Bom dia e meu respeito, leitores de Habr!
Antecedentes
Em nosso lugar, é habitual trocar descobertas interessantes em equipes de desenvolvimento. Na próxima reunião, discutindo o futuro do .NET e .NET 5 em particular, meus colegas e eu nos concentramos em ver uma plataforma unificada a partir desta imagem:
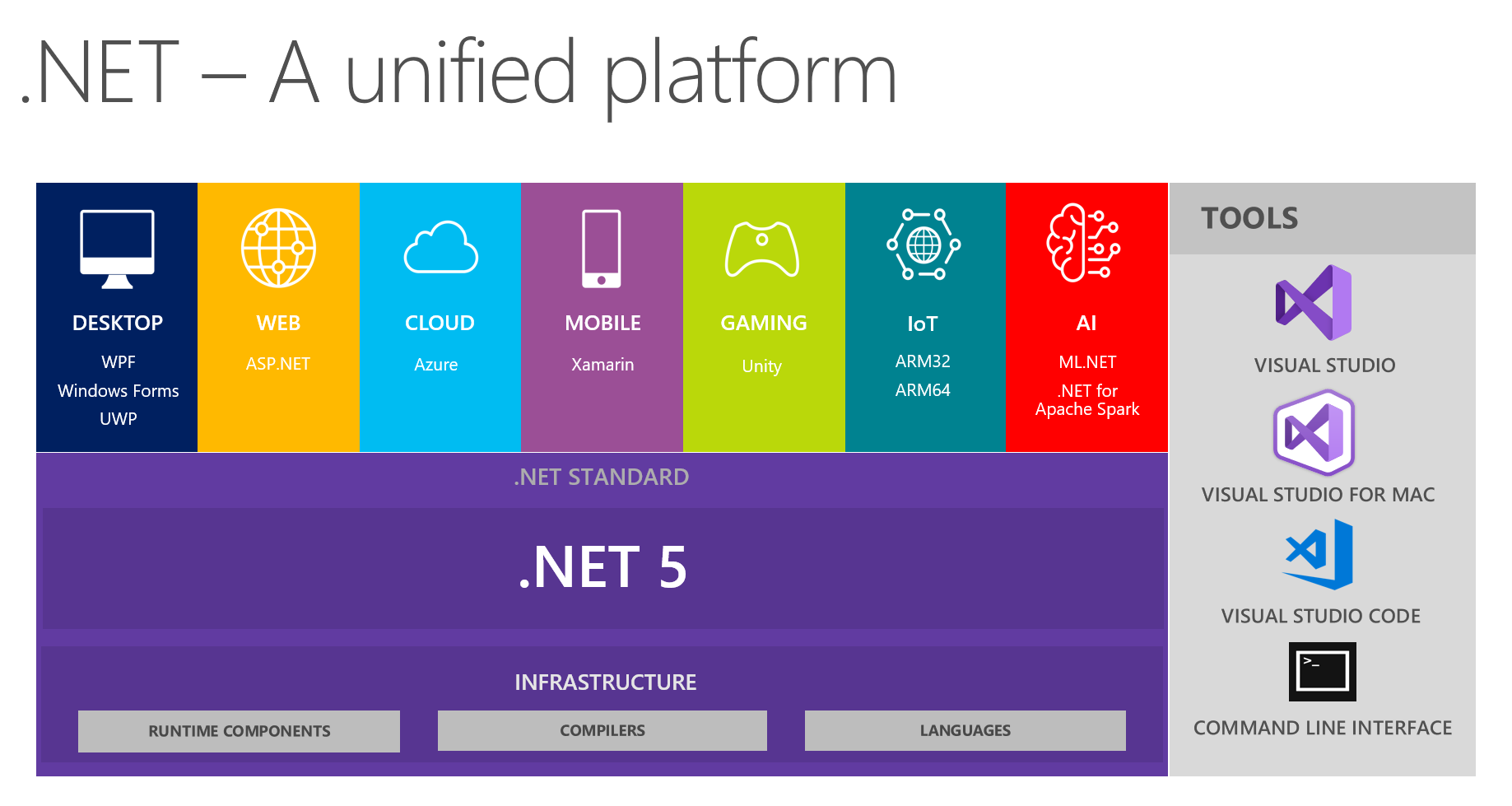
Isso mostra que a plataforma combina DESKTOP, WEB, NUVEM, MÓVEL, JOGOS, IoT e AI. Tive a ideia de conduzir uma conversa na forma de um pequeno relatório + perguntas / respostas sobre cada tópico nas próximas reuniões. A pessoa responsável por um tópico específico está se preparando preliminarmente, lendo informações sobre as principais inovações, tentando implementar algo usando a tecnologia escolhida e depois compartilhando seus pensamentos e impressões conosco. Como resultado, todos recebem feedback real sobre as ferramentas de uma fonte confiável em primeira mão - é muito conveniente, já que tentar e invadir todos os tópicos por conta própria pode não ser útil, pois suas mãos não alcançarão.
