
Há alguns anos, o Kubernetes
já foi
discutido no blog oficial do GitHub. Desde então, tornou-se a tecnologia padrão para implantar serviços. O Kubernetes agora administra uma parcela significativa dos serviços internos e públicos. À medida que nossos clusters aumentavam e os requisitos de desempenho se tornavam mais rigorosos, começamos a perceber que alguns serviços no Kubernetes exibiam esporadicamente atrasos que não podem ser explicados pela carga do próprio aplicativo.
De fato, em aplicativos, ocorre um atraso aleatório na rede de até 100 ms ou mais, o que leva a tempos limites ou novas tentativas. Esperava-se que os serviços pudessem responder a solicitações muito mais rápido que 100 ms. Mas isso não é possível se a conexão em si demorar tanto tempo. Separadamente, observamos consultas MySQL muito rápidas, que deveriam levar milissegundos, e o MySQL realmente gerenciava em milissegundos, mas do ponto de vista do aplicativo solicitante, a resposta levou 100 ms ou mais.
Imediatamente ficou claro que o problema ocorre apenas quando se conecta ao host Kubernetes, mesmo se a chamada vier de fora do Kubernetes. A maneira mais fácil de reproduzir o problema é no teste
Vegeta , que é executado em qualquer host interno, testa o serviço Kubernetes em uma porta específica e registra esporadicamente um grande atraso. Neste artigo, veremos como conseguimos rastrear a causa desse problema.
Elimine a complexidade desnecessária na cadeia de falhas
Tendo reproduzido o mesmo exemplo, queríamos restringir o foco do problema e remover as camadas extras de complexidade. Inicialmente, havia muitos elementos no fluxo entre o Vegeta e os pods no Kubernetes. Para identificar um problema de rede mais profundo, você precisa excluir alguns deles.
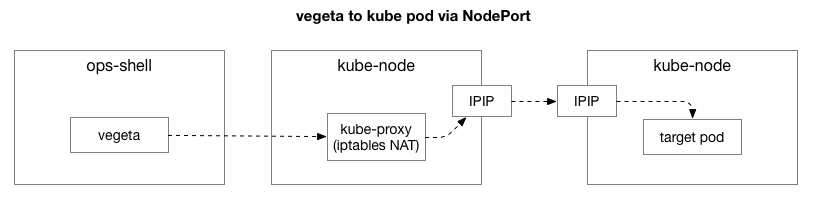
O cliente (Vegeta) cria uma conexão TCP com qualquer nó no cluster. O Kubernetes atua como uma rede de sobreposição (na parte superior da rede de data center existente) que usa
IPIP , ou seja, encapsula os pacotes IP da rede de sobreposição dentro dos pacotes IP do data center. Quando conectada ao primeiro nó, a conversão de endereço de rede NAT (
Network Address Translation ) é realizada com monitoramento de estado para converter o endereço IP e a porta do host Kubernetes no endereço IP e porta na rede de sobreposição (em particular, o pod com o aplicativo). Para pacotes recebidos, a sequência reversa é realizada. Este é um sistema complexo com muitos estados e muitos elementos que são constantemente atualizados e alterados à medida que os serviços são implantados e movidos.
O utilitário
tcpdump no teste Vegeta fornece um atraso durante o handshake TCP (entre SYN e SYN-ACK). Para remover essa complexidade desnecessária, você pode usar o
hping3 para "pings" simples com pacotes SYN. Verifique se há um atraso no pacote de resposta e, em seguida, redefina a conexão. Podemos filtrar os dados incluindo apenas pacotes com mais de 100 ms e obter uma opção mais simples para reproduzir o problema do que o teste de nível de rede 7 completo em Vegeta. Aqui estão os "pings" do host Kubernetes usando o TCP SYN / SYN-ACK na "porta" do host do serviço (30927) com um intervalo de 10 ms, filtrados pelas respostas mais lentas:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1485 win=29200 rtt=127.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1486 win=29200 rtt=117.0 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1487 win=29200 rtt=106.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=1488 win=29200 rtt=104.1 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5024 win=29200 rtt=109.2 ms
len=46 ip=172.16.47.27 ttl=59 DF id=0 sport=30927 flags=SA seq=5231 win=29200 rtt=109.2 msImediatamente pode fazer a primeira observação. Os números de série e horários mostram que esses não são congestionamentos únicos. O atraso geralmente se acumula e é finalmente processado.
