
No fórum RAIF 2019, realizado em Skolkovo como parte do Open Innovations, falei sobre como a introdução de modelos de aprendizado de máquina está sendo implementada. Em conexão com as características da profissão, passo vários dias por semana em produção, introduzindo modelos de aprendizado de máquina e o resto do tempo desenvolvendo esses modelos. Este post é uma gravação de um relatório no qual tentei resumir minha experiência.
Começamos descrevendo o processo em grandes traços, entrando gradualmente nos detalhes de cada estágio.
Quer estejamos contando com a otimização da produção com base nos resultados de uma pesquisa completa (idealmente) ou apenas com a coleta de idéias, "otimização de retalhos", o resultado é, de alguma forma, a
formação de uma lista de iniciativas . É necessário entender quais áreas de produção otimizaremos. Esse processo geralmente leva cerca de dois meses.
Em seguida, prosseguimos para a fase de
pilotagem , que levará de três a quatro meses - precisamos construir um modelo básico e entender se o aprendizado de máquina é aplicável a ele e quais benefícios ele pode trazer para os negócios.
Na próxima etapa, por muito mais tempo, não há muito aprendizado de máquina - a
implementação , quando você precisa integrar, criar sistemas atuais e começar a obter o mesmo lucro que previmos na segunda etapa. A implementação geralmente leva de seis a nove meses.
O estágio de
controle conclui o processo. Uma coisa é criar um modelo e mostrar e outra é mantê-lo por algum tempo. A produção está mudando, as máquinas-ferramentas estão sendo substituídas. Nessas condições, o modelo precisa “girar” constantemente e procurar novas oportunidades de otimização.
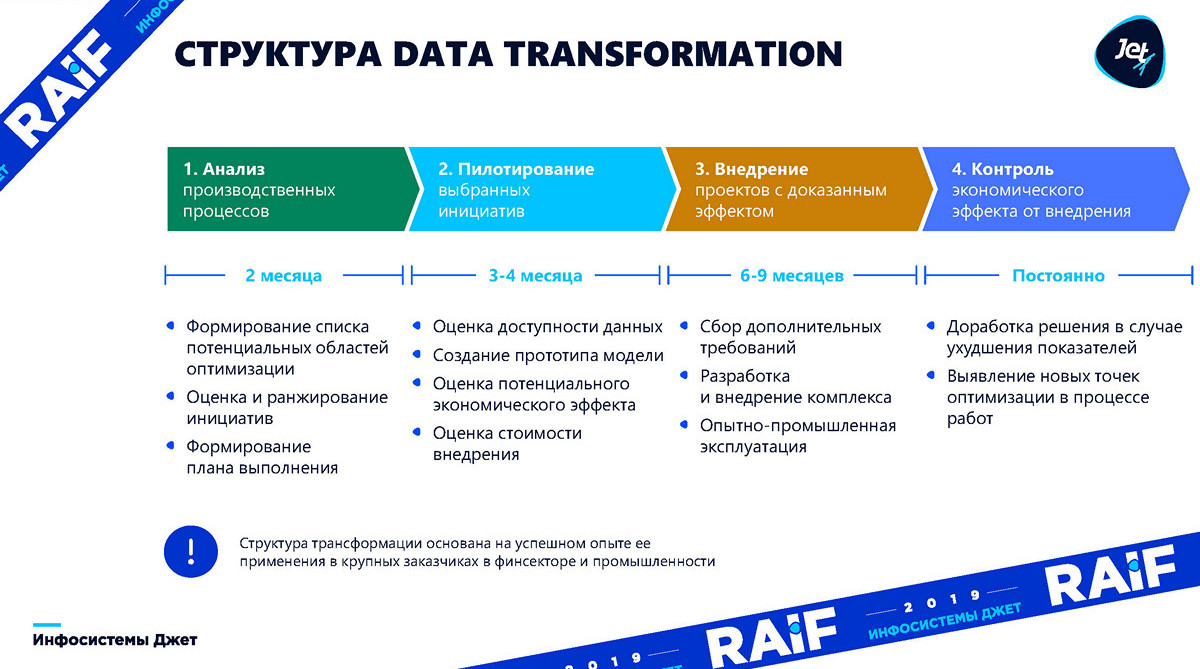
Agora com mais detalhes em ordem:
Procurando uma hipótese
De onde vem a hipótese? Quem a indicará?
Geralmente, é habitual recorrer a hipóteses no departamento de TI, mas as pessoas que podem configurar os sistemas trabalham lá, sabem sobre integração e não sabem nada sobre aprendizado de máquina. Além disso, eles não estão tão bem cientes da produção. Eles não têm competência para entender na prática como o aprendizado de máquina funciona.
A tentativa número dois é ir para a hipótese de produção. De fato, especialistas próximos à produção conhecem os recursos técnicos do processo, mas ... não conhecem o aprendizado de máquina. Portanto, eles não podem dizer onde é aplicável e onde não.
Nesse caso, de onde vem a hipótese? Para fazer isso, eles criaram uma posição especial - Chief Digital Transformation Officer. Esta é uma pessoa que está envolvida na transformação digital. Ou Chief Date Officer - uma pessoa que conhece os dados e como eles podem ser aplicados. Se essas duas pessoas não estiverem na empresa, as hipóteses devem vir da alta gerência. Ou seja, especialistas que entendem completamente o negócio e estão envolvidos na tecnologia moderna.
Se a empresa não tem nem o Diretor de Transformação Digital, nem o Diretor de Data, e a alta gerência não é capaz de gerar uma hipótese, então ... os concorrentes virão em socorro. Se eles implementaram algo, isso não pode ser tirado deles. Porém, uma empresa integradora conectada ao projeto pode dizer o que e como pode ser otimizado.

