Desenvolvemos um design de uma rede de data centers, que permite implantar clusters de computação com mais de 100 mil servidores com uma largura de banda de bissecção de mais de um petabit por segundo.
No relatório de Dmitry Afanasyev, você aprenderá sobre os princípios básicos do novo design, dimensionamento de topologias que surgem com esses problemas, soluções para eles, sobre os recursos de roteamento e dimensionamento das funções do plano de encaminhamento de dispositivos de rede modernos em dispositivos de rede modernos em topologias "densamente conectadas" com um grande número de rotas ECMP . Além disso, Dima falou brevemente sobre a organização da conectividade externa, o nível físico, o sistema de cabos e maneiras de aumentar ainda mais a capacidade.

Boa tarde a todos! Meu nome é Dmitry Afanasyev, sou arquiteto de redes da Yandex e lida principalmente com o design de redes de data center.

Minha história será sobre a rede atualizada do data center Yandex. Isso é basicamente uma evolução do design que tínhamos, mas ao mesmo tempo existem alguns elementos novos. Esta é uma apresentação de revisão, uma vez que era necessário reunir muitas informações em pouco tempo. Começamos escolhendo uma topologia lógica. Depois, haverá uma visão geral do plano de controle e os problemas com a escalabilidade do plano de dados, a escolha do que acontecerá no nível físico, vejamos alguns recursos dos dispositivos. Também abordaremos o que está acontecendo no data center com o MPLS, sobre o qual falamos há algum tempo.

Então, o que é o Yandex em termos de cargas de trabalho e serviços? Yandex é um hiperscaler típico. Se você olhar na direção dos usuários, processamos principalmente solicitações de usuários. Além disso, vários serviços de streaming e saída de dados, porque também temos serviços de armazenamento. Se estiver mais próximo do back-end, as cargas e os serviços de infraestrutura aparecerão, como armazenamentos de objetos distribuídos, replicação de dados e, é claro, filas persistentes. Um dos principais tipos de cargas é o MapReduce e similares, processamento de streaming, aprendizado de máquina etc.

Como está a infraestrutura em cima da qual tudo isso acontece? Novamente, somos um hiperskaler muito típico, embora talvez estejamos um pouco mais perto do lado do espectro onde os hiperskalers menores estão localizados. Mas temos todos os atributos. Utilizamos hardware comum e escala horizontal sempre que possível. Temos um crescimento total do pool de recursos: não trabalhamos com máquinas separadas, racks separados, mas as combinamos em um grande pool de recursos intercambiáveis com alguns serviços adicionais envolvidos no planejamento e alocação, e trabalhamos com todo esse pool.
Portanto, temos o próximo nível - o cluster de computação no nível do sistema operacional. É muito importante que controlemos completamente a pilha de tecnologia que usamos. Controlamos pontos finais (hosts), rede e pilha de software.
Temos vários grandes centros de dados na Rússia e no exterior. Eles são unidos por um backbone usando a tecnologia MPLS. Nossa infraestrutura interna é quase toda baseada em IPv6, mas como precisamos lidar com o tráfego externo, que ainda é entregue principalmente via IPv4, precisamos entregar as solicitações que chegam via IPv4 aos servidores front-end e ainda vamos um pouco ao IPv4 externo. Internet - por exemplo, para indexação.
As últimas iterações do design de rede do datacenter usam topologias Clos de vários níveis e apenas L3 é usado nelas. Saímos de L2 há algum tempo e respiramos aliviados. Por fim, nossa infraestrutura inclui centenas de milhares de instâncias de computação (servidor). O tamanho máximo do cluster há algum tempo era de cerca de 10 mil servidores. Isso se deve em grande parte à maneira como os mesmos sistemas operacionais em nível de cluster - agendadores, alocação de recursos etc. - Como o progresso ocorreu no lado do software de infraestrutura, agora o destino é de cerca de 100 mil servidores em um cluster de computação e tivemos uma tarefa - poder construir fábricas de rede que permitissem um pool eficiente de recursos nesse cluster.

