Processadores multinúcleo são comuns. Mais cedo ou mais tarde, qualquer programador prático terá que entrar no labirinto da programação multithread e se encontrar com os "monstros" que a habitam. Vamos falar sobre por onde começar dessa maneira e quais ferramentas e abordagens ajudarão a sair vitoriosas. Fiz esse relatório para futuros participantes do
estágio durante o
ano inteiro na Yandex.
- Meu nome é Seva Minkov. Eu trabalho no departamento de infraestrutura em nuvem do departamento de pesquisa. Eu lido principalmente com o back-end. Eu escrevo em linguagens diferentes, mas na maioria das vezes são Java e linguagens em execução na Java Virtual Machine (JVM).
Nossa equipe está desenvolvendo uma nuvem interna na qual quase todos os serviços Yandex são lançados - conhecidos publicamente como Search, Mail e Alice, além de vários serviços internos, máquinas virtuais, além de tarefas de curta duração do MapReduce e tarefas de aprendizado de máquina.
Nossa nuvem não é estática: a empresa está crescendo, o número de serviços e os recursos que consomem está aumentando. E nossa equipe frequentemente enfrenta os desafios de dimensionar e melhorar o desempenho. Conseguimos isso usando todas as ferramentas disponíveis, incluindo a escala vertical - ou seja, acelerando componentes individuais do sistema até reescrever alguns algoritmos de thread único para que eles trabalhem mais rapidamente. Fazemos escala horizontal: esmagando o sistema em pequenas partes para obter melhor desempenho adicionando servidores, processadores, núcleos, etc.
