
A empresa em que trabalho cria seu próprio sistema de filtragem de tráfego e protege os negócios contra ataques DDoS, bots, analisadores e muito mais. O produto é baseado em um processo como
proxy reverso , com a ajuda da qual analisamos grandes volumes de tráfego em tempo real e, no final, deixamos passar apenas solicitações legítimas de usuários, filtrando todas as maliciosas.
A principal característica é que nossos serviços funcionam com tráfego de entrada ilimitado; portanto, é muito importante usar todos os recursos das estações de trabalho da maneira mais eficiente possível. Muita experiência em desenvolvimento em C ++ moderno nos ajuda com isso, incluindo os padrões mais recentes e um conjunto de bibliotecas chamado Boost.
Proxy reverso
Vamos voltar ao proxy reverso e ver como você pode implementá-lo em C ++ e boost.asio. Primeiro de tudo, precisamos de dois objetos chamados sessões de servidor e cliente. A sessão do servidor estabelece e mantém uma conexão com o navegador; a sessão do cliente estabelece e mantém uma conexão com o serviço. Você também precisará de um buffer de fluxo que encapsule o trabalho com memória interna, na qual a sessão do servidor lê a partir do soquete e a partir da qual a sessão do cliente grava no soquete. Exemplos de sessões de servidor e cliente podem ser encontrados na documentação para boost.asio. Como trabalhar com o buffer de fluxo pode ser encontrado lá.
Depois de coletarmos o protótipo do proxy reverso a partir dos exemplos, ficará claro que esse aplicativo provavelmente não servirá tráfego de entrada ilimitado. Então começaremos a aumentar a complexidade do código. Vamos pensar em multithreading, wokers e pools para contextos io, e muito mais. Em particular, sobre otimizações prematuras relacionadas à cópia de memória entre as sessões do servidor e do cliente.
De que tipo de cópia de memória estamos falando? O fato é que, ao filtrar, o tráfego nem sempre é transmitido inalterado. Veja o exemplo abaixo: nele removemos um cabeçalho e adicionamos dois. O número de consultas de usuários sobre as quais ações semelhantes são executadas aumenta com a complexidade da lógica dentro do serviço. Em nenhum caso você pode copiar dados sem pensar nesses casos! Se apenas 1% do total de solicitações for alterado e 99% permanecerem inalterados, você deverá alocar nova memória somente para esse 1%. Ele o ajudará com este boost :: asio :: const_buffer e boost :: asio :: mutable_buffer, com o qual você pode representar vários blocos contínuos de memória com uma entidade.
Pedido do usuário:
Browser -> Proxy: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Content-Length: 5888903 > Content-Type: application/x-www-form-urlencoded > ... Proxy -> Service: > POST / HTTP/1.1 > User-Agent: curl/7.29.0 > Host: 127.0.0.1:50080 > Accept: */* > Transfer-Encoding: chunked > Content-Type: application/x-www-form-urlencoded > Expect: 100-continue > ... Service -> Proxy: < HTTP/1.1 200 OK Proxy -> Browser < HTTP/1.1 200 OK
O problema
Como resultado, obtivemos um aplicativo pronto que pode ser dimensionado bem e é dotado de todos os tipos de otimizações. Ao lançá-lo em produção, ficamos muito felizes por quanto tempo funcionou bem e de forma estável.
Com o tempo, começamos a ter mais e mais clientes, com o advento do qual o tráfego também aumentou. Em algum momento, fomos confrontados com o problema da falta de desempenho, repelindo grandes ataques. Após analisar o serviço usando o utilitário
perf , percebemos que todas as operações com o heap sob carga estão no topo. Em seguida, recriamos uma situação semelhante no circuito de teste usando
tanque yandex e cartuchos gerados com base no tráfego real. Ligando um serviço através de um
amplificador, vimos a seguinte imagem ...
