Sempre queremos escrever código rapidamente, mas você precisa pagar por isso. Em linguagens flexíveis de alto nível comuns, os programas podem ser desenvolvidos rapidamente, mas são executados lentamente após o lançamento. Por exemplo, é monstruosamente lento ler algo pesado em Python puro. Os idiomas do tipo C funcionam muito mais rápido, mas é mais fácil cometer erros, cuja busca reduzirá a nada o ganho de velocidade.
Normalmente, esse dilema é resolvido da seguinte forma: primeiro eles escrevem o protótipo em algo flexível, por exemplo, em Python ou R, e depois reescrevem-no em C / C ++ ou Fortran. Mas esse ciclo é muito longo, você pode ficar sem ele?

Talvez haja uma solução. Julia é uma linguagem de programação de alto nível e flexível, porém rápida. Julia possui despacho múltiplo, um compilador inteligente integrado e ferramentas de metaprogramação.
Gleb Ivashkevich (
phtRaveller ), o fundador da termodinâmica, que desenvolve sistemas de aprendizado de máquina para a indústria e outras indústrias, um ex-físico, lhe dirá mais sobre o que Julia tem.
Gleb explicará por que novas linguagens são necessárias e por que algumas vezes o Python está ausente. Ele lhe dirá o que é interessante em Julia, sobre seus pontos fortes e fracos, o comparará com outros idiomas e mostrará qual o idioma que tem a perspectiva de aprendizado de máquina e computação em geral.
Isenção de responsabilidade. Não haverá análise de sintaxe. Habrazhiteli experimentou desenvolvedores, por isso não faz sentido mostrar como escrever um loop, por exemplo.O problema de duas línguas
Se você escrever código rapidamente, os programas serão executados lentamente. Se os programas funcionarem rapidamente, escreva-os por um longo tempo.
O Python clássico se enquadra na primeira categoria. Se você remover o NumPy, considere algo em Python puro lentamente. Por outro lado, existem idiomas como C e C ++. É difícil encontrar um equilíbrio, então, na maioria das vezes, eles escrevem um protótipo em algo flexível e, após depurar o algoritmo, eles o reescrevem para o idioma mais rapidamente. Este é um exemplo de um
problema claro em duas linguagens : um longo ciclo quando você precisa escrever em Python e reescrevê-lo em C ou em Cython, por exemplo.
Especialistas em aprendizado de máquina e ciência de dados têm NumPy, Sklearn, TensorFlow. Eles estão resolvendo seus problemas há anos sem uma única linha em C, e parece que o problema dos dois idiomas não os preocupa. Não é assim, o problema se manifesta
implicitamente , porque o código no NumPy ou no TensorFlow não é realmente Python. É usado como uma metalinguagem para lançar o que está dentro. Dentro é exatamente C / Fortran (no caso do NumPy) ou C ++ (no caso do TensorFlow).
Esse "recurso" é pouco visível, por exemplo, no PyTorch, mas no Numpy é claramente visível. Por exemplo, se um ciclo clássico de Python apareceu nos cálculos, algo deu errado. No código produtivo, os loops não são necessários; você precisa reescrever tudo para que o NumPy possa vetorizá-lo e calculá-lo rapidamente.
Ao mesmo tempo, parece que muitos NumPy é rápido e está tudo bem com ele. Vamos ver o que NumPy tem sob o capô para ver isso.
- O NumPy está tentando corrigir o problema de flexibilidade do tipo Python, por isso possui um sistema de tipos bastante rigoroso . Se a matriz tiver um determinado tipo, não poderá haver mais nada; se o
Float64 estiver Float64 , nada poderá ser feito. - Despachar. Dependendo dos tipos de matrizes e de qual operação você precisa executar, o NumPy dentro de si decidirá qual função chamar para fazer os cálculos o mais rápido possível. A biblioteca tentará tirar o Python clássico do circuito de computação.
