Na véspera do lançamento do curso Backend PHP Developer, tivemos uma lição aberta tradicional . Dessa vez, nos familiarizamos com o conceito Serverless, conversamos sobre sua implementação na AWS, discutimos os princípios de operação, montagem e lançamento e também construímos um simples PHP-bot PHP baseado no AWS Lambda.
Palestrante - Alexander Pryakhin , CTO da Westwing Rússia.

Uma breve excursão pela história

Como chegamos a uma vida em que a computação sem servidor apareceu? Obviamente, eles apareceram não apenas assim, mas se tornaram uma continuação lógica das tecnologias de virtualização existentes.

O que geralmente virtualizamos? Por exemplo, um processador. Você também pode virtualizar a memória realçando certas áreas da memória e tornando-as acessíveis a alguns usuários e inacessíveis a outros. Você pode virtualizar uma rede VPN. E assim por diante

A virtualização é boa porque utilizamos melhor os recursos e aumentamos a produtividade. Mas também há desvantagens, por exemplo, ao mesmo tempo, havia problemas de compatibilidade. No entanto, praticamente não há arquiteturas incompatíveis com as máquinas virtuais modernas.
O próximo ponto negativo é que adicionamos uma camada adicional de abstração, adicionamos um hipervisor, adicionamos uma máquina virtual por si só e, é claro, podemos perder um pouco de velocidade. Um pouco complicado e o uso do servidor.
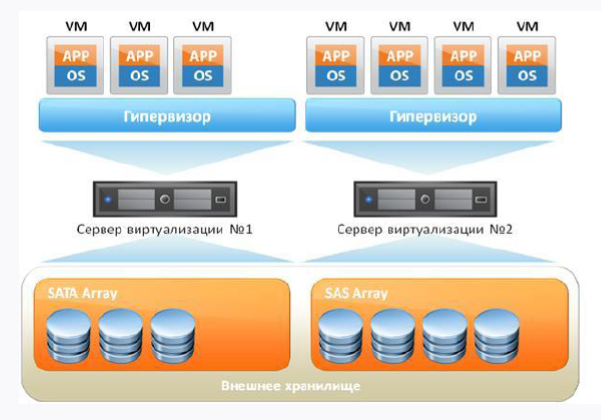
Se levarmos uma máquina virtual padrão com você, será algo parecido com isto:

Em primeiro lugar, temos um servidor de ferro e, em segundo lugar, o sistema operacional no qual nosso hipervisor girará. Além disso, nossas máquinas virtuais estão girando, nas quais há um sistema operacional convidado, bibliotecas e aplicativos. Se você pensar logicamente, veremos alguma sobrecarga na presença do SO convidado, porque na verdade gastamos recursos extras.
Como posso resolver o problema de sobrecarga? Recusando máquinas virtuais e colocando um sistema de gerenciamento de contêiner no topo do sistema operacional principal. Obviamente, o sistema mais popular agora é o Docker Engine. Em seguida, as bibliotecas dentro do contêiner usarão o kernel host do sistema operacional.

Dessa forma, removemos a sobrecarga, mas o Docker também não é o ideal e possui seus próprios problemas e recursos de trabalho que nem todo mundo gosta.
O principal a entender é que o Docker e a máquina virtual são abordagens diferentes e não há necessidade de igualá-las. O Docker não é um microvirtual com o qual você pode trabalhar como em uma máquina virtual, porque o contêiner é para isso e para o contêiner. Mas o contêiner nos permite oferecer flexibilidade e uma abordagem completamente diferente da entrega contínua, quando entregamos coisas à produção e entendemos que elas já estão testadas e funcionando.
Tecnologia em nuvem
Com o desenvolvimento da virtualização, as tecnologias em nuvem também começaram a se desenvolver. Essa é uma boa solução, mas vale a pena mencionar imediatamente que as nuvens não são uma bala de prata e nem uma panacéia para todos os males. Aqui não se pode deixar de lembrar uma citação famosa:
"Quando ouço alguém divulgando a nuvem como uma bala mágica para todos os problemas de computação, substituo silenciosamente" nuvem "por" palhaço "e continuo com um sorriso zen."
Amy rich
No entanto, para empresas de médio porte que desejam receber um certo nível de serviço e tolerância a falhas sem grandes injeções financeiras, as nuvens são uma opção. E para muitas empresas, manter seu data center com o mesmo SLA será muito mais caro do que ser servido na nuvem. Além disso, podemos usar as nuvens para nossas necessidades, pois elas fornecem algumas coisas com apenas alguns cliques do mouse, o que é muito conveniente. Por exemplo, a capacidade de levantar uma máquina virtual ou rede em apenas alguns cliques.
Sim, existem restrições, por exemplo, a 152ª Lei Federal que proíbe o armazenamento de dados pessoais no exterior, portanto a mesma Amazônia não será adequada para nós durante uma auditoria. Não se esqueça do bloqueio de fornecedor. Muitas soluções em nuvem não são portadas uma para a outra, embora o mesmo armazenamento compatível com S3 seja suportado pela maioria dos provedores.
As nuvens nos oferecem a oportunidade de receber diferentes níveis de serviço sem um conhecimento restrito. Quanto menos conhecimento você precisar, mais pagaremos. Na figura abaixo, é possível observar a pirâmide, onde, de baixo para cima, é exibida a diminuição dos requisitos de conhecimento técnico ao usar a nuvem:

