
De acordo com analistas, o mercado de data centers nos próximos anos crescerá 38% ao ano e em cinco anos aumentará para US $ 35 bilhões, e o nicho que mais consome recursos (em termos de intensidade de computação) é aprendizado profundo, redes neurais e tarefas de IA.
Obviamente, a Intel não ficará indiferente ao observar como a Nvidia (e a AMD, em menor grau) com suas GPUs capturam esse mercado, incluindo o setor que mais cresce. Na semana passada, o gigante da indústria microeletrônica fez vários anúncios de alto nível ao mesmo tempo:
- processadores para redes neurais Nervana NNP-T1000 e NNP-I1000 (NNP: processadores de rede neural), bem como o chip Movidius VPU ;
- Processadores escalonáveis Xeon de 10 nm (codinome Sapphire Rapids);
- interfaces de programação unificada oneAPI (para CPU, GPU, FPGA) - um concorrente da Nvidia CUDA;
- Uma GPU de 7 nm para data centers, com o codinome Ponte Vecchio, na nova arquitetura X e .
Módulos de computação Aurora
Nessas CPUs, GPUs e oneAPI, eles compõem os módulos de computação Aurora para o supercomputador de mesmo nome com um nível de desempenho de 1 exaflops (10 ^ 18 operações por segundo). Supõe-se que esta máquina será instalada no Laboratório Nacional de Argonne do Departamento de Energia dos EUA.

Cada módulo de computação possui dois processadores Sapphire Rapids e seis GPUs conectadas através do barramento CXL.

De acordo com as
estimativas da AnandTech , em um sistema de 200 racks, conforme declarado, se você subtrair a reserva da rede e unidades, aproximadamente 2400 nós Aurora de duas unidades serão adequados. Isso representa um total de 5.000 processadores Sapphire Rapids e 15.000 Ponte Vecchio. Se dividirmos o desempenho declarado de 1 exaflops pelo número de GPUs, surgirão cerca de 66,6 teraflops por GPU. Além disso, assumindo um desempenho de CPU de 14 teraflops, ainda temos cerca de 50 teraflops, ou seja, esse é um aumento de cinco vezes no desempenho da GPU nos data centers até 2021.
Obviamente, os planos não se limitam a um supercomputador para o Departamento de Energia. A Intel anunciou que a Lenovo e a Atos já estão se preparando para lançar plataformas de servidor baseadas nos processadores Xeon, X
e GPU e oneAPI. Assim, os módulos de computação Aurora, de alguma forma, encontrarão aplicação em outros data centers.
O supercomputador deve ser lançado em 2021. Ao mesmo tempo, as GPUs X
e 7 nanômetros devem aparecer no mercado.
Segundo a Intel, agora as soluções tradicionais de alto desempenho (HPC) convergem com a IA, passando para cargas de trabalho que usam aprendizado profundo. HPC, AI e análises são as três principais cargas de trabalho que direcionam a demanda por recursos de computação: “Essa variedade de necessidades de computação incentiva a computação heterogênea.
Disse Rajeeb Hazra, vice-presidente e gerente geral da Intel Enterprise and Government. - Soluções universais não são mais adequadas aqui. Nesta era de convergência, você deve considerar arquiteturas ajustadas às diferentes necessidades de diferentes tipos de cargas de trabalho. ”
GPU para data centers

Ponte Vecchio é a primeira GPU da nova arquitetura X
e . A arquitetura em si se tornará a base da GPU em vários segmentos:
- computação de alto desempenho;
- aprendizagem profunda;
- Computação em nuvem
- gráficos;
- transcodificação de mídia;
- estações de trabalho
- computadores para jogos;
- PCs de mesa regulares;
- dispositivos móveis e ultramóveis.