Acontece que o Numpy não é tão rápido quanto parece. É por isso que existem projetos como
Cython ou
Numba . O primeiro gera código C a partir do "híbrido" de Python e C, e o segundo compila o código em Python e, geralmente, isso é mais rápido.
Se o NumPy fosse realmente tão rápido quanto parece para muitos, a existência de Cython e Numba não faria sentido.
Reescrevemos tudo no Cython se queremos encontrar rapidamente algo grande e complexo. Um dos critérios para a qualidade de um wrapper no Cython é a presença ou ausência de chamadas Python puras no código gerado.
Um exemplo simples: adicionamos o tipo (bom) ou não (ruim) e obtemos dois códigos completamente diferentes, embora, além dos tipos, as opções iniciais não sejam diferentes.

Quando geramos o código C, no primeiro caso, obtemos o seguinte:
__pyx_t_4 = __pyx_v_i; __pyx_v_result = (__pyx_v_result + (*((double *) ( (__pyx_v_a.data + __pyx_t_4 * __pyx_v_a.strides[0]) ))));
E no segundo
result =0. vai virar isso:
__pyx_t_6 = PyFloat_FromDouble((*((double *) ( (__pyx_v_a.data + __pyx_t_4 * __pyx_v_a.strides[0]) )))); if (unlikely(!__pyx_t_6)) __PYX_ERR(0, 9, __pyx_L1_error) __Pyx_GOTREF(__pyx_t_6); __pyx_t_7 = PyNumber_InPlaceAdd(__pyx_v_result, __pyx_t_6); if (unlikely(!__pyx_t_7)) __PYX_ERR(0, 9, __pyx_L1_error) __Pyx_GOTREF(__pyx_t_7); __Pyx_DECREF(__pyx_t_6); __pyx_t_6 = 0; __Pyx_DECREF_SET(__pyx_v_result, __pyx_t_7); __pyx_t_7 = 0;
Quando um tipo é especificado, o código C executa a velocidade da luz. Se o tipo não for especificado, vemos o Python normal, mas do lado C: chamadas padrão do Python, nas quais, por algum motivo, os
float são criados a partir do
double , os links são contados e muitos outros códigos de lixo. Esse código é lento porque chama Python para todas as operações.
É possível resolver todos os problemas de uma só vez
É engraçado que, quando pensamos em algo, tentamos remover o Python puro. Existem duas opções para fazer isso.
- Usando Cython ou outras ferramentas. Existem várias maneiras de otimizar seu código Cython para acabar com quase nenhuma chamada de Python. Mas essa não é a atividade mais agradável: nem tudo é tão óbvio no Cython, e apenas um pouco menos de tempo é gasto do que se você escrever tudo em C. O módulo resultante pode ser usado no Python, mas ainda leva muito tempo, ocorrem erros, o código nem sempre é óbvio e nem sempre é claro como otimizá-lo.
- Usando o Numba, que faz uma compilação JIT .
Mas talvez haja uma maneira melhor, e acho que essa é a
Julia .
Julia
Os criadores afirmam que esta é uma linguagem
rápida , de
alto nível e
flexível , comparável ao Python em termos de facilidade de escrever código. Na minha opinião, Julia é como uma
linguagem de script: você não precisa fazer o que precisa em C, onde tudo é de nível muito baixo, incluindo estruturas de dados. Ao mesmo tempo, você pode trabalhar em um console comum, como o Python e outras linguagens.
Julia usa a
compilação Just-In-Time - este é um dos elementos que dá velocidade. Mas a linguagem é boa nos cálculos, porque foi desenvolvida para eles. Julia é usada para tarefas científicas e obtém um desempenho decente.
Embora Julia esteja tentando parecer uma linguagem de uso geral, Julia é boa para computação e não muito boa para serviços da Web. Usar Julia em vez de Django, por exemplo, não é a melhor escolha.
Vejamos os recursos da linguagem como um exemplo de função primitiva.
function f(x) α = 1 + 2x end julia> methods(f)
Quatro recursos são visíveis neste código.