Sem servidor e FaaS (função como serviço)
Sem servidor é uma maneira bastante jovem de executar scripts nas nuvens, por exemplo, como a AWS (em termos da AWS, o servidor é implementado no Lambda). * As abordagens AaS listadas na pirâmide acima já são familiares: IaaS (EC2, VDS), PaaS (hospedagem compartilhada), SaaS (Office 365, Tilda). Portanto, sem servidor é uma implementação da abordagem FaaS. E essa abordagem consiste em fornecer ao usuário uma plataforma pronta para o desenvolvimento, lançamento e gerenciamento de determinadas funcionalidades sem a necessidade de auto-preparação e configuração.
Imagine que você tem uma máquina envolvida no processamento noturno de documentos, executando tarefas das 00:00 às 18:00 e, durante o restante das horas, ela fica ociosa. A questão é: por que pagar por isso durante o dia? E por que não usar recursos gratuitos para outra coisa? Esse desejo de otimização e o desejo de gastar dinheiro apenas com o que você realmente usa e levou ao surgimento do FaaS.
Sem servidor é um recurso para executar código e nada mais. Isso não significa que não há servidor por trás do nosso script - é verdade, mas, na verdade, não temos nenhum recurso alocado especificamente no qual nosso Lambda será lançado. Quando executamos nosso script, a microestrutura se desdobra imediatamente, e esse não é o seu problema em princípio - você só pensa que tem o código executado e não precisa pensar em mais nada.
Isso requer, é claro, uma certa abordagem para o desenvolvimento do seu código. Por exemplo, você não pode armazenar nada neste ambiente, é necessário retirar tudo. Se forem dados, será necessário um banco de dados externo, se for um log, um serviço de log externo, se for um arquivo, e um armazenamento de arquivo externo. Felizmente, qualquer provedor sem servidor oferece a capacidade de se conectar a sistemas externos.
Você só tem código, trabalha no paradigma Stateless, não tem estado. Para o mesmo mundo do PHP, isso significa, por exemplo, que você pode esquecer o mecanismo de sessão padrão. Em princípio, você pode até criar seu Serverless, e recentemente em Habré havia um artigo sobre esse assunto .
A idéia principal do Serverless é que a infraestrutura não exija suporte da equipe. Tudo cai sobre os ombros da plataforma, pela qual você, de fato, paga dinheiro. Dos pontos negativos - você não controla o ambiente de execução e não sabe onde o que é executado.
Então sem servidor:
- não significa ausência física do servidor;
- não é um assassino de virtualoks e Docker;
- não exagere aqui e agora.
Sem servidor deve ser empurrado conscientemente e deliberadamente. Por exemplo, se você precisar testar rapidamente uma hipótese sem envolver metade da equipe. Então você obtém a função como serviço. A função responderá a alguns eventos e, como há uma reação a eventos, esses eventos devem ser chamados por alguma coisa - para isso, existem muitos gatilhos na mesma AWS.
Recursos do FaaS:
- infraestrutura não requer configuração;
- Modelo de evento “pronto para uso”;
- Sem estado;
- o dimensionamento é muito fácil e é realizado automaticamente de acordo com as necessidades do usuário.
AWS Lambda
A primeira implementação do FaaS disponível ao público é o AWS Lambda. Se for uma tese, possui os seguintes recursos:
- disponível desde 2014;
- suporta Java pronto para uso, Node.js, Python, Go e tempos de execução personalizados;
- pagamos por:
número de chamadas;
prazo de entrega.
AWS Lambda: por que é necessário:
Eliminação Você paga apenas pelo tempo em que o serviço está sendo executado.
Velocidade. O próprio Lambda sobe e trabalha muito rápido.
Funcional. O Lambda possui muitos recursos para integração com os serviços da AWS.
Performance. Colocar um lambda é bem difícil. Paralelamente, ele pode ser executado, dependendo da região, de no máximo 1000 a 3000 cópias. E, se desejado, esse limite pode ser aumentado escrevendo-se no suporte.
Temos o corpo de um lambda, um editor on-line, o VPC como uma grade de computação virtual, o log, o próprio código, variáveis de ambiente e gatilhos que causam um lambda (a propósito, o versionamento funciona muito bem). Excelente anatomia Lambda é descrita neste artigo .
O código é armazenado no corpo (se esses idiomas forem suportados imediatamente) ou em camadas. Temos um gatilho que chama o lambda, o lambda lê os ambientes temporários, puxa-os para si e executa nosso código:

Se tivermos um tempo de execução personalizado, teremos que colocar o código em uma camada. Se você trabalhou com o Docker, a camada do Docker é muito semelhante à camada no lambda - um tipo de quase-repositório no qual nossa ligação necessária está localizada. Lá temos o arquivo executável do ambiente (se estivermos falando sobre PHP, você deve colocar o binário PHP compilado com antecedência), o arquivo de inicialização lambda (localizado por padrão) e os scripts chamados diretamente que serão executados.

Com a entrega, tudo não é tão otimista:

Ou seja, somos oferecidos para pegar arquivos com o código, enviá-lo para o arquivo zip, enviá-lo para a camada e executar nosso código. É absolutamente legal que isso seja oferecido na documentação oficial da Amazon.

É claro que isso não corresponde às realidades modernas e ao cheiro de dois milésimos no ar. Felizmente, pessoas gentis tentaram e criaram várias estruturas, portanto, usaremos a estrutura sem servidor desenvolvida no Node.js e nos permitirá gerenciar aplicativos com base no AWS Lambda. Além disso, quando falamos sobre implantação e desenvolvimento, é claro, não quero implantar manualmente, mas há um desejo de fazer algo flexível e automatizado.
Então, precisamos:
- AWS CLI - interface de linha de comando para trabalhar com serviços da AWS;
- a estrutura sem servidor já mencionada acima (a versão de desenvolvimento é gratuita e sua funcionalidade é suficiente para os olhos);
- A biblioteca Bref, necessária para escrever código. Como a biblioteca é instalada usando o compositor, o código será compatível com qualquer estrutura. Uma ótima solução, especialmente considerando que o AWS Lambda não oferece suporte à chamada de scripts PHP imediatamente.

Personalize seu ambiente e a AWS
CLI da AWS
Vamos começar criando uma conta e instalando a AWS CLI. O shell do console da AWS é baseado no Python 2.7+ ou 3.4+. Como a AWS recomenda a versão 3 do Python, não discutiremos.
Os exemplos abaixo são para o Ubuntu.
sudo apt-get -y install python3-pip
Em seguida, instale diretamente o AWS CLI:
pip3 install awscli --upgrade --user
Verifique a instalação:
aws --version
Agora você precisa conectar o AWS CLI à sua conta. Você pode usar seu nome de usuário e senha existentes, mas seria melhor criar um usuário separado por meio do AWS IAM, definindo-o apenas os direitos de acesso necessários. Chamar a configuração não causará problemas:
aws configure
Em seguida, você precisará do AWS Secret e do AWS Access Key. Eles podem ser obtidos no ASW IAM na guia "Credenciais de segurança" (localizada na página do usuário desejado). O botão "Criar chave de acesso" ajudará a gerar chaves de acesso. Mantenha-os com você.