Ari Rauch, vice-presidente de arquitetura, gráficos e software da Intel, diz que uma arquitetura de GPU dará aos desenvolvedores uma "estrutura comum", mas como parte dessa arquitetura, a empresa está desenvolvendo "muitas microarquiteturas que oferecem o desempenho mais eficiente para cada um". essas cargas de trabalho ".
A GPU Ponte Vecchio é baseada na microarquitetura X
e especificamente para HPC e AI, e os recursos da microarquitetura incluem um mecanismo de matriz paralela flexível com matrizes vetoriais, alto rendimento de cálculos de ponto flutuante de precisão dupla (FP64) e rendimento ultra alto de cache e memória. Para os formatos INT8, Bfloat16 e FP32, haverá um Mecanismo de matriz separado para processamento paralelo de matrizes (possivelmente um analógico do TensorCore), e para o FP64 a aceleração será de até 40 vezes para cada unidade de computação.
“Essa carga de trabalho requer alto desempenho computacional; portanto, nos concentramos em adicionar um grande número de módulos vetoriais e matriciais e computação paralela que são adaptados e otimizados para essa carga de trabalho”, afirmou Rauch.
Ponte Vecchio será o primeiro GPU da nova geração. Ele implementa várias novas tecnologias que a Intel vem desenvolvendo nos últimos anos:
- processo de produção 7 nm;
- layout em camadas dos circuitos integrados 3D da Foveros;
- EMIB (Embedded Multi-Die Interconnect Bridge) para conectar vários cristais em um substrato;
- X e Link no novo padrão de interconexão CXL (baseado no PCI Express 5.0) - acesso à GPU através de um único espaço de memória.

 Circuitos integrados 3D Foveros em camadas da apresentação de dezembro de 2018 da Intel
Circuitos integrados 3D Foveros em camadas da apresentação de dezembro de 2018 da IntelAs especificações técnicas do chip ainda não foram anunciadas. Eles dizem que nessas GPUs haverá milhares de unidades executivas conectadas via XEMF (XE Memory Fabric) com memória e cache.

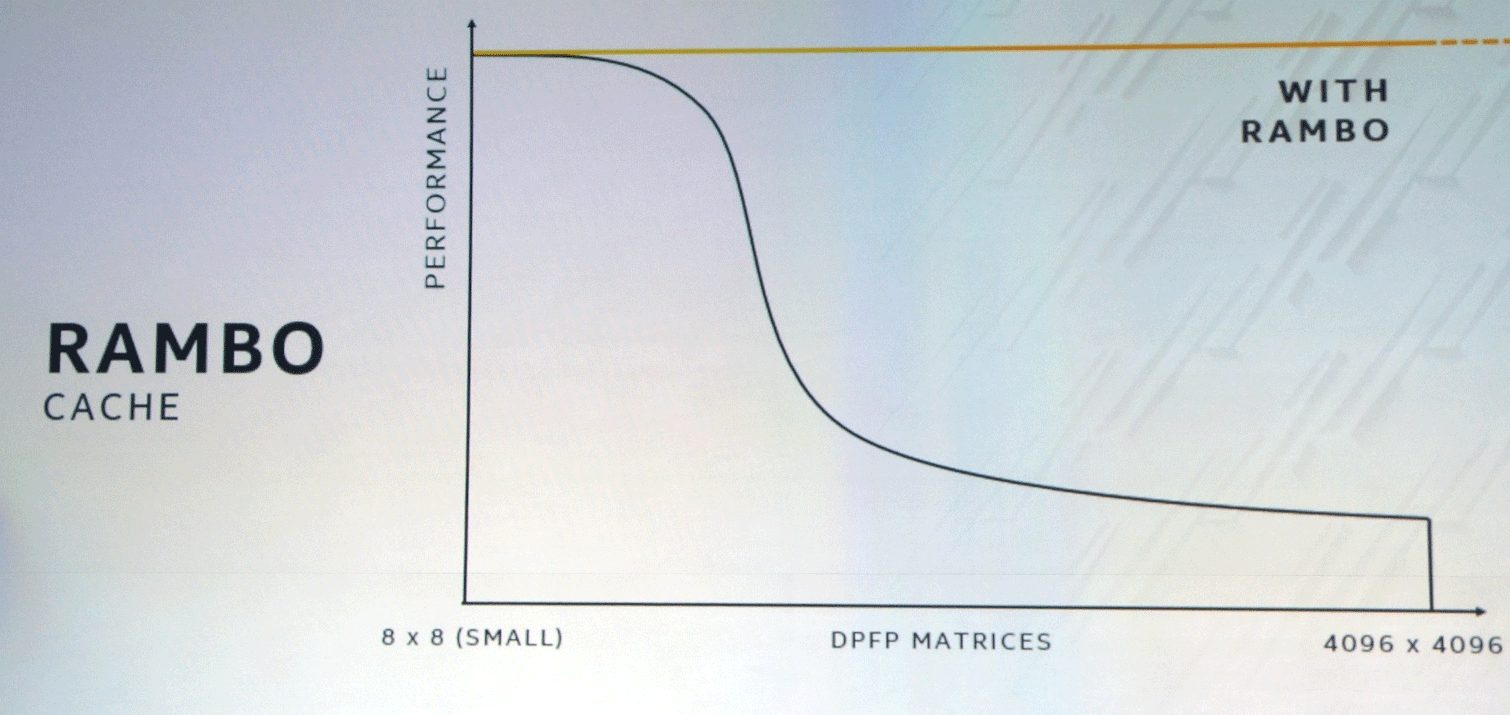
O barramento XEMF trabalha com o cache ultra-rápido especial do Rambo Cache para eliminar o gargalo do acesso à memória. Esse cache se conecta às unidades de computação através do Foveros, e o EMIB será usado para conectar a memória HBM.
A combinação de abordagens SIMT e SIMD específicas para a GPU e CPU, respectivamente, e instruções vetoriais de comprimento variável fornecerão um aumento significativo no desempenho em algumas classes de tarefas.

