 Baseado nas minhas performances no Highload ++ e no DataFest Minsk 2019
Baseado nas minhas performances no Highload ++ e no DataFest Minsk 2019Para muitos, o correio hoje é parte integrante da vida online. Com sua ajuda, realizamos correspondência comercial, armazenamos todos os tipos de informações importantes relacionadas a finanças, reservas de hotel, check-out e muito mais. Em meados de 2018, formulamos uma estratégia de produto de desenvolvimento de correio. O que deve ser o correio moderno?
O correio deve ser
inteligente , ou seja, ajudar os usuários a navegar na crescente quantidade de informações: filtrar, estruturar e fornecê-las da maneira mais conveniente. Deve ser
útil , permitindo diretamente na caixa de correio resolver vários problemas, por exemplo, pagar multas (uma função que, infelizmente, uso). E, ao mesmo tempo, é claro, o correio deve fornecer proteção de informações cortando spam e protegendo contra hackers, ou seja, estar
seguro .
Essas áreas determinam várias tarefas importantes, muitas das quais podem ser efetivamente resolvidas usando o aprendizado de máquina. Aqui estão exemplos de recursos existentes desenvolvidos como parte da estratégia - um para cada direção.
- Resposta inteligente . Há uma função de resposta inteligente no e-mail. A rede neural analisa o texto da carta, entende seu significado e propósito e, como resultado, oferece as três opções de resposta mais adequadas: positiva, negativa e neutra. Isso ajuda a economizar significativamente tempo ao responder cartas e também costuma responder de maneira não padronizada e divertida.
- Agrupamento de cartas relacionadas a pedidos em lojas online. Frequentemente fazemos compras na Internet e, como regra, as lojas podem enviar várias cartas para cada pedido. Por exemplo, no AliExpress, o maior serviço, existem muitas letras para um pedido e concluímos que no caso terminal o número pode chegar a 29. Portanto, usando o modelo de Reconhecimento de entidade nomeada, selecionamos o número do pedido e outras informações no texto e no grupo todas as letras em uma linha. Também mostramos as informações básicas sobre o pedido em uma caixa separada, o que facilita o trabalho com esse tipo de letras.
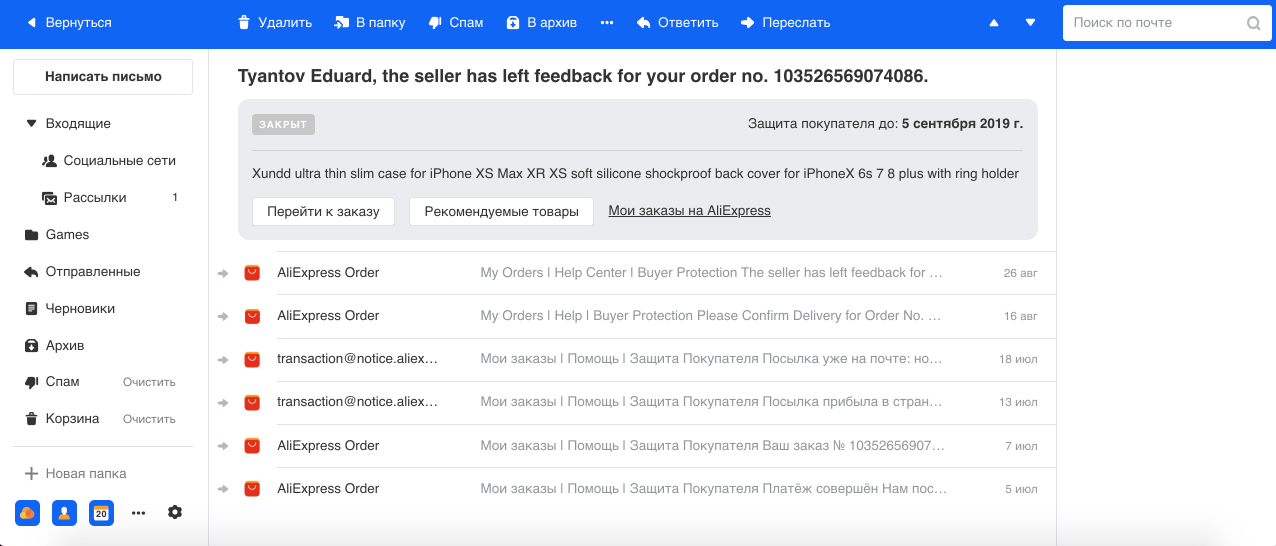
- Antiphishing . Phishing é um tipo de e-mail fraudulento particularmente perigoso, com a ajuda dos quais os invasores tentam obter informações financeiras (incluindo cartões bancários do usuário) e logins. Tais cartas imitam as reais enviadas pelo serviço, inclusive visualmente. Portanto, com a ajuda da Computer Vision, reconhecemos os logotipos e o estilo das cartas de grandes empresas (por exemplo, Mail.ru, Sberbank, Alpha) e levamos isso em conta, além de texto e outros sinais em nossos classificadores de spam e phishing.