E a programação multithread nos ajuda muito nisso. Hoje falaremos sobre ele - de onde veio, por que é relevante; o que é um modelo de memória e como ele geralmente é representado em Java. Abordaremos alguns aspectos práticos de como testar seus aplicativos e verificar sua correção.
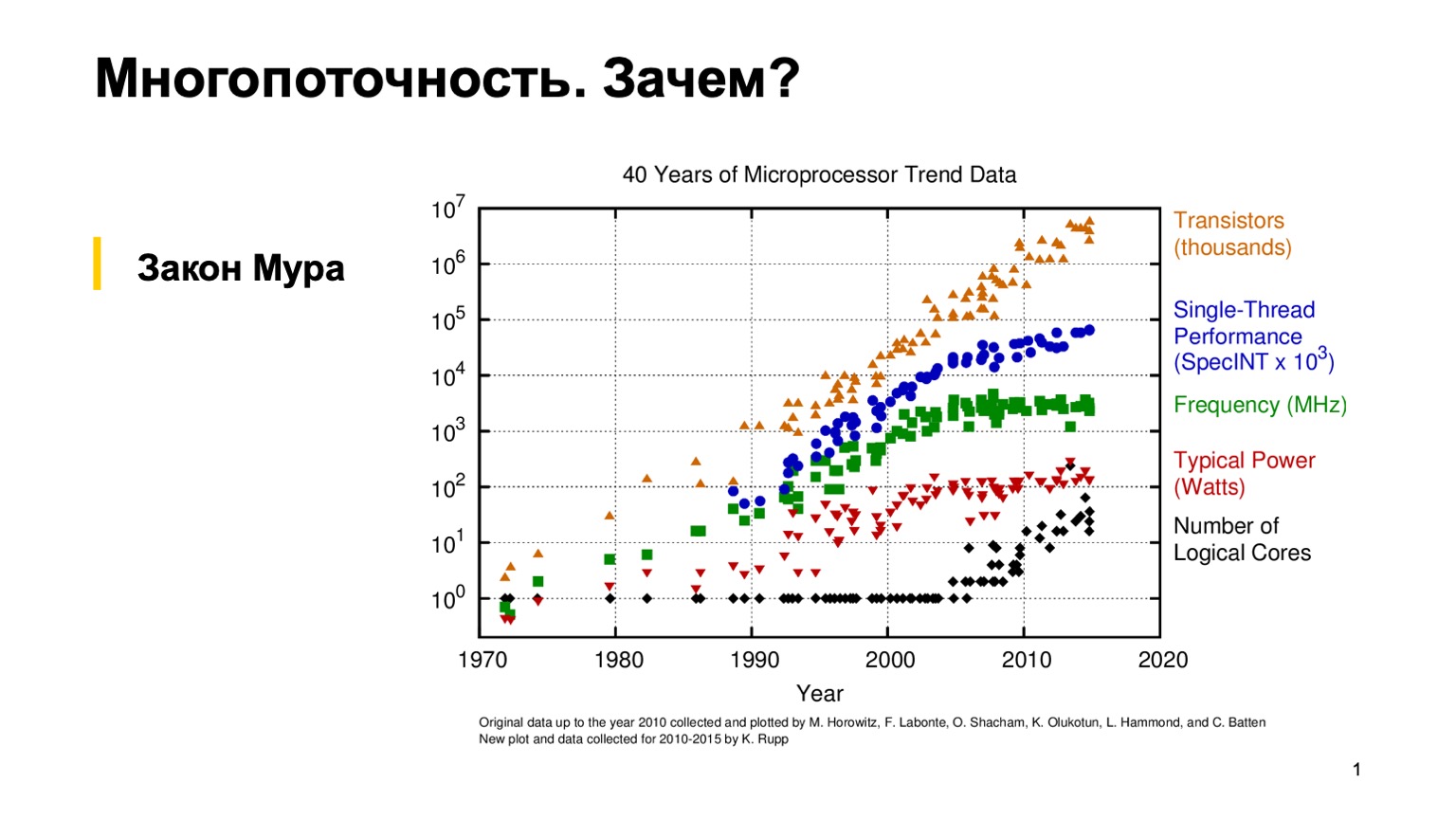
Para começar, vamos olhar para este gráfico interessante, que mostra as tendências nas características dos microprocessadores nos últimos 40 anos. Cerca de 10 a 15 anos atrás, quando a grama era mais verde e os processadores eram de rosca única, um programador comum poderia escrever um programa de rosca única correto e depois confiar na lei empírica de Moore. Ele diz que os processadores são duas vezes mais rápidos a cada dois anos. Como você pode ver, por volta de 2005, por várias razões, os fabricantes de microprocessadores mudaram para uma arquitetura de vários núcleos e começaram a aumentar o número de núcleos lógicos. E o ganho de desempenho de um único núcleo deixou de obedecer à lei de Moore, e o poder de processamento de um núcleo começou a crescer mais lentamente. Isso fez uma revolução, e os programadores comuns tiveram que usar a programação paralela para usar esse mesmo ganho de desempenho.
Como estamos praticando, tentaremos escrever um programa multithread simples e ver por si mesmo como ele funciona.
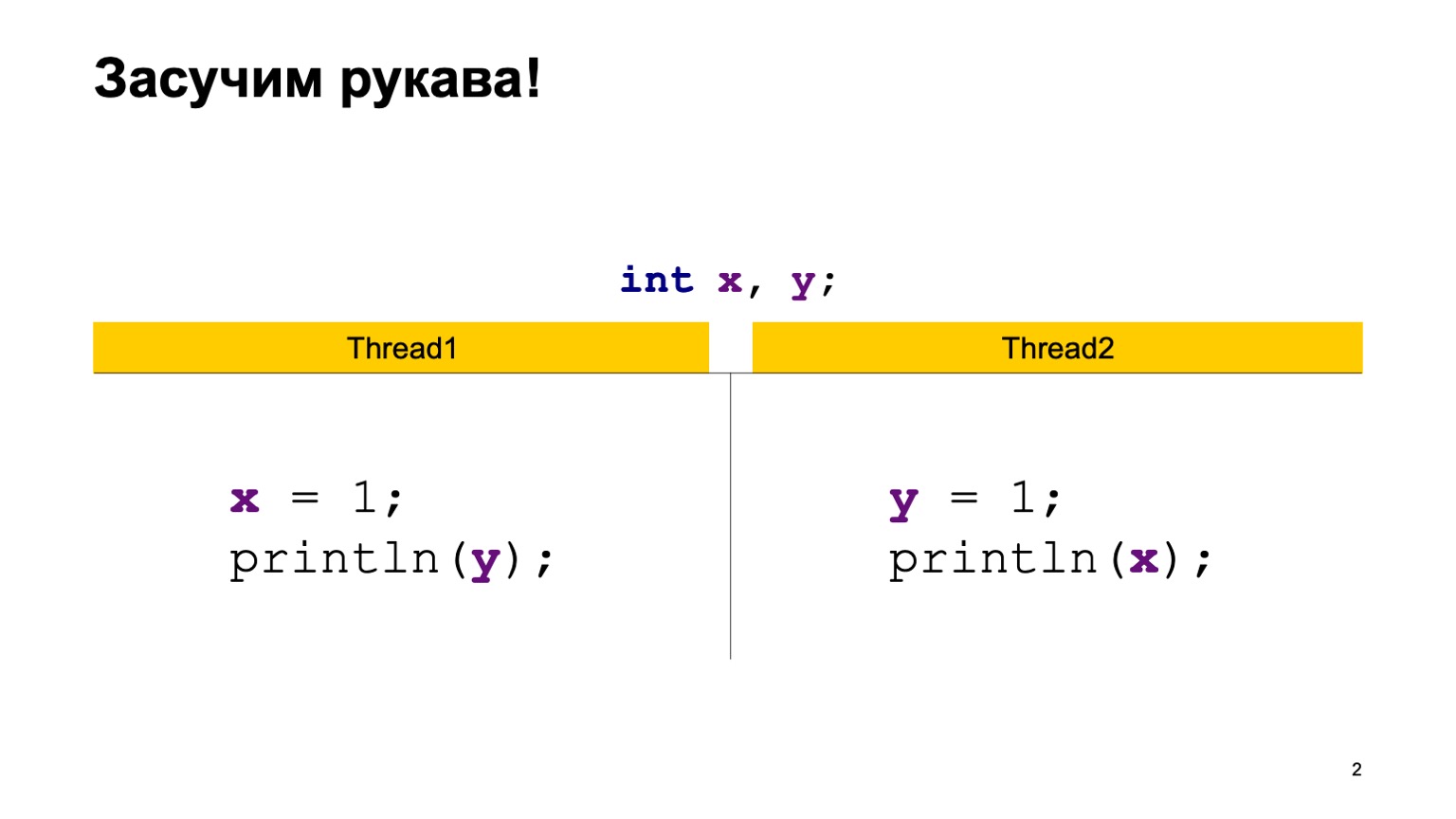
Como exemplo, vamos assumir uma tarefa bastante simples de leitura cruzada de registros. Vamos ter duas variáveis compartilhadas X e Y, primeiro inicializadas com o valor padrão (zero) e dois fluxos. Cada thread grava em uma variável e lê outra. Nesse caso, o Thread1 grava uma unidade em X e lê Y. O segundo thread faz o mesmo, apenas para trás.
Uma implementação simples de Java pode se parecer com isso.