- Praticamente não há restrições ao uso do Unicode . Você pode usar fórmulas de um artigo sobre aprendizado profundo ou modelagem numérica, reescrever com os mesmos caracteres e tudo funcionará - o Unicode é costurado em quase todos os lugares.
- Não há sinal de multiplicação. No entanto, nem sempre é possível ficar sem ele, por exemplo, em 2.x (um número de ponto flutuante vezes x) que Julia jurará.
- Sem
return . Em geral, é recomendável que você escreva return para poder ver o que está acontecendo, mas o exemplo retornará α , porque a atribuição é uma expressão. - Sem tipos . Parece que, se houver velocidade, em algum momento os tipos devem aparecer? Sim, eles aparecerão, mas depois.
Julia possui três recursos que oferecem flexibilidade e velocidade:
despacho múltiplo, metaprogramação e paralelismo . Falaremos sobre os dois primeiros e deixaremos o paralelismo para estudo independente para usuários avançados.
Programação múltipla
A chamada para os
methods(f) no exemplo acima parece inesperada - que tipo de métodos a função possui? Estamos acostumados ao fato de termos objetos de classe, classes têm métodos. Mas em Julia tudo é invertido: funções têm métodos, porque a linguagem usa múltiplos despachos.
O planejamento múltiplo significa que a variante de uma função específica que será executada é determinada por todo o conjunto de tipos de parâmetros dessa função.
Descreverei brevemente como isso funciona em um exemplo já familiar.
function f(x) α = 1 + 2x end function f(x::AbstractFloat) α = 1 + sin(x) end julia> methods(f)
Variantes da mesma função para diferentes conjuntos de tipos são chamadas de métodos. Existem dois no código: o primeiro para todos os números de ponto flutuante e o segundo para todo o resto. Quando chamamos a função pela primeira vez, Julia decide qual método usar e se deve compilá-lo. Se já tiver sido chamado e compilado, será usado o que é.
Como em Julia nem tudo está do jeito que estamos acostumados, aqui você pode adicionar funções aos tipos de usuário, mas esses não serão métodos de tipo no sentido de POO. Simplesmente será o campo em que a função é gravada, porque a
função é o mesmo objeto completo que todo o resto.
Para descobrir o que exatamente será acionado, existem macros especiais. Eles começam com
@ . No exemplo, a macro
@which permite descobrir qual método foi chamado para um caso específico.

No primeiro caso, Julia decidiu que, como 2 é um número inteiro, ele não se encaixa no
AbstractFloat e chama a primeira opção. No segundo caso, ela decidiu que era o
Float e já havia pedido uma versão especializada. Aproximadamente, isso funcionará se você adicionar outros métodos para alguns tipos específicos.
LLVM e JIT
Julia usa a estrutura LLVM para compilar. A biblioteca de compilação JIT vem em um pacote de idiomas. Na primeira vez que a função é chamada, Julia procura ver se a função foi usada com esse conjunto de tipos e a compila, se necessário. O primeiro lançamento levará algum tempo e tudo funcionará rapidamente.
A função será compilada no momento da primeira chamada para este conjunto de parâmetros.
Recursos do compilador
- O compilador é razoavelmente razoável porque o LLVM é um bom produto.
- Os desenvolvedores mais avançados podem analisar o processo de compilação e ver o que ele gera.
- A compilação de Julia e Numba é semelhante . No Numba, você também cria um decorador JIT, mas no Numba você não pode "entrar" tanto e decidir o que otimizar ou alterar.
Para ilustrar o trabalho do compilador, darei um exemplo de uma função simples:
function f(x) α = 1 + 3x end julia> @code_llvm f(2) define i64 @julia_f_35897(i64) { top: %1 = mul i64 %0, 3 %2 = add i64 %1, 1 ret i64 %2 }
A macro
@code_llvm permite que você veja o resultado da geração. Esse
IR LLVM é
uma representação intermediária , um tipo de montador.
