 O diagrama do computador CS-1 mostra que a maioria é dedicada à alimentação e ao resfriamento do gigante Wafer Scale Engine (WSE) "processador em placa". Foto: Cerebras Systems
O diagrama do computador CS-1 mostra que a maioria é dedicada à alimentação e ao resfriamento do gigante Wafer Scale Engine (WSE) "processador em placa". Foto: Cerebras SystemsEm agosto de 2019, a Cerebras Systems e seu parceiro de fabricação TSMC anunciaram o
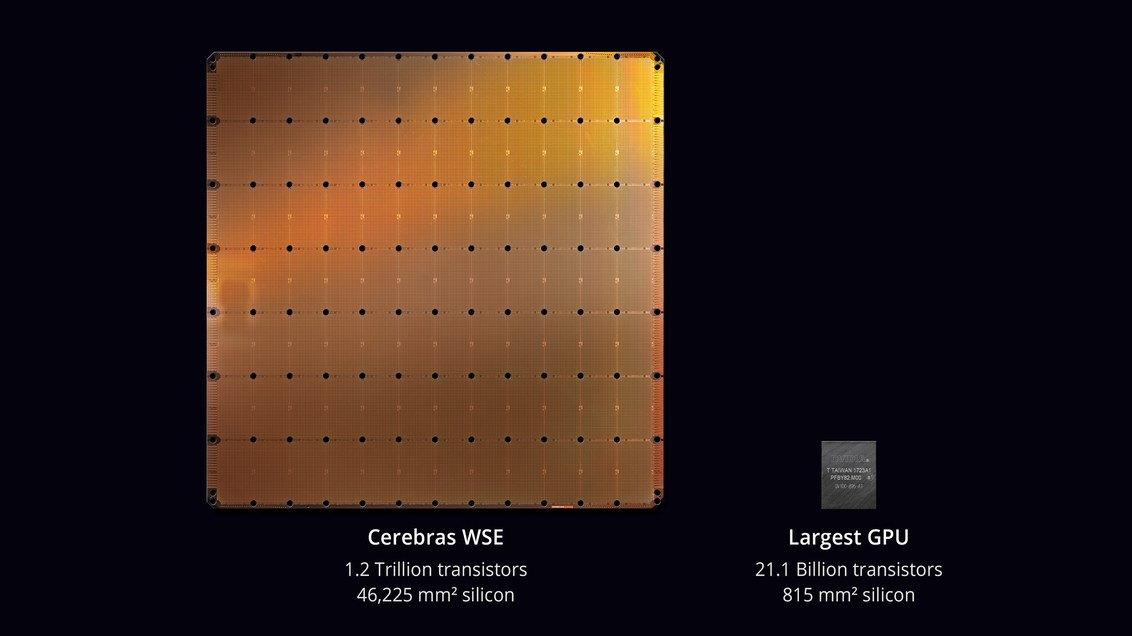
maior chip da história da tecnologia de computadores . Com uma área de 46.225 mm² e 1,2 trilhão de transistores, o chip Wafer Scale Engine (WSE) é aproximadamente 56,7 vezes maior que o maior GPU (21,1 bilhões de transistores, 815 mm²).
Os céticos disseram que desenvolver um processador não é a tarefa mais difícil. Mas aqui está como ele funcionará em um computador real? Qual é a porcentagem de trabalho defeituoso? Que energia e refrigeração serão necessárias? Quanto custa essa máquina?
Parece que os engenheiros da Cerebras Systems e TSMC foram capazes de resolver esses problemas. Em 18 de novembro de 2019, na conferência
Supercomputing 2019 , eles lançaram oficialmente o
CS-1 , "o computador mais rápido do mundo para a computação no campo de aprendizado de máquina e inteligência artificial".
As primeiras cópias do CS-1 já foram enviadas aos clientes. Um deles está instalado no Laboratório Nacional de Argonne, no Departamento de Energia dos EUA, aquele em que a montagem do supercomputador mais poderoso nos EUA a partir dos
módulos Aurora na nova arquitetura da GPU Intel começará. Outro cliente foi o Laboratório Nacional Livermore.
O processador com 400.000 núcleos foi projetado para data centers para processamento de computação no campo de aprendizado de máquina e inteligência artificial. A Cerebras alega que o computador treina sistemas de IA por ordens de magnitude com mais eficiência do que os equipamentos existentes. O desempenho CS-1 é equivalente a "centenas de servidores baseados em GPU", consumindo centenas de quilowatts. Ao mesmo tempo, ocupa apenas 15 unidades no rack do servidor e consome cerca de 17 kW.
 Processador WSE. Foto: Cerebras Systems
Processador WSE. Foto: Cerebras SystemsAndrew Feldman, CEO e co-fundador da Cerebras Systems, diz que o CS-1 é "o computador de IA mais rápido do mundo". Ele o comparou aos clusters de TPU do Google e observou que cada um deles "pega 10 racks e consome mais de 100 quilowatts para fornecer um terço do desempenho de uma única instalação do CS-1".
 Computador CS-1. Foto: Cerebras Systems
Computador CS-1. Foto: Cerebras SystemsO aprendizado de grandes redes neurais pode levar semanas em um computador padrão. Instalar um CS-1 com um chip de processador de 400.000 núcleos e 1,2 trilhões de transistores executa essa tarefa em minutos ou até segundos,
escreve o IEEE Spectrum. No entanto, a Cerebras não forneceu resultados reais para testar declarações de alto desempenho, como os
testes MLPerf . Em vez disso, a empresa estabeleceu contatos diretamente com clientes em potencial - e permitiu treinar seus próprios modelos de redes neurais no CS-1.