Em seguida, queremos descobrir quais componentes podem estar envolvidos na aparência de congestionamento. Talvez estas sejam algumas das centenas de regras do iptables no NAT? Ou alguns problemas com o tunelamento IPIP na rede? Uma maneira de verificar isso é verificar cada etapa do sistema excluindo-a. O que acontece se você remover a lógica do NAT e do firewall, deixando apenas uma parte do IPIP:
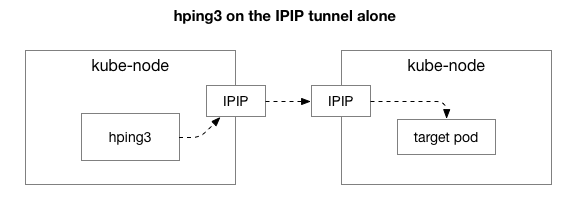
Felizmente, o Linux facilita o acesso direto à camada de sobreposição de IP se a máquina estiver na mesma rede:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7346 win=0 rtt=127.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7347 win=0 rtt=117.3 ms
len=40 ip=10.125.20.64 ttl=64 DF id=0 sport=0 flags=RA seq=7348 win=0 rtt=107.2 msA julgar pelos resultados, o problema ainda permanece! Isso exclui iptables e NAT. Então o problema está no TCP? Vamos ver como o ping ICMP normal é executado:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 ms
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 ms
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 ms
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 ms
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 ms
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 ms
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 msOs resultados mostram que o problema não desapareceu. Talvez este seja um túnel IPIP? Vamos simplificar o teste:
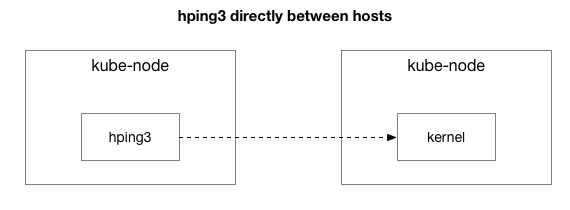
Todos os pacotes são enviados entre esses dois hosts?
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 ms
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 ms
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 ms
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 ms
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 msSimplificamos a situação para dois hosts Kubernetes enviando qualquer pacote um para o outro, mesmo ping ICMP. Eles ainda vêem um atraso se o host de destino for "ruim" (alguns piores que outros).
Agora a última pergunta: por que o atraso ocorre apenas em servidores de nós do kube? E isso acontece quando o kube-node é o remetente ou receptor? Felizmente, também é fácil descobrir isso enviando um pacote de um host fora do Kubernetes, mas com o mesmo destinatário "conhecido como ruim". Como você pode ver, o problema não desapareceu:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=312 win=0 rtt=108.5 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=5903 win=0 rtt=119.4 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=6227 win=0 rtt=139.9 ms
len=46 ip=172.16.47.27 ttl=61 DF id=0 sport=9876 flags=RA seq=7929 win=0 rtt=131.2 msEm seguida, executamos as mesmas solicitações do nó kube de origem anterior para o host externo (que exclui o host original, pois o ping inclui os componentes RX e TX):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}\.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 msDepois de examinar as capturas de pacotes atrasadas, obtivemos algumas informações adicionais. Em particular, que o remetente (abaixo) veja esse tempo limite, mas o receptor (acima) não o veja - veja a coluna Delta (em segundos):

Além disso, se você observar a diferença na ordem dos pacotes TCP e ICMP (por números de série) no lado do destinatário, os pacotes ICMP sempre chegarão na mesma sequência em que foram enviados, mas com tempo diferente. Ao mesmo tempo, os pacotes TCP às vezes se alternam e alguns ficam presos. Em particular, se examinarmos as portas dos pacotes SYN, no lado do remetente elas vão em ordem, mas no lado do destinatário não.
