A pergunta clássica de que um desenvolvedor chega ao seu DBA ou ao proprietário de uma empresa, um consultor do PostgreSQL, quase sempre soa o mesmo:
"Por que as consultas são executadas no banco de dados por tanto tempo?"O conjunto tradicional de razões:
- algoritmo ineficiente
quando você decidiu fazer uma junção de várias CTEs para algumas dezenas de milhares de registros - estatísticas irrelevantes
se a distribuição real dos dados na tabela já for muito diferente da última vez que a ANALYZE os coletou - "Mordaça" por recursos
e o poder de computação alocado da CPU já não é suficiente, gigabytes de memória são constantemente bombeados ou o disco não acompanha todo o banco de dados “Wishlist” - impedimento de processos concorrentes
E se os bloqueios forem muito difíceis de capturar e analisar, então, para todo o resto, precisamos de
um plano de consulta que possa ser obtido usando
o operador EXPLAIN (
melhor, é claro, imediatamente EXPLAIN (ANALYZE, BUFFERS) ... ) ou
o módulo auto_explain .
Mas, como dito na mesma documentação,
"Entender o plano é uma arte e, para dominá-lo, você precisa de alguma experiência ..."
Mas você pode ficar sem ele, se você usar a ferramenta certa!
Como é geralmente um plano de consulta? Algo assim:
Index Scan using pg_class_relname_nsp_index on pg_class (actual time=0.049..0.050 rows=1 loops=1) Index Cond: (relname = $1) Filter: (oid = $0) Buffers: shared hit=4 InitPlan 1 (returns $0,$1) -> Limit (actual time=0.019..0.020 rows=1 loops=1) Buffers: shared hit=1 -> Seq Scan on pg_class pg_class_1 (actual time=0.015..0.015 rows=1 loops=1) Filter: (relkind = 'r'::"char") Rows Removed by Filter: 5 Buffers: shared hit=1
ou assim:
"Append (cost=868.60..878.95 rows=2 width=233) (actual time=0.024..0.144 rows=2 loops=1)" " Buffers: shared hit=3" " CTE cl" " -> Seq Scan on pg_class (cost=0.00..868.60 rows=9972 width=537) (actual time=0.016..0.042 rows=101 loops=1)" " Buffers: shared hit=3" " -> Limit (cost=0.00..0.10 rows=1 width=233) (actual time=0.023..0.024 rows=1 loops=1)" " Buffers: shared hit=1" " -> CTE Scan on cl (cost=0.00..997.20 rows=9972 width=233) (actual time=0.021..0.021 rows=1 loops=1)" " Buffers: shared hit=1" " -> Limit (cost=10.00..10.10 rows=1 width=233) (actual time=0.117..0.118 rows=1 loops=1)" " Buffers: shared hit=2" " -> CTE Scan on cl cl_1 (cost=0.00..997.20 rows=9972 width=233) (actual time=0.001..0.104 rows=101 loops=1)" " Buffers: shared hit=2" "Planning Time: 0.634 ms" "Execution Time: 0.248 ms"
Mas ler o plano com o texto “da folha” é muito difícil e amado:
- o nó exibe a soma dos recursos da subárvore
isto é, para entender quanto tempo levou para executar um nó específico ou exatamente quanto essa leitura da tabela gerou dados do disco - você precisa subtrair de alguma forma uma da outra - o tempo do nó deve ser multiplicado por loops
sim, a subtração não é a operação mais difícil que precisa ser feita "na mente" - afinal, o tempo de execução é indicado como média em uma execução do nó e pode haver centenas delas - bem, e tudo isso junto dificulta a resposta à pergunta principal - então quem é o "elo mais fraco" ?
Quando tentamos explicar tudo isso para várias centenas de nossos desenvolvedores, percebemos que do lado de fora se parece com isso:

E isso significa que precisamos ...
Instrumento
Nele, tentamos coletar todas as principais mecânicas que ajudam de acordo com o plano e solicitam entender "quem é o culpado e o que fazer". Bem, compartilhe um pouco da sua experiência com a comunidade.
