Como tornar a queda suave?

Não encontrei um guia abrangente para o tratamento de erros nos aplicativos React, por isso decidi compartilhar a experiência adquirida neste artigo. O artigo é destinado a desenvolvedores iniciantes e pode ser um ponto de partida para sistematizar o tratamento de erros no aplicativo.
Problemas e definição de metas
Na segunda-feira de manhã, você bebe café com calma e se vangloria de ter corrigido mais bugs do que na semana passada e, em seguida, o gerente corre e acena com as mãos - “caímos, tudo é muito triste, estamos perdendo dinheiro”. Você executa e abre o seu Mac, vai para a versão de produção do seu SPA, dá alguns cliques para reproduzir o bug, vê a tela branca e apenas o Todo-Poderoso sabe o que aconteceu lá, entra no console, começa a cavar, dentro do componente t existe um componente com o nome falante b, em que o erro não pode ler a propriedade getId de indefinida. N horas de pesquisa e você corre com um grito vitorioso para lançar o hotfix. Tais ataques ocorrem com alguma frequência e se tornaram a norma, mas e se eu disser que tudo pode ser diferente? Como reduzir o tempo para erros de depuração e criar o processo para que o cliente praticamente não perceba erros de cálculo durante o desenvolvimento que são inevitáveis?
Vamos examinar em ordem os problemas que encontramos:- Mesmo se o erro for insignificante ou localizado dentro do módulo, em todo o caso, todo o aplicativo se tornará inoperante
Antes da versão 16 do React, os desenvolvedores não tinham um único mecanismo de captura de erro padrão e havia situações em que a corrupção de dados levava a uma queda na renderização apenas nas próximas etapas ou ao comportamento estranho do aplicativo. Cada desenvolvedor lidou com os erros porque estava acostumado a isso, e o modelo imperativo com try / catch geralmente não se encaixava bem com os princípios declarativos do React. Na versão 16, apareceu a ferramenta Limites de Erro, que tentou solucionar esses problemas, consideraremos como aplicá-lo. - O erro é reproduzido apenas no ambiente de produção ou não pode ser reproduzido sem dados adicionais.
Em um mundo ideal, o ambiente de desenvolvimento é o mesmo que a produção e podemos reproduzir qualquer bug localmente, mas vivemos no mundo real. Não há ferramentas de depuração no sistema de combate. É difícil e improdutivo descobrir tais incidentes, basicamente você precisa lidar com o código ofuscado e a falta de informações sobre o erro, e não com a essência do problema. Não consideraremos a questão de como aproximar as condições do ambiente de desenvolvimento às condições de produção, mas consideraremos as ferramentas que permitem obter informações detalhadas sobre os incidentes que ocorreram.
Tudo isso reduz a velocidade do desenvolvimento e a lealdade do usuário ao produto de software, por isso estabeleci para mim os três objetivos mais importantes:
- Melhore a experiência do usuário com o aplicativo em caso de erros;
- Reduza o tempo entre o erro que entra na produção e sua detecção;
- Acelere o processo de localização e depuração de problemas no aplicativo para o desenvolvedor.
Que tarefas precisam ser resolvidas?- Lidar com erros críticos com o limite de erro
Para melhorar a experiência do usuário com o aplicativo, devemos interceptar erros críticos da interface do usuário e processá-los. No caso em que o aplicativo consiste em componentes independentes, essa estratégia permitirá que o usuário trabalhe com o restante do sistema. Também podemos tentar tomar medidas para restaurar o aplicativo após uma falha, se possível.
- Salvar informações de erro estendidas
Se ocorrer um erro, envie as informações de depuração para o servidor de monitoramento, que irá filtrar, armazenar e exibir informações sobre incidentes. Isso nos ajudará a detectar e depurar facilmente erros após a implantação.