Desde que eu tenho um interesse ativo no aprendizado de máquina como hobby por algum tempo (e às vezes o uso para tarefas não comerciais no trabalho), entendi o tópico da AI & ML.NET. No processo de preparação, deparei-me com ferramentas e materiais maravilhosos, para minha surpresa, descobri que há muito pouca informação sobre eles em Habré. No início do blog oficial, a Microsoft escreveu sobre o lançamento do ML.Net e do Model Builder em particular. Gostaria de compartilhar como cheguei a ele e que impressões tive ao trabalhar com ele. O artigo é mais sobre o Model Builder do que o ML no .NET como um todo; tentaremos analisar o que a MS oferece ao desenvolvedor .NET comum, mas com os olhos de uma pessoa mais experiente em ML. Ao mesmo tempo, tentarei manter um equilíbrio entre a recontagem do tutorial, principalmente para iniciantes e a descrição de detalhes para especialistas em ML, que por algum motivo precisavam acessar o .NET.
Corpo principal
Portanto, uma rápida pesquisa sobre o ML no .NET me leva à página do tutorial :
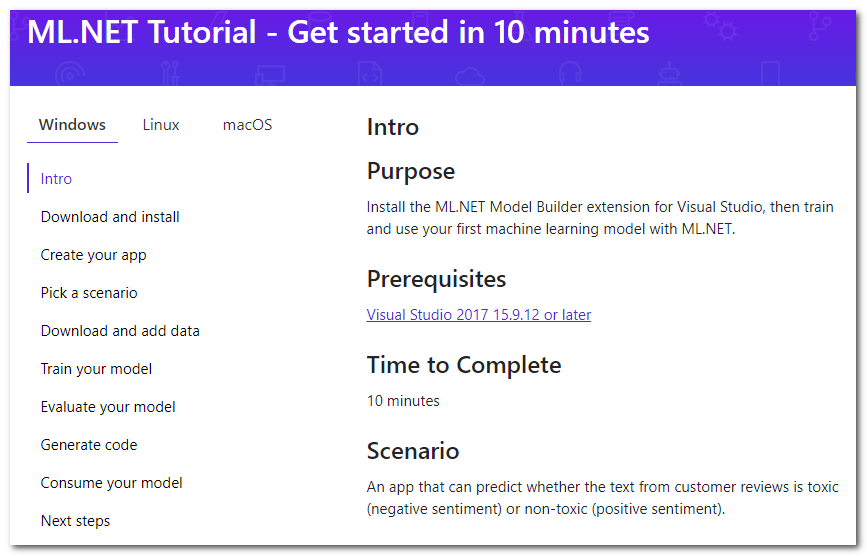
Acontece que existe uma extensão especial para o Visual Studio chamada Model Builder, que "permite adicionar aprendizado de máquina ao seu projeto com o botão direito do mouse" (tradução gratuita). Analisarei brevemente as principais etapas do tutorial que serão oferecidas, e adicionarei detalhes e meus pensamentos.
