Oi Hoje vou contar aos leitores da Habr sobre como criamos a tecnologia de reconhecimento de texto que funciona em 45 idiomas e é acessível aos usuários do Yandex.Cloud, que tarefas definimos e como as resolvemos. Será útil se você estiver trabalhando em projetos semelhantes ou quiser descobrir como aconteceu que hoje você só precisa fotografar o sinal da loja turca para que Alice o traduza para o russo.

A tecnologia de reconhecimento óptico de caracteres (OCR) vem sendo desenvolvida no mundo há décadas. Nós da Yandex começamos a desenvolver nossa própria tecnologia de OCR para melhorar nossos serviços e oferecer aos usuários mais opções. As imagens são uma grande parte da Internet e, sem a capacidade de entendê-las, a pesquisa na Internet será incompleta.
As soluções de análise de imagem estão se tornando cada vez mais populares. Isso se deve à proliferação de redes e dispositivos neurais artificiais com sensores de alta qualidade. É claro que, em primeiro lugar, estamos falando de smartphones, mas não apenas deles.
A complexidade das tarefas no campo do reconhecimento de texto está em constante crescimento - tudo começou com o reconhecimento de documentos digitalizados. Em seguida, foi adicionado o
reconhecimento de imagens digitais nascidas com texto da Internet. Então, com a crescente popularidade das câmeras móveis, o reconhecimento de boas fotos (
texto da cena com foco ). E quanto mais longe, mais complicados são os parâmetros: o texto pode ser confuso (
texto da cena incidental ),
escrito com qualquer curva ou espiral, de várias categorias - desde
fotografias de recibos até
prateleiras e letreiros.
Para que lado seguimos
O reconhecimento de texto é uma classe separada de tarefas de visão computacional. Como muitos algoritmos de visão computacional, antes da popularidade das redes neurais, era amplamente baseado em recursos manuais e heurísticos. No entanto, recentemente, com a transição para abordagens de redes neurais, a qualidade da tecnologia aumentou significativamente. Veja o exemplo na foto. Como isso aconteceu, vou contar mais.
Compare os resultados do reconhecimento de hoje com os resultados do início de 2018:
Que dificuldades encontramos no início?
No início de nossa jornada, desenvolvemos tecnologia de reconhecimento para os idiomas russo e inglês, e os principais casos de uso foram páginas fotografadas de textos e imagens da Internet. Mas, no decorrer do trabalho, percebemos que isso não basta: o texto nas imagens foi encontrado em qualquer idioma, em qualquer superfície, e as imagens às vezes eram de qualidade muito diferente. Isso significa que o reconhecimento deve funcionar em qualquer situação e em todos os tipos de dados recebidos.
E aqui estamos diante de uma série de dificuldades. Aqui estão apenas alguns:
- Detalhes Para uma pessoa que está acostumada a obter informações de texto, o texto da imagem é parágrafos, linhas, palavras e letras, mas para uma rede neural tudo parece diferente. Devido à natureza complexa do texto, a rede é forçada a ver a imagem como um todo (por exemplo, se as pessoas deram as mãos e construíram uma inscrição) e os menores detalhes (no idioma vietnamita, símbolos semelhantes ử e ừ alteram o significado das palavras). Desafios separados são reconhecer texto arbitrário e fontes não padrão.
- Multilinguismo . Quanto mais idiomas adicionamos, mais nos deparamos com suas especificidades: em cirílico e em latim as palavras são compostas por letras separadas, em árabe são escritas juntas, em japonês nenhuma palavra separada é distinguida. Alguns idiomas usam a ortografia da esquerda para a direita, alguns da direita para a esquerda. Algumas palavras são escritas horizontalmente, outras verticalmente. Uma ferramenta universal deve levar em conta todos esses recursos.
- A estrutura do texto . Para reconhecer imagens específicas, como cheques ou documentos complexos, é crucial uma estrutura que leve em consideração o layout de parágrafos, tabelas e outros elementos.
- Performance . A tecnologia é usada em uma ampla variedade de dispositivos, inclusive offline, por isso tivemos que levar em conta os rigorosos requisitos de desempenho.
Seleção do modelo de detecção
O primeiro passo para reconhecer o texto é determinar sua posição (detecção).
A detecção de texto pode ser considerada uma tarefa de reconhecimento de objeto, onde
caracteres ,
palavras ou
linhas individuais podem atuar como um objeto.
Era importante para nós que o modelo fosse escalado posteriormente para outros idiomas (agora suportamos 45 idiomas).
Muitos artigos de pesquisa sobre detecção de texto usam modelos que prevêem a posição de
palavras individuais. Mas, no caso de um
modelo universal, essa abordagem tem várias limitações - por exemplo, o próprio conceito de uma palavra para o idioma chinês é fundamentalmente diferente do conceito de uma palavra, por exemplo, em inglês. Palavras individuais em chinês não são separadas por um espaço. Em tailandês, apenas frases simples são descartadas com um espaço.
Aqui estão exemplos do mesmo texto em russo, chinês e tailandês:
. .
今天天气很好 这是一个美丽的一天散步。
สภาพอากาศสมบูรณ์แบบในวันนี้ มันเป็นวันที่สวยงามสำหรับเดินเล่นกันหน่อยแล้วAs linhas , por sua vez, são muito variáveis em termos de proporção. Por esse motivo, as possibilidades de tais modelos de detecção comuns (por exemplo, baseados em SSD ou RCNN) para previsão de linha são limitadas, pois esses modelos são baseados em regiões candidatas / caixas âncora com muitas proporções predefinidas. Além disso, as linhas podem ter uma forma arbitrária, por exemplo, curvada, portanto, para uma descrição qualitativa das linhas, não basta descrever exclusivamente um quad, mesmo com um ângulo de rotação.
Apesar de as posições de
caracteres individuais
serem locais e descritas, sua desvantagem é que é necessária uma etapa de pós-processamento separada - você precisa selecionar heurísticas para colar caracteres em palavras e linhas.
Portanto, tomamos
o modelo SegLink como base para a detecção, cuja principal idéia é decompor linhas / palavras em mais duas entidades locais: segmentos e relações entre eles.
Arquitetura do detector
A arquitetura do modelo é baseada no SSD, que prevê a posição dos objetos em várias escalas de recursos. Somente além de prever as coordenadas de "segmentos" individuais também são previstas "conexões" entre segmentos adjacentes, ou seja, se dois segmentos pertencem à mesma linha. As “conexões” são previstas tanto para segmentos vizinhos na mesma escala de sinais quanto para segmentos localizados em áreas adjacentes em escalas vizinhas (segmentos de diferentes escalas de sinais podem variar um pouco de tamanho e pertencer à mesma linha).
Para cada escala, cada célula de recurso é associada a um "segmento" correspondente. Para cada segmento s
(x, y, l) no ponto (x, y) em uma escala l, o seguinte é treinado:
- p
s se o segmento especificado é texto;
- x
s , y
s , w
s , h
s , θ
s - o deslocamento das coordenadas da base e o ângulo de inclinação do segmento;
- 8 pontos para a presença de “conexões” com segmentos adjacentes à l-ésima escala (L
w s, s ' , s' de {s
(x ', y', l) } / s
(x, y, l) , em que x –1 ≤ x '≤ x + 1, y - 1 ≤ y' ≤ y + 1);
- 4 pontos para a presença de “conexões” com segmentos adjacentes à escala l-1 (L
c s, s ' , s' de {s
(x ', y', l-1) }}, onde 2x ≤ x '≤ 2x + 1 , 2y ≤ y '≤ 2y + 1) (o que é verdade devido ao fato de que a dimensão dos recursos nas escalas vizinhas difere exatamente 2 vezes).