Muitos esperam que a Intel concorra com a Nvidia e a AMD no mercado de data centers e IA. Não se trata apenas da concorrência de preços, mas também do surgimento de plataformas tecnológicas alternativas, que estimularão o progresso tecnológico geral.
OneAPI: vértice de abstração para ferro heterogêneo
Além do anúncio de novos equipamentos, a Intel lançou uma versão beta das interfaces de software unificadas oneAPI. Eles foram projetados para facilitar o trabalho dos desenvolvedores que, para otimizar ao máximo seus programas, tradicionalmente tinham que alternar entre diferentes linguagens de programação e bibliotecas usando middleware e estruturas.
Por padrão, é aceito no setor que, em um nível baixo, diferentes códigos precisam ser preparados para cada arquitetura. Por exemplo, o TensorFlow foi inicialmente totalmente otimizado no momento do lançamento para a GPU de um fornecedor (para Nvidia CUDA).
"A OneAPI está tentando resolver esses problemas oferecendo uma interface comum de baixo nível para hardware heterogêneo com desempenho intransigente", disse Bill Savage, vice-presidente da divisão de arquitetura, gráficos e software da Intel. “Para que os desenvolvedores possam escrever programas diretamente no hardware através de linguagens e bibliotecas comuns a diferentes arquiteturas e fornecedores, além de garantir que o middleware e as estruturas funcionem na oneAPI e sejam totalmente otimizados para os desenvolvedores que estão no topo dessa abstração.”
A Intel defende o oneAPI como um "padrão aberto para suporte da comunidade e do setor", que permitirá "reutilizar códigos em arquiteturas e hardwares de diferentes fabricantes".
A especificação oneAPI incluirá a linguagem de programação DPC ++ de arquitetura cruzada padrão baseada em C ++ e SYCL, além de "APIs poderosas para acelerar as principais funções específicas do domínio".
Além do compilador DPC ++ e da biblioteca de API, serão lançadas ferramentas especiais, incluindo o VTune Inspector Advisor, um depurador e uma "ferramenta de compatibilidade" para transferir o código CUDA (Nvidia) para o DPC ++.
Para estimular a transição para o oneAPI, a Intel lançou uma sandbox no
DevCloud para desenvolver e testar programas em várias CPUs, GPUs e FPGAs. Trabalhar com a sandbox não requer a instalação de nenhum hardware ou software.
Enquanto isso, a receita da Nvidia no trimestre
aumentou para US $ 3 bilhões , enquanto no mercado de data centers, o crescimento nos três meses foi de 11% (US $ 726 milhões). As vendas dos processadores V100 e T4 estão quebrando todos os recordes. A Intel ainda está olhando de fora, mas já sabemos qual será a resposta. O mais interessante está apenas começando.