Como escolher uma ideia?
Quatro fatores são importantes aqui:
- A rotatividade do processo a ser otimizado.
- Desvios significativos no processo. Existe uma metodologia seis-sigma, que sugere que todos os processos devem se desviar em não mais que seis desvios-padrão de seus resultados. Se você tiver mais desses desvios, precisará analisá-los, e o aprendizado de máquina ajudará.
- Disponibilidade e disponibilidade de dados. Se, por exemplo, você receber dados de sensores na operação do equipamento após 12 meses, não implementará o aprendizado de máquina.
- A complexidade da implementação da digitalização no processo. O custo de introdução do seu modelo, comparado com o custo do que ele pode economizar.
Quais são os dados?
A estrutura dos dados são:
Estruturado: algumas tabelas, leituras - tudo é simples. Quando queremos usar dados de redes sociais ou conjuntos de fotos, temos que lidar com dados não estruturados. É necessário afirmar que esses dados também devem ser estruturados, transformando-se em números que o aprendizado de máquina pode perceber. O terceiro tipo de dados é encadeado. Se trabalharmos com dados que mudam a cada milissegundo, precisamos pensar imediatamente no balanceamento de carga: nosso sistema pode suportar a velocidade de seu recebimento?

Por origem, os dados são divididos em:
Automatizados - os sensores geram algum tipo de número, confiamos neles ou não. Mas eles são quase os mesmos. Introduzido manualmente - aqui você precisa entender que pode haver um erro relacionado ao fator humano. E o modelo deve ser resistente a isso. Dados externos - talvez estaremos interessados em taxas de câmbio, se a implementação estiver relacionada a transações financeiras, ou previsões do tempo, se prevermos trocas de calor de temperatura. Dados estáticos são tudo o que pode ser reutilizado.