Para registrar um novo bot no Telegram, use @BotFather e o comando / newbot. Como resultado, o token necessário para conectar-se ao seu bot será devolvido a você. Trave-o também.
Estrutura sem servidor
Para instalar o Serverless Framework, você precisará de uma conta em https://serverless.com/ .
Após concluir o registro, procederemos à instalação em nossa estação de trabalho. O Node.js 6 e acima será necessário.
sudo apt-get -y install nodejs
Para garantir o lançamento correto em nosso ambiente, seguimos as etapas recomendadas:
mkdir ~/.npm-global export PATH=~/.npm-global/bin:$PATH source ~/.profile npm config set prefix '~/.npm-global'
Adicione também:
~/.npm-global/bin:$PATH
para o arquivo / etc / environment.
Agora coloque Serverless:
npm install -g serverless
Aws
Bem, é hora de mudar para a interface da AWS e adicionar um nome de domínio. Criamos uma zona do AWS Route 53, um registro DNS e um certificado SSL para ele.
Além disso, você precisa do ELB, que criamos no serviço EC2 -> Load Balancers. A propósito, ao criar um ELB, você precisa seguir todas as etapas do assistente, indicando o certificado criado.
Quanto ao balanceador, você pode criá-lo por meio da CLI da AWS usando o seguinte comando:
aws elb create-load-balancer --load-balancer-name my-load-balancer --listeners "Protocol=HTTP,LoadBalancerPort=80,InstanceProtocol=HTTP,InstancePort=80" "Protocol=HTTPS,LoadBalancerPort=443,InstanceProtocol=HTTP,InstancePort=80,SSLCertificateId=arn:aws:iam::123456789012:server-certificate/my-server-cert" --subnets subnet-15aaab61 --security-groups sg-a61988c3
Um balanceador será necessário após a primeira implantação. Nesse caso, você precisa enviar solicitações para o nosso domínio. Para implementar isso, nas configurações do registro DNS (campo "Alias target"), comece a inserir o nome do ELB criado. Como resultado, você verá uma lista suspensa; portanto, resta selecionar a entrada desejada e salvá-la.