Baixe e instale
Aperte o botão, faça o download, instale. O estúdio terá que reiniciar.
Crie seu aplicativo
Primeiro, crie um aplicativo C # regular. No tutorial, propõe-se criar o Core, mas também se adequa ao Framework. E então, de fato, o ML começa - clique com o botão direito do mouse no projeto e depois em Adicionar -> Machine Learning. A janela que aparecerá para criar o modelo será analisada, pois é nela que toda a mágica acontece.
Escolha um cenário
Selecione o "script" do seu aplicativo. No momento, cinco estão disponíveis (o tutorial está um pouco desatualizado, existem quatro até agora):
- Análise de sentimentos - análise de tonalidade, classificação binária (classificação binária), o texto determina sua cor emocional, positiva ou negativa.
- Classificação do problema - a classificação multiclasse, o rótulo de destino do problema (ticket, erros, chamadas de suporte etc.) pode ser selecionado como uma das três opções mutuamente exclusivas
- Previsão de preço - regressão, o problema clássico de regressão quando a saída é um número contínuo; No exemplo, esta é uma estimativa de apartamento
- Classificação de imagem - classificação multiclasse, mas já para imagens
- Cenário personalizado - seu cenário; Sou forçado a lamentar que não haja nada de novo nessa opção. Só mais tarde, eles me permitirão escolher uma das quatro opções descritas acima.
Observe que não há uma classificação multilabel quando o método de destino pode ser muitos ao mesmo tempo (por exemplo, uma declaração pode ser ofensiva, racista e obscena ao mesmo tempo, e pode não ser nada disso). Para imagens, não há opção para selecionar uma tarefa de segmentação. Suponho que, com a ajuda da estrutura, eles geralmente sejam solucionáveis, mas hoje nos concentramos no construtor. Parece que dimensionar o assistente para expandir o número de tarefas não é uma tarefa difícil, portanto, você deve esperá-las no futuro.
Baixe e adicione dados
Propõe-se baixar o conjunto de dados. Da necessidade de fazer o download para sua máquina, concluímos automaticamente que o treinamento será realizado em nossa máquina local. Isso tem duas vantagens:
- Você controla todos os dados, pode corrigir, alterar localmente e repetir as experiências.
- Você não carrega dados para a nuvem, mantendo assim a privacidade. Afinal, não carregue, sim Microsoft ? :)
e contras:
- A velocidade de aprendizado é limitada pelos recursos da sua máquina local.
Propõe-se ainda selecionar o conjunto de dados baixado como uma entrada do tipo "Arquivo". Há também uma opção para usar o "SQL Server" - você precisará especificar os detalhes necessários do servidor e selecionar a tabela. Se bem entendi, ainda não é possível especificar um script específico. Abaixo, escrevo sobre os problemas que tive com esta opção.
Treine seu modelo
Nesta etapa, vários modelos são treinados sequencialmente, a velocidade é exibida para cada um e, no final, o melhor é selecionado. Ah, sim, esqueci de mencionar que isso é AutoML - ou seja, o melhor algoritmo e parâmetros (não tenho certeza, veja abaixo) serão selecionados automaticamente, para que você não precise fazer nada! Propõe-se limitar o tempo máximo de treinamento ao número de segundos. Heurísticas para a definição desse horário: https://github.com/dotnet/machinelearning-samples/blob/master/modelbuilder/readme.md#train . Na minha máquina nos 10 segundos padrão, apenas um modelo aprende, então tenho que apostar muito mais. Começamos, esperamos.
Aqui, quero acrescentar que os nomes dos modelos pessoalmente me pareciam um pouco incomuns, por exemplo: AveragedPerceptronBinary, FastTreeOva, SdcaMaximumEntropyMulti. A palavra "Perceptron" não é usada com muita frequência atualmente, "Ova" é provavelmente um contra todos, e "FastTree" acho difícil dizer o que.
