Muitas vezes, ao desenvolver aplicativos móveis (talvez o mesmo problema com aplicativos da web), os desenvolvedores se vêem em uma situação em que o back-end não funciona ou não fornece os métodos necessários.
Esta situação pode ocorrer por vários motivos. No entanto, na maioria das vezes no início do desenvolvimento, o back-end simplesmente não é gravado e o cliente inicia sem ele. Nesse caso, o início do desenvolvimento está atrasado em 2-4 meses
Às vezes, o servidor é encerrado (falha), às vezes não há tempo para implementar os métodos necessários, às vezes há problemas de dados etc. Todos esses problemas nos levaram a escrever um pequeno serviço Mocker que permite substituir o back-end real.

Como cheguei a issoComo cheguei a isso? Meu primeiro ano na empresa estava terminando e eles me colocaram em um novo projeto de comércio eletrônico. O gerente disse que o projeto precisa ser concluído em 4 meses, mas a equipe de back-end (do lado do cliente) começará o desenvolvimento somente após 1,5 meses. E durante esse tempo, já temos que lançar muitos recursos de interface do usuário.
Sugeri escrever um backend moch (antes de me tornar um desenvolvedor iOS, eu brincava com o .NET na uni). A ideia de implementação era simples: de acordo com uma especificação especificada, era necessário escrever métodos stub que usassem dados de arquivos JSON pré-preparados. Eles decidiram isso.
Após duas semanas, saí de férias e pensei: "Por que não gero tudo isso automaticamente?" Assim, durante duas semanas de férias, escrevi uma aparência de um intérprete que pega a especificação APIBlueprint e gera o .NET Web App a partir dele (código C #).
Como resultado, a primeira versão dessa coisa apareceu e nós a vivemos por quase 2,5 meses. Não posso dar números reais, o quanto isso nos ajudou, mas lembro como eles disseram retrospectivamente que, se não fosse esse sistema, não haveria liberação.
Agora, depois de vários anos, considerei os erros cometidos por mim (e havia muitos deles) e reescrevi completamente o instrumento.