Há uma diferença sutil em como
as placas de rede dos servidores modernos (como em nosso data center) processam pacotes contendo TCP ou ICMP. Quando um pacote chega, o adaptador de rede “faz o hash na conexão”, ou seja, tenta interromper as conexões alternadamente e envia cada fila para um núcleo de processador separado. Para o TCP, esse hash inclui o endereço IP e a porta de origem e de destino. Em outras palavras, cada conexão é hash (potencialmente) diferente. Para o ICMP, apenas os endereços IP são hash, pois não há portas.
Outra nova observação: durante esse período, vemos atrasos do ICMP em todas as comunicações entre os dois hosts, mas o TCP não. Isso nos diz que o motivo provavelmente se deve ao hash das filas RX: é quase certo que o congestionamento ocorre no processamento de pacotes RX, em vez de enviar respostas.
Isso exclui o envio de pacotes da lista de possíveis motivos. Agora sabemos que o problema com o processamento de pacotes está no lado de recebimento em alguns servidores do nó kube.
Entendendo o processamento de pacotes no kernel do Linux
Para entender por que o problema ocorre com o destinatário em alguns servidores de nós do kube, vamos ver como o kernel do Linux lida com pacotes.
Retornando à implementação tradicional mais simples, a placa de rede recebe o pacote e envia uma
interrupção ao kernel do Linux, que é o pacote que precisa ser processado. O kernel interrompe outra operação, alterna o contexto para o manipulador de interrupções, processa o pacote e retorna às tarefas atuais.

Essa troca de contexto é lenta: a latência pode não ter sido notada em placas de rede de 10 megabytes na década de 1990, mas em placas 10G modernas com uma taxa de transferência máxima de 15 milhões de pacotes por segundo, cada núcleo de um servidor pequeno de oito núcleos pode ser interrompido milhões de vezes por segundo.
Para não lidar constantemente com o tratamento de interrupções, há muitos anos o Linux adicionou o
NAPI : uma API de rede que todos os drivers modernos usam para aumentar o desempenho em alta velocidade. Em baixas velocidades, o kernel ainda aceita interrupções da placa de rede da maneira antiga. Assim que chega um número suficiente de pacotes que excede o limite, o kernel desativa as interrupções e começa a pesquisar o adaptador de rede e receber pacotes em lotes. O processamento é realizado em softirq, ou seja, no
contexto de interrupções de software após chamadas do sistema e hardware interrompe quando o kernel (diferente do espaço do usuário) já está em execução.
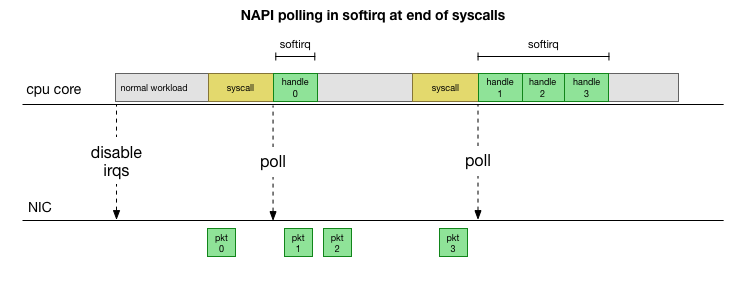
Isso é muito mais rápido, mas causa um problema diferente. Se houver muitos pacotes, o tempo necessário para processar pacotes da placa de rede e os processos de espaço do usuário não terão tempo para realmente esvaziar essas filas (leitura de conexões TCP, etc.). No final, as filas são preenchidas e começamos a soltar pacotes. Tentando encontrar um equilíbrio, o kernel define um orçamento para o número máximo de pacotes processados no contexto softirq. Quando esse orçamento é excedido, um encadeamento separado do
ksoftirqd (você verá um deles em
ps para cada núcleo), que processa esses softirqs fora do caminho normal do syscall / interrupt. Esse encadeamento é planejado usando um agendador de processos padrão que tenta distribuir recursos de maneira justa.
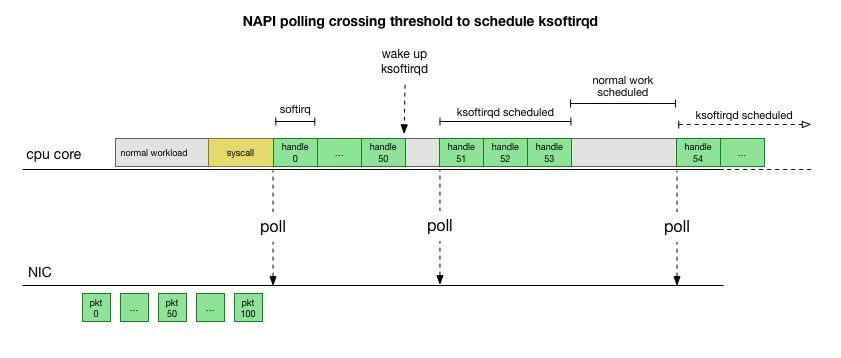
Após examinar como o kernel processa pacotes, você pode ver que há uma certa probabilidade de congestionamento. Se as chamadas softirq forem recebidas com menos frequência, os pacotes terão que esperar um pouco para serem processados na fila RX na placa de rede. Talvez isso ocorra devido a alguma tarefa que bloqueia o núcleo do processador, ou algo mais impede o kernel de iniciar o softirq.
Limitamos o processamento ao kernel ou método
Atrasos no Softirq são apenas uma suposição. Mas faz sentido, e sabemos que estamos vendo algo muito semelhante. Portanto, o próximo passo é confirmar essa teoria. E se for confirmado, encontre o motivo dos atrasos.
De volta aos nossos pacotes lentos:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 ms
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 ms
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 ms
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 ms
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 msComo discutido anteriormente, esses pacotes ICMP são divididos em hash em uma única fila NIC RX e processados por um único núcleo de CPU. Se quisermos entender como o Linux funciona, é útil saber onde (em qual núcleo da CPU) e como (softirq, ksoftirqd) esses pacotes são processados para acompanhar o processo.
Agora é hora de usar ferramentas que permitem o monitoramento em tempo real do kernel do Linux. Aqui usamos
cco . Este kit de ferramentas permite gravar pequenos programas em C que interceptam funções arbitrárias no kernel e armazenam eventos em um programa Python no espaço do usuário que pode processá-las e retornar o resultado. Ganchos para funções arbitrárias no kernel são complexos, mas o utilitário foi projetado para segurança máxima e foi projetado para rastrear com precisão esses problemas de produção que não são fáceis de reproduzir em um ambiente de teste ou desenvolvimento.
O plano aqui é simples: sabemos que o kernel processa esses pings do ICMP, então colocamos um gancho na
função do kernel
icmp_echo , que recebe o pacote ICMP de entrada "solicitação de eco" e inicia o envio da resposta do ICMP "resposta de eco". Podemos identificar o pacote aumentando o número icmp_seq, que mostra o
hping3 acima.