Outro fato interessante é que LightGbmMulti está entre os algoritmos candidatos. Se bem entendi, esse é o mesmo LightGBM, o mecanismo de aumento de gradiente que, juntamente com o CatBoost, agora está competindo com a regra do XGBoost, que era uma vez isolada. Ele está um pouco frustrado com sua velocidade no desempenho atual - pelos meus dados, seu treinamento levou mais tempo (cerca de 180 segundos). Embora a entrada seja texto, depois de vetorizar milhares de colunas mais do que os exemplos de entrada, esse não é o melhor caso para impulsionar e árvores em geral.
Avalie seu modelo
Na verdade, a avaliação dos resultados do modelo. Nesta etapa, você pode ver quais métricas de meta foram atingidas e impulsionar o modelo ao vivo. Sobre as próprias métricas podem ser lidas aqui: MS e sklearn .
Eu estava interessado principalmente na pergunta - em que foi testado? Uma pesquisa na mesma página de ajuda fornece uma resposta - a partição é muito conservadora, de 80% a 20%. Não encontrei a capacidade de configurar isso na interface do usuário. Na prática, eu gostaria de controlar isso, porque quando há realmente muitos dados, a partição pode ser de até 99% e 1% (de acordo com Andrew Ng, eu mesmo não trabalhei com esses dados). Também seria útil poder definir amostragem aleatória de dados de sementes, porque é difícil superestimar a repetibilidade durante a construção e seleção do melhor modelo. Parece que não é difícil adicionar essas opções. Para manter a transparência e a simplicidade, você pode ocultá-las atrás de algumas opções extras.
No processo de construção do modelo, os tablets com indicadores de velocidade são exibidos no console, cujo código de geração pode ser encontrado nos projetos da próxima etapa. Podemos concluir que o código gerado realmente funciona, e sua saída honesta é emitida, não é falsa.
Uma observação interessante - enquanto escrevia o artigo, eu mais uma vez andei pelas etapas do construtor, usei o conjunto de dados proposto dos comentários da Wikipedia. Mas, como tarefa, escolhi "Personalizado" e, em seguida, uma classificação em várias classes como alvo (embora haja apenas duas classes). Como resultado, a velocidade ficou 10% pior (cerca de 73% versus 83%) do que a velocidade da captura de tela com classificação binária. Para mim, isso é um pouco estranho, porque o sistema poderia ter adivinhado que existem apenas duas classes. Em princípio, classificadores do tipo um contra todos (um contra todos, quando o problema de classificação em várias classes é reduzido à solução seqüencial de problemas binários N para cada uma das N classes) também devem mostrar uma velocidade binária semelhante nessa situação.
Gerar código
Nesta etapa, dois projetos serão gerados e adicionados à solução. Um deles tem um exemplo completo do uso do modelo e o outro deve ser analisado apenas se os detalhes da implementação forem interessantes.
Descobri, por mim mesmo, que todo o processo de aprendizado é formado de forma concisa em um pipeline (olá aos alunos do sk-learn):
// Data process configuration with pipeline data transformations var processPipeline = mlContext.Transforms.Conversion.MapValueToKey("Sentiment", "Sentiment") .Append(mlContext.Transforms.Text.FeaturizeText("SentimentText_tf", "SentimentText")) .Append(mlContext.Transforms.CopyColumns("Features", "SentimentText_tf")) .Append(mlContext.Transforms.NormalizeMinMax("Features", "Features")) .AppendCacheCheckpoint(mlContext);
(tocou levemente na formatação do código para se ajustar bem)
Lembre-se, eu estava falando sobre os parâmetros? Não vejo nenhum parâmetro personalizado, todos os valores padrão. A propósito, usando o rótulo SentimentText_tf na saída do FeaturizeText podemos concluir que essa é uma frequência de termo (a documentação diz que estes são n-gramas e gramas de texto; me pergunto se existe uma IDF, frequência de documento invertida).