Escreveremos a classe ReadWriteTest, ela terá duas variáveis estáticas X e Y. Diretamente no método principal, construímos duas threads Thread1 e Thread2, fornecemos a cada uma delas uma função lambda de entrada que será executada no momento em que a thread for executada. Coloque o código do slide anterior lá e inicie dois threads.
A ordem na qual os threads iniciam é, de certa forma, imprevisível. Depende de como o sistema operacional encadeamentos. Por conseguinte, podemos ter versões diferentes. Parece entender como tudo isso funciona, teremos que executar esse programa várias vezes, agregar a saída e ver com que frequência essa ou aquela resposta será encontrada no programa.

Para não reinventar a roda, podemos usar uma ferramenta pronta. Isso é chamado jcstress, o utilitário de testes de estresse de concorrência em Java que faz parte do projeto OpenJDK.
Este utilitário fornece alguma estrutura para escrever testes de estresse. Nesse caso, o código do slide anterior é reescrito com bastante facilidade. Primeiro, vamos pendurar a anotação jcstress Test na classe, o que simplesmente torna nossos scripts de teste visíveis para o utilitário. Também a marcamos com a classe State, que diz que a classe contém dados que podem mudar: sendo modificados e lidos a partir de diferentes fluxos. Declaramos dois métodos, thread1 e thread2, e os marcamos com a anotação Actor. A anotação de ator significa que o método deve ser executado em um encadeamento separado. jcstress garante que cada método será executado em um thread separado em exatamente uma instância da classe State. A ordem na qual eles serão lançados não é especificada especificamente. E o resultado será gravado em algum objeto II_Result mostrado no slide. Podemos assumir que essa é uma tupla de dois valores numéricos, que são apresentados apenas pelo método de Injeção de Dependência, sobre o qual Kirill falou em um relatório anterior.
Antes de iniciar este teste, vamos pensar sobre quais conclusões os comandos podem dar e quais valores podemos adicionar em r1 e em r2.

Para fazer isso, usamos o chamado modelo de alternância. De uma forma ou de outra, cada uma das operações: leitura ou escrita, é realizada em alguma ordem. Basta apenas percorrer todas essas opções e ver quais resultados teremos.

Suponha que uma das possíveis variantes de eventos seja que o thread um seja completamente executado antes do thread dois. Primeiro, adicionamos um a X e lemos zero de Y, pois não havia entradas. Então eles escreveram um em Y e leram um de X, já que o primeiro fluxo já havia conseguido fazer isso.
A primeira resposta é zero e um.

A segunda variante do desenvolvimento de eventos é exatamente o oposto: o fluxo dois foi executado antes do fluxo um.

Conseqüentemente, obtemos um resultado espelhado de um zero.