O código de
script cco parece complicado, mas não é tão assustador quanto parece. A função
icmp_echo passa
struct sk_buff *skb : este é o pacote com a solicitação "echo request". Podemos rastrear, extrair a sequência
echo.sequence (que mapeia para
icmp_seq de hping3
) e enviá-la para o espaço do usuário. Também é conveniente capturar o nome / identificador atual do processo. Abaixo estão os resultados que vemos diretamente durante o processamento de pacotes pelo kernel:
NOME DO PROCESSO DO TGID PID ICMP_SEQ
0 0 trocador / 11.770
0 0 trocador / 11.771
0 0 trocador / 1172
0 0 trocador / 1173
0 0 trocador / 11.774
20041 20086 prometheus 775
0 0 trocador / 11.776
0 0 trocador / 11.777
0 0 trocador / 11788
4512 4542 spokes-report-s 779
Deve-se notar aqui que, no contexto do
softirq processos que fizeram chamadas do sistema aparecem como "processos", embora, de fato, esse kernel processe pacotes com segurança no contexto do kernel.
Com esta ferramenta, podemos estabelecer a conexão de processos específicos com pacotes específicos que mostram um atraso no
hping3 . Nós fazemos um
grep simples nesta captura para valores
icmp_seq específicos. Pacotes correspondentes aos valores acima icmp_seq foram marcados com seu RTT, o que observamos acima (entre parênteses são os valores RTT esperados para pacotes que filtramos devido a valores RTT inferiores a 50 ms):
NOME DO PROCESSO DO TGID PID ICMP_SEQ ** RTT
-
10137 10436 cadvisor 1951
10137 10436 cadvisor 1952
76 76 ksoftirqd / 11 1953 ** 99ms
76 76 ksoftirqd / 11 1954 ** 89ms
76 76 ksoftirqd / 11 1955 ** 79ms
76 76 ksoftirqd / 11 1956 ** 69ms
76 76 ksoftirqd / 11 1957 ** 59ms
76 76 ksoftirqd / 11 1958 ** (49ms)
76 76 ksoftirqd / 11 1959 ** (39ms)
76 76 ksoftirqd / 11 1960 ** (29ms)
76 76 ksoftirqd / 11 1961 ** (19 ms)
76 76 ksoftirqd / 11 1962 ** (9ms)
-
10137 10436 cadvisor 2068
10137 10436 cadvisor 2069
76 76 ksoftirqd / 11 2070 ** 75ms
76 76 ksoftirqd / 11 2071 ** 65ms
76 76 ksoftirqd / 11 2072 ** 55ms
76 76 ksoftirqd / 11 2073 ** (45ms)
76 76 ksoftirqd / 11 2074 ** (35ms)
76 76 ksoftirqd / 11 2075 ** (25ms)
76 76 ksoftirqd / 11 2076 ** (15ms)
76 76 ksoftirqd / 11 2077 ** (5ms)
Os resultados nos dizem algumas coisas. Primeiro, o contexto do
ksoftirqd/11 lida com todos esses pacotes. Isso significa que, para esse par específico de máquinas, os pacotes ICMP foram divididos em hash no núcleo 11 na extremidade receptora. Também vemos que, a cada congestionamento de tráfego, há pacotes processados no contexto da chamada do sistema do
cadvisor . Então o
ksoftirqd assume a tarefa e preenche a fila acumulada: exatamente o número de pacotes acumulados após o
cadvisor .
O fato de um
cadvisor sempre trabalhar imediatamente antes disso implica seu envolvimento no problema. Ironicamente, o objetivo do
cadvisor é "analisar a utilização de recursos e as características de desempenho de contêineres em execução", em vez de causar esse problema de desempenho.
Como em outros aspectos do manuseio de contêiner, todas essas são ferramentas extremamente avançadas, das quais problemas de desempenho podem ser esperados em algumas circunstâncias imprevistas.
O que o cadvisor faz isso retarda a fila de pacotes?