Tratamento de erros críticosA partir da versão 16, o React mudou o comportamento padrão da manipulação de erros. Agora, as exceções que não foram capturadas usando o Limite de erro levarão à desmontagem de toda a árvore do React e, como resultado, à inoperabilidade de todo o aplicativo. Essa decisão é argumentada pelo fato de que é melhor não mostrar nada do que dar ao usuário a oportunidade de obter resultados imprevisíveis. Você pode ler mais na
documentação oficial do React .
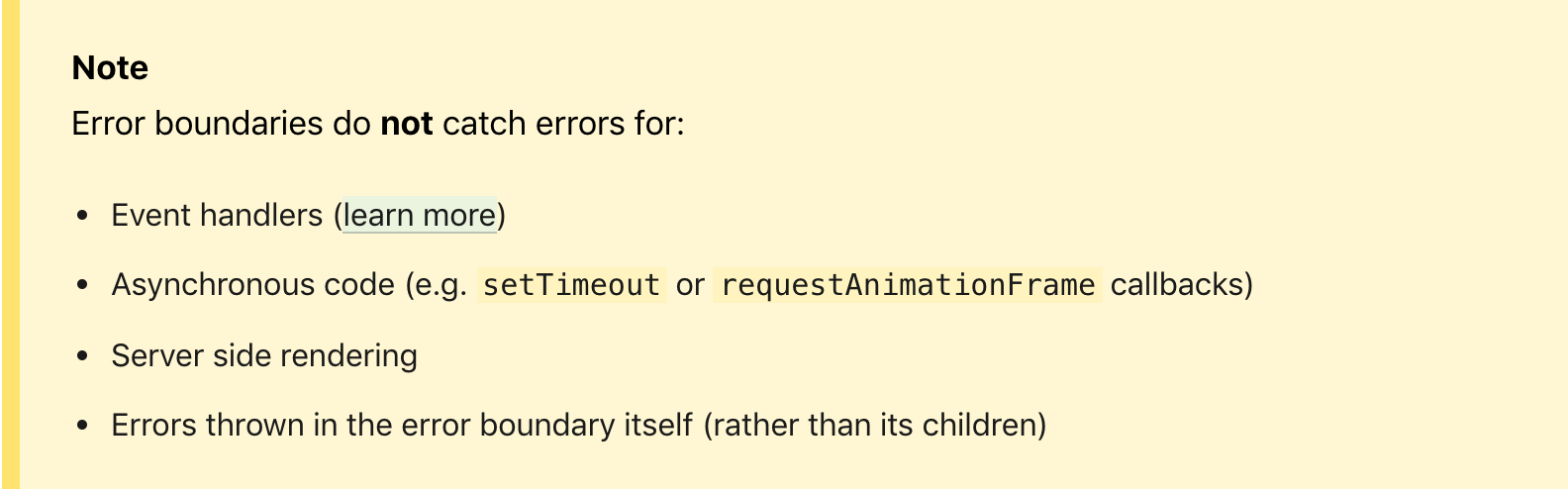
Além disso, muitos ficam confusos com a observação de que o Limite de erro não captura erros dos manipuladores de eventos e do código assíncrono, mas se você pensar bem, qualquer manipulador pode finalmente alterar o estado, com base no qual um novo ciclo de renderização será chamado, o que, finalmente, conta pode causar um erro no código da interface do usuário. Caso contrário, este não é um erro crítico para a interface do usuário e pode ser tratado de uma maneira específica dentro do manipulador.
Do nosso ponto de vista, um erro crítico é uma exceção que ocorreu dentro do código da interface do usuário e, se não for processado, toda a árvore do React será desmontada. Os erros restantes não são críticos e podem ser processados de acordo com a lógica do aplicativo, por exemplo, usando notificações.
Neste artigo, focaremos no tratamento de erros críticos, apesar do fato de que erros não críticos também podem levar à inoperabilidade da interface no pior dos casos. É difícil separar o processamento em um bloco comum e cada caso individual requer uma decisão, dependendo da lógica do aplicativo.