Aproveitando esta oportunidade - muito obrigado aos colegas que ajudaram com feedback e conselhos. E também aos líderes que suportaram toda a minha "arbitrariedade de engenharia".
1. Introdução
Como regra, qualquer aplicativo cliente-servidor se parece com isso:
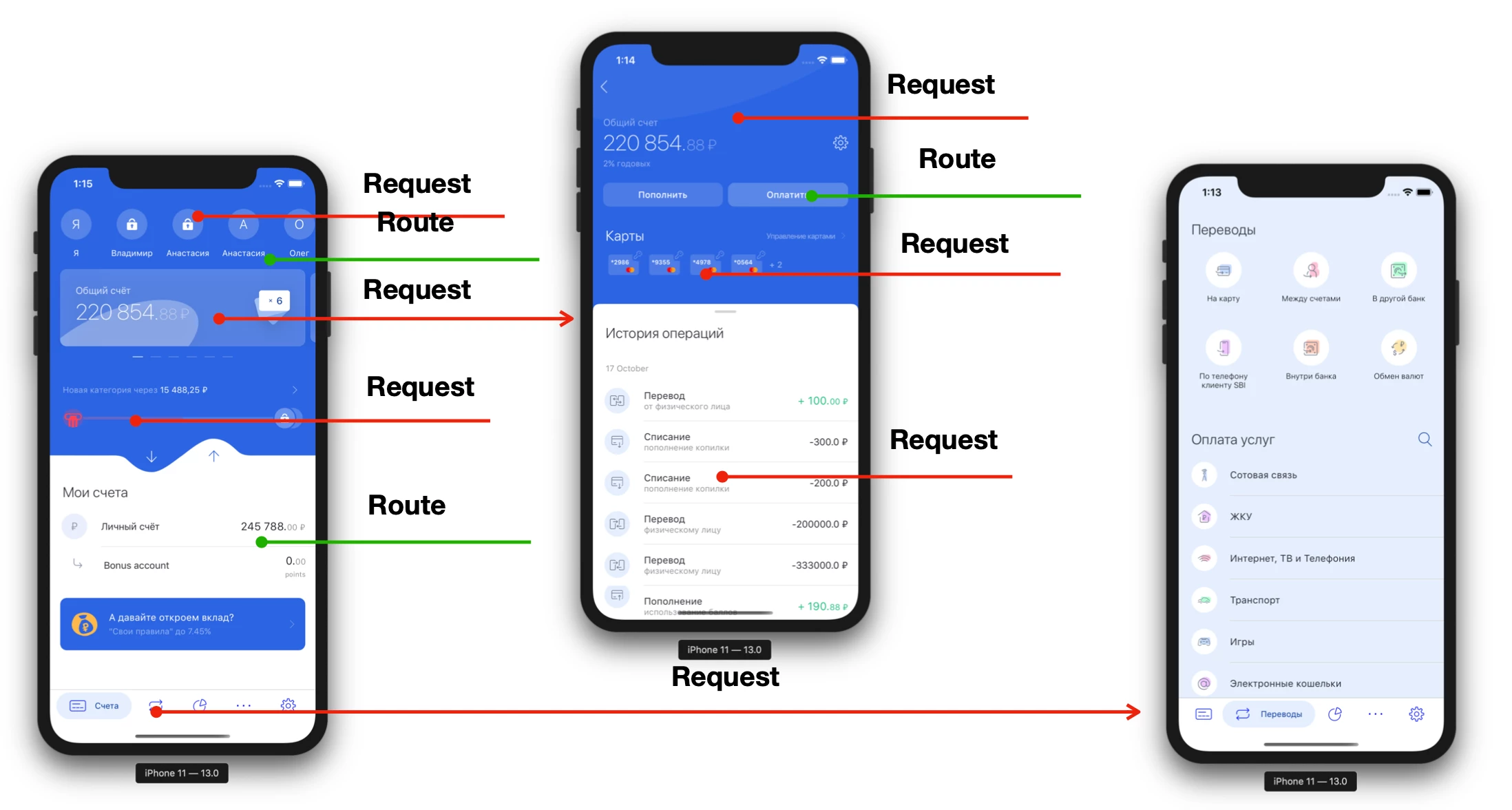
Cada tela possui pelo menos 1 consulta (e muitas vezes mais). Indo mais fundo nas telas, precisamos fazer mais e mais solicitações. Às vezes, não podemos fazer a transição até que o servidor nos diga "Mostrar o botão". Ou seja, o aplicativo móvel está muito ligado ao servidor, não apenas durante o trabalho imediato, mas também no estágio de desenvolvimento. Considere o ciclo de desenvolvimento do produto abstrato:

- Primeiro nós projetamos. Nós decompomos, descrevemos e discutimos.
- Tendo recebido as tarefas e os requisitos, começamos o desenvolvimento. Escrevemos o código, o texto digitado, etc.
- Depois de implementarmos algo, está sendo preparada uma montagem, que entra em teste manual, onde o aplicativo é verificado para diferentes casos.
- Se tudo estiver bem conosco, e os testadores testarem a montagem, ela será encaminhada ao cliente que realiza a aceitação.
Cada um desses processos é muito importante. Especialmente o último, como o cliente deve entender em que estágio realmente somos e, às vezes, ele precisa relatar os resultados à gerência ou aos investidores. Como regra, esses relatórios ocorrem, inclusive no formato de demonstração de um aplicativo móvel. Na minha prática, houve um caso em que um cliente demonstrou apenas metade do MVP, que funcionava apenas em mokas. O aplicativo mok se parece com o presente e grasna como o presente. Então é real (:
No entanto, este é um sonho rosa. Vejamos o que realmente acontece se não tivermos um servidor.

- O processo de desenvolvimento será mais lento e mais doloroso, já que não podemos escrever serviços normalmente, também não podemos verificar todos os casos, temos que escrever stubs que precisarão ser removidos posteriormente.
- Depois que fizemos a montagem ao meio com pesar, chega aos testadores que olham para ela e não entendem o que fazer com ela. Você não pode verificar nada, metade não funciona, porque não há servidor. Como resultado, eles perdem muitos bugs: lógicos e visuais.
- Bem, depois de "como eles poderiam ter parecido", você precisa entregar a montagem ao cliente e, em seguida, começa o mais desagradável. O cliente não pode realmente avaliar o trabalho, ele vê de um a dois casos possíveis e certamente não pode mostrá-lo a seus investidores.
Em geral, tudo está indo ladeira abaixo. E, infelizmente, essas situações acontecem quase sempre: às vezes não há servidor por alguns meses, às vezes meio ano, às vezes apenas no processo em que o servidor está muito atrasado ou é necessário verificar rapidamente os casos de limite que podem ser reproduzidos usando manipulações de dados em um servidor real.
Por exemplo, queremos verificar como o aplicativo se comporta se o pagamento do usuário for maior que a data de vencimento. É muito difícil (e longo) reproduzir essa situação no servidor e precisamos fazer isso artificialmente.
Portanto, existem os seguintes problemas:
- O servidor está completamente ausente. Por isso, é impossível projetar, testar e apresentar.
- O servidor não tem tempo, o que interfere no desenvolvimento e pode interferir nos testes.
- Queremos testar casos de fronteira, e o servidor não pode permitir isso sem gestos longos.
- Afetar testes e apresentações ameaçadoras.
- O servidor trava (uma vez, durante o desenvolvimento estável, perdemos o servidor por 3,5 dias).
Para combater esses problemas, o Mocker foi criado.
Princípio de funcionamento
O Mocker é um pequeno serviço da Web hospedado em algum lugar, escuta o tráfego em uma porta específica e pode responder com dados pré-preparados a solicitações de rede específicas.
A sequência é a seguinte:
1. O cliente envia uma solicitação.
2. Mocker recebe a solicitação.
3. Mocker encontra a simulação desejada.
4. Mocker retorna a simulação desejada.
Se tudo estiver claro nos pontos 1, 2 e 4, então 3 levanta questões.
Para entender como o serviço encontra a simulação necessária para o cliente, primeiro consideramos a estrutura da simulação.
Mock é um arquivo JSON no seguinte formato:
{ "url": "string", "method": "string", "statusCode": "number", "response": "object", "request": "object" }
Vamos analisar cada campo separadamente.
url
Este parâmetro é usado para especificar a URL da solicitação que o cliente acessa.
Por exemplo, se um aplicativo móvel fizer uma solicitação para url
host.dom/path/to/endpoint , no campo
url , precisamos escrever
/path/to/endpoint .
Ou seja, esse campo armazena o
caminho relativo para o terminal .
Este campo deve ser formatado no formato de modelo de URL, ou seja, os seguintes formatos são permitidos:
/path/to/endpoint - endereço de URL normal. Quando a solicitação é recebida, o serviço compara as linhas caractere por caractere./path/to/endpoint/{number} - URL com padrão de caminho. Um mock com esse URL responderá a qualquer solicitação que corresponda a esse padrão./path/to/endpoint/data?param={value} - URL com padrão de parâmetro. A simulação com esse URL acionará uma solicitação contendo os parâmetros fornecidos. Além disso, se um dos parâmetros não estiver na solicitação, ele não corresponderá ao modelo.
Assim, controlando os parâmetros da URL, você pode determinar claramente que um determinado falso retornará a um URL específico.
método
Este é o método http esperado. Por exemplo,
POST ou
GET .
A sequência deve conter apenas letras maiúsculas.
statusCode
Este é o código de status http para a resposta. Ou seja, ao solicitar esta simulação, o cliente receberá uma resposta com o status registrado no campo statusCode.
resposta
Este campo contém o objeto JSON que será enviado ao cliente no corpo da resposta à sua solicitação.
pedido
Este é o corpo da solicitação que se espera que seja recebido do cliente, que será usado para fornecer a resposta desejada, dependendo do corpo da solicitação. Por exemplo, se quisermos alterar as respostas, dependendo dos parâmetros de solicitação.
{ "url": "/auth", "method": "POST", "statusCode": 200, "response": { "token": "cbshbg52rebfzdghj123dsfsfasd" }, "request": { "login": "Tester", "password": "Valid" } }
{ "url": "/auth", "method": "POST", "statusCode": 400, "response": { "message": "Bad credentials" }, "request": { "login": "Tester", "password": "Invalid" } }
Se o cliente enviar uma solicitação com o corpo:
{ "login": "Tester", "password": "Valid" }
Então, em resposta, ele receberá:
{ "token": "cbshbg52rebfzdghj123dsfsfasd" }
E caso desejemos verificar como o aplicativo funcionará se a senha for digitada incorretamente, uma solicitação será enviada com o corpo:
{ "login": "Tester", "password": "Invalid" }
Então, em resposta, ele receberá:
{ "message": "Bad credentials" }
E podemos verificar o caso com a senha errada. E assim para todos os outros casos.
E agora vamos descobrir como o agrupamento e a pesquisa do moq desejado funcionam.

Para procurar rápida e facilmente o mok desejado, o servidor carrega todos os mokas na memória e os agrupa da maneira correta. A figura acima mostra um exemplo de agrupamento.
O servidor combina diferentes mokas por
URL e
método . Isso é necessário, entre outras coisas, para que possamos criar muitos moks diferentes em um URL.
Por exemplo, queremos que, puxando constantemente a opção Puxar para atualizar, surjam respostas diferentes e o estado da tela mude o tempo todo (para verificar todos os casos de limite).
Em seguida, podemos criar muitos moks diferentes com o mesmo
método e parâmetros de
URL , e o servidor os devolverá iterativamente (por sua vez).
Por exemplo, vamos ter tais mokas:
{ "url": "/products", "method": "GET", "statusCode": 200, "response": { "name": "product", "currency": 1, "value": 20 } }
{ "url": "/products", "method": "GET", "statusCode": 200, "response": { "name": "gdshfjshhkfhsdgfhshdjgfhjkshdjkfsfgbjsfgskdf", "currency": 5, "value": 100000000000 } }
{ "url": "/products", "method": "GET", "statusCode": 200, "response": null }
{ "url": "/products", "method": "GET", "statusCode": 400, "response": null }
Então, quando chamarmos o método GET / products pela primeira vez, obteremos a resposta:
{ "name": "product", "currency": 1, "value": 20 }
Quando chamamos pela segunda vez, o ponteiro do iterador mudará para o próximo elemento e retornará para nós:
{ "name": "gdshfjshhkfhsdgfhshdjgfhjkshdjkfsfgbjsfgskdf", "currency": 5, "value": 100000000000 }
E podemos verificar como o aplicativo se comporta se obtivermos alguns grandes valores. E assim por diante
Bem, e quando chegarmos ao último elemento e chamarmos o método novamente, o primeiro elemento retornará para nós novamente, porque o iterador retornará ao primeiro elemento.
Proxy de armazenamento em cache
O Mocker pode funcionar no modo de proxy em cache. Isso significa que, quando um serviço recebe uma solicitação de um cliente, ele pega o endereço do host no qual o servidor real está localizado e o esquema (para determinar o protocolo). Em seguida, ele pega a solicitação recebida (com todos os cabeçalhos; portanto, se o método exigir autenticação, tudo bem, sua
Authorization: Bearer ... transferida) e corta as informações de serviço (a mesma
host e
scheme ) e envia a solicitação ao servidor real.
Após receber a resposta com o 200º código, o Mocker salva a resposta no arquivo Mock (sim, você pode copiá-lo ou alterá-lo) e retorna ao cliente o que recebeu do servidor real. Além disso, ele não salva apenas o arquivo em um local aleatório, mas organiza os arquivos para que você possa trabalhar com eles manualmente.Por exemplo, o Mocker envia uma solicitação para o seguinte URL:
hostname.dom/main/products/loans/info . Em seguida, ele criará uma pasta
hostname.dom , em seguida, dentro dela, criará uma pasta
main , dentro dela, uma pasta de
products ...