Conheça e use -
explan.tensor.ruPlanos claros
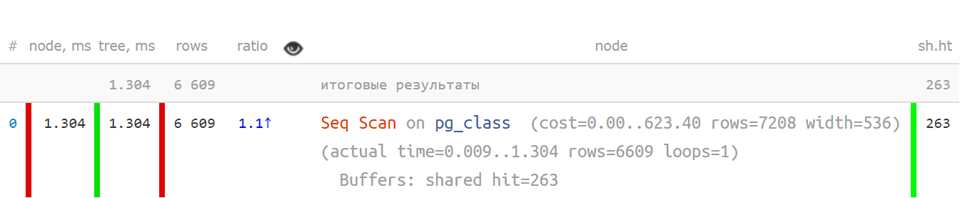
É fácil entender um plano quando é assim?
Seq Scan on pg_class (actual time=0.009..1.304 rows=6609 loops=1) Buffers: shared hit=263 Planning Time: 0.108 ms Execution Time: 1.800 ms
Na verdade não.
Mas assim, de
forma abreviada , quando os principais indicadores são separados - já é muito mais claro:
Porém, se o plano for mais complicado, a
distribuição de tempo em partes por nós será útil:
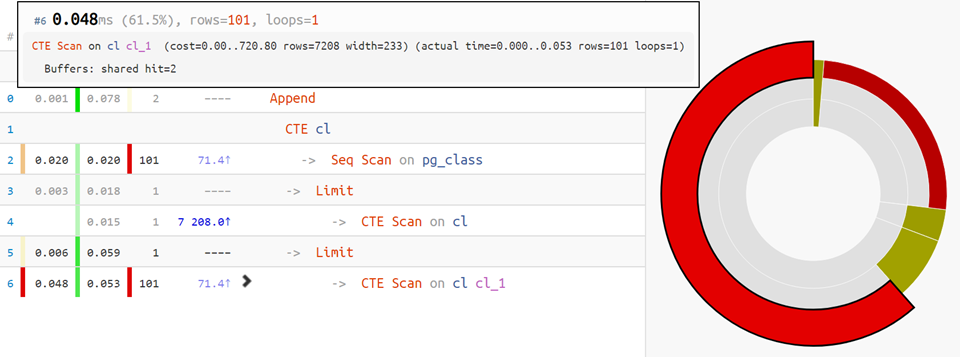
Bem, para as opções mais difíceis,
o diagrama de execução se apressa para ajudar:
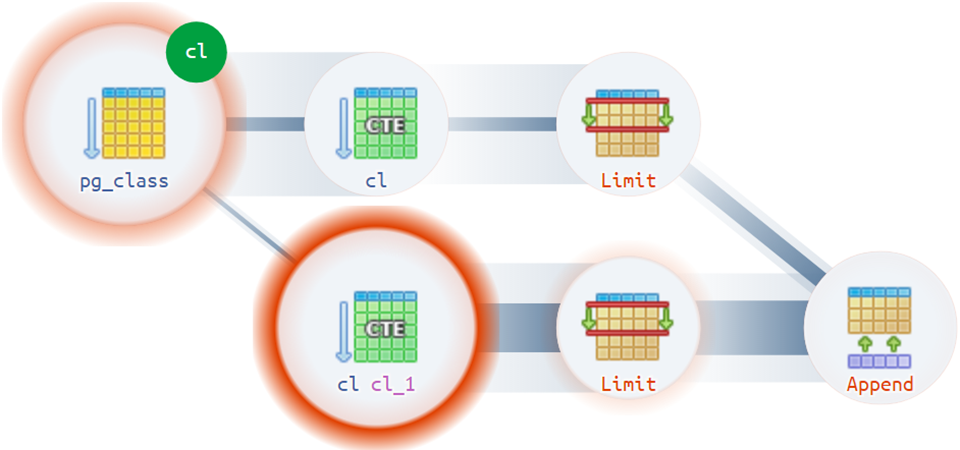
Por exemplo, há situações não triviais em que um plano pode ter mais de uma raiz real:
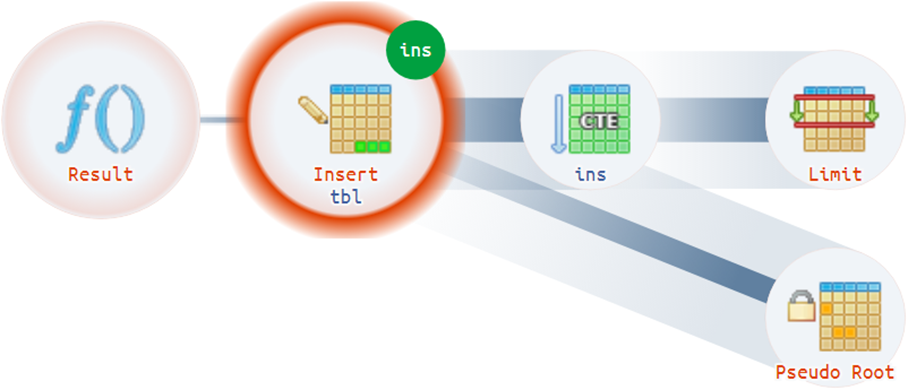
Dicas Estruturais
Bem, e se toda a estrutura do plano e seus pontos doloridos já estiverem definidos e visíveis - por que não destacá-los com o desenvolvedor e explicá-los com o "idioma russo"?