Em geral, erros não críticos podem ser muito críticos (como um trocadilho), portanto, as informações sobre eles devem ser registradas da mesma maneira que para os críticos.
Agora, estamos projetando o limite de erro para nosso aplicativo simples, que consistirá em uma barra de navegação, um cabeçalho e uma área de trabalho principal. É simples o suficiente para focar apenas no tratamento de erros, mas possui uma estrutura típica para muitos aplicativos.
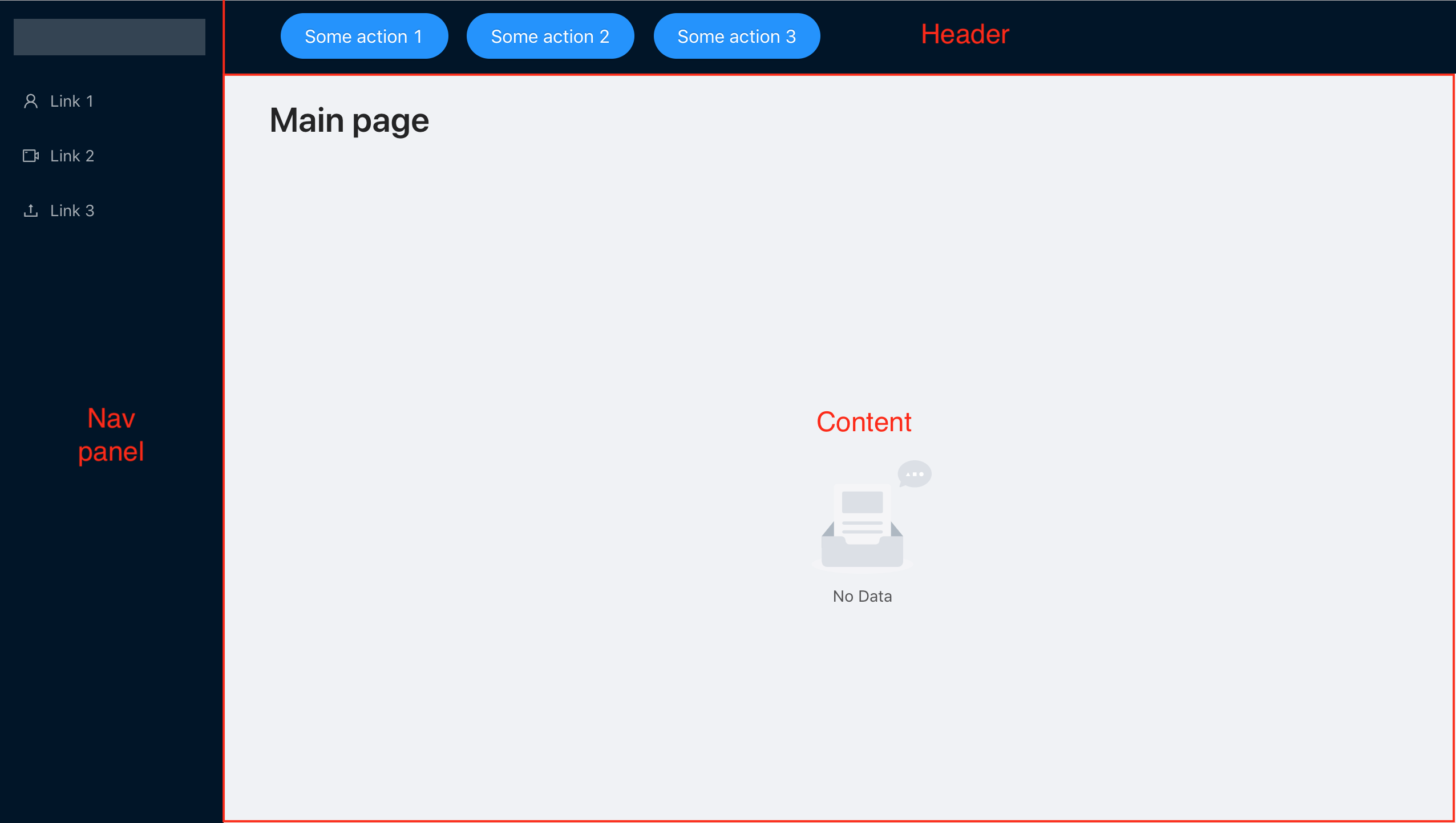
Temos um painel de navegação com 3 links, cada um dos quais leva a componentes independentes um do outro, portanto, queremos atingir um comportamento que, mesmo que um dos componentes não funcione, possamos continuar trabalhando com os outros.