Para evitar zombarias duplicadas, o nome é formado com base no
método http (GET, PUT ...) e um
hash do corpo de resposta do servidor real . Nesse caso, se já houver uma simulação em uma resposta específica, ela será simplesmente substituída.
Esse recurso pode ser ativado individualmente para cada solicitação. Para fazer isso, adicione três cabeçalhos à solicitação:
X-Mocker-Redirect-Is-On: "true", X-Mocker-Redirect-Host: "hostaname.ex:1234", X-Mocker-Redirect-Scheme: "http"
Indicação explícita do caminho para as zombarias
Às vezes, você deseja que o Mocker retorne apenas os mokas que queremos, e não todos que estão no projeto.
Especialmente relevante para testadores. Seria conveniente que eles tivessem algum tipo de conjunto de mokas preparado para cada um dos casos de teste. E, durante o teste, o controle de qualidade apenas seleciona a pasta de que precisa e trabalha silenciosamente, porque não há mais ruído nas zombarias de terceiros.
Agora isso é possível. Para habilitar esta função, você precisa usar um cabeçalho especial:
X-Mocker-Specific-Path: path
Por exemplo, deixe o Mocker ter uma estrutura de pastas na raiz
root/ block_card_test_case/ mocks.... main_test_case/ blocked_test_case/ mocks...
Se você precisar executar um caso de teste sobre cartões bloqueados,
X-Mocker-Specific-Path: block_card_test_caseSe você precisar executar um caso de teste associado ao bloqueio da tela principal,
X-Mocker-Specific-Path: main_test_case/blocked_test_caseInterface
Inicialmente, trabalhamos com mokas diretamente via ssh, mas com um aumento no número de mokas e usuários, passamos para uma opção mais conveniente. Agora estamos usando o CloudCommander.
No exemplo do docker-compose, ele se liga ao contêiner do Mocker.
Parece algo como isto:
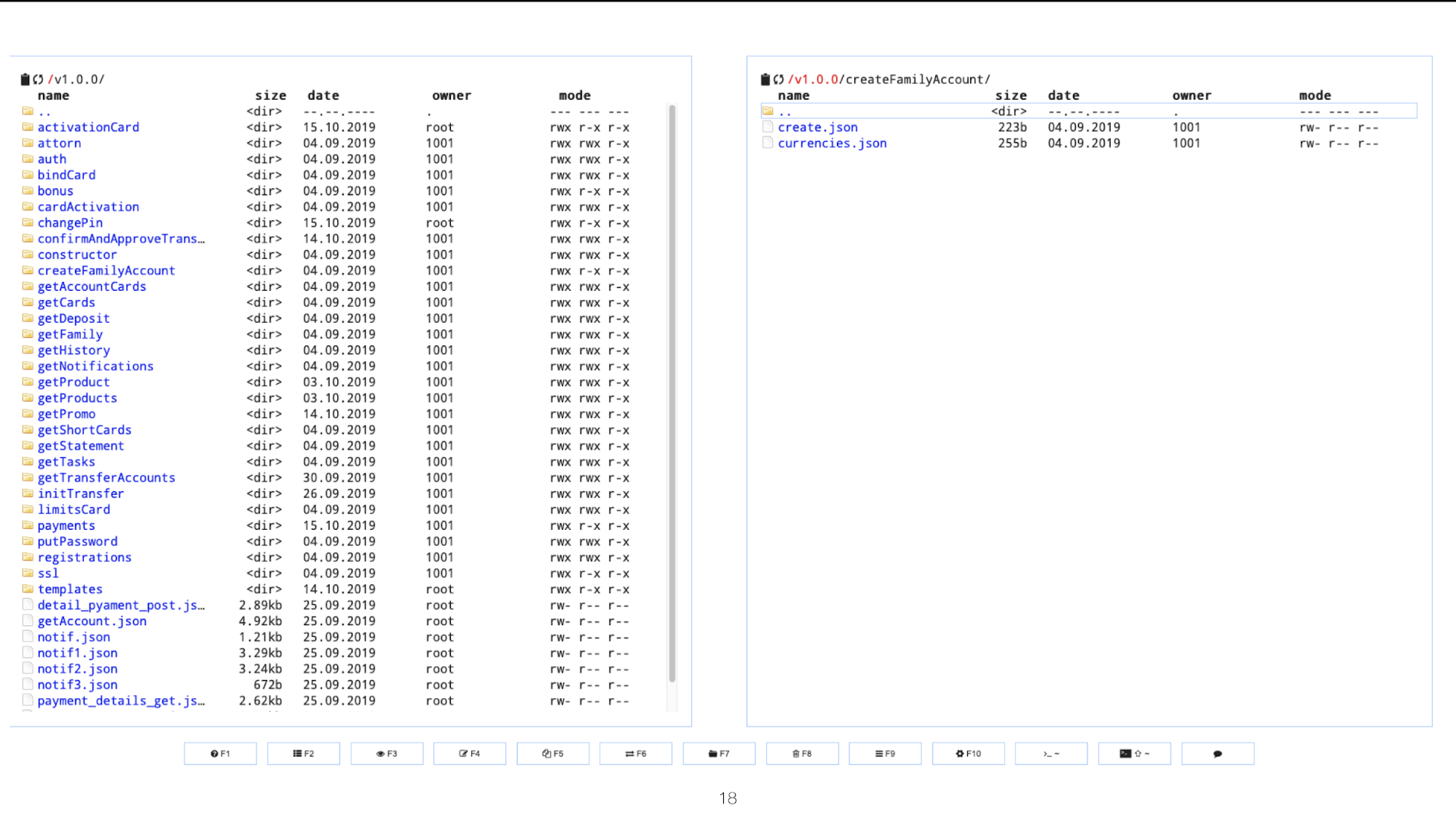
Bem, o bônus é um editor da web, que permite adicionar / alterar o moki diretamente do navegador.

Essa também é uma solução temporária. Nos planos de deixar de trabalhar com moks através do sistema de arquivos para algum banco de dados. E, consequentemente, será possível controlar os próprios mokas da GUI para esse banco de dados.
