Quero compartilhar com você minha primeira experiência bem-sucedida na restauração de todas as funcionalidades do banco de dados Postgres. Conheci o DBMS do Postgres há meio ano, antes disso eu não tinha nenhuma experiência em administração de banco de dados.

Trabalho como engenheiro semi-DevOps em uma grande empresa de TI. Nossa empresa está desenvolvendo software para serviços altamente carregados, mas sou responsável pelo desempenho, manutenção e implantação. Eles definem uma tarefa padrão para mim: atualizar o aplicativo em um servidor. O aplicativo é escrito no Django, durante a atualização, as migrações são realizadas (alterando a estrutura do banco de dados) e, antes desse processo, removemos o dump completo do banco de dados através do programa pg_dump padrão.
Ocorreu um erro inesperado ao remover o dump (a versão do Postgres é 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed. pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 pg_dump: The command was: COPY public.ws_log_smevlog [...] pg_dunp: [parallel archtver] a worker process dled unexpectedly
O erro
"página inválida no bloco" indica problemas no nível do sistema de arquivos, o que é muito ruim. Em vários fóruns, eles sugeriram criar
FULL VACUUM com a opção
zero_damaged_pages para resolver esse problema. Bem, popprobeum ...
Preparação para Recuperação
ATENÇÃO! Certifique-se de fazer backup do Postgres antes de qualquer tentativa de restaurar o banco de dados. Se você tiver uma máquina virtual, pare o banco de dados e tire uma captura instantânea. Se não for possível tirar uma captura instantânea, pare o banco de dados e copie o conteúdo do diretório Postgres (incluindo arquivos wal) para um local seguro. O principal em nosso negócio é não piorar as coisas. Leia
isto .
Como o banco de dados funcionou para mim como um todo, me limitei ao despejo de banco de dados usual, mas excluí a tabela com dados danificados (opção
-T, --exclude-table = TABLE no pg_dump).
O servidor era físico, era impossível tirar um instantâneo. O backup foi removido, siga em frente.
Verificação do sistema de arquivos
Antes de tentar restaurar o banco de dados, é necessário garantir que tudo esteja em ordem com o próprio sistema de arquivos. E, no caso de erros, corrija-os, pois, caso contrário, você só poderá piorar as coisas.
No meu caso, o sistema de arquivos com o banco de dados foi montado em
“/ srv” e o tipo era ext4.
Paramos o banco de dados:
systemctl stop postgresql@9.5-main.service e verificamos se o sistema de arquivos não é usado por ninguém e se pode ser desmontado usando o
comando lsof :
lsof + D / srvEu ainda tinha que parar o banco de dados redis, pois ele também usava
"/ srv" . Em seguida, desmontei
/ srv (umount).
A verificação do sistema de arquivos foi realizada usando o utilitário
e2fsck com a opção -f (
Forçar verificação mesmo se o sistema de arquivos estiver marcado como limpo ):
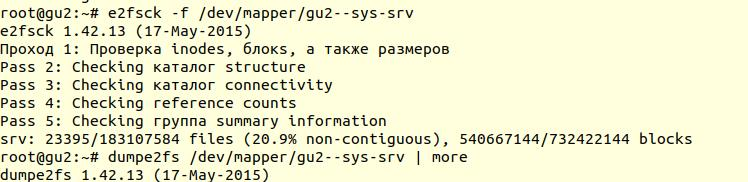
Em seguida, usando o utilitário
dumpe2fs (
sudo dumpe2fs / dev / mapper / gu2 - sys-srv | grep verificado ), você pode verificar se a verificação foi realmente executada:
 O e2fsck
O e2fsck diz que não foram encontrados problemas no nível do sistema de arquivos ext4, o que significa que você pode continuar tentando restaurar o banco de dados ou retornar ao
vácuo (é claro, é necessário montar o sistema de arquivos novamente e iniciar o banco de dados).
Se o seu servidor for físico, verifique o status dos discos (via
smartctl -a / dev / XXX ) ou do controlador RAID para garantir que o problema não esteja no nível do hardware. No meu caso, o RAID acabou sendo “ferro”, então pedi ao administrador local para verificar o status do RAID (o servidor estava a várias centenas de quilômetros de mim). Ele disse que não houve erros, o que significa que podemos definitivamente começar a restauração.
