Oi
Você costuma ver comentários tóxicos nas redes sociais? Provavelmente depende do conteúdo que você está assistindo. Proponho experimentar um pouco sobre esse tópico e ensinar a rede neural a determinar os comentários mais odiosos.
Portanto, nosso objetivo global é determinar se um comentário é agressivo, ou seja, estamos lidando com classificação binária. Escreveremos uma rede neural simples, treinamos em um conjunto de dados de comentários de diferentes redes sociais e, em seguida, faremos uma análise simples com visualização.
Para o trabalho, usarei o Google Colab. Este serviço permite que você execute Jupyter Notebooks e tenha acesso à GPU (NVidia Tesla K80) gratuitamente, o que acelerará o aprendizado. Vou precisar do back-end TensorFlow, a versão padrão no Colab 1.15.0, então atualize para o 2.0.0.
Nós importamos o módulo e atualizamos.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
Você pode ver a versão atual assim.
print(tf.__version__)
Concluído o trabalho preparatório, importamos todos os módulos necessários.
import os import numpy as np
Descrição das bibliotecas usadas
- os - para trabalhar com o sistema de arquivos
- numpy - para trabalhar com matrizes
- pandas - uma biblioteca para análise de dados tabulares
- keras - para construir um modelo
- keras.preprocessing.Text - para processamento de texto, para enviá-lo em formato numérico para treinar uma rede neural
- sklearn.train_test_split - para separar dados de teste do treinamento
- matplotlib - para visualizar o processo de aprendizagem
- sklearn.normalize - para normalizar dados de teste e treinamento
Analisando dados com o Kaggle
Carrego dados diretamente no próprio laptop da Colab. Além disso, sem problemas, eu já os estou extraindo.
path = 'labeled.csv' df = pd.read_csv(path) df.head()
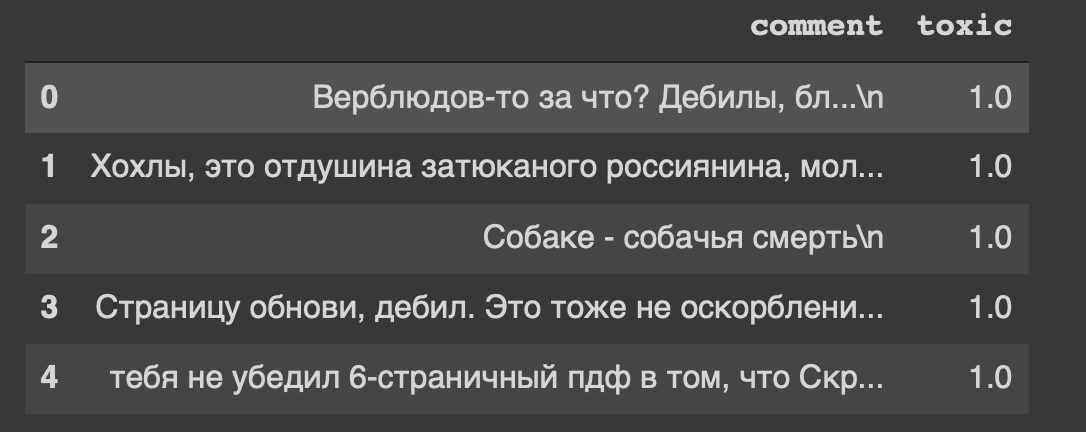
E este é o cabeçalho do nosso conjunto de dados ... Eu também me sinto desconfortável com a "atualização da página, idiota".
Portanto, nossos dados estão na tabela, dividiremos em duas partes: dados para treinamento e para o modelo de teste. Mas isso é tudo texto, algo precisa ser feito.
Processamento de dados
Remova os caracteres de nova linha do texto.
def delete_new_line_symbols(text): text = text.replace('\n', ' ') return text
df['comment'] = df['comment'].apply(delete_new_line_symbols) df.head()
Os comentários têm um tipo de dados real, precisamos convertê-los em um número inteiro. Em seguida, salve-o em uma variável separada.
target = np.array(df['toxic'].astype('uint8')) target[:5]
Agora, processaremos um pouco o texto usando a classe Tokenizer. Vamos escrever uma cópia disso.
tokenizer = Tokenizer(num_words=30000, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n', lower=True, split=' ', char_level=False)
Rapidamente sobre os parâmetros- num_words - número de palavras fixas (mais comuns)
- filtros - uma sequência de caracteres a serem excluídos
- lower - um parâmetro booleano que controla se o texto será minúsculo
- split - o símbolo principal para dividir uma frase
- char_level - indica se um único caractere será considerado uma palavra
E agora vamos processar o texto usando a classe
tokenizer.fit_on_texts(df['comment']) matrix = tokenizer.texts_to_matrix(df['comment'], mode='count') matrix.shape
Temos 14k linhas de amostra e 30k colunas de recursos.

Estou construindo um modelo a partir de duas camadas: Denso e Dropout.
def get_model(): model = Sequential() model.add(Dense(32, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(optimizer=RMSprop(lr=0.0001), loss='binary_crossentropy', metrics=['accuracy']) return model
Normalizamos a matriz e dividimos os dados em duas partes, conforme combinado (treinamento e teste).
X = normalize(matrix) y = target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) X_train.shape, y_train.shape
Modelo de treinamento
model = get_model() history = model.fit(X_train, y_train, epochs=150, batch_size=500, validation_data=(X_test, y_test)) history
Vou mostrar o processo de aprendizado nas últimas iterações.

Visualização do processo de aprendizagem
history = history.history fig = plt.figure(figsize=(20, 10)) ax1 = fig.add_subplot(221) ax2 = fig.add_subplot(223) x = range(150) ax1.plot(x, history['acc'], 'b-', label='Accuracy') ax1.plot(x, history['val_acc'], 'r-', label='Validation accuracy') ax1.legend(loc='lower right') ax2.plot(x, history['loss'], 'b-', label='Losses') ax2.plot(x, history['val_loss'], 'r-', label='Validation losses') ax2.legend(loc='upper right')
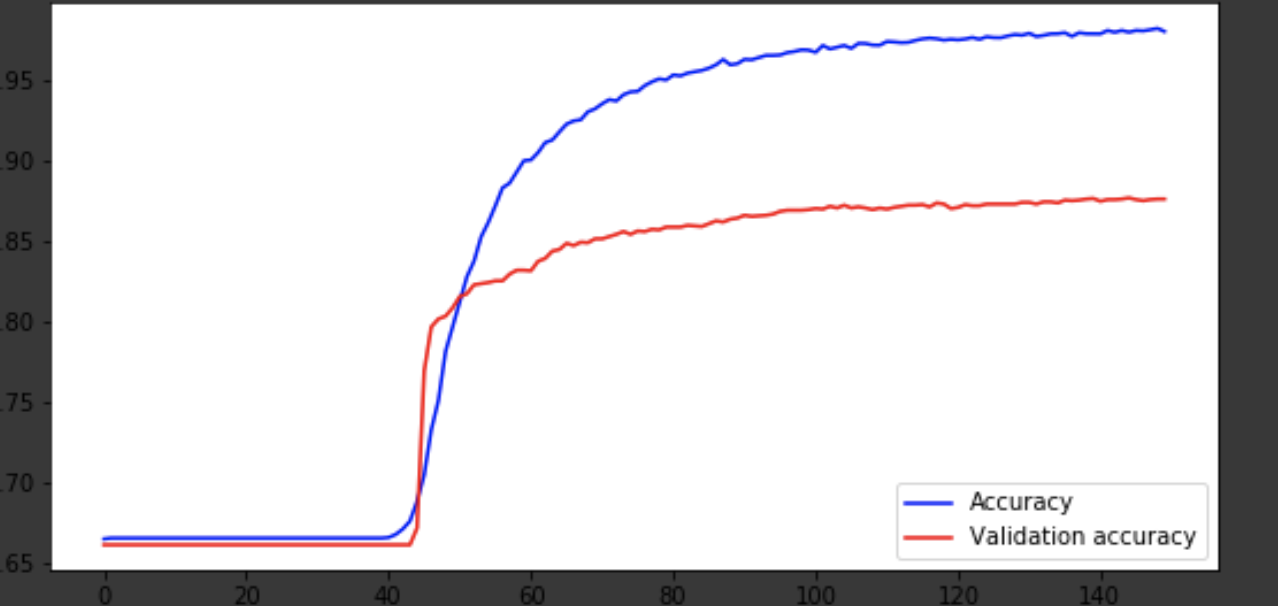
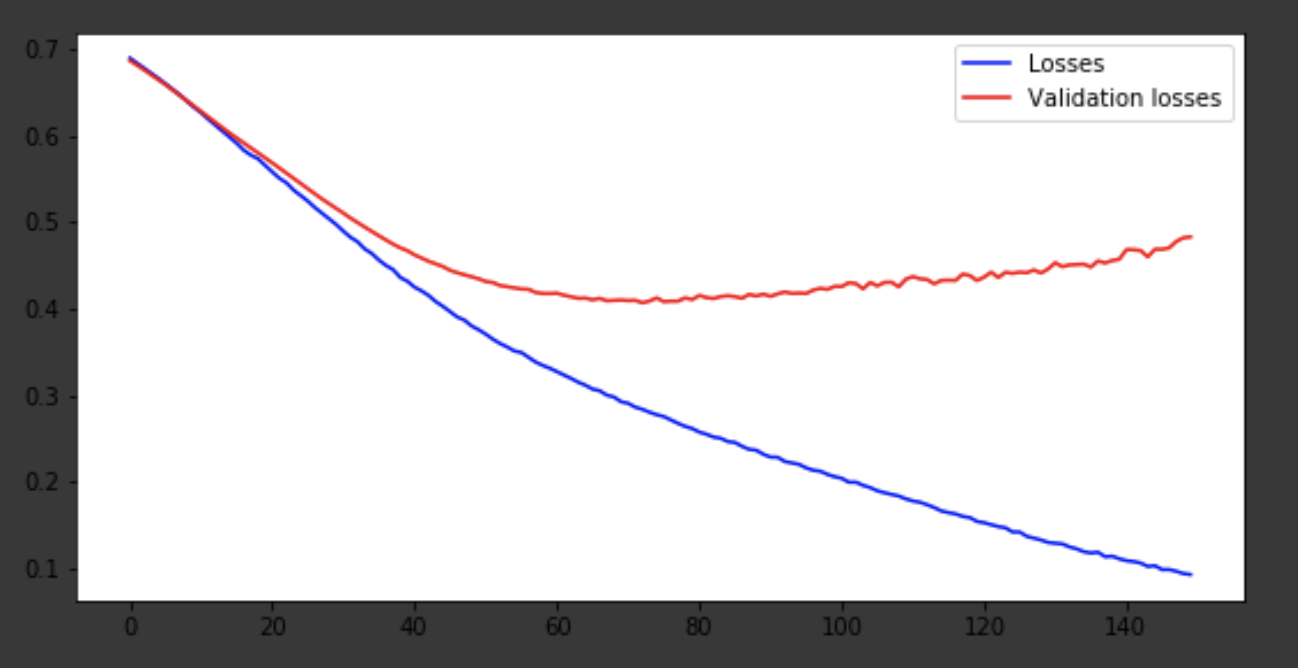
Conclusão
O modelo saiu por volta da era 75 e depois se comportou mal. A precisão de 0,85 não incomoda. Você pode se divertir com o número de camadas, hiperparâmetros e tentar melhorar o resultado. É sempre interessante e faz parte do trabalho. Escreva sobre seus pensamentos nos comentários, veremos quantos chapéus este artigo ganhará.