Implantação
A maneira mais fácil de implantar o Mocker é usar o Docker. Além disso, a implantação do serviço a partir do docker implementará automaticamente uma interface baseada na Web, através da qual é mais conveniente trabalhar com mokas. Os arquivos necessários para implantação através do Docker estão no repositório.
No entanto, se essa opção não for adequada para você, você poderá montar o serviço independentemente da origem. O suficiente para isso:
git clone https://github.com/LastSprint/mocker.git cd mocker go build .
Então você precisa escrever um arquivo de configuração (
exemplo ) e iniciar o serviço:
mocker config.json
Problemas conhecidos
- Após cada novo arquivo, você precisa
curl mockerhost.dom/update_models para que o serviço leia os arquivos novamente. Não encontrei uma maneira rápida e elegante de atualizá-lo. - Às vezes, o CloudCommander falha (ou fiz algo errado) e não permite editar moki que foram criados através da interface da web. É tratado limpando o cache do navegador.
- O serviço funciona apenas com
application/json . Os planos oferecem suporte form-url-encoding .
Sumário
O Mocker é um serviço da Web que resolve os problemas de desenvolvimento de aplicativos cliente-servidor quando o servidor não está pronto por algum motivo.
O serviço permite criar muitas simulações diferentes em uma única URL, permite conectar Solicitação e Resposta entre si, especificando explicitamente parâmetros no URL ou diretamente, configurando o corpo da solicitação esperado. O serviço possui uma interface baseada na Web que simplifica bastante a vida dos usuários.
Cada usuário do serviço pode adicionar independentemente o terminal necessário e a solicitação de que ele precisa. Nesse caso, no cliente, para alternar para um servidor real, basta substituir a constante pelo endereço do host.
Espero que este artigo ajude as pessoas que sofrem de problemas semelhantes e, talvez, trabalhemos juntos para desenvolver essa ferramenta.
Repositório do GitHub .