Captura de tela do amplificador (woslab):
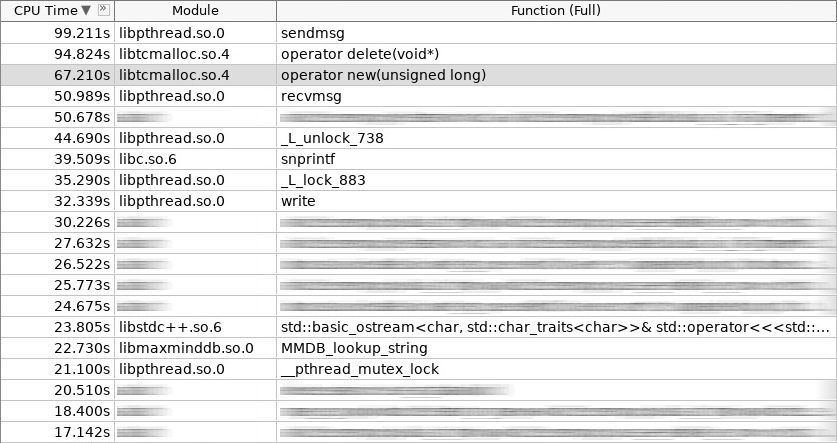
Na captura de tela, o novo operador trabalhou 67 segundos e o operador excluiu ainda mais - 97 segundos.
Essa situação nos chateou. Como reduzir o tempo de permanência do aplicativo no operador new e o delete do operador? É lógico que isso pode ser feito abandonando alocações constantes de objetos criados e excluídos com freqüência na pilha. Decidimos em três abordagens. Dois deles são padrão:
pool de objetos e
alocação de pilha . As sessões do cliente organizadas em um pool no estágio de inicialização do aplicativo são bem colocadas na primeira abordagem. A segunda abordagem é usada em qualquer lugar em que uma solicitação do usuário é processada do começo ao fim na mesma pilha, ou seja, no mesmo manipulador de contexto io. Não vamos nos aprofundar nisso com mais detalhes. É melhor falarmos sobre a terceira abordagem, como a mais complexa e interessante. É chamado de
alocação ou distribuição de placas.
A idéia de distribuição de placas não é nova. Foi inventado e implementado no Solaris, posteriormente migrado para o kernel Linux, e consiste no fato de que objetos do mesmo tipo frequentemente usados são mais fáceis de armazenar no pool. Apenas tiramos o objeto da piscina quando precisamos dele e, após a conclusão do trabalho, devolvemos o objeto. Nenhuma chamada para o operador novo e o operador é excluído! Além disso, um mínimo de inicialização. No núcleo da laje, a distribuição é usada para semáforos, descritores de arquivo, processos e encadeamentos. No nosso caso, ele se encaixava perfeitamente nas sessões de servidor e cliente, bem como em tudo o que há dentro delas.
Gráfico (distribuição da laje):

Além do fato de os alocadores de laje estarem no kernel, suas implementações também existem no espaço do usuário. Existem poucos deles, e aqueles que estão se desenvolvendo ativamente são geralmente poucos. Estabelecemos uma biblioteca chamada
libsmall , que faz parte do
tarantool . Tem tudo o que você precisa.
- small :: alocador
- small :: slab_cache (thread local)
- small :: slab
- small :: arena
- small :: quota
A estrutura small :: slab é um pool com um tipo específico de objeto. A estrutura small :: slab_cache é um cache que contém várias listas de conjuntos com um tipo específico de objetos. A estrutura small :: alocator é um código que seleciona o cache necessário, procura um pool adequado, no qual o objeto solicitado é distribuído. O que os objetos small :: arena e small :: quota fazem será claro nos exemplos abaixo.
Wrap
A biblioteca libsmall é escrita em C, não em C ++, então tivemos que desenvolver vários wrappers para integração transparente na biblioteca C ++ padrão.
- variti :: slab_allocator
- variti :: slab
- variti :: thread_local_slab
- variti :: slab_allocate_shared
A classe variti :: slab_allocator implementa os requisitos mínimos estabelecidos pelo padrão ao gravar seu próprio alocador. Dentro das classes variti :: slab, todo o trabalho com a biblioteca libsmall é encapsulado. Por que variti :: thread_local_slab é necessário? O fato é que os caches da laje de distribuição são objetos locais de encadeamento. Isso significa que cada encadeamento possui seu próprio conjunto de caches. Isso é feito para reduzir a zero o número de operações bloqueadas ao distribuir um novo objeto. Portanto, na memória de cada thread, colocamos nossa instância da classe variti :: slab e o acesso a ela é regulado usando o wrapper variti :: thread_local_slab. Vou falar sobre a função de modelo variti :: slab_allocate_shared mais tarde.