Como resultado, teremos o ErrorBoundary para cada componente que pode ser acessado através do menu de navegação e do ErrorBoundary geral, que informa sobre a falha de todo o aplicativo, no caso de um erro no componente do cabeçalho, painel de navegação ou dentro do ErrorBoundary, mas não o resolvemos. processar e descartar ainda mais.
Considere listar um aplicativo inteiro envolto em ErrorBoundary
const AppWithBoundary = () => ( <ErrorBoundary errorMessage="Application has crashed"> <App/> </ErrorBoundary> )
function App() { return ( <Router> <Layout> <Sider width={200}> <SideNavigation /> </Sider> <Layout> <Header> <ActionPanel /> </Header> <Content> <Switch> <Route path="/link1"> <Page1 title="Link 1 content page" errorMessage="Page for link 1 crashed" /> </Route> <Route path="/link2"> <Page2 title="Link 2 content page" errorMessage="Page for link 2 crashed" /> </Route> <Route path="/link3"> <Page3 title="Link 3 content page" errorMessage="Page for link 3 crashed" /> </Route> <Route path="/"> <MainPage title="Main page" errorMessage="Only main page crashed" /> </Route> </Switch> </Content> </Layout> </Layout> </Router> ); }
Não há mágica no ErrorBoundary, é apenas um componente de classe no qual o método componentDidCatch está definido, ou seja, qualquer componente pode ser criado como ErrorBoundary, se você definir esse método nele.
class ErrorBoundary extends React.Component { state = { hasError: false, } componentDidCatch(error) {
É assim que o ErrorBoundary se parece com o componente Page, que será renderizado no bloco Content:
const PageBody = ({ title }) => ( <Content title={title}> <Empty className="content-empty" /> </Content> ); const MainPage = ({ errorMessage, title }) => ( <ErrorBoundary errorMessage={errorMessage}> <PageBody title={title} /> </ErrorBoundary>
Como ErrorBoundary é um componente React regular, podemos usar o mesmo componente ErrorBoundary para agrupar cada página em seu próprio manipulador, simplesmente passando parâmetros diferentes para ErrorBoundary, já que essas são instâncias diferentes da classe, seu estado não dependerá um do outro .
IMPORTANTE: O ErrorBoundary pode detectar erros apenas nos componentes que estão abaixo dele na árvore.Na lista abaixo, o erro não será interceptado pelo ErrorBoundary local, mas será lançado e interceptado pelo manipulador acima da árvore:
const Page = ({ errorMessage }) => ( <ErrorBoundary errorMessage={errorMessage}> {null.toString()} </ErrorBoundary> );
E aqui o erro é capturado pelo ErrorBoundary local:
const ErrorProneComponent = () => null.toString(); const Page = ({ errorMessage }) => ( <ErrorBoundary errorMessage={errorMessage}> <ErrorProneComponent /> </ErrorBoundary> );
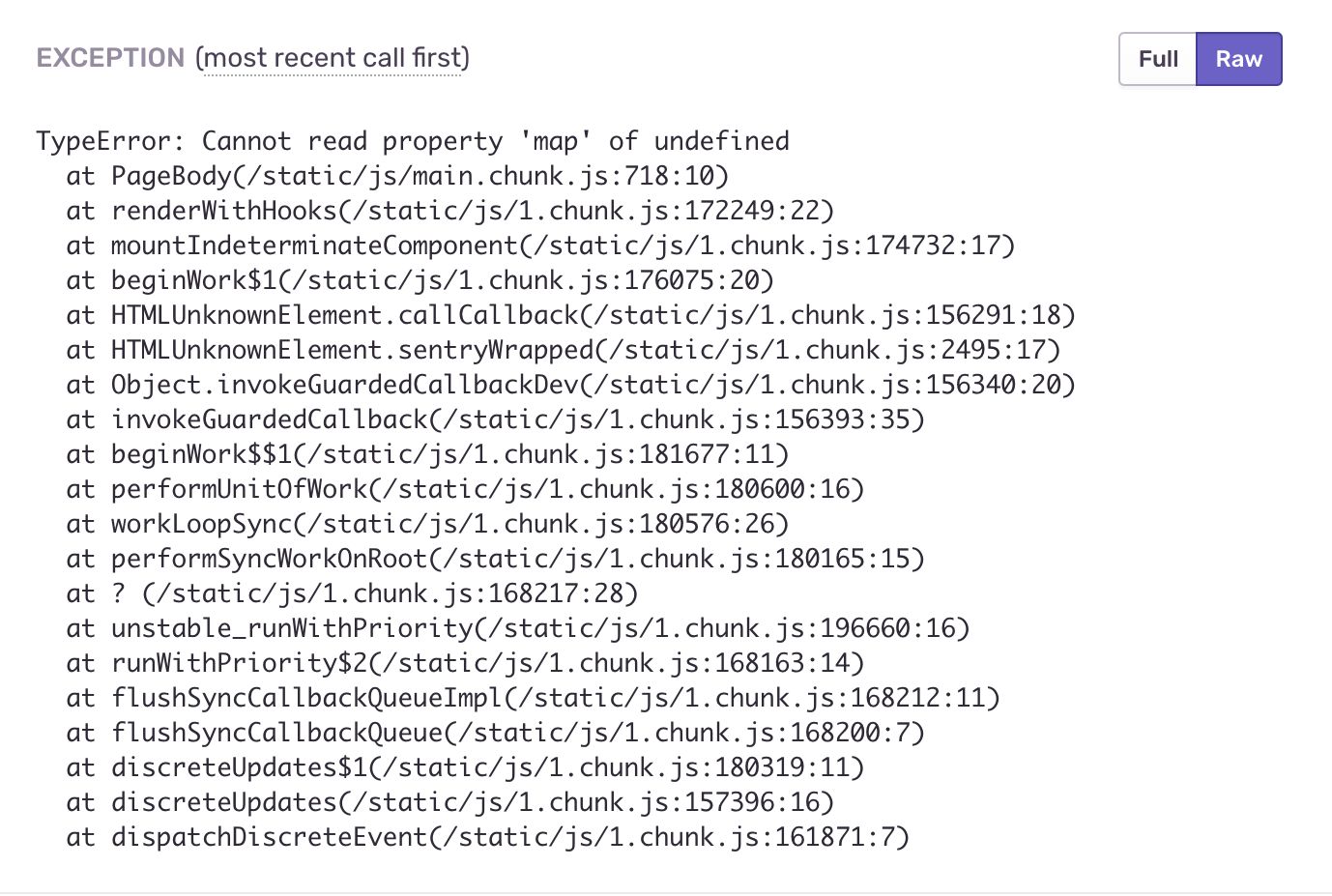