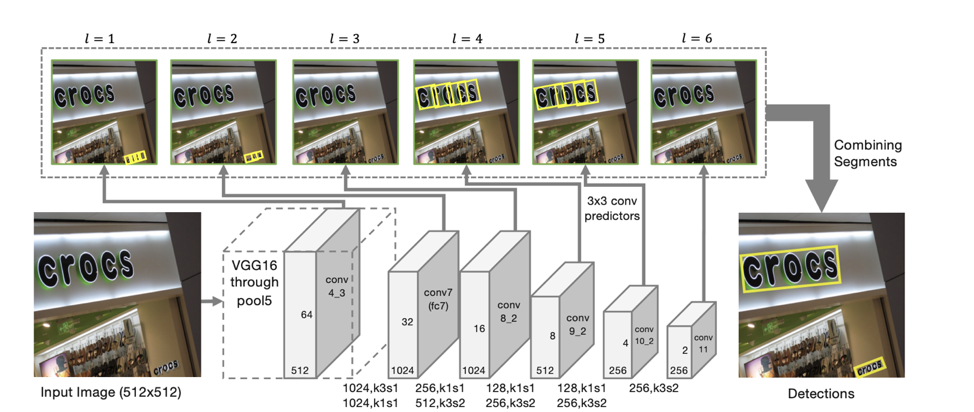
De acordo com essas previsões, se tomarmos como vértices todos os segmentos cuja probabilidade de serem texto é maior que o limite α e como arestas são todas as ligações cuja probabilidade é maior que o limite β, os segmentos formarão componentes conectados, cada um dos quais descrevendo uma linha de texto .
O modelo resultante tem uma
alta capacidade de generalização : mesmo treinado nas primeiras abordagens sobre dados em russo e inglês, encontrou qualitativamente texto em chinês e árabe.
Dez scripts
Se para a detecção conseguimos criar um modelo que funcione imediatamente para todos os idiomas, o reconhecimento das linhas encontradas é muito mais difícil de obter. Portanto, decidimos usar um
modelo separado para cada script (cirílico, latim, árabe, hebraico, grego, armênio, georgiano, coreano e tailandês). Um modelo geral separado é usado para chinês e japonês devido à grande interseção em hieróglifos.
O modelo comum a todo o script difere do modelo separado para cada idioma em menos de 1 p.p. qualidade. Ao mesmo tempo, a criação e implementação de um modelo é mais simples do que, por exemplo, 25 modelos (o número de idiomas latinos suportados pelo nosso modelo). Porém, devido à presença frequente de inglês em todos os idiomas, todos os nossos modelos são capazes de prever, além do script principal, caracteres latinos.
Para entender qual modelo deve ser usado para reconhecimento, primeiro determinamos se as linhas recebidas pertencem a um dos 10 scripts disponíveis para reconhecimento.
Deve-se notar separadamente que nem sempre é possível determinar exclusivamente seu script ao longo da linha. Por exemplo, números ou caracteres latinos únicos estão contidos em muitos scripts, portanto, uma das classes de saída do modelo é um script "indefinido".
Definição de script
Para definir o script, fizemos um classificador separado. A tarefa de definir um script é muito mais simples que a tarefa de reconhecimento, e a rede neural é facilmente treinada novamente em dados sintéticos. Portanto, em nossos experimentos, uma melhoria significativa na qualidade do modelo foi dada pelo
pré-treinamento no problema de reconhecimento de cordas . Para isso, treinamos primeiro a rede para o problema de reconhecimento de todos os idiomas disponíveis. Depois disso, o backbone resultante foi usado para inicializar o modelo na tarefa de classificação de script.
Embora um script em uma linha individual seja frequentemente bastante barulhento, a imagem como um todo geralmente contém texto em um idioma, além do principal intercalado com o inglês (ou no caso de nossos usuários russos). Portanto, para
aumentar a estabilidade, agregamos as previsões de linhas da imagem para obter uma previsão mais estável do script da imagem. Linhas com uma classe prevista de "indefinido" não são consideradas na agregação.
Reconhecimento de linha
A próxima etapa, quando já tivermos determinado a posição de cada linha e seu script, precisamos
reconhecer a sequência de caracteres do script fornecido , ou seja, da sequência de pixels para prever a sequência de caracteres. Após muitos experimentos, chegamos ao seguinte modelo baseado na atenção sequencial e sequencial:

O uso de CNN + BiLSTM no codificador permite obter sinais que capturam contextos locais e globais. Para o texto, isso é importante - geralmente é escrito em uma fonte (distinguir letras semelhantes com informações da fonte é muito mais fácil). E para distinguir duas letras escritas com um espaço das consecutivas, também são necessárias estatísticas globais para a linha.