Dentro da classe variti :: slab_allocator, tudo é bastante simples. Ele tem a capacidade de religar de um tipo para outro, por exemplo, de void para char. Curiosamente, você pode prestar atenção à prevalência de nullptr à exceção std :: bad_alloc no caso em que a memória fica fora da laje de distribuição. O restante está encaminhando chamadas dentro do wrapper variti :: thread_local_slab.
Snippet (slab_allocator.hpp):
template <typename T> class slab_allocator { public: using value_type = T; using pointer = value_type*; using const_pointer = const value_type*; using reference = value_type&; using const_reference = const value_type&; template <typename U> struct rebind { using other = slab_allocator<U>; }; slab_allocator() {} template <typename U> slab_allocator(const slab_allocator<U>& other) {} T* allocate(size_t n, const void* = nullptr) { auto p = static_cast<T*>(thread_local_slab::allocate(sizeof(T) * n)); if (!p && n) throw std::bad_alloc(); return p; } void deallocate(T* p, size_t n) { thread_local_slab::deallocate(p, sizeof(T) * n); } }; template <> class slab_allocator<void> { public: using value_type = void; using pointer = void*; using const_pointer = const void*; template <typename U> struct rebind { typedef slab_allocator<U> other; }; };
Vamos ver como o construtor e destruidor variti :: slab é implementado. No construtor, alocamos um total de não mais que 1 GiB de memória para todos os objetos. O tamanho de cada piscina no nosso caso não excede 1 MiB. O objeto mínimo que podemos distribuir é de 2 bytes de tamanho (na verdade, libsmall aumentará para o mínimo necessário - 8 bytes). Os demais objetos disponíveis na distribuição de laje serão múltiplos de dois (definidos pela constante 2.f). No total, você pode distribuir objetos de tamanho 8, 16, 32 etc. Se o objeto solicitado tiver tamanho de 24 bytes, ocorrerá uma sobrecarga na memória. A distribuição retornará esse objeto para você, mas será colocado em um pool que corresponda a um objeto de 32 bytes de tamanho. Os 8 bytes restantes estarão ociosos.
Snippet (slab.hpp):
inline void* phys_to_virt_p(void* p) { return reinterpret_cast<char*>(p) + sizeof(std::thread::id); } inline size_t phys_to_virt_n(size_t n) { return n - sizeof(std::thread::id); } inline void* virt_to_phys_p(void* p) { return reinterpret_cast<char*>(p) - sizeof(std::thread::id); } inline size_t virt_to_phys_n(size_t n) { return n + sizeof(std::thread::id); } inline std::thread::id& phys_thread_id(void* p) { return *reinterpret_cast<std::thread::id*>(p); } class slab : public noncopyable { public: slab() { small::quota_init(& quota_, 1024 * 1024 * 1024); small::slab_arena_create(&arena_, & quota_, 0, 1024 * 1024, MAP_PRIVATE); small::slab_cache_create(&cache_, &arena_); small::allocator_create(&allocator_, &cache_, 2, 2.f); } ~slab() { small::allocator_destroy(&allocator_); small::slab_cache_destroy(&cache_); small::slab_arena_destroy(&arena_); } void* allocate(size_t n) { auto phys_n = virt_to_phys_n(n); auto phys_p = small::malloc(&allocator_, phys_n); if (!phys_p) return nullptr; phys_thread_id(phys_p) = std::this_thread::get_id(); return phys_to_virt_p(phys_p); } void deallocate(const void* p, size_t n) { auto phys_p = virt_to_phys_p(const_cast<void*>(p)); auto phys_n = virt_to_phys_n(n); assert(phys_thread_id(phys_p) == std::this_thread::get_id()); small::free(&allocator_, phys_p, phys_n); } private: small::quota quota_; small::slab_arena arena_; small::slab_cache cache_; small::allocator allocator_; };
Todas essas restrições se aplicam a uma instância específica da classe variti :: slab. Como cada encadeamento possui o seu (pense no encadeamento local), o limite total no processo não será de 1 GiB, mas será diretamente proporcional ao número de encadeamentos que usam distribuição de laje.