Agora, temos um bom entendimento de como ocorre a falha, qual processo a causa e em qual CPU. Vemos que, devido ao bloqueio físico, o kernel do Linux não tem tempo para agendar o
ksoftirqd . E vemos que os pacotes são processados no contexto do
cadvisor . É lógico supor que o
cadvisor inicia uma
cadvisor lenta, após a qual todos os pacotes acumulados no momento são processados:
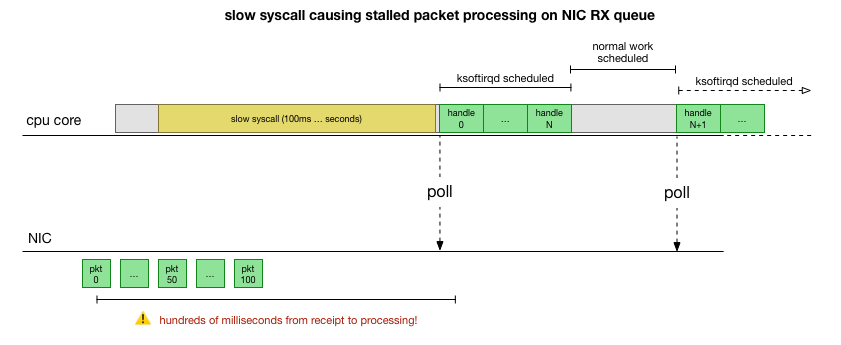
Esta é uma teoria, mas como testá-la? O que podemos fazer é rastrear a operação do núcleo da CPU ao longo deste processo, encontrar o ponto em que o orçamento é excedido pelo número de pacotes e o ksoftirqd é chamado e, em seguida, olhar um pouco mais cedo - o que exatamente funcionou no núcleo da CPU antes desse momento. É como um raio-x de uma CPU a cada poucos milissegundos. Será algo parecido com isto:
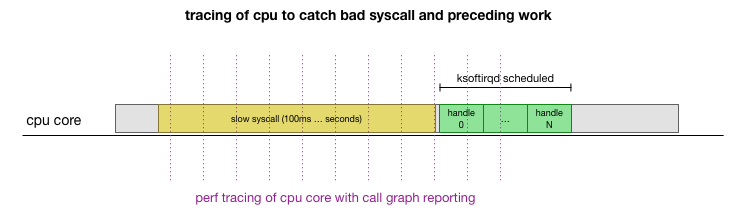
Convenientemente, tudo isso pode ser feito com as ferramentas existentes. Por exemplo, o
registro perf verifica o núcleo da CPU especificado com a frequência indicada e pode gerar um agendamento de chamadas para um sistema em execução, incluindo o espaço do usuário e o kernel do Linux. Você pode pegar esse registro e processá-lo usando uma pequena bifurcação do programa
FlameGraph de Brendan Gregg, que preserva a ordem de rastreamento da pilha. Podemos salvar rastreamentos de pilha de uma linha a cada 1 ms e, em seguida, selecionar e salvar a amostra por 100 milissegundos antes que o
ksoftirqd entre no rastreamento:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100Aqui estão os resultados:
( , )
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_runHá muitas coisas aqui, mas a principal é que encontramos o modelo "cadvisor before ksoftirqd" que vimos anteriormente no rastreador do ICMP. O que isso significa?
Cada linha é um rastreio da CPU em um determinado momento. Cada chamada na pilha em uma linha é separada por ponto e vírgula. No meio das linhas, vemos syscall chamado:
read(): .... ;do_syscall_64;sys_read; ... read(): .... ;do_syscall_64;sys_read; ... Portanto, o cadvisor passa muito tempo na chamada do sistema
read() , relacionada às funções
mem_cgroup_* (parte superior da pilha de chamadas / fim de linha).
No rastreamento de chamadas, é inconveniente ver exatamente o que está sendo lido, portanto, execute o
strace e veja o que o cadvisor faz e encontre chamadas do sistema com mais de 100 ms:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0\.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880\nrss 507904\nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880\nrss 507904\nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0\nrss 0\nrss_huge 0\nmapped_"..., 4096) = 576 <0.154442>Como você pode esperar, aqui vemos chamadas de
read() lenta
read() . A partir do conteúdo das operações de leitura e do contexto
mem_cgroup ,
mem_cgroup possível observar que essas chamadas
read() referem ao arquivo
memory.stat , que mostra as limitações de uso de memória e cgroup (tecnologia de isolamento de recursos do Docker). A ferramenta cadvisor consulta este arquivo para obter informações de uso de recursos para contêineres. Vamos verificar se esse core ou cadvisor faz algo inesperado:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
real 0m0.153s
user 0m0.000s
sys 0m0.152s
theojulienne@kube-node-bad ~ $Agora podemos reproduzir o bug e entender que o kernel do Linux está enfrentando patologia.