Uma observação interessante : no modelo resultante, as saídas da máscara de atenção para um símbolo específico podem ser usadas para prever sua posição na imagem.
Isso nos inspirou a tentar
"focar" claramente a atenção do modelo . Tais idéias também foram encontradas em artigos - por exemplo, no artigo
Atenção concentrada: em direção ao reconhecimento preciso de texto em imagens naturais .
Como o mecanismo de atenção fornece uma distribuição de probabilidade no espaço de recurso, se considerarmos como perda adicional a soma da atenção emitida dentro da máscara correspondente à letra prevista nesta etapa, obteremos a parte da "atenção" que foca diretamente nela.
Introduzindo -log de perda (∑
i, j∈M t α
i, j ), onde M
t é a máscara da décima letra, α é a saída da atenção, incentivaremos a “atenção” por focar o símbolo fornecido e, assim, ajudar redes neurais aprendem melhor.
Para os exemplos de treinamento para os quais a localização de caracteres individuais é desconhecida ou imprecisa (nem todos os dados de treinamento têm marcações no nível de caracteres individuais, não palavras), esse termo não foi levado em consideração na perda final.
Outro recurso interessante: essa arquitetura permite prever o
reconhecimento de linhas da direita para a esquerda sem alterações adicionais (o que é importante, por exemplo, para idiomas como árabe, hebraico). O próprio modelo começa a emitir reconhecimento da direita para a esquerda.
Modelos rápidos e lentos
No processo, encontramos um problema:
para fontes “altas” , ou seja, fontes alongadas verticalmente, o modelo funcionou mal. Isso foi causado pelo fato de a dimensão dos sinais no nível de atenção ser 8 vezes menor que a dimensão da imagem original devido a avanços e puxões na arquitetura da parte convolucional da rede. E a localização de vários caracteres vizinhos na imagem de origem pode corresponder à localização do mesmo vetor de recurso, o que pode levar a erros nesses exemplos. O uso da arquitetura com um estreitamento menor da dimensão dos recursos levou a um aumento na qualidade, mas também ao aumento do tempo de processamento.
Para resolver esse problema e
evitar aumentar o tempo de processamento , fizemos os seguintes refinamentos no modelo:
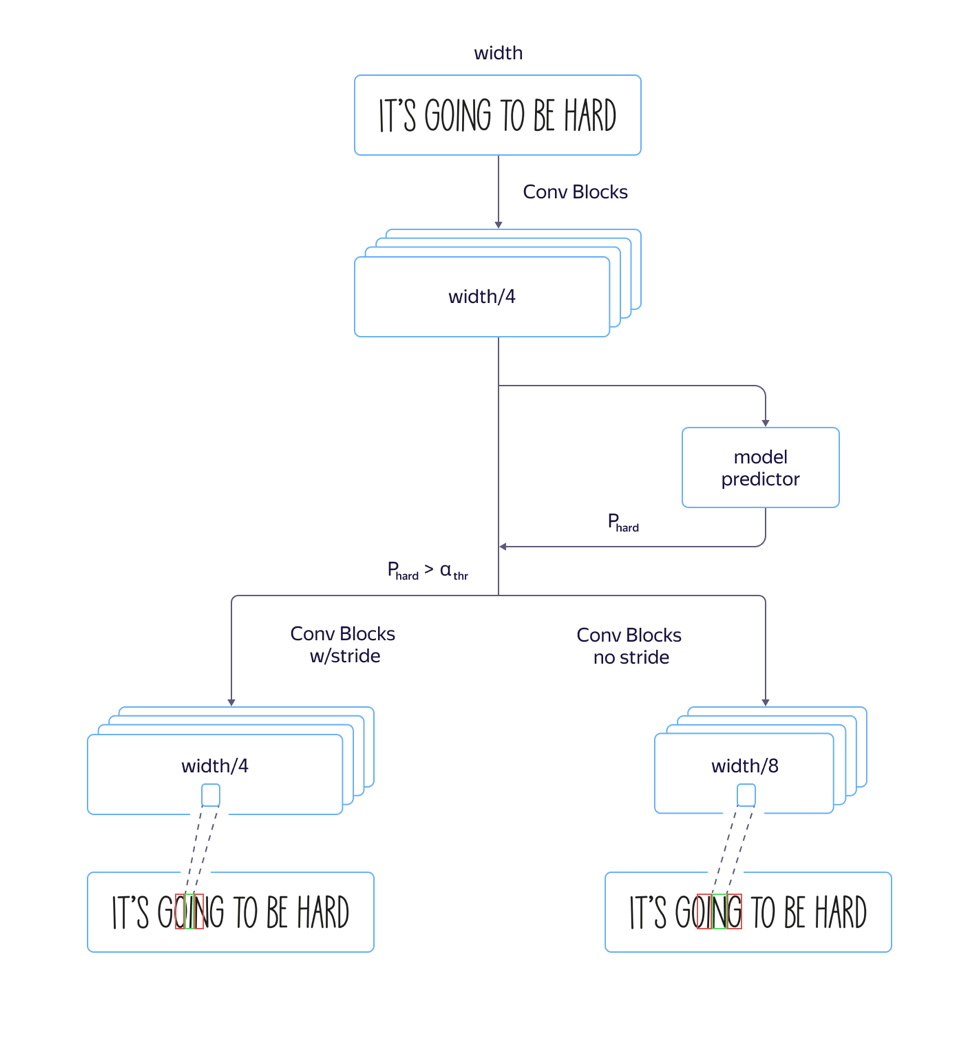
Treinamos um modelo rápido com muitos avanços e um lento com menos. Na camada em que os parâmetros do modelo começaram a diferir, adicionamos uma saída de rede separada que previa qual modelo teria menos erro de reconhecimento. A perda total do modelo foi composta por qualidade L
pequeno + L