Existem cerca de quatro opções que dão o mesmo resultado quando temos a execução de threads completamente confusa. Por exemplo, registramos uma unidade em um fluxo em X, no segundo, conseguimos ter uma unidade em Y e calculamos um. Você pode ver quais outras opções existem como exercício em casa.

Parece que examinamos todas as opções possíveis, não há mais nada. Vamos executar o utilitário e ver que conclusão ele dá.

A saída parece uma tabela. A primeira coluna lista os resultados que adicionamos em II_Result - o utilitário executa esse código milhões de vezes - e o número de casos em que um resultado específico foi encontrado. Mas provavelmente este relatório não teria sido se tudo tivesse sido tão simples.
De fato, nesta conclusão, também podemos ver o resultado zero-zero, o que é difícil de explicar com o modelo de alternância. Parece que uma das opções possíveis é que alguém diretamente no código de fluxo pegou e reorganizou as linhas.
Vamos pensar por que isso aconteceu e como podemos viver com isso. Peço também que você preste atenção ao fato de que a opção one-one foi encontrada especificamente na minha máquina extremamente raramente. Das 130 milhões de apresentações, apenas 154 apresentações resultaram no resultado de um. E, pelo contrário, o zero-zero ocorre com muita frequência, em quase 30% dos casos.

Então, para resumir alguns resultados intermediários que todos vimos com você. Primeiro de tudo, poderíamos entender que a interação dos fluxos através da memória não é trivial. O modelo de rotação que usamos não funciona. Vimos algum rearranjo. Isso pode acontecer por vários motivos.
Por exemplo, pudemos ver alguns "efeitos relativísticos" do ferro. Isso pode ser pensado da seguinte forma: em um ciclo de clock de um processador de 3 GHz, a luz viaja cerca de 10 cm no vácuo. O protocolo de leitura e gravação na memória do processador é complicado e, às vezes, são necessárias centenas de ciclos de clock para transferir o valor de um núcleo para outro. Assim, um núcleo pode parecer ver o passado. O resultado após o registro ocorreu, mas vemos o valor antigo. Além disso, os processadores também não ficam parados e podem alterar as instruções em alguns locais.
Compiladores otimizadores modernos podem levar à mesma permutação. Para alcançar o desempenho máximo de thread único, eles também podem trocar instruções para que isso não prejudique a correção de um programa de thread único. Mas em programas multithread pode levar a efeitos interessantes que vimos.
E a segunda - provavelmente a principal conclusão: vimos que programas multithread não são determinados fundamentalmente. Os programas de thread único dependem principalmente de alguns invariantes na entrada e na saída e são determinísticos; dado que o gerador de números aleatórios e a entrada do usuário são parâmetros de entrada.
Isso torna as coisas muito complicadas: é difícil entender o que o programa faz e é difícil testá-lo.
Sobre a complexidade dos testes, podemos acrescentar que o mesmo resultado foi encontrado apenas 154 vezes em 130 milhões de chamadas. A probabilidade de ocorrência desse resultado é de um milionésimo. Na produção, isso significa que esse bug pode ser reproduzido após semanas. E certamente acontecerá em algum lugar no domingo à noite, quando você não esperava isso.

Vamos pensar em como devemos ser e o que geralmente queremos da nossa língua para dormir em paz no domingo à noite. Primeiro, precisamos de uma ferramenta que nos permita prever o comportamento do programa e fazer julgamentos sobre sua execução. Em segundo lugar, precisamos de ferramentas de linguagem que nos permitam influenciar as permutações e efeitos - eles podem ser do hardware, do compilador etc. Gostaria de saber menos sobre como um processador específico funciona, quais otimizações o compilador pode fazer e usar a abreviação que vieram do mundo Java. Escreva uma vez, execute em qualquer lugar - escreva uma vez o código multithread correto para que ele funcione em todas as plataformas.

Essas perguntas e requisitos que listamos surgiram nas mentes dos desenvolvedores por muito tempo, teóricos e profissionais. Como qualquer tarefa complexa com um alto nível de complexidade, ela foi resolvida com a introdução do conceito de alguma máquina abstrata. Todos nós, desenvolvedores de linguagens de programação de alto nível, não escrevemos para nenhum hardware específico, nem para um modelo de processador, mas escrevemos alguma máquina abstrata. E a especificação da linguagem é projetada para descrever seu comportamento de maneira a reconciliar esses três mundos. Por um lado, permita que desenvolvedores de compiladores e processadores façam suas otimizações e expliquem levemente seus cérebros para nós, programadores que já escrevem em um idioma específico.
O modelo de memória ocupa uma posição central nesta máquina abstrata. Ela deve responder a uma pergunta: se eu ler uma variável X em algum fluxo, o resultado de qual das últimas entradas posso ver lá? Uma tentativa de formalizar o modelo de memória foi feita pela primeira vez na linguagem Java; todos os outros modelos de memória apareceram posteriormente. Digamos que o C ++ 11 seja quase uma pasta de cópia do modelo de memória Java com algumas alterações.
Havia vários modelos de memória em Java. Inicialmente, o chamado modelo de memória em forma de sino, foi reconhecido como malsucedido, pois dificultava o trabalho dos programadores que escrevem em Java e proibia algumas otimizações para o compilador, que são bastante apropriadas para si. Consequentemente, como parte do processo da comunidade JSR-133, um modelo de memória moderno foi escrito.
Como temos as escrituras na forma de uma especificação, vamos tentar examiná-las e entender o que realmente está acontecendo por dentro.