O que queremos de uma rede de data center? Primeiro de tudo - muita largura de banda barata e uniformemente distribuída. Porque a rede é aquele substrato através do qual podemos fazer o pool de recursos. O novo tamanho de destino é de cerca de 100 mil servidores em um cluster.
Além disso, é claro, queremos um plano de controle escalável e estável, porque em uma infraestrutura tão grande surgem muitas dores de cabeça, mesmo a partir de eventos aleatórios, e não queremos que o plano de controle nos cause dor de cabeça. Ao mesmo tempo, queremos minimizar o estado nele. Quanto menor a condição, melhor e mais estável tudo funciona, mais fácil é diagnosticar.
Obviamente, precisamos de automação, porque é impossível gerenciar essa infraestrutura manualmente, e isso era impossível há algum tempo. Sempre que possível, precisamos de suporte operacional e de CI / CD, na medida do possível.
Com esses tamanhos de datacenters e clusters, a tarefa de oferecer suporte à implantação e expansão incrementais sem interrupção do serviço tornou-se bastante aguda. Se em clusters o tamanho de mil carros é provavelmente próximo a dez mil máquinas, eles ainda podem ser implementados como uma operação - ou seja, estamos planejando expandir a infraestrutura e vários milhares de máquinas são adicionados como uma operação, e um cluster do tamanho de cem mil carros não assim, ele foi construído por algum tempo. E é desejável que todo esse tempo o que já foi divulgado, a infraestrutura implantada, esteja disponível.
E um requisito que tínhamos e deixamos: o suporte à multilocação, ou seja, virtualização ou segmentação de rede. Agora, não precisamos fazer isso no nível da fábrica de rede, porque a segmentação foi para os hosts, e isso facilitou muito o dimensionamento. Graças ao IPv6 e a um grande espaço de endereço, não precisamos usar endereços duplicados na infraestrutura interna, todo o endereçamento já era exclusivo. E devido ao fato de levarmos a filtragem e a segmentação de rede para os hosts, não precisamos criar nenhuma entidade de rede virtual nas redes do data center.

Uma coisa muito importante é que não precisamos. Se algumas funções puderem ser removidas da rede, isso simplifica muito a vida e, via de regra, expande a escolha do hardware e software disponível e simplifica muito o diagnóstico.
Então, do que não precisamos, do que fomos capazes de recusar, nem sempre com alegria no momento em que isso aconteceu, mas com grande alívio quando o processo foi concluído?
Primeiro de tudo, a rejeição de L2. Não precisamos de L2 real ou emulado. Não é utilizado em grande parte devido ao fato de controlarmos a pilha de aplicativos. Nossos aplicativos são dimensionados horizontalmente, trabalham com endereçamento L3, não se preocupam com o fato de uma instância específica estar desativada, apenas lançam uma nova, não precisam ser lançadas no endereço antigo, porque existe um nível separado de descoberta de serviço e monitoramento de máquinas localizadas no cluster . Não transferimos essa tarefa para a rede. A tarefa da rede é entregar pacotes do ponto A ao ponto B.
Além disso, não temos situações em que endereços se movam dentro da rede, e isso precisa ser monitorado. Em muitos projetos, isso geralmente é necessário para dar suporte à mobilidade da VM. Não usamos a mobilidade de máquinas virtuais na infraestrutura interna exatamente do grande Yandex e, além disso, acreditamos que, mesmo que isso seja feito, isso não deve acontecer com o suporte de rede. Se você realmente precisar fazer isso, precisará fazer isso no nível do host e direcionar os endereços que podem ser migrados para sobreposições para não tocar ou fazer muitas alterações dinâmicas no subjacente do próprio sistema de roteamento (rede de transporte).
Outra tecnologia que não usamos é o multicast. Eu posso lhe dizer em detalhes o porquê. Isso facilita muito a vida, porque se alguém lida com ele e observa como é exatamente o plano de controle de um multicast - em todas as instalações, exceto a mais simples, é uma grande dor de cabeça. Além disso, é difícil encontrar uma implementação de código aberto que funcione bem, por exemplo.
Por fim, projetamos nossas redes para que elas não tenham muitas mudanças. Podemos contar com o fato de que o fluxo de eventos externos no sistema de roteamento é pequeno.

Quais problemas surgem e quais limitações devem ser levadas em consideração quando desenvolvemos uma rede de data center? Custo do curso. Escalabilidade, em que nível queremos crescer. A necessidade de expansão sem interromper o serviço. Disponibilidade de largura de banda. A visibilidade do que está acontecendo na rede, para sistemas de monitoramento, para equipes operacionais. O suporte à automação é, novamente, o máximo possível, pois tarefas diferentes podem ser resolvidas em diferentes níveis, incluindo a introdução de camadas adicionais. Bem e não - sempre que possível - dependência de fornecedores. Embora em períodos históricos diferentes, dependendo de qual seção examinar, essa independência foi mais fácil ou mais difícil de alcançar. Se pegarmos uma fatia dos chips de dispositivos de rede, até recentemente, falaremos sobre independência dos fornecedores; se também desejássemos chips com alto rendimento, isso poderia ser muito arbitrário.

Que topologia lógica usaremos para construir nossa rede? Este será um Clos de vários níveis. De fato, atualmente não há alternativas reais. E a topologia Clos é boa o suficiente, mesmo se a compararmos com várias topologias avançadas que agora estão mais na esfera do interesse acadêmico, se tivermos comutadores com uma grande raiz.
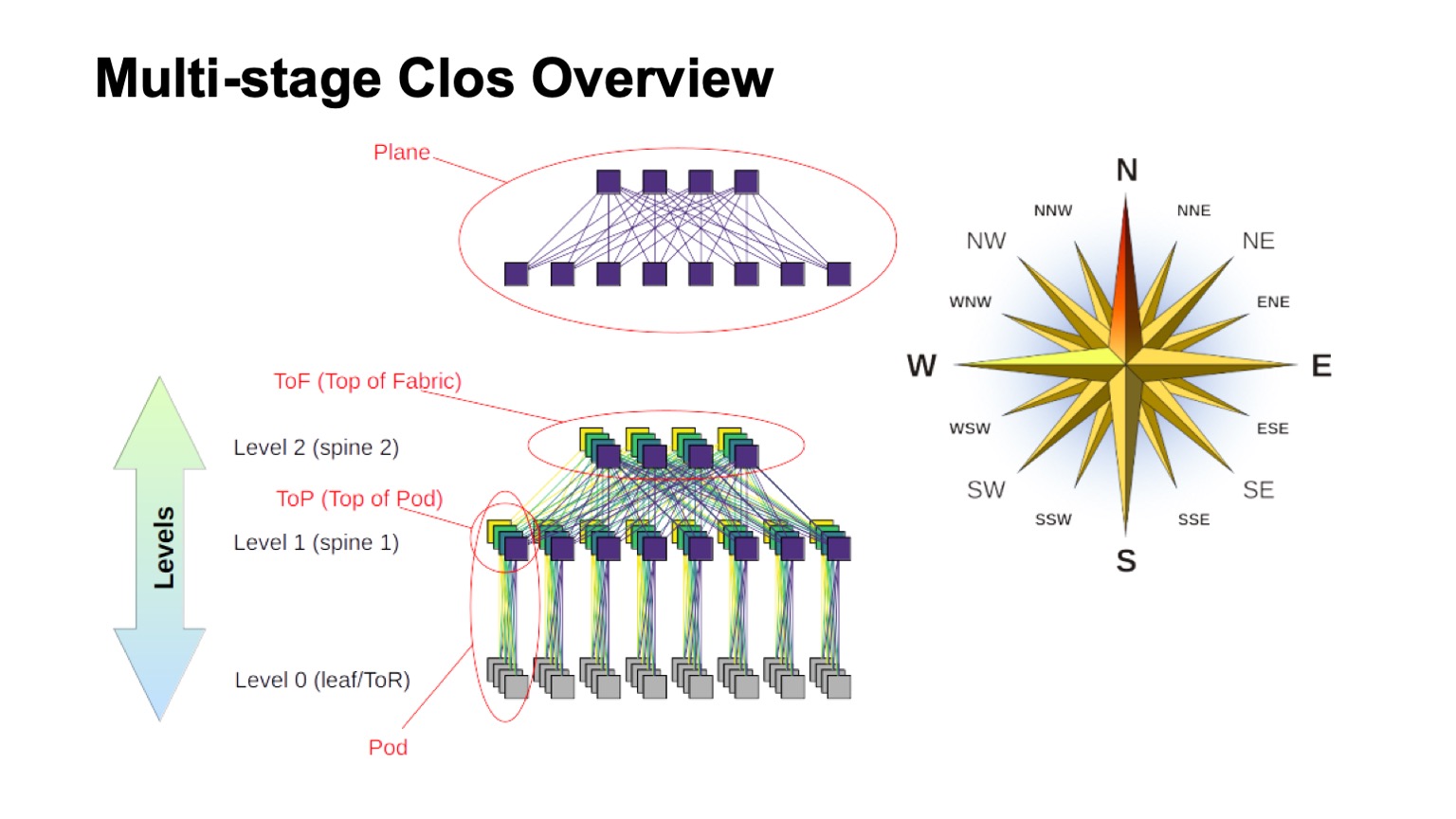
Como a rede Clos em camadas é aproximadamente estruturada e como são chamados os diferentes elementos nela? Primeiro de tudo, o vento aumentou, para descobrir onde o norte, onde o sul, onde o leste, onde o oeste. Redes desse tipo geralmente são construídas por aqueles que têm um tráfego muito grande oeste - leste. Quanto ao restante dos elementos, um comutador virtual montado a partir de comutadores menores é mostrado na parte superior. Essa é a idéia básica de criar recursivamente redes Clos. Pegamos elementos com algum tipo de raiz e os conectamos para que o que aconteceu possa ser considerado como um interruptor com uma raiz maior. Se você precisar ainda mais, o procedimento pode ser repetido.
Nos casos, por exemplo, no Clos de dois níveis, quando é possível distinguir claramente os componentes verticais no meu diagrama, eles geralmente são chamados de planos. Se construímos o Clos com três níveis de spine switches (todos que não são limítrofes e nem ToR-switches e que são usados apenas para trânsito), os aviões pareceriam mais complicados, os dois níveis seriam assim. O bloco de ToR ou interruptores de folha e os interruptores associados da coluna de primeiro nível que chamamos de Pod. Os interruptores de nível 1 da coluna na parte superior do Pod são a parte superior do Pod, a parte superior do Pod. Os comutadores localizados na parte superior de toda a fábrica são a camada superior da fábrica, a parte superior do tecido.

Obviamente, surge a pergunta: as redes Clos foram criadas há algum tempo, a idéia em si geralmente vem dos dias da telefonia clássica, das redes TDM. Talvez algo melhor apareceu, talvez você possa fazer algo melhor de alguma forma? Sim e não Teoricamente, sim, na prática, em um futuro próximo, definitivamente não. Como existem várias topologias interessantes, algumas delas são usadas até na produção, por exemplo, o Dragonfly é usado em aplicativos HPC; Também existem topologias interessantes, como Xpander, FatClique, Jellyfish. Se você olhar relatórios em conferências como SIGCOMM ou NSDI nos últimos tempos, poderá encontrar um número bastante grande de artigos sobre topologias alternativas que possuem melhores propriedades (uma ou outra) que Clos.
Mas todas essas topologias têm uma propriedade interessante. Isso impede sua implementação nas redes de data centers, que estamos tentando construir em hardware comum e que custam dinheiro razoavelmente razoável. Em todas essas topologias alternativas, infelizmente, a maioria da banda não é acessível pelos caminhos mais curtos. Portanto, perdemos imediatamente a capacidade de usar o plano de controle tradicional.
Teoricamente, a solução para o problema é conhecida. Essas são, por exemplo, modificações do estado do link usando o caminho mais curto k, mas, novamente, não há protocolos que seriam implementados na produção e disponíveis massivamente nos equipamentos.
Além disso, como a maior parte da capacidade não é acessível pelos caminhos mais curtos, precisamos modificar não apenas o plano de controle para selecionar todos esses caminhos (e, a propósito, esse é um estado muito maior no plano de controle). Ainda precisamos modificar o plano de encaminhamento e, em regra, são necessários pelo menos dois recursos adicionais. Esta é uma oportunidade para tomar todas as decisões sobre o encaminhamento de pacotes uma vez, por exemplo, em um host. Na verdade, esse é o roteamento de origem, às vezes na literatura sobre redes de interconexão é chamado de decisões de encaminhamento de uma vez. E o roteamento adaptável já é uma função que precisamos nos elementos da rede, que se resume, por exemplo, ao fato de selecionar o próximo salto com base em informações sobre a menor carga na fila. Como exemplo, outras opções são possíveis.
Portanto, a direção é interessante, mas, infelizmente, não podemos aplicá-la agora.

Ok, resolvemos a topologia lógica de Clos. Como vamos escalar isso? Vamos ver como funciona e o que pode ser feito.

Na rede Clos, existem dois parâmetros principais que podemos, de alguma forma, variar e obter certos resultados: elementos de base e o número de níveis na rede. Descrevo esquematicamente como um e outro afetam o tamanho. Idealmente, combinamos ambos.
Pode-se observar que a largura total da rede Clos é um produto de todos os níveis de comutadores da coluna do radix sul, quantos links temos, como ele se ramifica. É assim que dimensionamos o tamanho da rede.
Quanto à capacidade, especialmente nos switches ToR, existem duas opções de dimensionamento. Enquanto mantemos a topologia geral, podemos usar links mais rápidos ou podemos adicionar mais planos.
Se você olhar a versão detalhada da rede Clos (no canto inferior direito) e retornar a esta imagem com a rede Clos abaixo ...
... então essa é exatamente a mesma topologia, mas neste slide ela é recolhida de forma mais compacta e os planos de fábrica são sobrepostos. É um e o mesmo.

Como é o dimensionamento de uma rede Clos em números? Aqui eu tenho dados sobre qual a largura máxima que uma rede pode obter, qual o número máximo de racks, ToR-switches ou leaf-switches, se eles não estiverem em racks, podemos obter dependendo da quantidade de switches que usamos para espinhos níveis e quantos níveis usamos.
Ele mostra quantos racks podemos ter, quantos servidores e quanto tudo isso pode consumir à taxa de 20 kW por rack. Um pouco antes, mencionei que buscamos um tamanho de cluster de cerca de 100 mil servidores.
Pode-se observar que em toda essa construção duas opções e meia são de interesse. Existe uma opção com duas camadas de espinhos e comutadores de 64 portas, o que é um pouco curto. Em seguida, opções perfeitamente ajustadas para spine switches de 128 portas (com 128 radix) com dois níveis ou switches com um radix 32 com três níveis. E em todos os casos em que há mais radix e mais níveis, você pode criar uma rede muito grande, mas, se observar o consumo esperado, em regra, há gigawatts. Você pode colocar o cabo, mas é improvável que obtenhamos tanta eletricidade em um site. Se você olhar para estatísticas, dados públicos sobre data centers - muito poucos data centers podem ser encontrados para uma capacidade estimada de mais de 150 MW. Além disso, como regra, campus de data center, vários grandes data centers localizados bem próximos um do outro.
Há outro parâmetro importante. Se você olhar para a coluna da esquerda, a largura de banda utilizável é indicada lá. É fácil perceber que em uma rede Clos, uma parte significativa das portas é gasta na conexão dos comutadores entre si. Largura de banda utilizável é o que você pode distribuir para os servidores. Naturalmente, estou falando sobre portas condicionais e sobre a faixa. Como regra, os links dentro da rede são mais rápidos que os links para os servidores, mas por unidade de banda, na medida em que podemos distribuí-lo aos nossos equipamentos de servidor, ainda existem mais bandas na própria rede. E quanto mais níveis fizermos, maiores serão os custos unitários para fornecer essa faixa para o exterior.
Além disso, mesmo essa banda extra não é exatamente a mesma. Embora os vãos sejam curtos, podemos usar algo como DAC (cobre de conexão direta, ou seja, cabos twinax) ou óptica multimodo, que custa ainda mais ou menos dinheiro razoável. Assim que passamos a abranger de forma mais autentica - em regra, trata-se de óptica de modo único e o custo dessa banda adicional aumenta acentuadamente.
E, voltando ao slide anterior, se fizermos uma rede Clos sem precisar se inscrever novamente, será fácil olhar para o diagrama, ver como a rede é construída - adicionando cada nível de switches da coluna, repetimos toda a faixa abaixo. Nível positivo - mais a mesma banda, o mesmo número de portas nos comutadores que no nível anterior, o mesmo número de transceptores. Portanto, é muito desejável minimizar o número de níveis de comutadores da coluna.
Com base nesta imagem, é claro que realmente queremos construir algo como switches com um radix de 128.

Aqui, em princípio, tudo é o mesmo que acabei de dizer, é mais provável que esse slide seja considerado mais tarde.

, ? , - . , . , . , . , , , , . ( ), control plane , , , , . , , .
, , , SerDes- — - . forwarding . , , , , , Clos-, . .
, , . , , , , , , , , , .

— , . , , . , , , - , . , , , , .
, , , . -, , . , , 128 , .
, , , data plane. . , , . , , , . , , , , 128 , . . . .
, - , . ( ), , — ToR- leaf-, . - , , , , - . , , , - .

, , .

? . , , , : leaf-, 1, 2. , — twinax, multimode, single mode. , , , , , .
. , , multimode , , , 100- . , , , single mode , , single mode, - CWDM, single mode (PSM) , , , .
: , 100 425 . SFP28 , QSFP28 100 . multimode .
- , - , - - . , . , - Pods twinax- ( ).
, , , CWDM. .
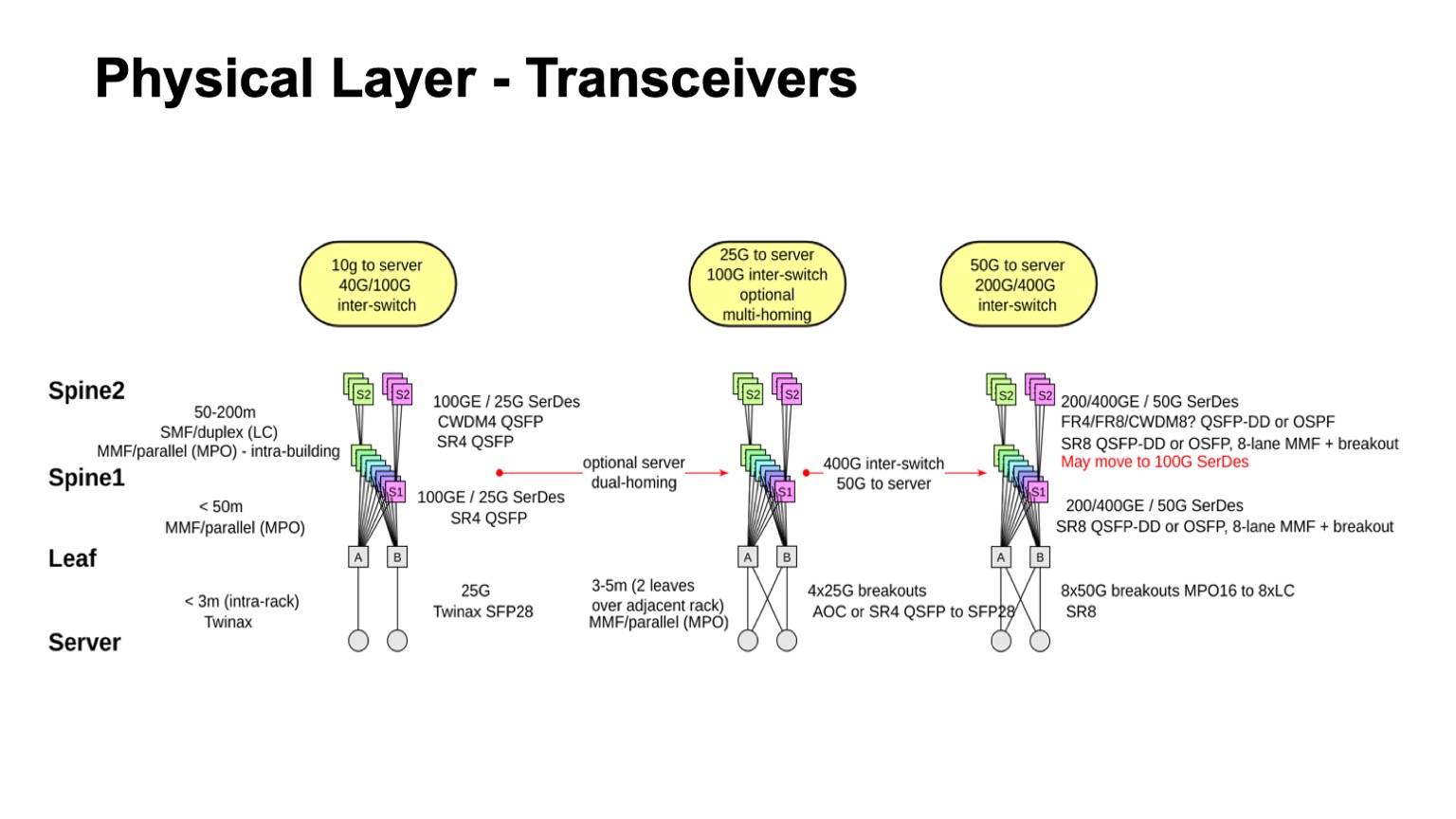
, , . , , 50- SerDes . , , 400G, 50G SerDes- , 100 Gbps per lane. , 50 100- SerDes 100 Gbps per lane, . , 50G SerDes , , , 100G SerDes . - , , .
. , 400- 200- 50G SerDes. , , , , , , . 128. , , , , .
, , . , , , , , 100- , .

— , . , . leaf- — , . , , — .
, , , -. , , - -, . . , , , . - -, -, , , , . : . - , « », Clos-, . , , .
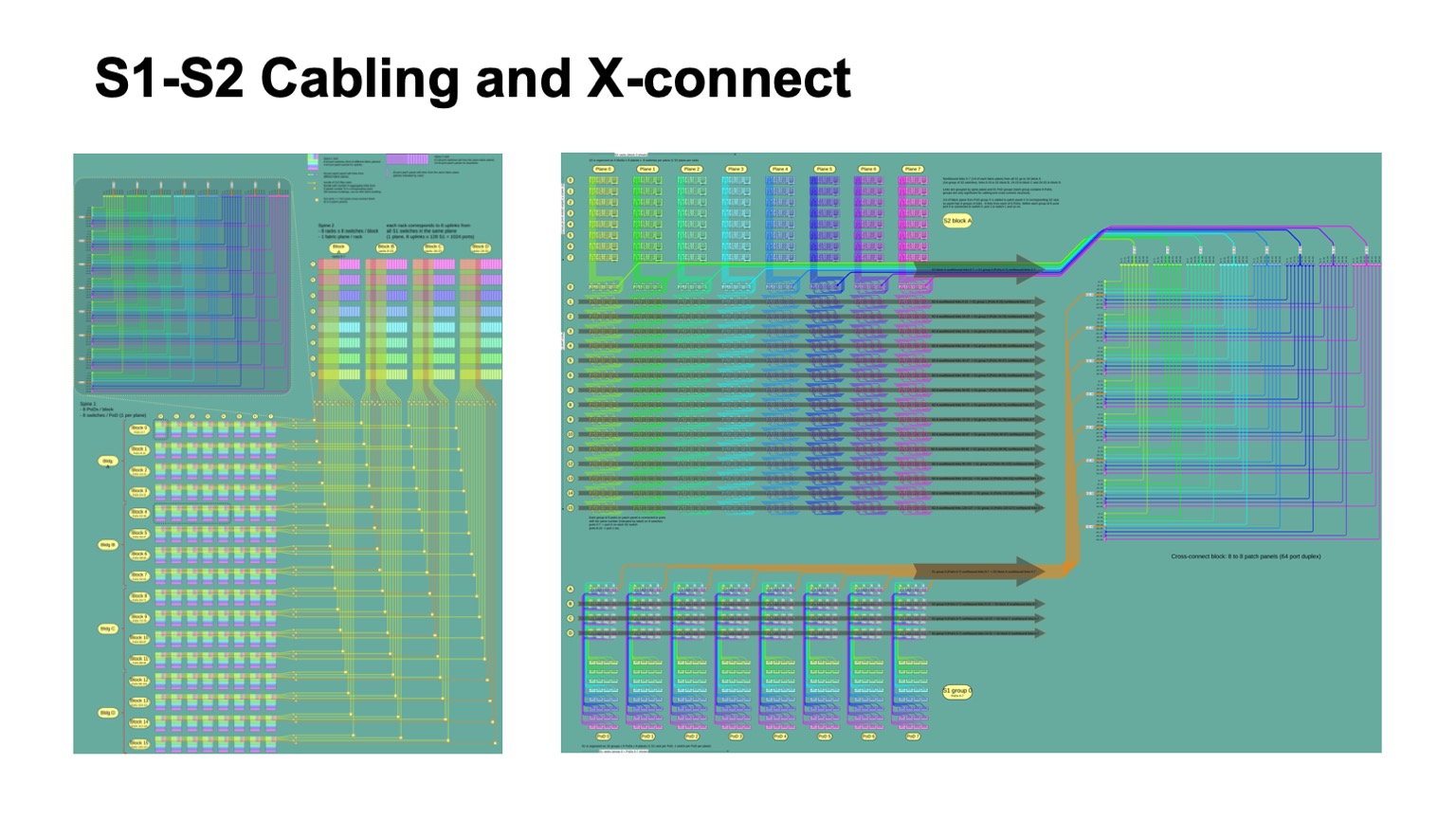
. - , , , , -2-.
. , - 512 512 , , , -2. Pods -1, -, -2.

Aqui está como fica. -2 () -. , . -, . , , .

: , . control plane-? , - , link state , , , , . , — , link state . , , , , fanout, control plane . link state .
— BGP. , RFC 7938 BGP -. : , , , path hunting. , , , valley free. , , , . , , . . .
, , BGP. eBGP, link local, : ToR, -1- Pod, Top of Fabric. , BGP , .

, , , , control plane. L3 , , . — , , , multi-path, multi-path , , , . , , , , , . , multi-path, ToR-.

, , — . , , , , BGP, . , corner cases , BGP .
RIFT, .

— , data plane , . : ECMP , Next Hop.
, , Clos- , , , , , . , ECMP, single path-. . , Clos- , Top of fabric, , . , , . , ECMP state.
data plane ? LPM (longest prefix match), , 100 . Next Hop , , 2-4 . , Next Hops ( adjacencies), - 16 64. . : MPLS -? , .

. , . white boxes MPLS. MPLS, , , , ECMP. E aqui está o porquê.

ECMP- IP. Next Hops ( adjacencies, -). , -, Next Hop. IP , , Next Hops.

MPLS , . Next Hops . , , .
, 4000 ToR-, — 64 ECMP, -1 -2. , , ECMP-, ToR , Next Hops.

, Segment Routing . Next Hops. wild card: . , .
, - . ? Clos- . , Top of fabric. . , , Top of fabric, , , . , , , , .
— . , Clos- , , , ToR, Top of fabric , . Pod, Edge Pod, .
. , , Facebook. Fabric Aggregator HGRID. -, -. , . , touch points, . , , -. , - , , . , , . overlays, .

? — CI/CD-. , , , . , , . , , .
, . . — .
. , RIFT. congestion control , , , , RDMA .
, , , , overhead. — HPC Cray Slingshot, commodity Ethernet, . overhead .

, , . — . — . - scale out — . , . . Obrigada