamos a capacidade de manipular um tipo incompleto por ponteiro. Em reactor.h declaramos a estrutura do reactor e em reactor.c definimos-o, impedindo assim o usuário de alterar explicitamente seus campos. Esse é um dos padrões de ocultação de dados que se encaixa organicamente na semântica de C.
As reactor_register , reactor_deregister e reactor_reregister atualizam a lista de soquetes de interesse e os manipuladores de eventos correspondentes no seletor de sistema e na tabela de hash.
Mostrar recursos de registro #define REACTOR_CTL(reactor, op, fd, interest) \ if (epoll_ctl(reactor->epoll_fd, op, fd, \ &(struct epoll_event){.events = interest, \ .data = {.fd = fd}}) == -1) { \ perror("epoll_ctl"); \ return -1; \ } int reactor_register(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg) { REACTOR_CTL(reactor, EPOLL_CTL_ADD, fd, interest) g_hash_table_insert(reactor->table, int_in_heap(fd), callback_data_new(callback, callback_arg)); return 0; } int reactor_deregister(const Reactor *reactor, int fd) { REACTOR_CTL(reactor, EPOLL_CTL_DEL, fd, 0) g_hash_table_remove(reactor->table, &fd); return 0; } int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest, Callback callback, void *callback_arg) { REACTOR_CTL(reactor, EPOLL_CTL_MOD, fd, interest) g_hash_table_insert(reactor->table, int_in_heap(fd), callback_data_new(callback, callback_arg)); return 0; }
Depois que o reator de E / S interceptou o evento com o descritor fd , ele chama o manipulador de eventos correspondente, no qual passa fd , a máscara de bit dos eventos gerados e o ponteiro do usuário para void .
Mostrar a função reactor_run () int reactor_run(const Reactor *reactor, time_t timeout) { int result; struct epoll_event *events; if ((events = calloc(MAX_EVENTS, sizeof(*events))) == NULL) abort(); time_t start = time(NULL); while (true) { time_t passed = time(NULL) - start; int nfds = epoll_wait(reactor->epoll_fd, events, MAX_EVENTS, timeout - passed); switch (nfds) {
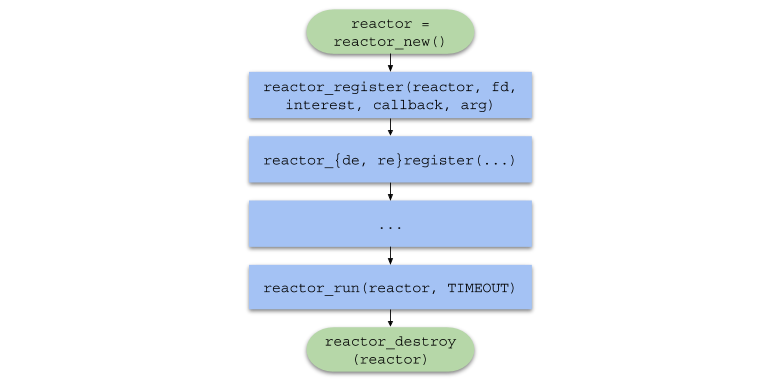
Para resumir, a cadeia de chamadas de função no código do usuário terá o seguinte formato:
Servidor de thread único
Para testar o reator de E / S sob alta carga, escreveremos um servidor Web HTTP simples para responder a qualquer solicitação com uma imagem.
Referência Rápida do Protocolo HTTPO HTTP é um protocolo no nível do aplicativo usado principalmente para a interação do servidor com um navegador.
O HTTP pode ser facilmente usado no topo do protocolo de transporte TCP , enviando e recebendo mensagens do formato definido pela especificação .
<> <URI> < HTTP>CRLF < 1>CRLF < 2>CRLF < N>CRLF CRLF <>
CRLF é uma sequência de dois caracteres: \r \n , separando a primeira linha de consulta, cabeçalhos e dados.<> é um dos CONNECT , DELETE , GET , HEAD , OPTIONS , PATCH , POST , PUT , TRACE . O navegador enviará um comando GET ao nosso servidor, significando "Envie-me o conteúdo do arquivo".<URI> é o identificador de recurso unificado . Por exemplo, se URI = /index.html , o cliente solicita a página principal do site.< HTTP> - versão do protocolo HTTP/XY no formato HTTP/XY . A versão mais usada até o momento é HTTP/1.1 .< N> é um par de valores-chave no formato <>: <> , enviado ao servidor para análise posterior.<> - dados exigidos pelo servidor para concluir a operação. Muitas vezes, é apenas JSON ou qualquer outro formato.