Já coletamos algumas dezenas de modelos de recomendação.
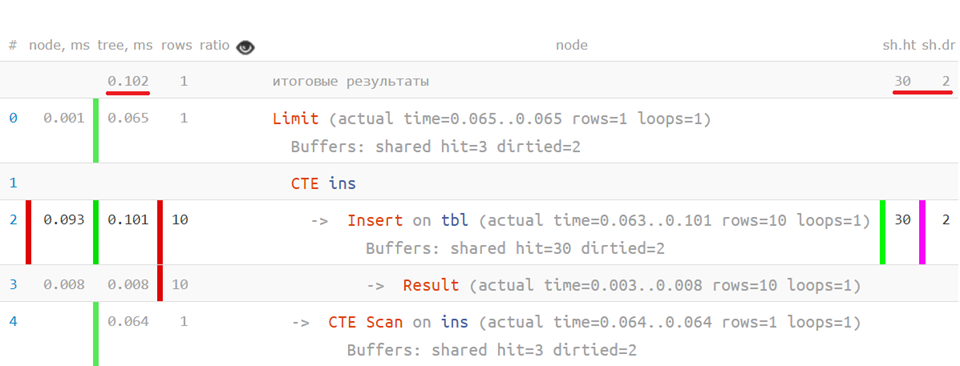
Perfil de consulta
Agora, se você colocar a consulta original no plano analisado, poderá ver quanto tempo levou para cada operador individual - algo como isto:
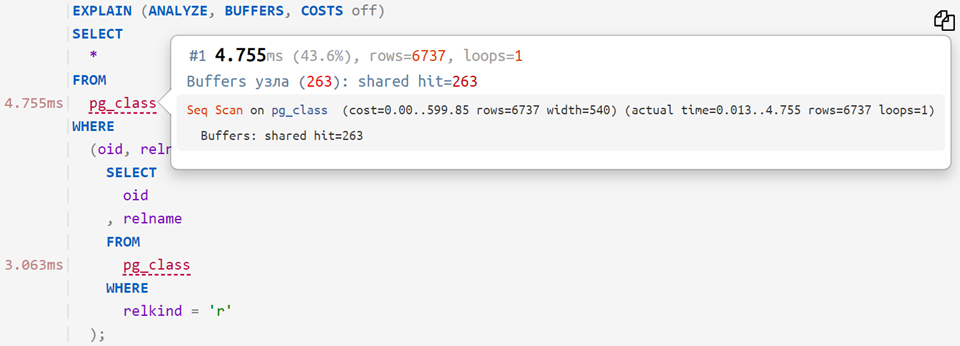
... ou mesmo assim:

Substituição de parâmetros na solicitação
Se você "anexou" não apenas a solicitação ao plano, mas também seus parâmetros da linha DETAIL do log, é possível copiá-la adicionalmente em uma das opções:
- com substituição de valores na solicitação
para execução direta em sua base e perfis adicionais
SELECT 'const', 'param'::text;
- com substituição de valor via PREPARE / EXECUTE
emular o trabalho do planejador quando a parte paramétrica pode ser ignorada - por exemplo, ao trabalhar em tabelas particionadas
DEALLOCATE ALL; PREPARE q(text) AS SELECT 'const', $1::text; EXECUTE q('param'::text);
Arquivo de Planos
Inserir, analisar, compartilhar com colegas! Os planos permanecerão no arquivo
morto e você poderá retornar a eles mais tarde:
explan.tensor.ru/archiveMas se você não deseja que outras pessoas vejam seu plano, não se esqueça de marcar a caixa de seleção "não publicar no arquivo".
Nos artigos a seguir, falarei sobre as dificuldades e soluções que surgem na análise do plano.