Agora vá para o código.
Escrevendo um código
Usaremos Bref para escrever o código. Como mencionado anteriormente, esta biblioteca é instalada usando o compositor, portanto, o código será compatível com qualquer estrutura. A propósito, os desenvolvedores já descreveram o processo de usar o Bref com o Laravel e o Symfony . Mas é aconselhável que trabalhemos no PHP "vazio" - isso ajudará a entender melhor a essência.
Começamos com as dependências:
{ "require": { "php": ">=7.2", "bref/bref": "^0.5.9", "telegram-bot/api": "*" }, "autoload": { "psr-4": { "App\": "src/" } } }
Escreveremos no PHP 7.2 e superior e, para trabalhar com o Telegram, esse shell para a API é adequado para nós - https://github.com/TelegramBot/Api . Quanto ao próprio código, ele será colocado no diretório src.
Portanto, o ambiente sem servidor está passando por uma caixa de diálogo do console. É necessário um aplicativo HTTP e, do ponto de vista do Lambda, isso significa que as chamadas de script serão executadas da mesma maneira que o Nginx. A interpretação será realizada pelo PHP-FPM. Em geral, isso é mais como uma chamada de script do console padrão. Este é um ponto importante, porque sem levar esse recurso em consideração, não poderemos chamar scripts via HTTP.
Realizamos:
vendor/bin/bref init
Na caixa de diálogo, selecione o item "Aplicativo HTTP" e não se esqueça de especificar a região, pois o aplicativo deve funcionar na mesma região em que o balanceador funciona.
Após a inicialização, 2 novos arquivos aparecerão:
index.php - o arquivo chamado;
serverless.yml - arquivo de configuração de implantação.
A pasta .serverless precisará ser imediatamente adicionada ao .gitignore (ela aparecerá após a primeira tentativa de implantação).
Quando tivermos um aplicativo da Web, colocaremos o index.php na pasta pública, imediatamente mudando para o serverless.yml. Aqui está o que pode parecer em nossa implementação:
# lambda- service: app # provider: name: aws # ! region: eu-central-1 # runtime: provided # , bref 1024. memoryLimit: 256 # stage: dev # environment: BOT_TOKEN: ${ssm:/app/bot-token} # bref plugins: - ./vendor/bref/bref # Lambda- functions: # php-api-dev # service-function-stage api: handler: public/index.php description: '' # in seconds (API Gateway has a timeout of 29 seconds) timeout: 28 layers: - ${bref:layer.php-73-fpm} # API Gateway events: - http: 'ANY /' - http: 'ANY /{proxy+}' # environment: MY_VARIABLE: ${ssm:/app/my_variable}
Agora vamos analisar as linhas não óbvias. Precisamos principalmente de variáveis de ambiente. Não queremos codificar conexões de banco de dados, APIs externas, etc. Se nos conectarmos ao Telegram, teremos nosso próprio token, recebido do BotFather. E não é recomendável armazenar esse token no serverless.yml, portanto, é melhor enviá-lo para o armazenamento AWS ssm:
aws ssm put-parameter --region eu-central-1 --name '/app/my_variable' --type String --value '___BOTFATHER'
A propósito, estamos nos referindo a ele na configuração.
Essas variáveis estão disponíveis como variáveis de ambiente e você pode acessá-las no PHP usando a função getenv. Se falarmos sobre o nosso exemplo, vamos manter o token do bot no escopo global para simplificar. Também podemos transferir o token para o escopo de uma única função e a chamada em si não será alterada a partir disso.
Vamos seguir em frente. Vamos agora criar uma classe simples do BotApp - ele será responsável por gerar uma resposta para o bot e responderá aos comandos. Os desenvolvedores de telegrama recomendam adicionar suporte aos comandos / help e / start para todos os bots. Vamos adicionar outro comando por diversão. A classe em si é bastante simples e possibilita implementar o controlador Front no index.php sem carregar o arquivo de chamada. Para obter uma lógica mais complexa, a arquitetura deve ser desenvolvida e complicada.
<?php namespace App; use TelegramBot\Api\Client; use Telegram\Bot\Objects\Update; class BotApp { function run(): void{ $token = getenv('BOT_TOKEN'); $bot = new Client($token); // start $bot->command('start', function ($message) use ($bot) { $answer = ' !'; $bot->sendMessage($message->getChat()->getId(), $answer); }); // $bot->command('help', function ($message) use ($bot) { $answer = ': /help - '; $bot->sendMessage($message->getChat()->getId(), $answer); }); // $bot->command('hello', function ($message) use ($bot) { $answer = '-, - , Serverless '; $bot->sendMessage($message->getChat()->getId(), $answer); }); $bot->run(); } }
E aqui está a lista de index.php:
<?php require_once('../vendor/autoload.php'); use App\BotApp; try{ $botApp = new BotApp(); $botApp->run(); } catch (Exception $e){ echo $e->getMessage(); print_r($e->getTrace(), 1); }
Pode parecer estranho, mas está tudo pronto para partirmos para a Produção. Vamos fazer isso executando o comando na pasta serverless.yml:
sls deploy
No modo normal, sem servidor, os arquivos serão compactados em arquivos zip, criarão um bucket S3 onde os colocar, criarão ou atualizarão o Aplicativo AWS anexado ao Lambda e colocarão o código e o tempo de execução em uma camada separada.
Durante o primeiro lançamento, a API do Gateway será criada (deixamos para facilitar o teste de chamadas, mas é recomendável excluí-la). Você também precisará configurar a chamada Lambda via ELB, para a qual selecionamos “Adicionar gatilho” na janela de controle de funções e selecione “Application Load Balancer” na lista suspensa. Você precisará especificar o ELB criado anteriormente, definir a conexão via HTTPS, deixar o host vazio e em Path especificar o caminho que o Lambda chamará (por exemplo, / lambda / mytgbot). Como resultado, seu Lambda estará disponível no URL com o caminho especificado.
Agora você pode registrar a parte da resposta do bot no Telegram para que o mensageiro entenda onde obter as mensagens. Para fazer isso, chame o seguinte URL no navegador, mas não esqueça de substituir seus próprios parâmetros nele:
https://api.telegram.org/bot_/setWebhook?url=https://my-elb-host.com/lambda/mytgbot
Como resultado, a API retornará "OK", após o que o bot ficará disponível.

Testando o bot em localidades
O bot pode ser testado antes da implantação. O fato é que o Serverless Framework suporta a inicialização em localidades usando contêineres do Docker para isso. Comando de chamada:
sls invoke local --docker -f myFunction
Não se esqueça de que usamos variáveis de ambiente; portanto, durante a chamada, elas também devem ser definidas no formato:
sls invoke local --docker -f myFunction --env VAR1=val1
Logs
Por padrão, a saída da chamada será registrada no CloudWatch - está disponível no painel Monitoramento da função Lambda correspondente. Aqui você pode ler os rastreamentos de chamadas no caso de um dump no lado do PHP. Além disso, você pode conectar serviços avançados de monitoramento, mas eles custarão alguns centavos adicionais a cada mês.
Total
Como resultado, obtivemos uma solução bastante rápida, flexível, escalável e também relativamente barata. Sim, o Lambda nem sempre vence em comparação com VMs e contêineres padrão, mas há situações em que o aplicativo sem servidor ajuda a "fotografar" de maneira rápida e eficiente. E o exemplo do bot criado apenas demonstra isso.
Materiais úteis sobre o tema: