O artigo discute abordagens para a criação de recomendações personalizadas de produtos e conteúdos e possíveis casos de uso.
Recomendações personalizadas de produtos e conteúdo são usadas para aumentar a conversão, verificar a média e melhorar a experiência do usuário.

Um exemplo de uso da abordagem é Amazon e Netflix. A Amazon começou a usar uma abordagem de filtragem colaborativa nos primeiros anos de sua existência e alcançou crescimento de receita somente por meio do algoritmo em 10%. A Netflix aumenta a quantidade de conteúdo visualizado devido à abordagem baseada no algoritmo do sistema de recomendação em 40%. Agora, é mais fácil nomear uma empresa que não usa essa abordagem do que listar todos que a usam.
A Netflix tem uma história fascinante relacionada a essa tecnologia. Em 2006-2009 (mesmo antes do local da competição Kaggle ML se tornar popular), a Netflix anunciou um concurso aberto para melhorar o algoritmo com um prêmio total de US $ 1.000.000. A competição durou 2 anos e vários milhares de desenvolvedores e cientistas participaram. Se a Netflix os contratasse no estado, os custos seriam muitas vezes maiores que o prêmio prometido. Como resultado, uma das equipes venceu enviando uma solução com a qualidade necessária 2 horas antes da outra equipe, repetindo o resultado do vencedor. Como resultado, o dinheiro foi para uma equipe rápida. A competição se tornou um catalisador de mudanças qualitativas no campo de recomendações personalizadas.
A principal abordagem para resolver o problema da construção de sistemas de recomendação é a filtragem colaborativa.
A ideia da filtragem colaborativa é simples: se um usuário fez uma compra de um produto ou visualizou um conteúdo, encontraremos usuários com gostos semelhantes e recomendaremos ao nosso cliente que pessoas como ele consumiram, mas o cliente não. Essa é uma abordagem baseada no usuário.
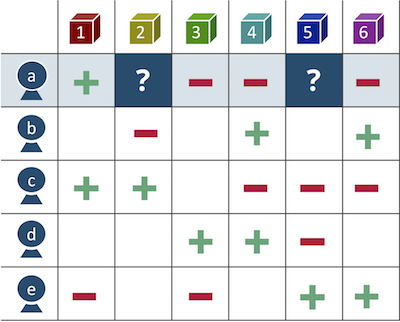 Figura 1 - Matriz de preferência do produto
Figura 1 - Matriz de preferência do produtoDa mesma forma, você pode analisar o problema do ponto de vista das mercadorias e pegar mercadorias complementares na cesta do cliente aumentando a média de cheques ou substituindo as mercadorias que não estão em estoque por um analógico. Essa é uma abordagem baseada em itens.
No caso mais simples, é usado o algoritmo para encontrar os vizinhos mais próximos.
Exemplo: Se Maria gosta do filme "Titanic" e "Guerra nas Estrelas", a usuária mais próxima de seu gosto será Anya, que também assistiu "Hachiko" além desses filmes. Vamos recomendar a Maria o filme "Hachiko". Vale esclarecer que geralmente eles usam não um vizinho mais próximo, mas vários, com a média dos resultados.
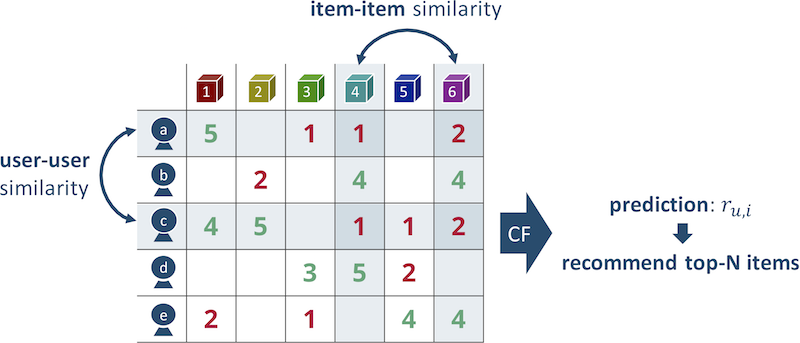 Fig. 2 O princípio de operação do algoritmo dos vizinhos mais próximos
Fig. 2 O princípio de operação do algoritmo dos vizinhos mais próximosTudo parece simples, mas a qualidade das recomendações usando essa abordagem é pequena.