Gráfico (std :: thread :: id):
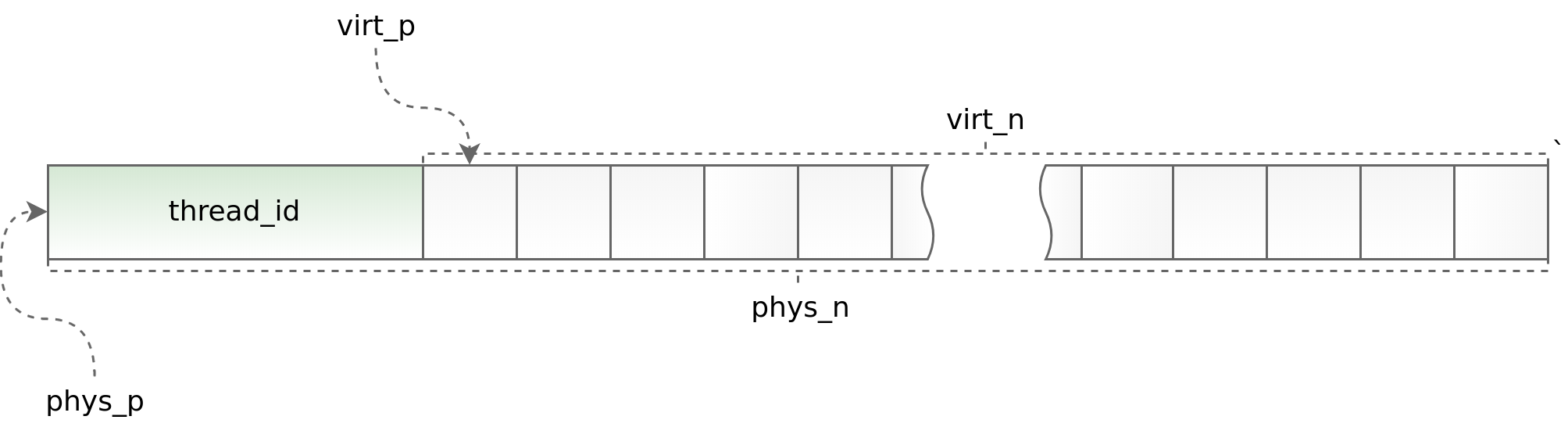
Por um lado, o uso do encadeamento local permite acelerar o trabalho de distribuição de laje em um aplicativo multithread, por outro lado, impõe sérias restrições à arquitetura do aplicativo assíncrono. Você deve solicitar e retornar um objeto no mesmo fluxo. Fazer isso como parte do boost.asio às vezes é muito problemático. Para rastrear situações obviamente errôneas, no início de cada objeto, colocamos o identificador do fluxo no qual o método de alocação é chamado. Esse identificador é verificado no método de desalocação. Os ajudantes phys_to_virt_p e virt_to_phys_p ajudam nisso.
Snippet (thread_local_slab.hpp):
class thread_local_slab : public noncopyable { public: static void initialize(); static void finalize(); static void* allocate(size_t n); static void deallocate(const void* p, size_t n); };
Snippet (thread_local_slab.cpp):
static thread_local slab* slab_; void thread_local_slab::initialize() { slab_ = new slab(slab_cfg_); } void thread_local_slab::finalize() { delete slab_; } void* thread_local_slab::malloc(size_t n) { return slab_->malloc(n); } void thread_local_slab::free(const void* p, size_t n) { slab_->free(p, n); }
Quando o controle sobre o fluxo é perdido (ao transferir um objeto entre diferentes contextos io), um ponteiro inteligente permite a liberação correta do objeto. Tudo o que ele faz é distribuir o objeto, lembrando-se de seu contexto io, e depois envolvê-lo em std :: shared_ptr com um divisor personalizado, que não retorna imediatamente o objeto à distribuição, mas o faz no contexto io salvo anteriormente. Isso funciona bem quando cada contexto io é executado em um único encadeamento. Caso contrário, infelizmente, essa abordagem não é aplicável.
Snippet (slab_helper.hpp):
template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator](T* p) { p->~T(); allocator.deallocate(p); }); return ptr; }; template <typename T, typename Allocator, typename... Args> std::shared_ptr<T> slab_allocate_shared(Allocator allocator, boost::asio::io_service* io, Args... args) { T* p = allocator.allocate(1); new ((void*)p) T(std::forward<Args>(args)...); std::shared_ptr<T> ptr(p, [allocator, io](T* p) { io->post([allocator, p]() { p->~T(); allocator.deallocate(p); }); }); return ptr; };
Solução
Depois que o trabalho de empacotamento da libsmall foi concluído, movemos primeiro os alocadores de chun dentro do buffer de fluxo para a laje. Isso foi bem fácil de fazer. Tendo recebido um resultado positivo, seguimos em frente e aplicamos alocadores de laje primeiro no próprio buffer de fluxo e depois em todos os objetos nas sessões do servidor e do cliente.
- variti :: chunk
- variti :: streambuf
- variti :: server_session
- variti :: client_session
Ao mesmo tempo, era necessário resolver problemas adicionais, a saber: transferir objetos simples, objetos compostos e coleções para alocadores de laje. E se não houve dificuldades sérias nas duas primeiras classes de objetos (objetos compostos são reduzidos a simples), então, ao traduzir coleções, encontramos sérias dificuldades.
- std :: list
- std :: deque
- std :: vector
- std :: string
- std :: map
- std :: unordered_map
Uma das principais limitações ao trabalhar com distribuição de laje é que o número de objetos de tipos diferentes não deve ser muito grande (quanto menor, melhor). Nesse contexto, algumas coleções podem se encaixar no conceito de alocadores de laje, enquanto outras podem não.
Para a laje std :: list, os alocadores funcionam muito bem. Essa coleção é implementada internamente usando uma lista vinculada, cada elemento com um tamanho fixo. Assim, com a adição de novos dados à lista std :: na distribuição da laje, novos tipos de objetos não aparecem. A condição indicada acima está satisfeita! O std :: map é organizado de maneira semelhante. A única diferença é que, dentro dela, não há uma lista vinculada, mas uma árvore.
No caso de std :: deque, as coisas são mais complicadas. Essa coleção é implementada por meio de um bloco de memória contíguo que contém ponteiros para blocos. Embora os blocos sejam bastante precisos, o std :: deque se comporta da mesma forma que o std :: list, mas quando eles terminam, esse mesmo bloco de memória é redistribuído. Do ponto de vista dos alocadores de laje, cada redistribuição de memória é um objeto com um novo tipo. O número de objetos adicionados à coleção depende diretamente do usuário e pode crescer incontrolavelmente. Como essa situação não é aceitável, limitamos preliminarmente o tamanho do std :: deque onde era possível ou preferimos o std :: list.
Se pegarmos std :: vector e std :: string, eles ainda serão mais complicados. A implementação dessas coleções é um pouco semelhante ao std :: deque, exceto que seu bloco de memória contínuo cresce significativamente mais rápido. Substituímos std :: vector e std :: string por std :: deque e, na pior das hipóteses, por std :: list. Sim, perdemos em funcionalidade e em algum lugar até em desempenho, mas isso afetou muito menos a imagem final do que as otimizações para as quais tudo foi concebido.
Fizemos exatamente a mesma coisa com std :: unordered_map, abandonando-o em favor da variti :: flat_map auto-escrita implementada por meio de std :: deque. Ao mesmo tempo, simplesmente armazenamos em cache as chaves usadas com freqüência em variáveis separadas, por exemplo, como é feito com os cabeçalhos de solicitação http no nginx.
Conclusão
Depois de concluir a transferência completa de sessões de servidor e cliente para alocadores de slab, reduzimos o tempo gasto trabalhando com vários grupos em mais de uma vez e meia.