Aprendizado de máquina
Um pouco sobre o aprendizado de máquina no correio em geral. O Mail é um sistema altamente carregado: em nossos servidores, uma média de 1,5 bilhão de cartas por dia passa para 30 milhões de usuários de DAU. Servir todas as funções e recursos necessários de cerca de 30 sistemas de aprendizado de máquina.
Cada letra passa por um transportador de classificação inteiro. Primeiro, eliminamos o spam e deixamos bons e-mails. Os usuários geralmente não percebem a operação do anti-spam, porque 95-99% do spam nem chega à pasta correspondente. O reconhecimento de spam é uma parte muito importante do nosso sistema e o mais difícil, pois na esfera anti-spam há uma constante adaptação entre os sistemas de defesa e ataque, o que fornece um desafio contínuo de engenharia para nossa equipe.
Em seguida, separamos letras de pessoas e robôs. As cartas das pessoas são mais importantes, portanto, para elas, fornecemos funções como Resposta Inteligente. As cartas dos robôs são divididas em duas partes: transacional - são cartas importantes de serviços, por exemplo, confirmação de compras ou reservas de hotéis, finanças e informações - publicidade comercial, descontos.
Acreditamos que as letras transacionais são iguais em valor à correspondência pessoal. Eles devem estar à mão, porque muitas vezes é necessário encontrar rapidamente informações sobre o pedido ou reservar um bilhete, e passamos um tempo pesquisando essas cartas. Portanto, por conveniência, as dividimos automaticamente em seis categorias principais: viagens, reservas, finanças, passagens, registros e, finalmente, multas.
Os boletins são o maior e provavelmente menos importante grupo que não requer reação instantânea, pois nada de significativo mudará na vida do usuário se ele não ler essa carta. Em nossa nova interface, os agrupamos em dois segmentos: redes sociais e boletins, limpando visualmente a caixa de correio e deixando apenas cartas importantes à vista.

Operação
Um grande número de sistemas causa muitas dificuldades na operação. Afinal, os modelos degradam-se com o tempo, como qualquer software: sinais quebram, máquinas falham, um código rola. Além disso, os dados estão mudando constantemente: novos são adicionados, o padrão de comportamento do usuário é transformado etc., portanto, o modelo sem suporte adequado funcionará cada vez mais com o passar do tempo.
Não devemos esquecer que quanto mais o aprendizado de máquina penetra na vida dos usuários, maior o impacto que eles causam no ecossistema e, como resultado, mais perdas ou lucros financeiros os participantes do mercado podem obter. Portanto, em um número crescente de áreas, os jogadores estão se adaptando ao trabalho dos algoritmos de ML (exemplos clássicos são publicidade, pesquisa e anti-spam já mencionados).
