Antecipando o início de um novo tópico no curso "Redes Neurais em Python", preparamos para você uma tradução de um artigo interessante.
Um dos principais problemas na implementação da nova geração de computadores quânticos reside no cliente mais básico: o
qubit . Os Qubits podem interagir com qualquer objeto na vizinhança imediata que transfira
energia perto de seus próprios
fótons errantes (ou seja, campos eletromagnéticos indesejados,
fônons (vibrações mecânicas de um dispositivo quântico) ou defeitos quânticos (irregularidades na superfície do chip que apareceram durante a fase de fabricação), que pode imprevisivelmente mudar o estado dos qubits por conta própria.
O assunto é complicado por muitas tarefas que colocam as ferramentas usadas para controlar os qubits. Os Qubits são processados e lidos por métodos
clássicos : sinais analógicos na forma de campos eletromagnéticos, acoplados a uma placa física na qual um qubit é construído, por exemplo, em um microcircuito supercondutor. Imperfeições na eletrônica de controle (levando ao ruído branco), interferência de fontes externas de radiação e flutuações nos conversores digital-analógico levam a erros estocásticos ainda maiores que pioram a operação de microcircuitos quânticos. Essas questões práticas afetam a precisão dos cálculos e, portanto, limitam a aplicação da próxima geração de dispositivos quânticos.
Para aumentar o poder computacional dos computadores quânticos e abrir o caminho para a computação quântica em larga escala, é necessário primeiro criar modelos físicos que descrevam com precisão esses problemas experimentais.
No artigo
“Controle Quântico Universal por meio do Aprendizado por Reforço Profundo” , publicado no Nature Partner Journal (npj) Informações Quânticas (https://www.nature.com/npjqi/articles), introduzimos uma nova estrutura de controle quântico criada usando aprendizado profundo com reforço no qual os problemas práticos de otimizar o controle quântico podem ser encapsulados com uma única função de
perda . A estrutura em consideração fornece uma redução no erro médio da
porta quântica para duas ordens de grandeza em comparação com as soluções estocásticas padrão de descida gradiente e uma redução significativa no tempo da porta para os valores ótimos dos análogos da síntese da porta. Nossos resultados abrem novos horizontes para modelagem quântica, química quântica e testes de excelência quântica usando dispositivos quânticos em um futuro próximo.
A inovação desse paradigma de controle quântico é baseada no desenvolvimento de uma função de controle quântico e de um método de otimização eficaz baseado em aprendizado profundo com reforço. Para desenvolver uma função abrangente de perda, precisamos primeiro desenvolver um modelo físico de um processo realista de controle quântico no qual possamos prever com precisão a magnitude do erro. Um dos erros mais irritantes na avaliação da precisão da computação quântica é o vazamento: a quantidade de informações quânticas perdidas durante o cálculo. Esse vazamento geralmente ocorre quando o estado quântico de um qubit muda para um nível de energia mais alto ou para um valor mais baixo devido à emissão espontânea. Devido ao erro de vazamento, não apenas as informações quânticas úteis são perdidas, mas também degrada a “quantumidade” e, finalmente, reduz o desempenho de um computador quântico ao desempenho de um computador com arquitetura clássica.
Uma prática comum para estimar com precisão informações perdidas durante uma computação quântica é modelar a computação inteira primeiro. No entanto, isso nega o objetivo de criar computadores quânticos em larga escala, uma vez que sua vantagem é que eles são capazes de realizar cálculos impossíveis para computadores clássicos. Com o aprimoramento da modelagem física, nossa função de perda comum nos permite otimizar conjuntamente erros de vazamento acumulados, violações das condições dos limites de controle, tempo total da válvula e precisão da válvula.
Com a nova função de gerenciamento de perdas, o próximo passo é usar uma ferramenta de otimização eficaz para minimizá-la. Os métodos de otimização existentes não são bons o suficiente para procurar soluções de alta precisão que sejam confiáveis para controlar flutuações. Em vez disso, usamos um método baseado no método dentro da política de aprendizado profundo com reforço (RL),
RL - uma área confiável . Como esse método demonstra bom desempenho em todas as tarefas de teste, é inerentemente resistente ao ruído da amostra e pode otimizar problemas complexos de controle com centenas de milhões de parâmetros de controle. Uma diferença significativa entre esse método de RL dentro da política e os métodos de RL fora da política estudados anteriormente é que a política de gerenciamento é apresentada independentemente do gerenciamento de perdas. Por outro lado, todas as políticas de RL, como
Q-learning , usam uma única rede neural para representar o caminho de controle e a recompensa associada, onde a trajetória de controle determina os sinais de controle que devem ser associados aos qubits em diferentes medidas, e a recompensa associada mede a qualidade do tato. controle quântico.
