As linguagens OO mais populares fornecem uma ferramenta como um modificador para acessar um método ou campo. E isso é bom para programadores experientes, mas não é por onde começar o encapsulamento. Abaixo vou explicar o porquê.
 Isenção de responsabilidade.
Isenção de responsabilidade. Este artigo não é um plano de ação e não afirma que existe a única maneira razoavelmente correta de ocultar dados. Este artigo pretende oferecer ao leitor uma possível nova perspectiva sobre o encapsulamento. Existem muitas situações em que os modificadores de acesso são preferíveis, mas esse não é um motivo para silenciar as interfaces.
Em geral, o encapsulamento é definido como um meio de ocultar a implementação interna de um objeto do cliente, a fim de manter a integridade do objeto e ocultar a complexidade dessa implementação muito interna.
Existem várias maneiras de conseguir essa ocultação. Um é o uso de modificadores de acesso, o outro é o uso de interfaces (protocolos, arquivos de cabeçalho, ...). Existem outros recursos complicados, mas o artigo não é sobre eles.
Os modificadores de acesso à primeira vista podem parecer mais poderosos em termos de ocultar a implementação, pois eles controlam cada campo individualmente e oferecem mais opções de acesso. Na realidade, isso é parcialmente um atalho para a criação de várias interfaces para a classe. Os modificadores de acesso oferecem oportunidades não maiores que as interfaces, porque se expressam, exceto por um detalhe. Sobre ela abaixo.
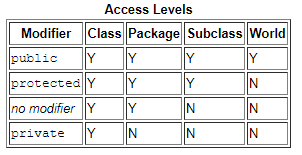 Visibilidade do campo indicada por diferentes modificadores de acesso em Java.
Visibilidade do campo indicada por diferentes modificadores de acesso em Java.O trecho de código abaixo mostra uma classe com modificadores de acesso a métodos e representações equivalentes na forma de interfaces.
public class ConsistentObject { public void methodA() { } protected void methodB() { } void methodC() { } private void methodD() { } } public interface IPublicConsistentObject { void methodA() { } } public interface IProtectedConsistentObject: IPublicConsistentObject { void methodB() { } } public interface IDefaultConsistentObject: IProtectedConsistentObject { void methodC() { } }
Protocolos têm várias vantagens. Basta mencionar que este é o principal meio de implementar o polimorfismo no POO, que chega aos recém-chegados muito mais tarde do que poderia.
A única dificuldade de abordar os protocolos é que você precisa controlar o processo de criação de objetos. A geração de modelos é necessária precisamente para proteger códigos perigosos que contêm tipos específicos de códigos puros que funcionam com interfaces. Observando esta regra simples, obtemos o mesmo encapsulamento que o uso de qualificadores, mas, ao mesmo tempo, obtemos mais flexibilidade.
Esse código em c #
public class DataAccessObject { private void readDataFromFixedSource() {
será equivalente ao das capacidades do cliente.
public class DataAccessObjectFactory { public IDataAccessObject createNew() { return new DataAccessObject(); } } public interface IDataAccessObject { byte[] getData(); } class DataAccessObject: IDataAccessObject { void readDataFromFixedSource() {
Devido à existência de modificadores de acesso, os iniciantes não saberão sobre interfaces por muito tempo. Por esse motivo, eles não usam o poder real da OLP. Ou seja, há alguma substituição de conceitos. Os modificadores de acesso são, sem dúvida, um atributo do OOP, mas também arrastam a cobertura das interfaces que abrem o OOP com muito mais força.
Além disso, as interfaces fazem com que você escolha conscientemente quais recursos um cliente pode receber de um objeto. Ou seja, temos a oportunidade de fornecer protocolos não relacionados a diferentes clientes, enquanto modificadores não fazem distinção entre clientes. Esta é uma grande vantagem a favor de interfaces.