grande + L. Assim, na camada intermediária, o modelo aprendeu a determinar a “complexidade” deste exemplo. Além disso, no estágio de aplicação, a parte geral e a previsão da “complexidade” do exemplo foram consideradas para todas as linhas e, dependendo de sua saída, um modelo rápido ou lento foi usado no futuro, de acordo com o valor limite. Isso nos permitiu obter uma qualidade quase diferente da qualidade de um modelo longo, enquanto a velocidade aumentou apenas 5% por cento em vez dos 30% estimados.
Dados de treinamento
Uma etapa importante na criação de um modelo de alta qualidade é a preparação de uma amostra grande e variada de treinamento. A natureza "sintética" do texto permite gerar grandes quantidades de exemplos e obter resultados decentes em dados reais.
Após a primeira abordagem para a geração de dados sintéticos, analisamos cuidadosamente os resultados do modelo obtido e descobrimos que o modelo não reconhece letras únicas 'I' devido ao viés nos textos usados para criar o conjunto de treinamento. Portanto, geramos claramente um
conjunto de exemplos “problemáticos” e, quando o adicionamos aos dados iniciais do modelo, a qualidade aumentou significativamente. Repetimos esse processo várias vezes, adicionando fatias cada vez mais complexas, nas quais queríamos melhorar a qualidade do reconhecimento.
O ponto importante é que os
dados gerados
devem ser diversos e semelhantes aos reais . E se você deseja que o modelo trabalhe em fotografias de texto em folhas de papel e todo o conjunto de dados sintético contenha texto escrito sobre paisagens, isso pode não funcionar.
Outro passo importante é usar para treinar os exemplos nos quais o reconhecimento atual está errado. Se houver um grande número de fotos para as quais não há marcação, você pode obter as saídas do sistema de reconhecimento atual em que ela não tem certeza e marcar apenas elas, reduzindo assim o custo da marcação.
Para exemplos complexos, pedimos aos usuários do serviço Yandex.Tolok uma taxa para fotografar e nos enviar
imagens de um determinado grupo "complexo" - por exemplo, fotos de pacotes de mercadorias:


Qualidade do trabalho em dados "complexos"
Queremos dar aos nossos usuários a oportunidade de trabalhar com fotografias de qualquer complexidade, pois pode ser necessário reconhecer ou traduzir o texto não apenas na página de um livro ou documento digitalizado, mas também em uma placa de rua, anúncio ou embalagem do produto. Portanto, mantendo a alta qualidade do trabalho no fluxo de livros e documentos (dedicaremos uma história separada a esse tópico), prestamos atenção especial a "conjuntos complexos de imagens".