Tentativa 1: zero_damaged_pages
Nós nos conectamos ao banco de dados através da conta psql com direitos de superusuário. Precisamos exatamente do superusuário, porque somente ele pode alterar a opção
zero_damaged_pages . No meu caso, este é o postgres:
psql -h 127.0.0.1 -U postgres -s [database_name]A opção
zero_damaged_pages é necessária para ignorar erros de leitura (no site do postgrespro):
Quando um título de página danificado é detectado, o Postgres Pro geralmente relata um erro e aborta a transação atual. Se o parâmetro zero_damaged_pages estiver ativado, o sistema emitirá um aviso, limpará a página danificada na memória e continuará o processamento. Esse comportamento destrói dados, ou seja, todas as linhas na página danificada.
Ative a opção e tente criar mesas de vácuo completas:
VACUUM FULL VERBOSE
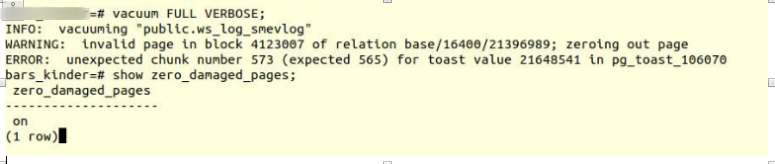
Infelizmente, falha.
Encontramos um erro semelhante:
INFO: vacuuming "“public.ws_log_smevlog” WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070
pg_toast - o mecanismo para armazenar "dados longos" no Postgres, se eles não couberem na mesma página (8kb por padrão).
Tentativa 2: reindexar
A primeira dica do Google não ajudou. Após alguns minutos de pesquisa, encontrei uma segunda dica - para tornar a
reindexação uma tabela danificada. Eu conheci esse conselho em muitos lugares, mas não inspirou confiança. Faça reindexar:
reindex table ws_log_smevlog
 reindexação
reindexação concluída sem problemas.
No entanto, isso não ajudou, o
VACUUM FULL caiu com um erro semelhante. Desde que me acostumei a falhas, comecei a procurar mais conselhos na Internet e me deparei com um
artigo bastante interessante.
Tentativa 3: SELECT, LIMIT, OFFSET
O artigo acima sugeriu examinar a tabela linha por linha e excluir os dados problemáticos. Para começar, era necessário olhar para todas as linhas:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; done
No meu caso, a tabela continha
1.628.991 linhas! De uma maneira boa, era necessário cuidar do
particionamento dos dados , mas esse é um tópico para uma discussão separada. Era sábado, executei este comando no tmux e fui dormir:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; done
De manhã, decidi verificar como as coisas estavam indo. Para minha surpresa, descobri que em 2 horas apenas 2% dos dados foram digitalizados! Eu não queria esperar 50 dias. Outra falha completa.
Mas eu não desisti. Eu me perguntava por que a verificação demorou tanto. Na documentação (novamente no postgrespro), descobri:
OFFSET indica para pular o número especificado de linhas antes de começar a produzir linhas.
Se OFFSET e LIMIT forem especificados, o sistema ignorará primeiro as linhas OFFSET e começará a contar as linhas para limitar LIMIT.
Ao usar LIMIT, também é importante usar a cláusula ORDER BY para que as linhas de resultado sejam retornadas em uma ordem específica. Caso contrário, subconjuntos imprevisíveis de seqüências serão retornados.
Obviamente, o comando acima foi errado: primeiro, não havia
ordem , o resultado poderia ser errado. Em segundo lugar, o Postgres primeiro teve que digitalizar e pular as linhas OFFSET e, com um aumento no
OFFSET, o desempenho diminuiria ainda mais.
Tentativa 4: remover o despejo em forma de texto
Além disso, uma ideia aparentemente brilhante veio à minha mente: remover o despejo em forma de texto e analisar a última linha registrada.
Mas primeiro,
vejamos a estrutura da tabela
ws_log_smevlog :

No nosso caso, temos uma coluna
"id" , que continha um identificador exclusivo (contador) para a linha. O plano era este:
- Começamos a remover o despejo em forma de texto (na forma de comandos sql)
- Em um determinado momento, o despejo seria interrompido devido a um erro, mas o arquivo de texto ainda seria salvo no disco
- Observamos o final do arquivo de texto e, assim, encontramos o identificador (id) da última linha que foi filmada com sucesso
Comecei a remover o despejo em forma de texto:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dump
O dump dump, como esperado, foi interrompido com o mesmo erro:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
Além disso, através da
cauda, olhei para o final do despejo (
cauda -5 ./my_dump.dump ) e descobri que o despejo foi interrompido na linha com o ID
186 525 . "Então, o problema está na linha do ID 186 526, está quebrado e precisa ser excluído!", Pensei. Mas, fazendo uma solicitação ao banco de dados:
“
Selecione * de ws_log_smevlog em que id = 186529 ” verificou-se que estava tudo bem com esta linha ... Linhas com índices 186 530 - 186 540 também funcionavam sem problemas. Outra "idéia brilhante" falhou. Mais tarde, percebi por que isso aconteceu: ao excluir / alterar dados da tabela, eles não são excluídos fisicamente, mas são marcados como "tuplas mortas"; o
vácuo automático vem e marca essas linhas como excluídas e permite o uso dessas linhas novamente. Para entender, se os dados na tabela forem alterados e o vácuo automático estiver ativado, eles não serão armazenados sequencialmente.