No código, o argumento da função é multiplicado por 3, 1 é adicionado ao resultado e o resultado é retornado. Tudo é o mais direto possível. Se você definir a função de maneira um pouco diferente, por exemplo, substitua 3 por 2, tudo mudará.
function f(x) α = 1 + 2x end julia> @code_llvm f(2) define i64 @julia_f_35894(i64) { top: %1 = shl i64 %0, 1 %2 = or i64 %1, 1 ret i64 %2 }
Parece, qual é a diferença: 2, 3, 10? Mas Julia e LLVM vêem que quando você chama uma função para um número inteiro, você pode ser um pouco mais inteligente. Multiplicar por um número inteiro é um deslocamento para a esquerda em um bit - é mais rápido que o produto. Mas, é claro, isso funciona apenas para números inteiros, não funcionará para deslocar
Float esquerda em 1 bit e obter o resultado da multiplicação por 2.
Tipos personalizados
Os tipos personalizados em Julia são tão rápidos quanto os tipos internos. A programação múltipla é executada neles e será tão rápida quanto para os tipos internos. Nesse sentido, o mecanismo de despacho múltiplo está profundamente incorporado à linguagem.
É lógico esperar que as variáveis não tenham tipos, apenas os valores os tenham. Variáveis sem um tipo são apenas um marcador, um rótulo em algum contêiner.
O sistema de tipos é hierárquico. Não podemos criar descendentes de tipos concretos; os tipos abstratos podem apenas tê-los. No entanto, tipos abstratos não podem ser instanciados. Essa nuance não vai agradar a todos.
Como os autores da linguagem explicaram quando desenvolveram Julia, eles queriam obter o resultado e, se algo era difícil de fazer, eles recusavam. Um sistema desse tipo hierárquico foi mais fácil de desenvolver. Este não é um problema catastrófico, mas se você não virar a cabeça do avesso, será inconveniente.
Os tipos podem ser parametrizados , um pouco como o C / C ++. Por exemplo, podemos ter uma estrutura dentro da qual existem campos, mas os tipos desses campos não são especificados - esses são parâmetros. Nós especificamos um tipo específico na instanciação.
Na maioria dos casos, os tipos podem ser ignorados . Geralmente eles são necessários quando o tipo ajuda o compilador a adivinhar a melhor forma de compilar. Nesse caso, os tipos são melhores para especificar. Você também precisa especificar tipos se quiser obter melhor desempenho.
Vamos ver o que é possível e o que não pode ser instanciado.

O primeiro tipo de
AbstractPoint não pode ser instanciado. Este é apenas um pai comum para todos que podemos especificar nos métodos, por exemplo. A segunda linha diz que o
PlanarPoint{T} é um descendente desse ponto abstrato. Abaixo os campos começam - aqui você pode ver a parametrização. Você pode colocar um
float ,
int ou outro tipo aqui.
O primeiro tipo não pode ser instanciado e, por todo o resto, é impossível criar descendentes. Além disso, por padrão eles são
imutáveis . Para poder alterar os campos, isso deve ser especificado explicitamente.
Quando tudo estiver pronto, você pode continuar, por exemplo, calcular a distância para diferentes tipos de pontos. No exemplo, o primeiro ponto no plano é
PlanarPoint , depois na esfera e no cilindro. Dependendo dos dois pontos em que calculamos a distância, precisamos usar métodos diferentes. Em geral, a função terá esta aparência:
function describe(p::AbstractPoint) println("Point instance: $p") end
Para
Float64 ,
Float32 ,
Float16 , será:
function distance(pf::PlanarPoint{T}, ps::PlanarPoint{T}) where T<:AbstractFloat sqrt((pf.x-ps.x)^2 + (pf.y-ps.y)^2) end
E para números inteiros, o método de cálculo da distância terá a seguinte aparência:
function distance(pf::PlanarPoint{T}, ps::PlanarPoint{T}) where T<:Integer abs(pf.x-ps.x) + abs(pf.y-ps.y) end
Para pontos de cada tipo, métodos diferentes serão chamados.