A RL dentro da política é bem conhecida por sua capacidade de usar recursos não locais nos caminhos de controle, o que se torna crítico quando o cenário de controle é multidimensional e repleto de um número combinatorialmente grande de soluções não globais, como costuma ser o caso dos sistemas quânticos.
Codificamos o caminho de controle em uma política de rede neural - NN totalmente conectada em três camadas, e a função de perda de controle no valor da segunda rede neural - NN, que reflete o prêmio futuro descontado. Soluções de controle confiáveis foram obtidas com agentes de aprendizado por reforço que treinam ambas as redes neurais em um ambiente estocástico que simula controle de ruído realista. Oferecemos uma solução para controlar um conjunto de portas quânticas de dois qubit continuamente parametrizados, que são de particular importância na aplicação à química quântica, mas são muito caras para implementar usando um conjunto universal de portas padrão.
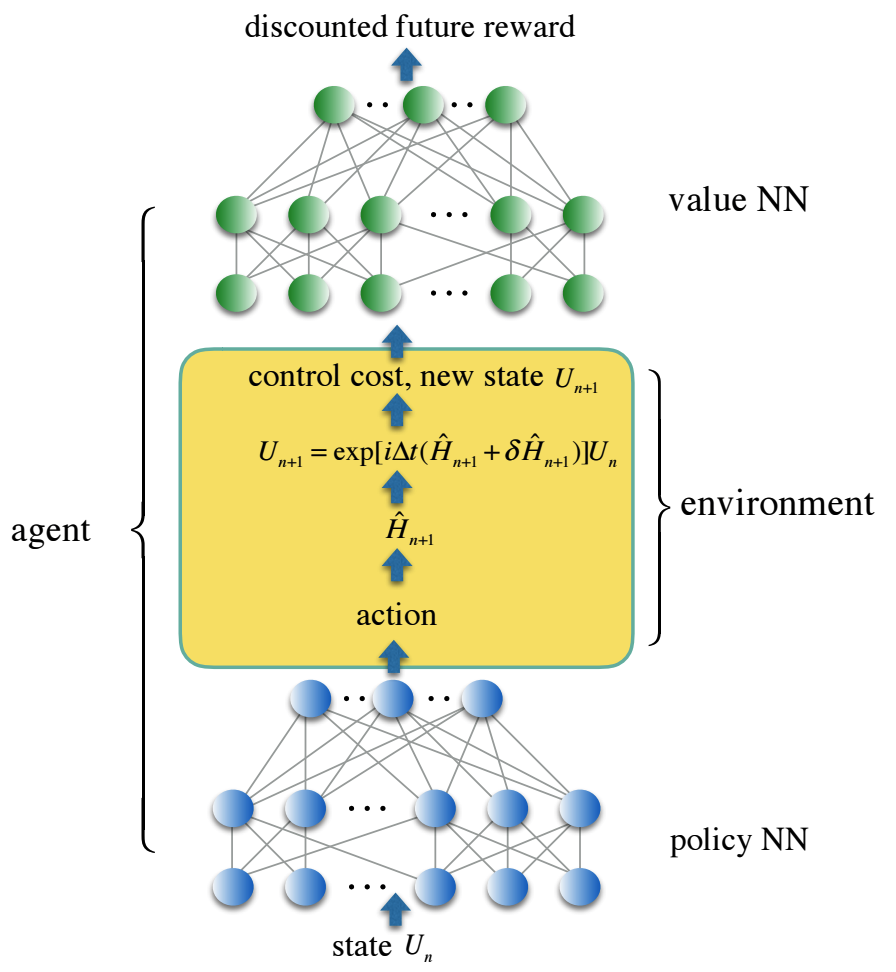
Dentro da estrutura dessa nova estrutura, nossa simulação numérica mostra uma diminuição de cem vezes nos erros de portas quânticas e uma redução no tempo de portas para a família de portas quânticas de simulação continuamente parametrizadas por uma média de uma ordem de magnitude em comparação com abordagens tradicionais usando um conjunto universal de portas.
Este trabalho enfatiza a importância do uso de novos métodos de aprendizado de máquina e dos mais recentes algoritmos quânticos que usam a flexibilidade e o poder de processamento adicional de um circuito universal de controle quântico. Para integrar totalmente o aprendizado de máquina e aumentar os recursos computacionais, é necessário realizar experimentos adicionais, semelhantes aos apresentados neste trabalho.