Consuma seu modelo
Na verdade, um exemplo de uso. Só posso notar que o Predict é feito elementarmente.
Bem, isso é tudo, na verdade - examinamos todas as etapas do construtor e observamos os pontos principais. Mas este artigo ficaria incompleto sem um teste em seus próprios dados, porque qualquer pessoa que já tenha encontrado o ML e o AutoML sabe muito bem que qualquer máquina é boa em tarefas padrão, testes sintéticos e conjuntos de dados da Internet. Portanto, foi decidido verificar o construtor em suas tarefas; a seguir, ele sempre trabalha com texto ou texto + recursos categóricos.
Não foi por acaso que eu tinha em mãos um conjunto de dados com alguns erros / problemas / defeitos registrados em um dos projetos. Possui 2949 linhas, 8 classes-alvo desequilibradas, 4mb.
ML.NET (carregamento, conversões, algoritmos da lista abaixo; levou 219 segundos)
| Top 2 models explored | -------------------------------------------------------------------------------- | Trainer MicroAccuracy MacroAccuracy Duration #Iteration| |1 SdcaMaximumEntropyMulti 0,7475 0,5426 176,7 1| |2 AveragedPerceptronOva 0,7128 0,4492 42,4 2| --------------------------------------------------------------------------------
(vazios picados na placa para caber no Markdown)
Minha versão do Python (carregar, limpar , converter e LinearSVC; levou 41 segundos):
Classsification report: precision recall f1-score support Class 1 0.71 0.61 0.66 33 Class 2 0.50 0.60 0.55 5 Class 3 0.65 0.58 0.61 59 Class 4 0.75 0.60 0.67 5 Class 5 0.78 0.86 0.81 77 Class 6 0.75 0.46 0.57 13 Class 7 0.82 0.90 0.86 227 Class 8 0.86 0.79 0.82 169 accuracy 0.80 588 macro avg 0.73 0.67 0.69 588 weighted avg 0.80 0.80 0.80 588
0,80 vs 0,747 Micro e 0,73 vs 0,542 Macro (pode haver alguma imprecisão na definição de Macro, se for interessante, eu vou te dizer nos comentários).
Estou agradavelmente surpreendido, apenas 5% da diferença. Em alguns outros conjuntos de dados, a diferença era ainda menor e, às vezes, não era. Analisando a magnitude da diferença, vale a pena levar em consideração o fato de que o número de amostras nos conjuntos de dados é pequeno e, às vezes, após o próximo upload (algo é excluído, algo é adicionado), observei movimentos de velocidade de 2 a 5%.
Enquanto eu estava experimentando por conta própria, não houve problemas ao usar o construtor. No entanto, durante a apresentação, os colegas ainda encontraram vários batentes:
- Tentamos carregar honestamente um dos conjuntos de dados da tabela no banco de dados, mas encontramos uma mensagem de erro não informativa. Tive uma idéia aproximada de que tipo de plano os dados de texto existem e imediatamente descobri que o problema poderia estar nos feeds de linha. Bem, baixei o conjunto de dados usando pandas.read_csv , limpei-o de \ n \ r \ t, salvei-o em tsv e segui em frente.
- Durante o treinamento do próximo modelo, eles receberam uma exceção relatando que uma matriz de tamanho ~ 220.000 por 1000 não pode caber confortavelmente na memória, para que o treinamento seja interrompido. Ao mesmo tempo, o modelo também não foi gerado. O que fazer a seguir não é claro: saímos da situação substituindo o prazo de aprendizado "a olho nu" - para que o algoritmo em queda não tenha tempo para começar a trabalhar.
A propósito, a partir do segundo parágrafo, podemos concluir que o número de palavras e n-gramas durante a vetorização não é realmente limitado pelo limite superior, e "n" é provavelmente igual a dois. Posso dizer por experiência própria que 200k é claramente demais. Geralmente, é limitado às ocorrências mais frequentes ou é aplicado sobre vários tipos de algoritmos de redução dimensional, por exemplo, SVD ou PCA.