Além disso, as tarefas de aprendizado de máquina têm uma peculiaridade: qualquer alteração, embora insignificante, no sistema pode gerar muito trabalho com o modelo: trabalhar com dados, reciclagem, implantação, o que pode levar semanas ou meses. Portanto, quanto mais rápido o ambiente em que seus modelos operam, mais esforço exige o suporte deles. Uma equipe pode criar muitos sistemas e se divertir, e depois gastar quase todos os recursos em seu suporte, sem a capacidade de fazer algo novo. Uma vez, encontramos essa situação em uma equipe anti-spam. E eles chegaram à conclusão óbvia de que a manutenção deve ser automatizada.
Automação
O que pode ser automatizado? De fato, quase tudo. Eu identifiquei quatro áreas que definem a infraestrutura do aprendizado de máquina:
- coleta de dados;
- educação continuada;
- implantação;
- teste e monitoramento.
Se o ambiente é instável e muda constantemente, toda a infraestrutura em torno do modelo é muito mais importante que o próprio modelo. Pode ser o bom e velho classificador linear, mas se você aplicar corretamente os sinais e estabelecer um bom feedback dos usuários, ele funcionará muito melhor do que os modelos de última geração com todos os sinos e assobios.
Loop de feedback
Esse ciclo combina coleta de dados, treinamento adicional e implantação - de fato, todo o ciclo de atualização do modelo. Por que isso é importante? Veja a programação de registro pelo correio:

O desenvolvedor de aprendizado de máquina introduziu um modelo de antibot que impede o registro de bots no correio. O gráfico cai para um valor em que apenas usuários reais permanecem. Está tudo ótimo! Mas quatro horas se passam, os botvods apertam seus scripts e tudo volta à estaca zero. Nesta implementação, o desenvolvedor passou um mês adicionando recursos e um modelo de treinamento, mas o remetente de spam conseguiu se adaptar em quatro horas.
Para não ser tão dolorosamente doloroso e não precisar refazer tudo mais tarde, precisamos pensar inicialmente sobre como será o ciclo de feedback e o que faremos se o ambiente mudar. Vamos começar coletando dados - esse é o combustível para nossos algoritmos.
Coleta de dados
É claro que as redes neurais modernas, quanto mais dados, melhor, e elas, de fato, geram usuários do produto. Os usuários podem nos ajudar a marcar os dados, mas você não pode abusar deles, porque em algum momento os usuários estarão cansados de concluir seus modelos e mudarão para outro produto.
Um dos erros mais comuns (aqui faço uma referência a Andrew Ng) é que a orientação para as métricas no conjunto de dados de teste é muito forte, e não para o feedback do usuário, que é realmente a principal medida da qualidade do trabalho, pois criamos um produto para o usuário. Se o usuário não entender ou não gostar do trabalho do modelo, tudo será perecível.
Portanto, o usuário sempre deve poder votar, deve fornecer a ele uma ferramenta para feedback. Se acharmos que uma carta relacionada a finanças chegou na caixa, precisamos marcá-la como "financiar" e pressionar um botão no qual o usuário pode clicar e dizer que não é financiada.
Qualidade do feedback
Vamos falar sobre a qualidade do feedback do usuário. Primeiramente, você e o usuário podem colocar significados diferentes em um conceito. Por exemplo, você e os gerentes de produto pensam que "finanças" são cartas do banco e o usuário acredita que a carta da minha avó sobre a aposentadoria também se refere a finanças. Em segundo lugar, existem usuários que gostam de pressionar botões sem lógica. Terceiro, o usuário pode estar profundamente enganado em suas conclusões. Um exemplo vívido de nossa prática é a introdução do classificador de
spam nigeriano , um tipo de spam muito engraçado, quando o usuário é solicitado a coletar vários milhões de dólares de um parente distante encontrado de repente na África. Após a introdução desse classificador, verificamos os cliques "Sem spam" nessas cartas e constatamos que 80% deles são spam nigeriano suculento, o que sugere que os usuários podem ser extremamente confiáveis.
E não vamos esquecer que não apenas as pessoas podem apertar os botões, mas todos os tipos de bots que fingem ser um navegador. Portanto, o feedback bruto não é bom para o aprendizado. O que pode ser feito com essa informação?
Usamos duas abordagens:
- Feedback de ML relacionado . Por exemplo, temos um sistema antibot online, que, como mencionei, toma uma decisão rápida com base em um número limitado de sinais. E existe um segundo sistema lento que funciona ex post. Ela tem mais dados sobre o usuário, sobre o comportamento dele etc. Como resultado, a decisão mais equilibrada é tomada, respectivamente, com maior precisão e perfeição. Você pode direcionar a diferença no trabalho desses sistemas no primeiro como dados para treinamento. Assim, um sistema mais simples sempre tentará se aproximar de um desempenho mais complexo.
- Classificação de cliques . Você pode simplesmente classificar cada clique do usuário, avaliar sua validade e capacidade de uso. Fazemos isso no correio anti-spam usando os atributos do usuário, seu histórico, os atributos do remetente, o próprio texto e o resultado dos classificadores. Como resultado, obtemos um sistema automático que valida o feedback do usuário. E como é necessário treiná-lo com muito menos frequência, seu trabalho pode se tornar o principal para todos os outros sistemas. A precisão é a principal prioridade desse modelo, porque o treinamento de um modelo em dados imprecisos é repleto de consequências.
Enquanto limpamos os dados e reciclamos nossos sistemas ML, não devemos esquecer os usuários, porque para nós milhares e milhões de erros em um gráfico são estatísticas e, para um usuário, todo bug é uma tragédia. Além do fato de que o usuário precisa, de alguma forma, conviver com seu erro no produto, ele, após o feedback, espera excluir uma situação semelhante no futuro. Portanto, você deve sempre dar aos usuários não apenas a oportunidade de votar, mas também corrigir o comportamento dos sistemas de ML, criando, por exemplo, heurísticas pessoais para cada clique de feedback, no caso de correio, pode ser possível filtrar essas mensagens por remetente e cabeçalho para esse usuário.
Você também precisa incluir o modelo com base em alguns relatórios ou chamadas de suporte no modo semiautomático ou manual, para que outros usuários também não sofram problemas semelhantes.
Heurística para a Aprendizagem
Existem dois problemas com essas heurísticas e muletas. A primeira é que é difícil manter um número cada vez maior de muletas, sem mencionar a qualidade e o desempenho a longa distância. O segundo problema é que o erro pode não ser a frequência e alguns cliques para treinar novamente o modelo não serão suficientes. Parece que esses dois efeitos não relacionados podem ser substancialmente nivelados se a abordagem a seguir for aplicada.
- Crie uma muleta temporária.
- Os dados são direcionados para o modelo, que são recuperados regularmente, incluindo os dados recebidos. Aqui, é claro, é importante que a heurística tenha alta precisão para não reduzir a qualidade dos dados no conjunto de treinamento.
- Em seguida, desligamos o monitoramento para a operação da muleta e, se depois de algum tempo a muleta não funcionar mais e for completamente coberta pelo modelo, você poderá removê-la com segurança. Agora, é improvável que esse problema se repita.
Portanto, o exército de muletas é muito útil. O principal é que seu serviço é urgente, não permanente.
Educação continuada
A reciclagem é o processo de adicionar novos dados obtidos como resultado do feedback dos usuários ou de outros sistemas e treinar o modelo existente sobre eles. Pode haver vários problemas com a reciclagem:
- Um modelo pode simplesmente não apoiar o ensino superior e aprender apenas do zero.
- Em nenhum lugar do livro da natureza está escrito que a educação continuada certamente melhorará a qualidade do trabalho em produção. Muitas vezes acontece exatamente o oposto, ou seja, apenas a deterioração é possível.
- Mudanças podem ser imprevisíveis. Este é um ponto bastante sutil que identificamos para nós mesmos. Mesmo que o novo modelo no teste A / B mostre resultados semelhantes em comparação ao atual, isso não significa que funcionará de forma idêntica. Seu trabalho pode diferir em um por cento, o que pode trazer novos erros ou retornar os antigos já corrigidos. Nós e os usuários já sabemos como conviver com os erros atuais e, quando ocorre um grande número de novos erros, o usuário também pode não entender o que está acontecendo, porque espera um comportamento previsível.
Portanto, a coisa mais importante na reciclagem é garantida para melhorar o modelo, ou pelo menos para não piorá-lo.
A primeira coisa que vem à mente quando falamos sobre educação continuada é a abordagem do Aprendizado Ativo. O que isso significa? Por exemplo, o classificador determina se a carta se refere a finanças e, em torno de sua fronteira de tomada de decisão, adicionamos uma seleção de exemplos marcados. Isso funciona bem, por exemplo, na publicidade, onde há muito feedback e você pode treinar o modelo online. E, se houver pouco feedback, obtemos uma amostra fortemente tendenciosa em relação à produção da distribuição de dados, com base na qual é impossível avaliar o comportamento do modelo durante a operação.
De fato, nosso objetivo é preservar padrões antigos, modelos já conhecidos e adquirir novos. Aqui, a continuidade é importante. O modelo, que costumamos lançar com grande dificuldade, já funciona, para que possamos focar em seu desempenho.
No correio, diferentes modelos são usados: árvores, lineares, redes neurais. Para cada um, criamos nosso próprio algoritmo de reciclagem. No processo de reciclagem, obtemos não apenas novos dados, mas muitas vezes novos recursos que levaremos em consideração em todos os algoritmos abaixo.
Modelos lineares
Digamos que temos uma regressão logística. Compomos o modelo de perda a partir dos seguintes componentes:
- LogLoss em novos dados;
- regularizamos o peso de novos sinais (não tocamos nos antigos);
- aprendemos com dados antigos para preservar padrões antigos;
- e, talvez, o mais importante: anexamos a Regularização Harmônica, que garante uma ligeira alteração nos pesos em relação ao modelo antigo de acordo com a norma.
Como cada componente de perda possui coeficientes, podemos escolher os valores ideais para nossa tarefa de validação cruzada ou com base nos requisitos do produto.

Árvores
Vamos para as árvores de decisão. Filmamos o seguinte algoritmo de reciclagem de árvores:
- Uma floresta de 100 a 300 árvores trabalha no produto, que foi treinado no antigo conjunto de dados.
- No final, excluímos M = 5 partes e adicionamos 2M = 10 novas, treinadas em todo o conjunto de dados, mas com alto peso a partir dos novos dados, o que naturalmente garante uma alteração incremental no modelo.
Obviamente, com o tempo, o número de árvores aumenta significativamente, e elas devem ser periodicamente reduzidas para se ajustarem aos horários. Para fazer isso, usamos a agora onipresente Destilação de Conhecimento (KD). Brevemente sobre o princípio de seu trabalho.
- Temos o atual modelo "complexo". Começamos no conjunto de dados de treinamento e obtemos a distribuição de probabilidade das classes na saída.
- Em seguida, ensinamos o modelo do aluno (um modelo com menos árvores neste caso) a repetir os resultados do modelo, usando a distribuição de classes como uma variável de destino.
- É importante observar aqui que não usamos a marcação do conjunto de dados de nenhuma maneira e, portanto, podemos usar dados arbitrários. Obviamente, usamos uma amostra de dados do fluxo de combate como uma amostra de treinamento para o modelo do aluno. Assim, o conjunto de treinamento nos permite garantir a precisão do modelo, e uma amostra do fluxo garante um desempenho semelhante na distribuição da produção, compensando o deslocamento da amostra de treinamento.
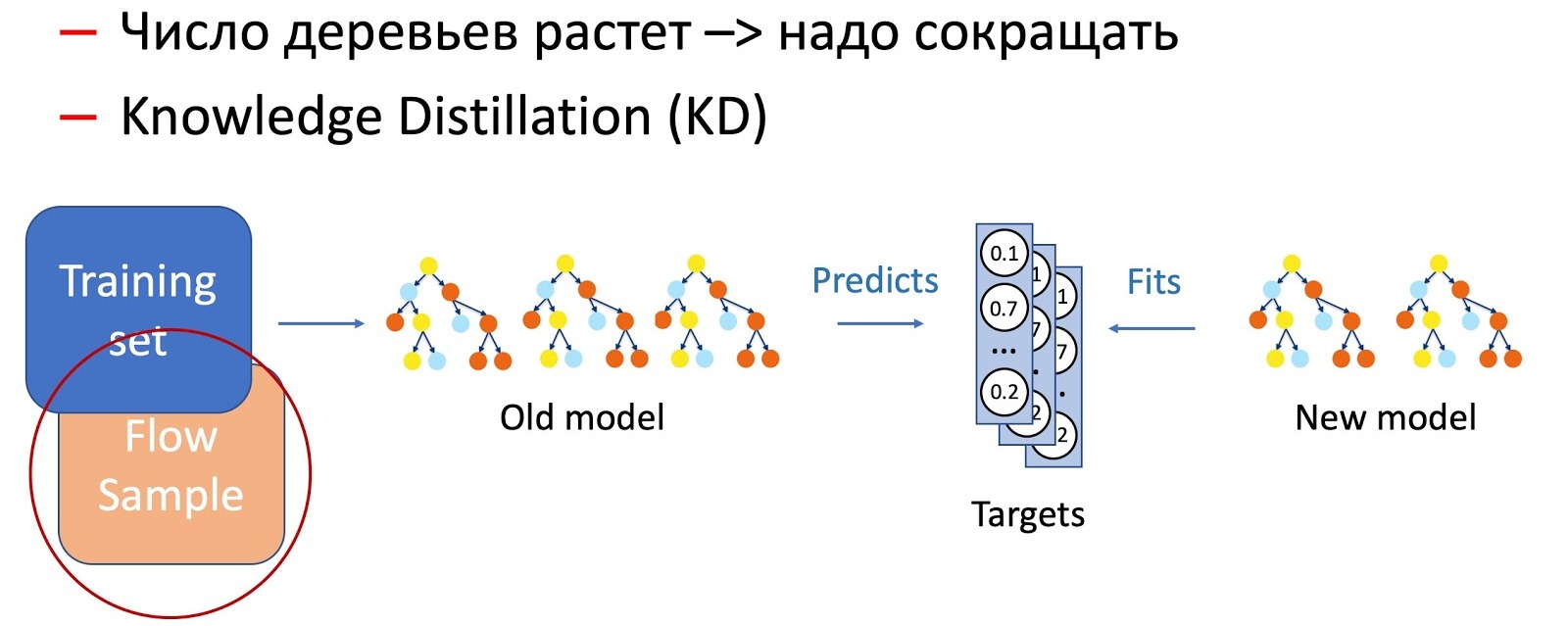
A combinação dessas duas técnicas (adicionando árvores e reduzindo periodicamente seu número usando a Destilação de conhecimento) garante a introdução de novos padrões e a continuidade completa.
Com a ajuda da KD, também realizamos a distinção de operações com características de um modelo, por exemplo, remoção de características e trabalho em passes. No nosso caso, temos vários recursos estatísticos importantes (por remetentes, hashes de texto, URLs etc.) armazenados em um banco de dados que tem a propriedade de recusar. O modelo, é claro, não está pronto para esse desenvolvimento de eventos, pois não há situações de falha no conjunto de treinamento. Nesses casos, combinamos KD e técnicas de aumento: ao treinar para uma parte dos dados, excluímos ou zeramos os sinais necessários e tomamos os rótulos (saídas do modelo atual) como os iniciais, o modelo do aluno nos ensina a repetir essa distribuição.
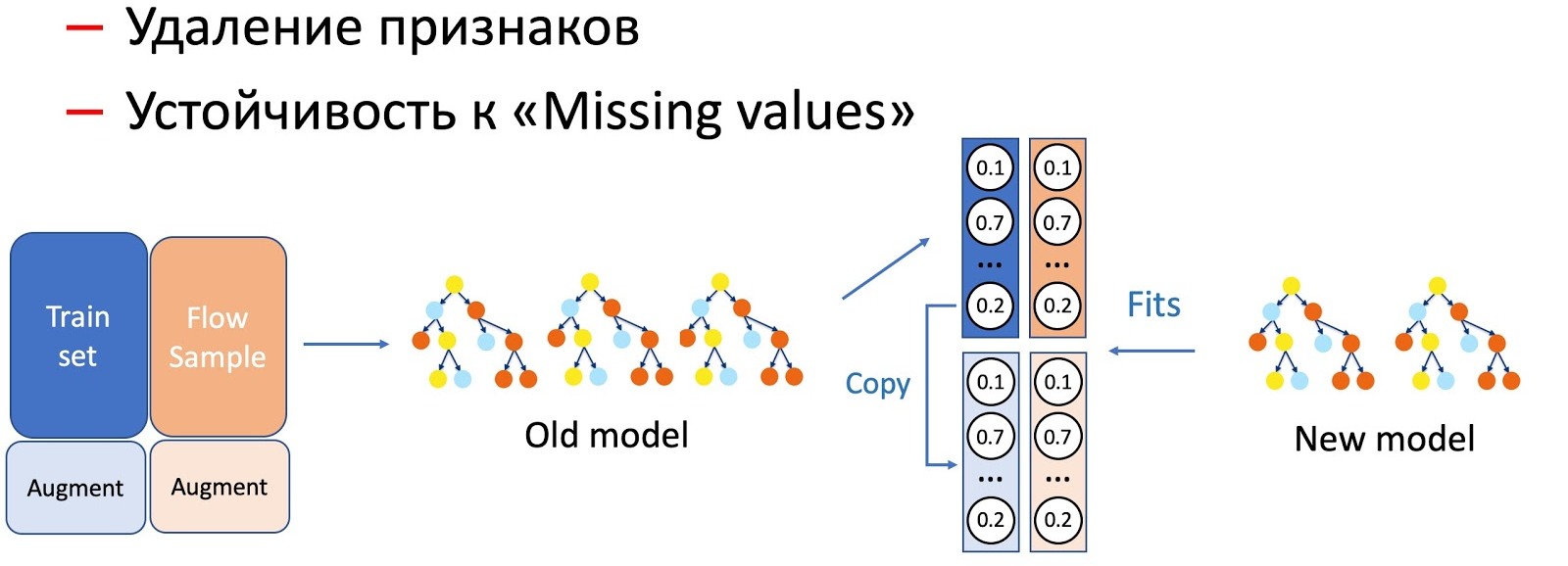
Percebemos que quanto mais séria a manipulação dos modelos ocorre, maior a porcentagem de fluxo de amostra necessária.
Para remover recursos, a operação mais simples, apenas uma pequena parte do fluxo é necessária, pois apenas alguns recursos mudam e o modelo atual estudado no mesmo conjunto - a diferença é mínima. Para simplificar o modelo (reduzindo o número de árvores em várias vezes), já é necessário 50 a 50. E omitir recursos estatísticos importantes que afetam seriamente o desempenho do modelo requer ainda mais fluxo para uniformizar o trabalho do novo modelo, que é resistente a omissões, em todos os tipos de letras.
Texto rápido
Vamos para o FastText. Deixe-me lembrá-lo de que a representação (incorporação) de uma palavra consiste na soma da incorporação da própria palavra e de todas as letras N-gramas, geralmente trigramas. Como os trigramas podem ser bastante, o Hashing de balde é usado, ou seja, a conversão de todo o espaço em um determinado hashmap fixo. Como resultado, a matriz de pesos é obtida pela dimensão da camada interna pelo número de palavras + balde.
Durante a educação continuada, novos sinais aparecem: palavras e trigramas. No pós-treinamento padrão do Facebook, nada de significativo acontece. Somente pesos antigos com entropia cruzada em novos dados são reciclados. , , , , . FastText. ( ), - , .

CNN
. CNN , , , . , , . Triplet Loss (
).
Triplet Loss
Triplet Loss. , . , , .

, , . , . , .
- . (Finetuning): , . , — . , v1 v2. .

, , . , , CNN Fast Text . , ( , , ). . , .

. CNN Fast Text , — . Knowledge Distillation.
, . , , .
, .
/B-
, , , , - . , , , A/B-. . 5 %, 30 %, 50 % 100 % , . - , , , . 50 % , , .
A/B- . , A/B- ( 6 24 ), . , /B- ( ), A/B- . , , .
, A/B-. , Precision, Recall , . , , (Complexity) . , -, , , A/B-.

A/B-.
&
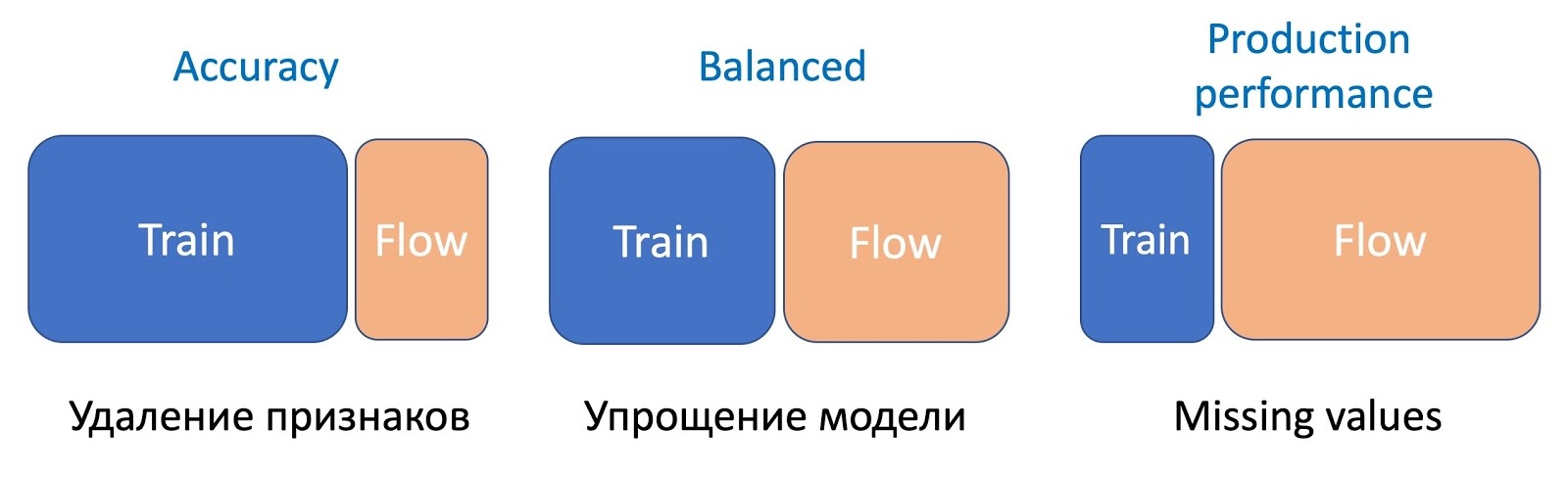
, , , , , . , — , .
, — . , . , — - , .
, . ( ). - . , , «» . , , . .

. , , . KL- A/B- , .
, . , NER- -, , . !
Sumário
.
- . : , . , — , ML-. , , , .
- . — , -. , .
- . . , .
, , ML-, , .