Considere algoritmos complexos de sistemas de recomendação baseados na propriedade de matrizes, ou melhor, na decomposição de matrizes.
O algoritmo clássico é SVD (decomposição de matriz singular).
O significado do algoritmo é que a matriz de preferências do produto (a matriz em que as linhas são usuários e as colunas são os produtos com os quais os usuários interagiram) é representada como o produto de três matrizes.
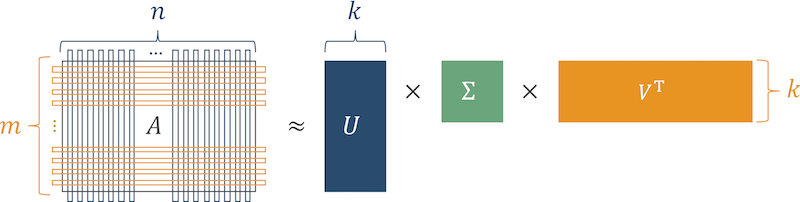 Fig. 3 Algoritmo SVD
Fig. 3 Algoritmo SVDApós restaurar a matriz original, as células nas quais o usuário tinha zeros e números "grandes" apareceram mostram o grau de interesse latente no produto. Organize esses números e obtenha uma lista de produtos relevantes para o usuário.
Durante esta operação, o usuário e o produto aparecem sinais "latentes". Estes são sinais que mostram o estado "oculto" do usuário e do produto.
Mas sabe-se que tanto o usuário quanto o produto, além dos “latentes”, também têm sinais óbvios. Sexo, idade, recebimento médio de compra, região etc.
Vamos tentar enriquecer nosso modelo com esses dados.
Para fazer isso, usamos o algoritmo da máquina de fatoração.
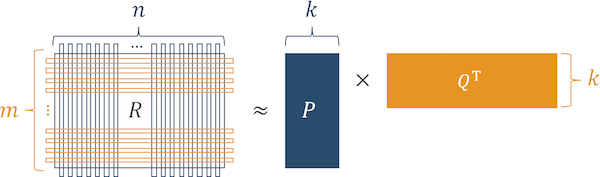 Fig. 4 Algoritmo de operação de máquinas de fatoração
Fig. 4 Algoritmo de operação de máquinas de fatoraçãoDe acordo com a nossa experiência, na
Data4 , estudos de caso no campo da construção de sistemas de recomendação para lojas on-line, ou seja, máquinas de fatoração, fornecem o melhor resultado. Por isso, usamos máquinas de fatoração para construir um sistema de recomendação para o nosso cliente, o KupiVip. O crescimento na métrica RMSE foi de 6-7%.
Mas as abordagens baseadas em matriz têm suas desvantagens. O número de padrões generalizados de combinação mútua de bens não é grande. Para resolver esse problema, é aconselhável usar redes neurais. Mas uma rede neural requer volumes de dados que apenas grandes empresas possuem.
De acordo com nossa experiência, no
Data4 , apenas um cliente possui uma rede neural para recomendações personalizadas de produtos que deram o melhor resultado. Mas, com sucesso, você pode obter até 10% da métrica RMSE. As redes neurais são usadas no YouTube e em alguns dos maiores sites de conteúdo.
Casos de uso
Para lojas online
- Recomendar produtos relevantes para o usuário nas páginas da loja online
- Use o bloco "você pode gostar" no cartão do produto
- Na cesta recomendar produtos complementares (controle remoto para TV)
- Se o produto não estiver em estoque, recomende um
- Faça boletins personalizados
Para conteúdo
- Aumente o envolvimento recomendando artigos, filmes, livros, vídeos relevantes
Outros
- Recomendar pessoas em aplicativos de namoro
- Recomendar pratos em um restaurante
No artigo, discutimos os conceitos básicos dos sistemas de recomendação de dispositivos e estudos de caso. Aprendemos que o princípio principal é recomendar produtos de pessoas com gostos semelhantes e o uso do algoritmo de filtragem colaborativa.
No próximo artigo , serão considerados os hacks de vida dos sistemas de recomendação baseados em casos reais de negócios. Mostramos quais métricas são melhor usadas e qual coeficiente de proximidade escolher para previsão.