Problemas de dados
- Completude - o momento em que alguns dados / meses podem ser ignorados.
- O erro de alteração - se, por exemplo, seu sensor apresentar um erro de 5 milissegundos, o modelo com uma precisão de dois milissegundos - você não poderá, pois os dados de entrada começam a divergir.
- Acessibilidade online - se você deseja fazer uma previsão "agora", os dados devem estar prontos.
- Tempo de armazenamento - se você deseja usar tendências anuais e precisa prever a demanda, e os dados são armazenados apenas por seis meses - você não criará um modelo.
Trabalhar com dados
Ouça os profissionais, mas apenas acredite nos dados. Você precisa ir à oficina, conversar com profissionais, ir à fábrica, conversar com operadores, entender seus negócios. Mas acredite apenas nos dados. Havia muitos exemplos em que os operadores dizem que isso não pode ser - mostramos os dados - acontece que isso realmente está acontecendo. Um exemplo interessante: uma vez que o modelo mostrou que o dia da semana afeta a produção. Às segundas-feiras - um coeficiente, às sextas-feiras - outro.
O efeito é compreensível apenas em batalha - a prototipagem rápida é muito importante. O mais importante é ver rapidamente como o modelo funciona na vida cotidiana. Nas apresentações e nos laptops locais, o projeto pode parecer completamente diferente do que realmente é: como regra, de fato, problemas completamente diferentes vêm em primeiro lugar.
Somente um modelo interpretado tem chance de melhoria. Você sempre precisa entender claramente por que o modelo decidiu dessa maneira e não o contrário.
Trabalhar com métricas
Na realidade, a dependência da precisão do lucro pode ser qualquer. Até entendermos como essa precisão afeta o efeito, a questão da precisão é completamente sem sentido. Você sempre precisa traduzir em lucro. Os gráficos abaixo mostram que os lucros podem variar dependendo da precisão do modelo. O primeiro gráfico ilustra como é difícil determinar antecipadamente exatamente em que ponto a precisão do modelo é suficiente para o crescimento do lucro:
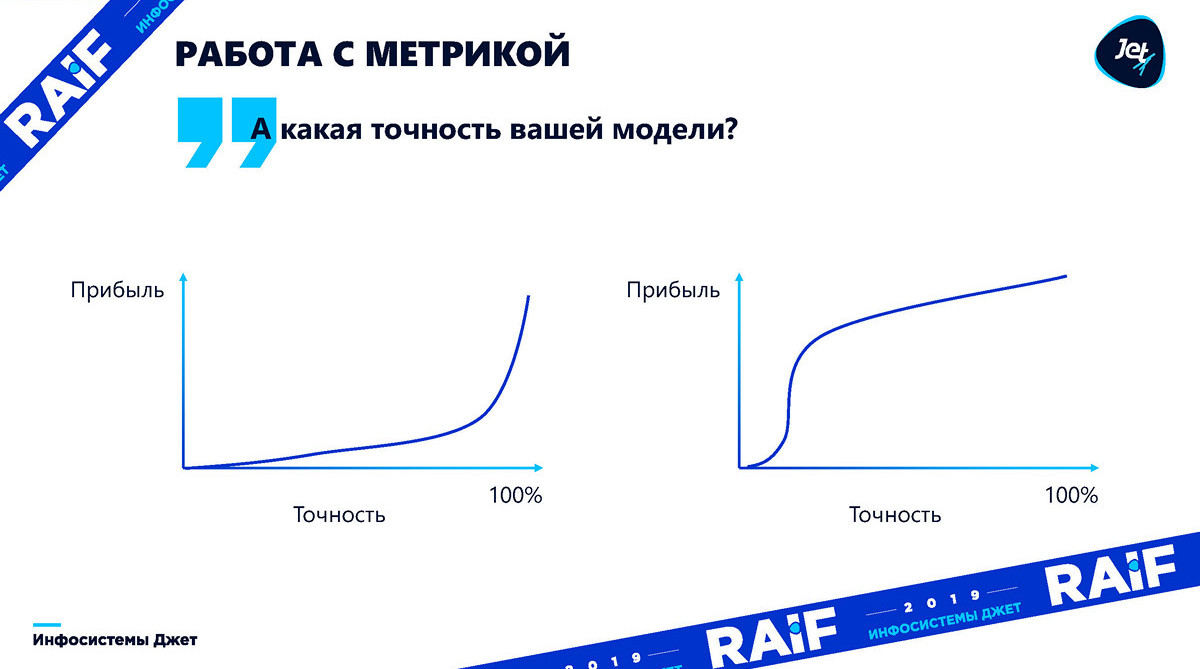
Além disso, em alguns casos com precisão insuficiente do modelo, isso simplesmente trará perda:

Pontos principais sobre integração:
- A integração leva mais tempo que o desenvolvimento do modelo.
- Novas ideias. Às vezes, o projeto se beneficia onde não era esperado.
- Treinamento. As pessoas se adaptam mais rápido que o ferro.
Outro ponto que os dataainists frequentemente esquecem é o objetivo de introduzir o modelo: previsão ou recomendação. Geralmente, as recomendações são baseadas no modelo preditivo, mas nesse caso o modelo preditivo deve ser construído especialmente, porque é bastante difícil encontrar a caixa preta mínima com efeitos desagradáveis repentinos. Se falamos de métricas de desempenho, dependendo do objetivo da implementação:
- Emita uma previsão, - avalie o resultado da aplicação do conhecimento;
- Dê recomendações - avalie a comparação com o processo antigo.
Nuances importantes da fase de implementação:
Implementação / Treinamento
- Alfabetização estatística - a implementação é muito mais bem-sucedida quando os funcionários locais começam a operar com termos estatísticos corretos.
- A motivação de várias unidades estruturais - todos devem entender por que isso está acontecendo e não ter medo de mudanças.
- Mudanças organizacionais - pelo menos um funcionário analisará os resultados do modelo, o que significa que eles mudarão sua abordagem ao processo. Muitas vezes acontece que as pessoas não estão prontas para isso.
Suporte
Não se esqueça de que as condições estão mudando e o modelo precisa “torcer” constantemente e procurar novas oportunidades de otimização. Aqui são importantes:
- Estratégias de gerenciamento de modelos e reação a previsões são um pouco de autopromoção: nós da Jet Infosystems apenas pensamos muito sobre isso e desenvolvemos nosso próprio sistema JET GALATEA.
- O fator humano - os principais problemas do modelo estão frequentemente associados ao seu uso, ou intervenção humana, que o modelo não podia prever.
- Análise regular do trabalho com profissionais da área - é improvável que tudo seja reduzido a um número, o que indicará o que precisa ser aprimorado, será necessário analisar cada previsão ou recomendação duvidosa. Esteja preparado para aprender outra profissão a falar o mesmo idioma com tecnólogos e operadores de dispositivos no local de trabalho.

Postado por Nikolay Knyazev, chefe do grupo de aprendizado de máquina, Jet Infosystems