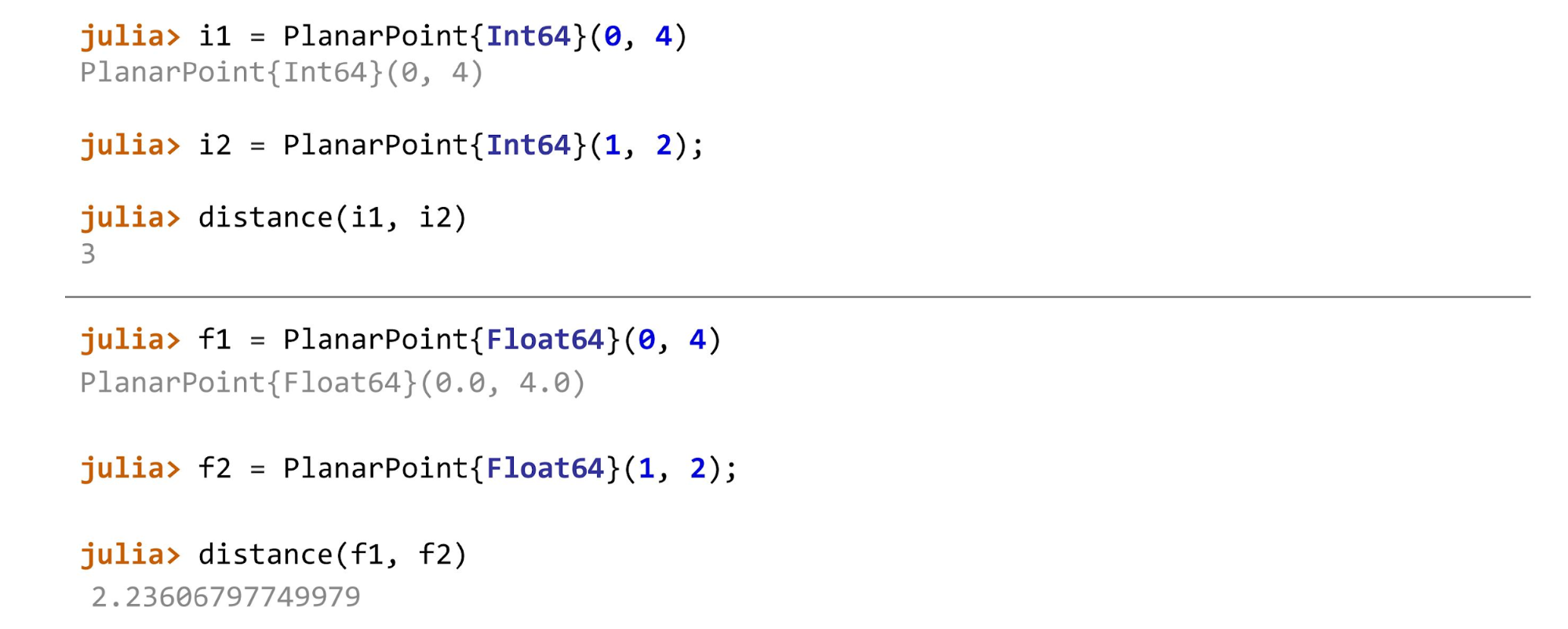
Se você trapaceia e, por exemplo, aplica
distance(f1, i2) , Julia jura: “Eu não conheço esse método! Você me perguntou esses métodos e disse que ambos são do mesmo tipo. Você não me contou como contar isso quando um parâmetro é
float e o outro é
int . "
Velocidade
Você já deve ter se encantado: “Existe uma compilação JIT: escrever é fácil, funciona rapidamente. Jogue fora o Python e comece a escrever em Julia!
Mas não é tão simples. Nem todos os recursos de Julia serão rápidos. Depende de dois fatores.
- Do desenvolvedor . Não há idiomas nos quais qualquer função seja rápida. Um desenvolvedor inexperiente até escreverá código em C que funcionará muito mais lentamente que o código Python de um desenvolvedor experiente. Qualquer idioma tem seus próprios truques e nuances, dos quais o desempenho depende. O compilador, seja ele estático regular ou JIT, não pode fornecer todas as opções possíveis e otimizar tudo.
- Da estabilidade do tipo . Em uma versão mais rápida, funções que são estáveis por tipo serão compiladas.
Estabilidade de tipo
O que é estabilidade de tipo? Quando o compilador não consegue adivinhar suficientemente o que acontece com os tipos, ele precisa gerar muito código de wrapper para que tudo que chegue à entrada funcione.
Um exemplo simples para entender a estabilidade do tipo.

Os especialistas em aprendizado de máquina dirão que essa é uma ativação relu normal: se x> 0, retorne como está, caso contrário, retorne zero. Um problema é o zero após o número inteiro do ponto de interrogação. Isso significa que, se chamarmos essa função para um número de ponto flutuante, em um caso, o número de ponto flutuante será retornado e, no outro, o número inteiro.
O compilador não pode adivinhar o tipo de resultado apenas pelo argumento do tipo de função. Ele também precisa saber o significado. Portanto, gera muito código.
Em seguida, criamos uma matriz de 100 por 100 números aleatórios de 0 a 1, deslocamos 0,5 para distribuir uniformemente números positivos e negativos e medimos o resultado. Existem dois pontos interessantes: o ponto e a função. O ponto após
rand(100,100) significa "aplicar a cada elemento". Se você tem algum tipo de coleção e função escalar, você acaba com ele e Julia faz o resto. Podemos assumir que isso é tão eficaz quanto um loop normal em uma linguagem compilada normal. Não há necessidade de escrever - tudo será feito para você.
Não há problemas no momento - o
problema está dentro da própria função . O tempo estimado de execução dessa opção em um computador decente para essa matriz é de microssegundos. Mas, na realidade - milissegundos, o que é demais para uma matriz tão pequena.
Mude apenas uma linha.

A função
zero(x) executada gera um zero do mesmo tipo que o argumento
(x) . Isso significa que, independentemente do valor de
x , o tipo de resultado sempre será conhecido pelo tipo de
x .
Quando analisamos apenas o tipo de argumento e já sabemos o tipo de resultado, essas são funções que são do tipo estável.
Se precisarmos examinar o significado dos argumentos, essas não são funções estáveis.
Quando o compilador pode otimizar o código, a diferença no tempo de execução é obtida por duas ordens de magnitude. No segundo exemplo, ele foi alocado apenas exatamente para uma nova matriz, mais algumas dezenas de bytes e nada mais. Esta opção é muito mais eficaz que a anterior.
Esta é a principal coisa a observar quando escrevemos código em Julia. Se você escrever como em Python, funcionará como em Python. Se você executar as mesmas operações no NumPy, zero com ou sem um ponto não desempenhará um papel. Mas em Julia, isso pode prejudicar muito o desempenho.
Felizmente, existe um método para descobrir se existe um problema. Essa é a macro
@code_warntype , que permite descobrir se o compilador pode adivinhar onde estão os tipos e otimizar se tudo estiver bem.

Na primeira opção (esquerda), o compilador não tem certeza do tipo e o exibe em vermelho. No segundo caso, sempre haverá
Float64 para esse argumento, para que você possa gerar um código muito mais curto.
Isso ainda não é LLVM, mas o código Julia rotulado,
return 0 ou
return 0.0 fornece uma diferença de desempenho de duas ordens de magnitude.
Metaprogramação
A metaprogramação é quando criamos programas em um programa e os executamos em qualquer lugar.
Este é um método poderoso que permite fazer várias coisas interessantes. Um exemplo clássico é o Django ORM, que cria campos usando metaclasses.
Muitas pessoas conhecem o aviso de
Tim Peters , autor do Zen of Python:
“Metaclasses são uma mágica mais profunda com a qual 99% dos usuários nunca devem se preocupar. Se você está se perguntando se são necessárias metaclasses no Python, não precisa delas. Se você precisar deles, sabe exatamente por que e como usá-los. ”
Com a metaprogramação, a situação é semelhante, mas em Julia é costurada muito mais profundamente, essa é uma característica importante de toda a linguagem. O código Julia é a mesma estrutura de dados que qualquer outro, você pode manipular, combinar, criar expressões e tudo isso funcionará.
julia> x = 4; julia> typeof(:(x+1)) Expr julia> expr = :(x+1) :(x + 1) julia> expr.head :call julia> expr.args 3-element Array{Any,1}: :+ :x 1
As macros são uma das ferramentas de metaprogramação em Julia : damos a elas algo, elas parecem, adicionam a correta, removem o desnecessário e dão o resultado. Em todos os exemplos anteriores, passamos a chamada para a função e a macro interna analisou a chamada. Tudo isso acontece no nível do trabalho com a árvore de sintaxe.
Você pode analisar expressões muito simples: se for, por exemplo,
(x+1) , será uma chamada para a função
+ (a adição não é um operador, como em muitos outros idiomas, mas uma função) e dois argumentos: um caractere (dois pontos significa que é um caractere ) e o segundo é apenas uma constante.
Outro exemplo simples de macro:
macro named(name, expr) println("Starting $name") return quote $(esc(expr)) end end julia> @named "some process" x=5; Starting some process julia> x 5
Usando macros, por exemplo, indicadores ou filtros de progresso para quadros de dados são criados - esse é um mecanismo comum em Julia.
As macros não são executadas no momento da chamada, mas ao analisar o código.
Este é o principal recurso de macro em Julia. - , . , , .
,
Julia — . .
- Julia . .
- , . , , C .
- Julia JIT- . , , , , .
- — . .
- ( ). , . , , .
- Julia — .
Ecossistema
, , Julia . , , data science , , , Python. , Python Pandas, , , , Julia .
Julia , Python 2008 . Python, , Julia. , . , Julia.
( ) Python Julia
. Julia: , , .…
. .
- DataFrames.jl .
- JuliaDB , .
- Query.jl . Pandas — - , ..
Plotting .
Matplotlib , Julia. :
VegaLite.jl ,
Plots.jl , ,
Gadfly.jl .
.
TensorFlow , Flux.jl. Flux , , , Keras TensorFlow, . .
Scikit-learn . , , sklearn, , .
XGBoost . , Julia .
?
Jupyter . IDE — Juno, Visual Studio, .
. GPU/TPU . CUDAnative.jl Julia . Julia-, - , . , , , , .
: C, Fortran, Python .
, .
Packaging : Julia: , , ..
, , . , , . ,
PyTorch , TensorFlow, , .
, , , . Julia, , , . ,
,
Zygote.jl . Flux.jl.
julia> using Zygote julia> φ(x) = x*sin(x) julia> Zygote.gradient(φ, π/2.) (1.0,) julia> model = Chain(Dense(768, 128, relu), Dense(128, 10), softmax) julia> loss(x, y) = crossentropy(model(x), y) + sum(norm, params(model)) julia> optimizer = ADAM(0.001) julia> Flux.train!(loss, params(model), data, optimizer) julia> model = Chain(x -> sqrt(x), x->x-1)
φ , , , .
Zygote «source-to-source»: , , .
differentiable programming — — backpropagation , .
Julia : «source-to-source» , . , .
Julia ?
, — . .
- , , , — .
, , .
Julia , .
- , , . Julia «» .
- , API, , .
Moscow Python Conf++ , 27 , Python Julia. , , telegram- MoscowPython.