Há algum problema. Levante as mãos, quem abriu a especificação do idioma e leu o que estava acontecendo lá. E quantos de vocês leram o modelo de memória do parágrafo 17.4? Uma pequena surpresa espera por você. A especificação da linguagem é basicamente descrita em uma linguagem bastante compreensível. Mas o modelo de memória está cheio, digamos, de algum hardcore matemático. Existem inclusões em grego, muitos termos matemáticos do fechamento transitivo da série, a união de duas ordens, etc.
Infelizmente, não há outro caminho. A única coisa em que você pode confiar ao escrever programas multithread é a especificação. Ela terá que ler e entender. Eu recomendo você. Além disso, quando li a especificação pela primeira vez, tive essas impressões.
Por que isso é tão difícil? Eu segui o caminho errado e te aviso muito para agir como eu.
Eu peguei, procurei na Internet o que é um modelo de memória. Encontrei um livro chamado JSR-133 Cookbook for Compiler Writers. Ela descreve como um desenvolvedor de compilador pode implementar esse modelo de memória de maneira simples. O problema é que esta é uma implementação específica e não pode ser usada para julgar o modelo de memória inteiro em geral.
De qualquer forma, vamos tentar fazer uma pequena tentativa nas principais conclusões que podem ser entendidas no modelo de memória Java.

Pode haver muitas execuções do seu programa multithread. Nós mesmos vimos isso no exemplo de nosso programa antes. No exemplo mais simples, já tivemos quatro resultados de sua implementação. E a tarefa do modelo de memória Java é dizer qual dessas execuções está correta e qual delas deve ser proibida. E postula três coisas. A primeira é que, dentro da estrutura de um thread, sua tarefa é executada pseudo-seqüencialmente. Isso implica que o compilador pode trocar operações, o processador também pode executar instruções em paralelo, trocá-las. Mas eles devem fazer isso para que os efeitos visíveis da execução do seu programa sejam os mesmos, como se fossem executados diretamente seqüencialmente.
Em segundo lugar, os chamados significados fora do ar, tirados do nada, são proibidos no idioma. Infelizmente, não temos tempo para mostrá-lo, mas há casos em que o compilador pode realmente fazer uma conversão que tudo estará correto em um programa de thread único e você pode ter um registro em um programa de vários threads que não fez.
Dessa forma, o modelo de memória diz que a leitura de qualquer variável retornará o valor padrão ou alguns dos resultados da gravação que já foi feita por outro comando. E as ações restantes podem ser interpretadas como seqüenciais, se estiverem conectadas por uma relação de ordem parcial, antes do ocorrido. E agora é o único lugar onde precisamos de matemática. Relação parcial, isso ocorre porque nem todas as operações de leitura e gravação de variáveis são conectadas por relação. Possui propriedades de reflexividade, transitividade e anti-simetria.