< HTTP> < > < >CRLF < 1>CRLF < 2>CRLF < N>CRLF CRLF <>
< > é um número que representa o resultado de uma operação. Nosso servidor sempre retornará o status 200 (operação bem-sucedida).< > - representação de sequência do código de status. Para o código de status 200, isso está OK .< N> - um cabeçalho do mesmo formato da solicitação. Retornaremos os cabeçalhos Content-Length (tamanho do arquivo) e Content-Type: text/html (return type data).<> - dados solicitados pelo usuário. No nosso caso, este é o caminho para a imagem em HTML .
O http_server.c (servidor de thread único) inclui o arquivo common.h , que contém os seguintes protótipos de função:
Mostrar protótipos de função em common.h static void on_accept(void *arg, int fd, uint32_t events); static void on_send(void *arg, int fd, uint32_t events); static void on_recv(void *arg, int fd, uint32_t events); static void set_nonblocking(int fd); static noreturn void fail(const char *format, ...); static int new_server(bool reuse_port);
A macro de função SAFE_CALL() também SAFE_CALL() descrita e a função fail() é definida. A macro compara o valor da expressão com o erro e, se a condição for atendida, chamará a função fail() :
#define SAFE_CALL(call, error) \ do { \ if ((call) == error) { \ fail("%s", #call); \ } \ } while (false)
A função fail() imprime os argumentos passados no terminal (como printf() ) e finaliza o programa com o código EXIT_FAILURE :
static noreturn void fail(const char *format, ...) { va_list args; va_start(args, format); vfprintf(stderr, format, args); va_end(args); fprintf(stderr, ": %s\n", strerror(errno)); exit(EXIT_FAILURE); }
A função new_server() retorna o descritor de arquivo do soquete "server" criado pelo sistema chama socket() , bind() e listen() e é capaz de aceitar conexões de entrada no modo sem bloqueio.
Mostrar função new_server () static int new_server(bool reuse_port) { int fd; SAFE_CALL((fd = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, IPPROTO_TCP)), -1); if (reuse_port) { SAFE_CALL( setsockopt(fd, SOL_SOCKET, SO_REUSEPORT, &(int){1}, sizeof(int)), -1); } struct sockaddr_in addr = {.sin_family = AF_INET, .sin_port = htons(SERVER_PORT), .sin_addr = {.s_addr = inet_addr(SERVER_IPV4)}, .sin_zero = {0}}; SAFE_CALL(bind(fd, (struct sockaddr *)&addr, sizeof(addr)), -1); SAFE_CALL(listen(fd, SERVER_BACKLOG), -1); return fd; }
- Observe que o soquete é criado inicialmente no modo sem bloqueio usando o sinalizador
SOCK_NONBLOCK , para que na função on_accept() (para ler mais), a chamada do sistema accept() não interrompa a execução do fluxo. - Se
reuse_port for true , essa função configurará o soquete com a opção SO_REUSEPORT usando setsockopt() para usar a mesma porta em um ambiente com vários threads (consulte a seção "Servidor com vários threads").
O manipulador de eventos on_accept() é chamado após o SO gerar um evento EPOLLIN , neste caso, significando que uma nova conexão pode ser aceita. on_accept() aceita uma nova conexão, a alterna para o modo sem bloqueio e registra-se no manipulador de eventos on_recv() no reator de E / S.
Mostrar a função on_accept () static void on_accept(void *arg, int fd, uint32_t events) { int incoming_conn; SAFE_CALL((incoming_conn = accept(fd, NULL, NULL)), -1); set_nonblocking(incoming_conn); SAFE_CALL(reactor_register(reactor, incoming_conn, EPOLLIN, on_recv, request_buffer_new()), -1); }
O manipulador de eventos on_recv() é chamado depois que o SO gera um evento EPOLLIN , nesse caso, o que significa que a conexão registrada on_accept() está pronta para receber dados.
on_recv() lê os dados da conexão até que a solicitação HTTP completa seja recebida e registra o manipulador on_send() para enviar a resposta HTTP. Se o cliente for desconectado, o soquete será cancelado o registro e será fechado com close() .
Mostrar a função on_recv () static void on_recv(void *arg, int fd, uint32_t events) { RequestBuffer *buffer = arg;
O manipulador de eventos on_send() é chamado depois que o SO gera um evento EPOLLOUT , o que significa que a conexão registrada por on_recv() está pronta para enviar dados. Essa função envia uma resposta HTTP contendo HTML com a imagem ao cliente e altera o manipulador de eventos para on_recv() novamente.