Do modo descrito acima, compilamos um conjunto de imagens contendo texto em estado selvagem, o que pode ser útil para nossos usuários: fotografias de letreiros, anúncios, pratos, capas de livros, textos em eletrodomésticos, roupas e objetos. Nesse conjunto de dados (cujo link está abaixo), avaliamos a qualidade do nosso algoritmo.
Como métrica para comparação, usamos a métrica padrão de precisão e integridade do reconhecimento de palavras no conjunto de dados, bem como a medida F. Uma palavra reconhecida é considerada corretamente encontrada se suas coordenadas corresponderem às coordenadas da palavra marcada (IoU> 0,3) e o reconhecimento coincidir com o marcado exatamente para o caso. Figuras no conjunto de dados resultante:
Conjunto de dados, métricas e scripts para reproduzir os resultados estão disponíveis
aqui .
Upd. Amigos, comparar nossa tecnologia com uma solução semelhante da Abbyy causou muita controvérsia. Respeitamos as opiniões da comunidade e dos pares da indústria. Mas, ao mesmo tempo, estamos confiantes em nossos resultados, por isso decidimos da seguinte maneira: removeremos os resultados de outros produtos da comparação, discutiremos a metodologia de teste com eles novamente e retornaremos aos resultados em que chegamos a um acordo geral.
Próximas etapas
Na junção de etapas individuais, como detecção e reconhecimento, sempre surgem problemas: as menores alterações no modelo de detecção acarretam a necessidade de alterar o modelo de reconhecimento; portanto, estamos experimentando ativamente a criação de uma solução de ponta a ponta.
Além das formas já descritas para melhorar a tecnologia, desenvolveremos uma direção para analisar a estrutura do documento, que é de fundamental importância na extração de informações e é procurada pelos usuários.
Conclusão
Os usuários já estão acostumados a tecnologias convenientes e, sem hesitar, ligam a câmera, apontam para a placa da loja, o menu no restaurante ou a página do livro em um idioma estrangeiro e recebem rapidamente uma tradução. Reconhecemos o texto em 45 idiomas com precisão comprovada, e as oportunidades só serão expandidas. Um conjunto de ferramentas dentro do Yandex.Cloud permite que qualquer pessoa que queira usar as melhores práticas que o Yandex vem praticando há muito tempo.
Hoje você pode simplesmente pegar a tecnologia final, integrá-la ao seu próprio aplicativo e usá-la para criar novos produtos e automatizar seus próprios processos. A documentação para o nosso OCR está disponível
aqui .
O que ler:
- D. Karatzas, SR Mestre, J. Mas, F. Nourbakhsh e PP Roy, “ICDAR 2011 robusto concurso de desafio 1: leitura de texto em imagens digitais nascidas (web e email)”, em Análise e reconhecimento de documentos (ICDAR) ), Conferência Internacional de 2011 em. IEEE, 2011, pp. 1485-1490.
- Karatzas D. et al. Concurso ICDAR 2015 sobre leitura robusta // 13ª Conferência Internacional sobre Análise e Reconhecimento de Documentos (ICDAR). - IEEE, 2015 - S. 1156-1160.
- Chee-Kheng Chng et. al. Desafio de leitura robusta da ICDAR2019 em texto em forma arbitrária (RRC-ArT) [ arxiv: 1909.07145v1 ]
- Desafio de leitura robusta do ICDAR 2019 sobre OCR de recibos digitalizados e extração de informações rrc.cvc.uab.es/?ch=13
- ShopSign: um conjunto de dados de texto de cena diversa de letreiros chineses em vistas da rua [ arxiv: 1903.10412 ]
- Baoguang Shi, Xiang Bai, Serge Belongie Detectando texto orientado em imagens naturais, vinculando segmentos [ arxiv: 1703.06520 ].
- Zhanzhan Cheng, Fan Bai, Yunlu Xu, Gang Zheng, Shiliang Pu, Shuigeng Zhou Focando a atenção: rumo ao reconhecimento preciso do texto em imagens naturais [ arxiv: 1709.02054 ].