Vamos falar com mais detalhes sobre o que acontece antes de si mesmo. A primeira regra é que ele vincula todas as operações em um único encadeamento. Se você escreveu dentro de um segmento que X é igual a um, Y é igual a um; afirma-se que as operações de gravação em X estão relacionadas a acontecer antes de Y. Ou seja, X acontece antes de Y. E também vincula algumas ações especiais, as chamadas ações de sincronização. Leia mais na especificação. Por exemplo, isso é escrever e ler de uma variável volátil, bloquear / desbloquear em um monitor, entrar no bloco sincronizado e sair do bloco sincronizado. Um ponto muito importante é que todas as ações de sincronização no seu programa veem os threads exatamente na mesma ordem, como se estivessem sendo executados um por um.
E acontece - antes vincula alguns pares dessas ações. Não importa em quais ações de sincronização de encadeamento ocorrem. É importante que eles passem, por exemplo, sobre uma variável volátil. A especificação diz, digamos, que a gravação na variável volátil ocorra antes de qualquer outra ação subsequente. Isso se refere precisamente à maneira pela qual tivemos ações de sincronização.
E o mais importante de tudo isso é a regra acontece antes da consistência, que apenas responde à pergunta mais importante sobre o modelo de memória. Pode ser interpretado da seguinte maneira. Se houver uma cadeia de operações de leitura / gravação em uma variável e elas estiverem conectadas por uma cadeia de relacionamentos anteriores, a leitura deve definitivamente ver o último registro dessa cadeia. Se não estiver lá, você poderá ver qualquer outro valor, qualquer outro registro ou valor padrão. Agora você pode expirar, com as definições básicas que terminamos.
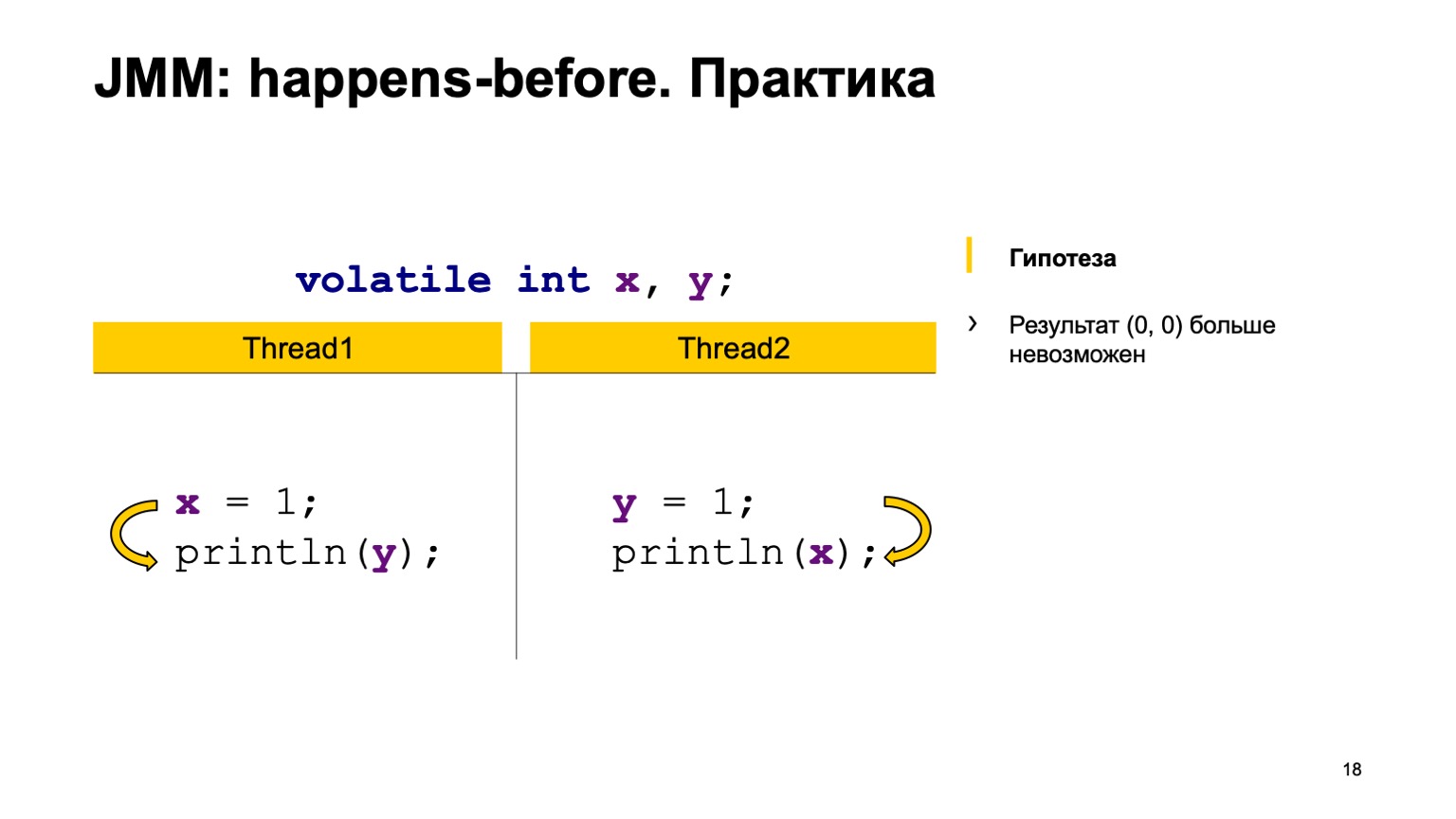
Vamos tentar testar a teoria na prática? Vamos dar um exemplo com uma leitura cruzada de registros e apenas adicionar o modificador volátil às variáveis X e Y. Vamos tentar provar a hipótese de que não veremos mais o valor zero-zero. Para fazer isso, basta usar as regras que eu expressei acima.