Captura de tela do amplificador (coldslab):
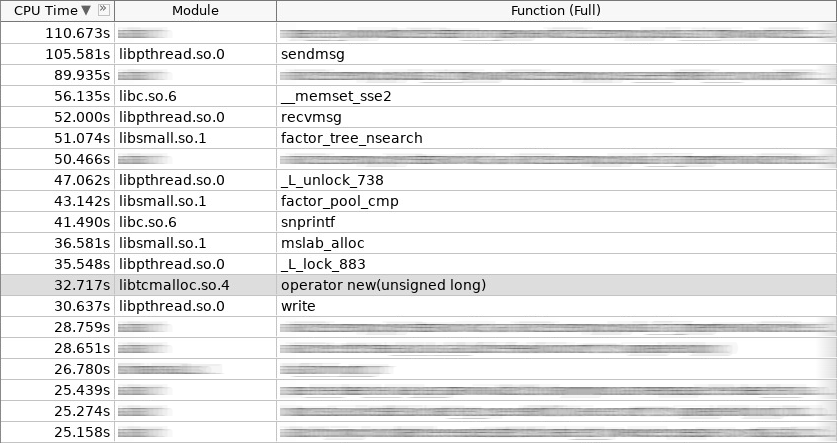
Na captura de tela, o novo operador trabalhou 32 segundos e o operador excluiu - 24 segundos. Nesse momento, outras funções para trabalhar com o heap foram adicionadas: smalloc - 21 segundos, mslab_alloc - 37 segundos, smfree - 8 segundos, mslab_free - 21 segundos. Total, 143 segundos versus 161 segundos.
Porém, essas medidas foram feitas imediatamente após o início do serviço sem inicializar os caches na distribuição da laje. Após disparos repetidos de um tanque Yandex, a imagem geral melhorou.
Captura de tela do amplificador (hotslab):
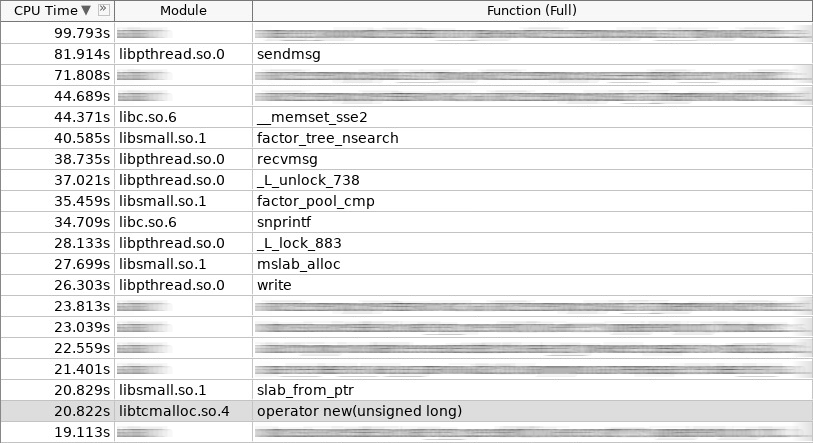
Na captura de tela, o novo operador trabalhou 20 segundos, smalloc - 16 segundos, mslab_alloc - 27 segundos, operador delete - 16 segundos, smfree - 7 segundos, mslab_free - 17 segundos. Total de 103 segundos contra 161 segundos.
Tabela de medição:
woslab coldslab hotslab operator new 67s 32s 20s smalloc - 21s 16s mslab_alloc - 37s 27s operator delete 94s 24s 16s smfree - 8s 7s mslab_free - 21s 17s summary 161s 143s 103s
Na vida real, o resultado deve ser ainda melhor, pois os alocadores de placas resolvem não apenas o problema de alocação e liberação de memória longa, mas também reduzem a fragmentação. Sem laje, com o tempo, a operação do operador novo e a exclusão do operador devem diminuir apenas. Com laje - sempre permanecerá no mesmo nível.
Como podemos ver, os alocadores de placas resolvem com êxito o problema de alocação de memória dos objetos usados com freqüência. Preste atenção a eles se o problema da criação e remoção freqüentes de objetos for relevante para você. Mas não se esqueça das limitações que elas impõem à arquitetura do seu aplicativo! Nem todos os objetos complexos podem ser simplesmente colocados na distribuição da laje. Às vezes você tem que desistir muito! Bem, quanto mais complexa a arquitetura do seu aplicativo, mais frequentemente você precisará devolver o objeto ao cache correto em termos de multithreading. Pode ser simples quando você elaborou imediatamente a arquitetura do aplicativo, levando em consideração o uso de alocadores de laje, mas definitivamente causará dificuldades quando você decidir integrá-los posteriormente.
App
Confira o código fonte
aqui !