Mostrar a função on_send () static void on_send(void *arg, int fd, uint32_t events) { const char *content = "<img " "src=\"https://habrastorage.org/webt/oh/wl/23/" "ohwl23va3b-dioerobq_mbx4xaw.jpeg\">"; char response[1024]; sprintf(response, "HTTP/1.1 200 OK" CRLF "Content-Length: %zd" CRLF "Content-Type: " "text/html" DOUBLE_CRLF "%s", strlen(content), content); SAFE_CALL(send(fd, response, strlen(response), 0), -1); SAFE_CALL(reactor_reregister(reactor, fd, EPOLLIN, on_recv, arg), -1); }
E, finalmente, no arquivo http_server.c , na função main() , criamos um reator de E / S usando reactor_new() , criamos um soquete de servidor e o registramos, iniciamos o reator usando reactor_run() exatamente um minuto e depois liberamos os recursos e saímos do programa.
Mostrar http_server.c #include "reactor.h" static Reactor *reactor; #include "common.h" int main(void) { SAFE_CALL((reactor = reactor_new()), NULL); SAFE_CALL( reactor_register(reactor, new_server(false), EPOLLIN, on_accept, NULL), -1); SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1); SAFE_CALL(reactor_destroy(reactor), -1); }
Verifique se tudo funciona conforme o esperado. chmod a+x compile.sh && ./compile.sh ( chmod a+x compile.sh && ./compile.sh na raiz do projeto) e iniciamos o servidor auto-escrito, abra http://127.0.0.1:18470 no navegador e observamos o que era esperado:
Medição de desempenho
Mostrar as características do meu carro $ screenfetch MMMMMMMMMMMMMMMMMMMMMMMMMmds+. OS: Mint 19.1 tessa MMm----::-://////////////oymNMd+` Kernel: x86_64 Linux 4.15.0-20-generic MMd /++ -sNMd: Uptime: 2h 34m MMNso/` dMM `.::-. .-::.` .hMN: Packages: 2217 ddddMMh dMM :hNMNMNhNMNMNh: `NMm Shell: bash 4.4.20 NMm dMM .NMN/-+MMM+-/NMN` dMM Resolution: 1920x1080 NMm dMM -MMm `MMM dMM. dMM DE: Cinnamon 4.0.10 NMm dMM -MMm `MMM dMM. dMM WM: Muffin NMm dMM .mmd `mmm yMM. dMM WM Theme: Mint-Y-Dark (Mint-Y) NMm dMM` ..` ... ydm. dMM GTK Theme: Mint-Y [GTK2/3] hMM- +MMd/-------...-:sdds dMM Icon Theme: Mint-Y -NMm- :hNMNNNmdddddddddy/` dMM Font: Noto Sans 9 -dMNs-``-::::-------.`` dMM CPU: Intel Core i7-6700 @ 8x 4GHz [52.0°C] `/dMNmy+/:-------------:/yMMM GPU: NV136 ./ydNMMMMMMMMMMMMMMMMMMMMM RAM: 2544MiB / 7926MiB \.MMMMMMMMMMMMMMMMMMM
Medimos o desempenho de um servidor de thread único. Vamos abrir dois terminais: em um, ./http_server , no outro - wrk . Após um minuto, as seguintes estatísticas serão exibidas no segundo terminal:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 493.52us 76.70us 17.31ms 89.57% Req/Sec 24.37k 1.81k 29.34k 68.13% 11657769 requests in 1.00m, 1.60GB read Requests/sec: 193974.70 Transfer/sec: 27.19MB
Nosso servidor de thread único foi capaz de processar mais de 11 milhões de solicitações por minuto, originando 100 conexões. Não é um resultado ruim, mas pode ser melhorado?
Servidor multithread
Como mencionado acima, um reator de E / S pode ser criado em fluxos separados, utilizando assim todos os núcleos da CPU. Vamos aplicar esta abordagem na prática:
Mostrar http_server_multithreaded.c #include "reactor.h" static Reactor *reactor; #pragma omp threadprivate(reactor) #include "common.h" int main(void) { #pragma omp parallel { SAFE_CALL((reactor = reactor_new()), NULL); SAFE_CALL(reactor_register(reactor, new_server(true), EPOLLIN, on_accept, NULL), -1); SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1); SAFE_CALL(reactor_destroy(reactor), -1); } }
Agora, cada thread possui seu próprio reator:
static Reactor *reactor; #pragma omp threadprivate(reactor)
Observe que o argumento para new_server() é true . Isso significa que estamos configurando o soquete do servidor para a opção SO_REUSEPORT para usá-lo em um ambiente multithread. Você pode ler mais aqui .
Segunda execução
Agora, mediremos o desempenho de um servidor multithread:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 100 connections Thread Stats Avg Stdev Max +/- Stdev Latency 1.14ms 2.53ms 40.73ms 89.98% Req/Sec 79.98k 18.07k 154.64k 78.65% 38208400 requests in 1.00m, 5.23GB read Requests/sec: 635876.41 Transfer/sec: 89.14MB
O número de solicitações processadas em 1 minuto aumentou em ~ 3,28 vezes! Mas até o número da rodada, apenas ~ dois milhões não foram suficientes, vamos tentar corrigi-lo.