Essa abordagem não é incomum, dizem os analistas: "Todo mundo gerencia seus próprios modelos que eles desenvolveram para seus próprios negócios", disse
Karl Freund , analista de inteligência artificial da Moor Insights & Strategies. "Esta é a única coisa que importa para os clientes."
Muitas empresas estão desenvolvendo chips especializados para IA, incluindo representantes tradicionais da indústria, como Intel, Qualcomm, além de várias startups nos EUA, Reino Unido e China. O Google desenvolveu um chip especificamente para redes neurais - um processador tensorial ou TPU. Vários outros fabricantes seguiram o exemplo. Os sistemas de IA operam no modo multiencadeado e o gargalo está movendo dados entre os chips: "A conexão dos chips os torna mais lentos e exige muita energia",
explica Subramanian Iyer, professor da Universidade da Califórnia em Los Angeles, especializado em desenvolvendo chips para inteligência artificial. Os fabricantes de equipamentos estão explorando muitas opções diferentes. Alguns estão tentando expandir conexões entre processos.
Fundada há três anos, a startup Cerebras, que recebeu mais de US $ 200 milhões em financiamento de empreendimentos, propôs uma nova abordagem. A idéia é salvar todos os dados em um chip gigante - e, assim, acelerar os cálculos.

Toda a placa de microcircuito é dividida em 400.000 seções menores (núcleos), uma vez que algumas delas não funcionam. O chip foi projetado com a capacidade de rotear em torno de áreas defeituosas. Núcleos programáveis O SLAC (Núcleos de Álgebra Linear Esparsa) é otimizado para álgebra linear, ou seja, para cálculos no espaço vetorial. A empresa também desenvolveu a tecnologia "colheita de escassez" para melhorar o desempenho da computação sob cargas de trabalho esparsas (contendo zeros), como aprendizado profundo. Vetores e matrizes no espaço vetorial geralmente contêm muitos elementos nulos (de 50% a 98%); portanto, nas GPUs tradicionais, a maior parte da computação é desperdiçada. Por outro lado, os núcleos SLAC pré-filtram dados nulos.
As comunicações entre os núcleos são fornecidas pelo sistema Swarm com uma taxa de transferência de 100 petabits por segundo. Roteamento de hardware, latência medida em nanossegundos.
O custo de um computador não é chamado. Especialistas independentes acreditam que o preço real depende da porcentagem de casamento. Além disso, o desempenho do chip e quantos núcleos estão operacionais em amostras reais não são conhecidos com confiabilidade.
De software
A Cerebras anunciou alguns detalhes sobre a parte do software do sistema CS-1. O software permite que os usuários criem seus próprios modelos de aprendizado de máquina usando estruturas padrão como
PyTorch e
TensorFlow . O sistema distribui 400.000 núcleos e 18 gigabytes de memória SRAM no chip para as camadas da rede neural, para que todas as camadas concluam seu trabalho quase ao mesmo tempo que seus vizinhos (tarefa de otimização). Como resultado, as informações são processadas por todas as camadas sem demora. Com um subsistema de E / S de 12 portas e 100 Gigabit Ethernet, o CS-1 pode processar 1,2 terabits de dados por segundo.
A conversão da rede neural de origem em uma representação executável otimizada (Representação Intermediária de Álgebra Linear da Cerebras, CLAIR) é feita pelo Cerebras Graph Compiler (CGC). O compilador aloca recursos de computação e memória para cada parte do gráfico e os compara com a matriz de computação. Em seguida, o caminho da comunicação é calculado de acordo com a estrutura interna da placa, exclusiva para cada rede.
 Distribuição de operações matemáticas de uma rede neural por núcleos de processador. Foto : Cerebras
Distribuição de operações matemáticas de uma rede neural por núcleos de processador. Foto : CerebrasDevido ao enorme tamanho do WSE, todas as camadas em uma rede neural estão localizadas simultaneamente nela e funcionam em paralelo. Essa abordagem é exclusiva do WSE - nenhum outro dispositivo possui memória interna suficiente para caber em todas as camadas de um chip ao mesmo tempo, diz Cerebras. Essa arquitetura com a colocação de toda a rede neural em um chip oferece enormes vantagens devido ao seu alto rendimento e baixa latência.
O software pode executar a tarefa de otimização para vários computadores, permitindo que o cluster de computadores atue como uma grande máquina. Um cluster de 32 computadores CS-1 mostra um aumento de aproximadamente 32 vezes no desempenho, o que indica uma escalabilidade muito boa. Feldman diz que isso é diferente dos clusters baseados em GPU: “Hoje, quando você cria um cluster de GPUs, ele não se comporta como uma grande máquina. Você adquire muitos carros pequenos. ”
O
comunicado à imprensa dizia que o Laboratório Nacional de Argonne trabalha com a Cerebras há dois anos: "Ao implantar o CS-1, aumentamos drasticamente a velocidade do treinamento de redes neurais, o que nos permitiu aumentar a produtividade de nossa pesquisa e alcançar um sucesso significativo".
Uma das primeiras cargas do CS-1 será uma
simulação de rede neural de uma colisão de buracos negros e ondas gravitacionais, criadas como resultado dessa colisão. A versão anterior desta tarefa funcionou em 1024 de 4392 nós do supercomputador
Theta .