No processo de trabalhar em um grande projeto, emprestar módulos de outras pessoas e soluções prontas para uso economiza uma quantidade enorme de tempo do desenvolvedor e do investidor. Um dos maiores repositórios dessas soluções é de longe o github.
Existe um pequeno truque sob o gato que eu uso ao pesquisar e escolher as soluções do github.
Imagine a tarefa de desenvolver um grande sistema
OSINT , digamos que precisamos examinar todas as soluções disponíveis no github nessa direção. usamos a pesquisa global padrão do github para a palavra-chave osint. Temos 1124 repositórios, a capacidade de filtrar pelo local da pesquisa por palavra-chave (código, confirmações, emissão, etc.), pelo idioma de execução. E classifique por vários atributos (como a maioria / menos partidas, forquilhas, etc.).
A decisão é tomada de acordo com vários critérios: funcionalidade, número de estrelas, suporte ao projeto, linguagem de desenvolvimento.
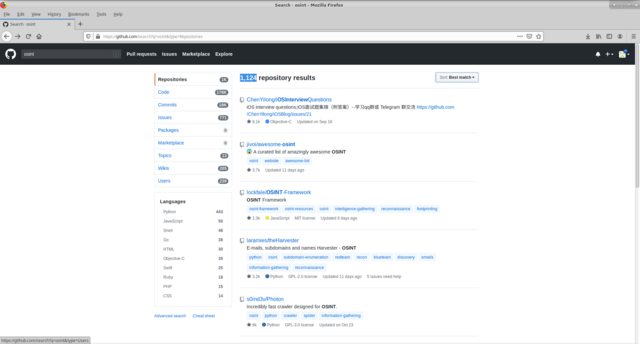
As decisões que me interessaram foram resumidas em uma tabela em que os campos indicados acima foram preenchidos, anotações apropriadas foram feitas com base nos resultados de um teste específico.
A desvantagem dessa visão, parece-me, é a falta de capacidade de classificar e filtrar simultaneamente vários campos.
Usando
api_github e python3, descrevemos um script simples e simples que forma um documento csv para nós com os campos de interesse para nós.
Execute o script
python3 git_repo_search.py osint
nós temos
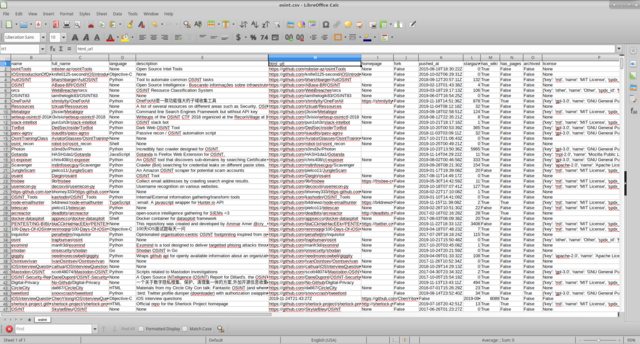
Parece-me que trabalhar com informações é mais conveniente, depois de ocultar colunas desnecessárias.
Código
aquiEspero que alguém venha a calhar.