Conclusões
O construtor oferece uma escolha de vários cenários nos quais não encontrei locais críticos que exijam imersão no ML. Desse ponto de vista, é perfeito como uma ferramenta "iniciando" ou resolvendo problemas simples típicos aqui e agora. Os casos de uso reais são inteiramente da sua imaginação. Você pode ir para as opções oferecidas pela MS:
- resolver o problema da avaliação de sentimentos (análise de sentimentos), por exemplo, nos comentários sobre os produtos no site
- classifique os ingressos por categorias ou equipes (classificação da edição)
- continue fingindo tíquetes, mas com a ajuda da previsão de preços - estime os custos de tempo
E você pode adicionar algo de sua preferência, por exemplo, para automatizar a tarefa de distribuir erros / incidentes de entrada entre desenvolvedores, reduzindo-a à tarefa de classificação por texto (rótulo de destino - ID / Sobrenome do desenvolvedor). Ou você pode agradar aos operadores da estação de trabalho interna que preenchem os campos no cartão com um conjunto fixo de valores (lista suspensa) para outros campos ou descrição de texto. Para fazer isso, basta preparar uma seleção em csv (até várias centenas de linhas são suficientes para experimentos), ensinar o modelo diretamente do UI Visual Studio e aplicá-lo em seu projeto, copiando o código do exemplo gerado. Levo ao fato de que o ML.NET, na minha opinião, é bastante adequado para resolver tarefas práticas, pragmáticas e mundanas que não exigem qualificações especiais e em vão vão consumindo tempo. Além disso, pode ser aplicado no projeto mais comum, que não pretende ser inovador. Qualquer desenvolvedor .NET que esteja pronto para dominar uma nova biblioteca pode se tornar o autor desse modelo.
Eu tenho um background de ML um pouco mais do que o desenvolvedor .NET comum, então eu decidi da seguinte maneira: para fotos, provavelmente não, para casos complexos, mas para tarefas simples de tabela, definitivamente sim. No momento, é mais conveniente para mim executar qualquer tarefa de ML na pilha de tecnologia Python / numpy / pandas / sk-learn / keras / pytorch mais familiar, no entanto, eu teria feito um caso típico para incorporar posteriormente em um aplicativo .NET usando o ML.NET .
A propósito, é bom que a estrutura de texto funcione perfeitamente sem gestos desnecessários e a necessidade de ajuste pelo usuário. Em geral, isso não é surpreendente, porque na prática, em pequenas quantidades de dados, os bons e antigos TfIDFs com classificadores como SVC / NaiveBayes / LR funcionam muito bem. Isso foi discutido no DataFest de verão em um relatório do iPavlov - em algumas suítes de testes word2vec, GloVe, ELMo (tipo de) e BERT foram comparados com o TfIdf. No teste, foi possível alcançar a superioridade de alguns por cento em apenas um caso de 7 a 10 casos, embora a quantidade de recursos gastos em treinamento não seja comparável.
PS A popularização da ML entre as massas agora está em tendência, mesmo com a “ ferramenta do Google para criar IA, que até um estudante pode usar ”. É tudo engraçado e intuitivo para o usuário, mas o que realmente está acontecendo nos bastidores na nuvem não é claro. Nisso, para desenvolvedores .NET, o ML.NET com um construtor de modelos parece uma opção mais atraente.
A apresentação do PSS saiu com um estrondo, os colegas estavam motivados a tentar :)
Comentários
A propósito, um dos boletins com a manchete "ML.NET Model Builder" disse:
Dê-nos o seu feedback
Se você encontrar algum problema, sentir que algo está faltando ou realmente gostar de algo sobre o ML.NET Model Builder, informe-nos criando um problema em nosso repositório do GitHub.
O Model Builder ainda está na visualização, e seus comentários são super importantes para direcionar a direção que tomamos com esta ferramenta!
Este artigo pode ser considerado um feedback!
Referências
No ML.NET
Para um artigo antigo com orientação