Primeiro, observe as estatísticas geradas pelo perf :
$ sudo perf stat -B -e task-clock,context-switches,cpu-migrations,page-faults,cycles,instructions,branches,branch-misses,cache-misses ./http_server_multithreaded Performance counter stats for './http_server_multithreaded': 242446,314933 task-clock (msec) # 4,000 CPUs utilized 1 813 074 context-switches # 0,007 M/sec 4 689 cpu-migrations # 0,019 K/sec 254 page-faults # 0,001 K/sec 895 324 830 170 cycles # 3,693 GHz 621 378 066 808 instructions # 0,69 insn per cycle 119 926 709 370 branches # 494,653 M/sec 3 227 095 669 branch-misses # 2,69% of all branches 808 664 cache-misses 60,604330670 seconds time elapsed
Usando a afinidade da CPU , compilar com -march=native , PGO , aumentar o número de MAX_EVENTS no cache , aumentar MAX_EVENTS e usar EPOLLET não proporcionou um aumento significativo no desempenho. Mas o que acontece se você aumentar o número de conexões simultâneas?
Estatísticas para 352 conexões simultâneas:
$ wrk -c352 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive" Running 1m test @ http://127.0.0.1:18470 8 threads and 352 connections Thread Stats Avg Stdev Max +/- Stdev Latency 2.12ms 3.79ms 68.23ms 87.49% Req/Sec 83.78k 12.69k 169.81k 83.59% 40006142 requests in 1.00m, 5.48GB read Requests/sec: 665789.26 Transfer/sec: 93.34MB
O resultado desejado foi obtido e, com ele, um gráfico interessante, mostrando a dependência do número de solicitações processadas em 1 minuto no número de conexões:
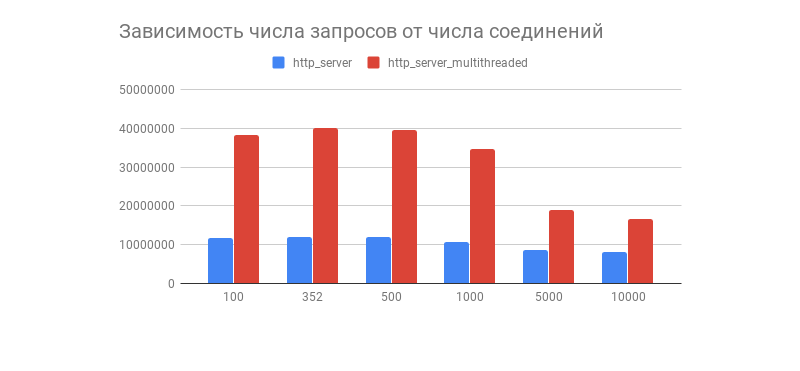
Vimos que, depois de algumas centenas de conexões, o número de solicitações processadas de ambos os servidores cai acentuadamente (em uma versão com vários threads, isso é mais perceptível). Isso está relacionado à implementação da pilha TCP / IP do Linux? Sinta-se livre para escrever suas suposições sobre esse comportamento gráfico e otimizações de opções multithread e single-threaded nos comentários.
Conforme observado nos comentários, esse teste de desempenho não mostra o comportamento do reator de E / S em cargas reais, porque quase sempre o servidor interage com o banco de dados, exibe logs, usa criptografia com TLS , etc., como resultado do qual a carga se torna heterogênea (dinâmica). Testes junto com componentes de terceiros serão realizados em um artigo sobre o proator de E / S.
Desvantagens do reator de E / S
Você precisa entender que o reator de E / S não apresenta desvantagens, a saber:
- Usar um reator de E / S em um ambiente multithread é um pouco mais difícil, porque você precisa gerenciar manualmente os fluxos.
- A prática mostra que, na maioria dos casos, a carga é heterogênea, o que pode levar ao fato de que um segmento será descartado enquanto o outro é carregado com trabalho.
- Se um manipulador de eventos bloquear o fluxo, o próprio seletor de sistema também será bloqueado, o que pode levar a erros difíceis de capturar.
Esses problemas são resolvidos pelo proctor de E / S , geralmente com um planejador que distribui uniformemente a carga no conjunto de encadeamentos e também possui uma API mais conveniente. Será discutido mais adiante em meu outro artigo.
Conclusão
Nisso, nossa jornada da teoria direto para o perfilador de exaustão chegou ao fim.
Não mencione isso, porque existem muitas outras abordagens igualmente interessantes para escrever software de rede com diferentes níveis de conveniência e velocidade. Interessante, na minha opinião, os links são fornecidos abaixo.
Até breve!
Projetos interessantes
O que mais ler?