Depois de agrupar cada componente separado em nosso ErrorBoundary, alcançamos o comportamento necessário, colocamos o código deliberadamente errôneo no componente usando o link3 e ver o que acontece. Esquecemos intencionalmente de passar o parâmetro steps:
const PageBody = ({ title, steps }) => ( <Content title={title}> <Steps current={2} direction="vertical"> {steps.map(({ title, description }) => (<Step title={title} description={description} />))} </Steps> </Content> ); const Page = ({ errorMessage, title }) => ( <ErrorBoundary errorMessage={errorMessage}> <PageBody title={title} /> </ErrorBoundary> );
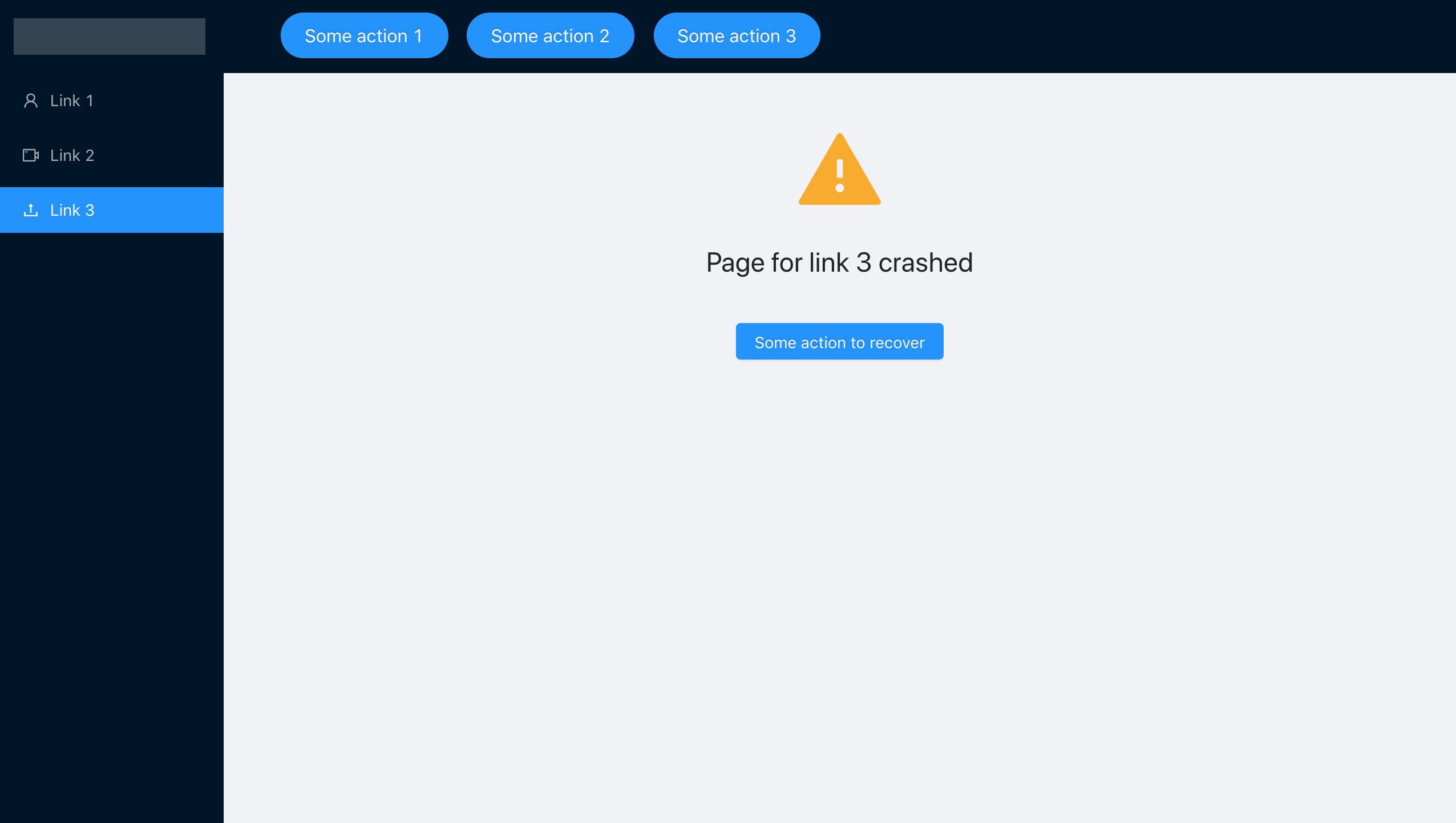
O aplicativo nos informará que ocorreu um erro, mas não cairá completamente. Podemos navegar pelo menu de navegação e trabalhar com outras seções.