Tentativa 5: SELECT, FROM, WHERE id =
Falhas nos fortalecem. Você nunca deve desistir, você precisa ir até o fim e acreditar em si mesmo e em suas capacidades. Portanto, decidi tentar mais uma opção: basta visualizar todas as entradas no banco de dados, uma de cada vez. Conhecendo a estrutura da minha tabela (veja acima), temos um campo de ID exclusivo (chave primária). Na tabela, temos 1.628.991 linhas e o
id fica em ordem, o que significa que podemos simplesmente iterá-los um por vez:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Se alguém não entender, o comando funciona da seguinte forma: ele varre a tabela linha por linha e envia stdout para
/ dev / null , mas se o comando SELECT falhar, o texto do erro será exibido (stderr é enviado ao console) e uma linha contendo o erro será exibida (graças a ||, que significa que o select teve problemas (o código de retorno do comando não é 0)).
Eu tive sorte, criei índices no campo
id :

Isso significa que encontrar a linha com o ID desejado não deve demorar muito. Em teoria, deve funcionar. Bem, execute o comando no
tmux e vá dormir.
Pela manhã, descobri que cerca de 90.000 registros foram visualizados, o que representa pouco mais de 5%. Excelente resultado quando comparado com o método anterior (2%)! Mas eu não queria esperar 20 dias ...
Tentativa 6: SELECT, FROM, ONDE id> = e id <
Um excelente servidor foi alocado para o cliente no banco de dados: processador dual
Intel Xeon E5-2697 v2 , em nossa localização havia até 48 threads! A carga do servidor era média, poderíamos levar cerca de 20 threads sem problemas. RAM também foi suficiente: até 384 gigabytes!
Portanto, o comando precisava ser paralelizado:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Aqui foi possível escrever um script bonito e elegante, mas eu escolhi a maneira mais rápida de paralelizar: divida manualmente o intervalo 0-1628991 em intervalos de 100.000 registros e execute 16 comandos do formulário separadamente:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done
Mas isso não é tudo. Em teoria, conectar-se a um banco de dados também leva algum tempo e recursos do sistema. Conectar 1.628.991 não era muito razoável, concorda. Portanto, vamos extrair 1000 linhas em uma conexão em vez de uma. Como resultado, a equipe se transformou nisso:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Abra 16 janelas na sessão tmux e execute os comandos:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Um dia depois, obtive os primeiros resultados! Ou seja (os valores XXX e ZZZ não foram preservados):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070 829000 ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070 146000
Isso significa que temos três linhas contendo um erro. O ID do primeiro e do segundo registros de problemas estava entre 829.000 e 830.000, o ID do terceiro estava entre 146.000 e 147.000. Em seguida, bastava encontrar o valor exato dos IDs dos registros de problemas. Para fazer isso, consulte nosso intervalo com registros de problemas na etapa 1 e identifique o ID:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
Final feliz
Encontramos as linhas problemáticas. Entramos no banco de dados via psql e tentamos removê-los:
my_database=# delete from ws_log_smevlog where id=829417; DELETE 1 my_database=# delete from ws_log_smevlog where id=829449; DELETE 1 my_database=# delete from ws_log_smevlog where id=146911; DELETE 1
Para minha surpresa, as entradas foram excluídas sem problemas, mesmo sem a opção
zero_damaged_pages .
Então eu me conectei ao banco de dados, fiz
VACUUM FULL (acho que não era necessário fazê-lo) e, finalmente, removi o backup com sucesso usando
pg_dump . O despejo estrelou sem erros! O problema foi resolvido de uma maneira tão estúpida. Não havia limite para a alegria, depois de tantas falhas, conseguimos encontrar uma solução!
Agradecimentos e Conclusões
Esta é a minha primeira experiência em restaurar um banco de dados Postgres real. Vou me lembrar dessa experiência por um longo tempo.
E, finalmente, gostaria de agradecer ao PostgresPro pela documentação traduzida para o russo e pelos
cursos on-line totalmente gratuitos que ajudaram muito na análise do problema.