O que torna a leitura tão lenta?
Nesse momento, é muito mais fácil encontrar mensagens de outros usuários sobre problemas semelhantes. Como se viu, no rastreador do cadvisor esse bug foi relatado como um
problema de uso excessivo da CPU , mas ninguém percebeu que o atraso também era aleatoriamente refletido na pilha da rede. De fato, notou-se que o cadvisor consome mais tempo do processador do que o esperado, mas isso não recebeu muita importância, porque nossos servidores possuem muitos recursos de processador, portanto, não estudamos cuidadosamente o problema.
O problema é que os grupos de controle (cgroups) levam em consideração o uso de memória dentro do espaço para nome (contêiner). Quando todos os processos neste cgroup terminam, o Docker libera um grupo de controle de memória. No entanto, "memória" não é apenas uma memória de processo. Embora a própria memória do processo não seja mais usada, o kernel também atribui conteúdo em cache, como dentries e inodes (metadados de diretório e arquivo), armazenados em cache no cgroup de memória. A partir da descrição do problema:
cgroups zombies: grupos de controle nos quais não há processos e são excluídos, mas para os quais a memória ainda está alocada (no meu caso, a partir do cache do dentry, mas também pode ser alocada no cache da página ou tmpfs).
O kernel que verifica todas as páginas no cache quando o cgroup é liberado pode ser muito lento, portanto o processo lento é escolhido: espere até que essas páginas sejam solicitadas novamente e, mesmo quando a memória for realmente necessária, limpe o cgroup. Até agora, o cgroup ainda é levado em consideração ao coletar estatísticas.
Em termos de desempenho, eles sacrificaram a memória por desempenho: acelerando a limpeza inicial devido ao fato de que resta um pouco de memória em cache. Isso é normal. Quando o kernel usa a última parte da memória em cache, o cgroup é eventualmente limpo, então isso não pode ser chamado de "vazamento". Infelizmente, a implementação específica do mecanismo de pesquisa
memory.stat nesta versão do kernel (4.9), combinada com a enorme quantidade de memória em nossos servidores, leva ao fato de que leva muito mais tempo para restaurar os dados em cache mais recentes e limpar os zumbis do cgroup.
Acontece que havia tantos zumbis cgroup em alguns de nossos nós que a leitura e a latência excederam um segundo.
Uma solução alternativa para o problema do cadvisor é limpar imediatamente os caches de dentries / inodes em todo o sistema, o que elimina imediatamente a latência de leitura e a latência de rede no host, pois a exclusão do cache inclui páginas em cache do cgroup zombie e elas também são liberadas. Esta não é uma solução, mas confirma a causa do problema.
Verificou-se que as versões mais recentes do kernel (4.19+) melhoravam o desempenho da chamada
memory.stat , portanto, a mudança para esse kernel corrigiu o problema. Ao mesmo tempo, tínhamos ferramentas para detectar nós de problemas nos clusters do Kubernetes, drenando-os e reinicializando-os normalmente. Examinamos todos os clusters, encontramos os nós com um atraso suficientemente alto e os reinicializamos. Isso nos deu tempo para atualizar o sistema operacional nos demais servidores.
Resumir
Como esse bug interrompeu o processamento das filas da NIC RX por centenas de milissegundos, causou simultaneamente um grande atraso em conexões curtas e um atraso no meio da conexão, por exemplo, entre consultas do MySQL e pacotes de resposta.
, Kubernetes, . Kubernetes .