Nós vamos providenciar os eventos antes em um tópico. Escrever para X acontece - antes da leitura de Y e no segundo segmento. Escrever para Y acontece - antes de ler de X.
synchronization actions: , Y, , Y. , .
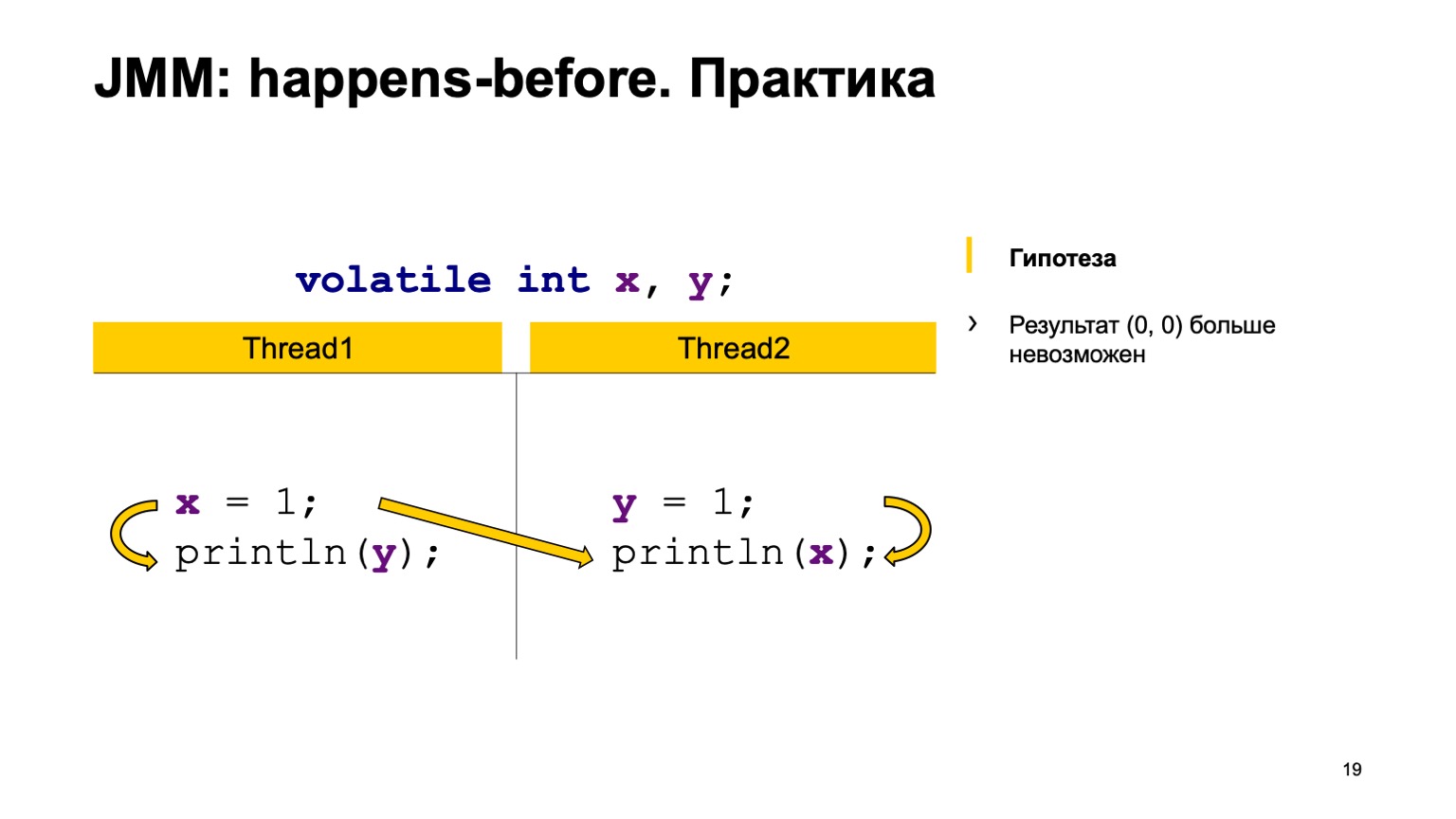
, , ( happens-before). , Y. Y , , . . , -, -.
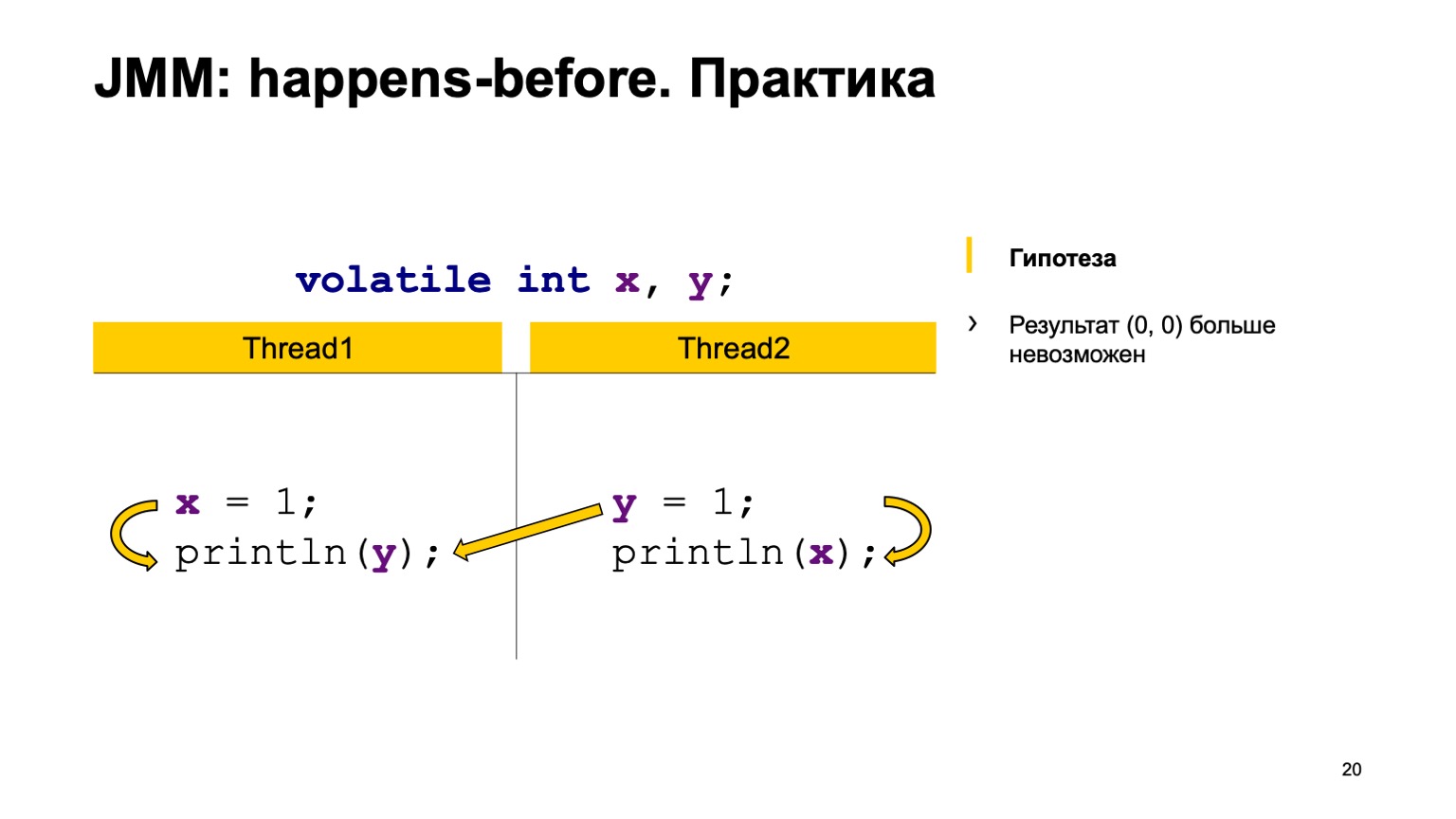
, . — Y happens-before Y. . , , -, -. .

. volatile. , , , . happens-before — . .

, . volatile Z volatile, . , Z; , , , Z. happens-before . , Z , . .
, , — put value. — get value . happens-before , , put value happens-before get value. , happens-before , volatile, . , , — put happens-before get.

, . -, . , , . , . , , . , . , , , , .
-, , jcstress. : , JVM . , .
, . — «The Art of Multiprocessor Programming» . , happens-before, , . . — «Java Concurrency in Practice» . , . , , . . .
, performance- Oracle, Red Hat. , Java- , . JMM.
Você pode ler o blog de Roman Elizarov . Ele ensinou, na minha opinião, a programação multithread do ITMO. Ele tem um blog um pouco abandonado, mas você pode ler, pesquisar suas palestras e discursos no YouTube. Em geral, muito adequado, eu aconselho. Obrigado a todos.