Uma configuração tão simples nos permite alcançar facilmente nosso objetivo, mas, na prática, poucas pessoas prestam muita atenção ao tratamento de erros, planejando apenas a execução regular do aplicativo.
Salvando informações de erroAgora que colocamos ErrorBoundary suficiente em nosso aplicativo, é necessário salvar informações sobre erros para detectar e corrigi-los o mais rápido possível. A maneira mais fácil é usar serviços SaaS, como Sentry ou Rollbar. Eles têm uma funcionalidade muito semelhante, portanto você pode usar qualquer serviço de monitoramento de erros.
Vou mostrar um exemplo básico no Sentry, porque em apenas um minuto você pode obter uma funcionalidade mínima. Ao mesmo tempo, o Sentry captura exceções e até modifica console.log para obter todas as informações de erro. Depois disso, todos os erros que ocorrerão no aplicativo serão enviados e armazenados no servidor. O Sentry possui mecanismos para filtrar eventos, ofuscar dados pessoais, vincular a liberações e muito mais. Vamos considerar apenas o cenário básico de integração.
Para se conectar, você deve se registrar no site oficial e seguir o guia de início rápido, que o direcionará imediatamente após o registro.
Em nossa aplicação, adicionamos apenas algumas linhas e tudo decola.
import * as Sentry from '@sentry/browser'; Sentry.init({dsn: “https:
Mais uma vez, clique no link / link3 em nosso aplicativo e obtenha a tela de erro, após a qual vamos para a interface sentinela, aparentemente que um evento ocorreu e falhou por dentro.
Os erros são automaticamente agrupados por tipo, frequência e hora da ocorrência; vários filtros podem ser aplicados. Temos um evento - caímos nele e, na tela seguinte, vemos várias informações úteis, por exemplo, rastreamento de pilha

e a última ação do usuário antes do erro (trilhas de navegação).
Mesmo com uma configuração tão simples, podemos acumular e analisar informações de erro e usá-las para futuras depurações. Neste exemplo, um erro é enviado do cliente no modo de desenvolvimento, para que possamos observar as informações completas sobre o componente e os erros. Para obter informações semelhantes no modo de produção, você deve configurar adicionalmente a sincronização dos dados da versão com o Sentry, que armazenará o mapa de origem em si mesmo, permitindo salvar informações suficientes sem aumentar o tamanho do pacote. Não consideraremos essa configuração na estrutura deste artigo, mas tentarei falar sobre as armadilhas dessa solução em um artigo separado após sua implementação.
O resultado:O tratamento de erros usando o ErrorBoundary permite suavizar os cantos com uma falha parcial do aplicativo, aumentando assim a experiência do usuário do sistema e o uso de sistemas especializados de monitoramento de erros para reduzir o tempo de detecção e depuração de problemas.
Pense cuidadosamente em uma estratégia para processar e monitorar os erros do seu aplicativo. No futuro, você economizará muito tempo e esforço.
Uma estratégia bem pensada melhorará principalmente o processo de trabalhar com incidentes e só então afetará a estrutura do código.PS Você pode experimentar várias opções de configuração do ErrorBoundary ou conectar o Sentry ao aplicativo na ramificação feature_sentry, substituindo as chaves pelas obtidas durante o registro no site.
Aplicativo de demonstração do Git-hubDocumentação oficial de limite de erro do React