Oi
Acontece que você assiste a um filme, e na sua cabeça há apenas uma pergunta: "Estou recebendo a isca de novo?" Vamos resolver esse problema e assistiremos apenas a filmes adequados. Sugiro experimentar um pouco os dados e escrever uma rede neural simples para avaliar o filme.
Nosso experimento é baseado na tecnologia de análise de sentimentos para determinar o humor do público em relação a um produto. Como dados, coletamos um conjunto de dados de avaliações de usuários em filmes da IMDb. O ambiente de desenvolvimento do Google Colab permitirá que você treine rapidamente sua rede neural, graças ao acesso gratuito à GPU (NVidia Tesla K80).
Uso a biblioteca Keras, com a ajuda da qual construirei um modelo universal para resolver problemas semelhantes de aprendizado de máquina. Vou precisar do back-end TensorFlow, a versão padrão no Colab 1.15.0, então atualize para o 2.0.0.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h
Em seguida, importamos todos os módulos necessários para pré-processamento de dados e construção de modelo. Nos artigos anteriores, a ênfase está nas bibliotecas, você pode procurar lá.
%matplotlib inline import matplotlib import matplotlib.pyplot as plt
import numpy as np from keras.utils import to_categorical from keras import models from keras import layers from keras.datasets import imdb
Analisando dados da IMDb
O conjunto de dados da IMDb consiste em 50.000 críticas de filmes de usuários marcados como positivo (1) e negativo (0).
- As revisões são pré-processadas e cada uma delas é codificada por uma sequência de índices de palavras na forma de números inteiros.
- As palavras nas revisões são indexadas pela frequência total no conjunto de dados. Por exemplo, o número inteiro “2” codifica a segunda palavra usada com mais frequência
- 50.000 revisões são divididas em dois conjuntos: 25.000 para treinamento e 25.000 para testes.
Faça o download do conjunto de dados incorporado ao Keras. Como os dados são divididos em treinamento e teste em uma proporção de 50 a 50, eu os combinarei para que mais tarde eu possa dividi-los por 80 a 20.
from keras.datasets import imdb (training_data, training_targets), (testing_data, testing_targets) = imdb.load_data(num_words=10000) data = np.concatenate((training_data, testing_data), axis=0) targets = np.concatenate((training_targets, testing_targets), axis=0)
Exploração de dados
Vamos ver com o que estamos trabalhando.
print("Categories:", np.unique(targets)) print("Number of unique words:", len(np.unique(np.hstack(data))))

length = [len(i) for i in data] print("Average Review length:", np.mean(length)) print("Standard Deviation:", round(np.std(length)))

Você pode ver que todos os dados pertencem a duas categorias: 0 ou 1, o que representa o clima da revisão. O conjunto de dados inteiro contém 9998 palavras exclusivas, o tamanho médio da revisão é 234 palavras com um desvio padrão de 173.
Vejamos a primeira revisão desse conjunto de dados, marcada como positiva.
print("Label:", targets[0]) print(data[0])

index = imdb.get_word_index() reverse_index = dict([(value, key) for (key, value) in index.items()]) decoded = " ".join( [reverse_index.get(i - 3, "#") for i in data[0]] ) print(decoded)

Preparação de dados
É hora de preparar os dados. Precisamos vetorizar cada pesquisa e preenchê-la com zeros para que o vetor contenha exatamente 10.000 números. Isso significa que toda revisão com menos de 10.000 palavras é preenchida com zeros. Faço isso porque a maior visão geral tem quase o mesmo tamanho e cada elemento de entrada da nossa rede neural deve ter o mesmo tamanho. Você também precisa converter as variáveis em um tipo de flutuação.
def vectorize(sequences, dimension = 10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1 return results data = vectorize(data) targets = np.array(targets).astype("float32")
Em seguida, divido o conjunto de dados em dados de treinamento e teste, conforme acordado 4: 1.
test_x = data[:10000] test_y = targets[:10000] train_x = data[10000:] train_y = targets[10000:]
Criar e treinar um modelo
A coisa é pequena, resta apenas escrever um modelo e treiná-lo. Comece escolhendo um tipo. Dois tipos de modelos estão disponíveis no Keras: seqüencial e com uma API funcional. Então você precisa adicionar camadas de entrada, ocultas e de saída.
Para evitar a reciclagem, usaremos um "abandono" entre eles.Em cada camada, usamos a função "densa" para conectar completamente as camadas umas às outras. Em camadas ocultas, usaremos a função de ativação “relu”, isso quase sempre leva a resultados satisfatórios. Na camada de saída, usamos uma função sigmóide que renormaliza os valores no intervalo de 0 a 1.
Eu uso o adam optimizer, ele mudará de peso durante o treinamento.
Usamos entropia cruzada binária como uma função de perda e precisão como uma métrica de medida.
Agora você pode treinar nosso modelo. Faremos isso com um tamanho de lote de 500 e apenas três épocas, pois foi revelado que o modelo começa a ser treinado novamente se for treinado por mais tempo.
model = models.Sequential()
Conclusão
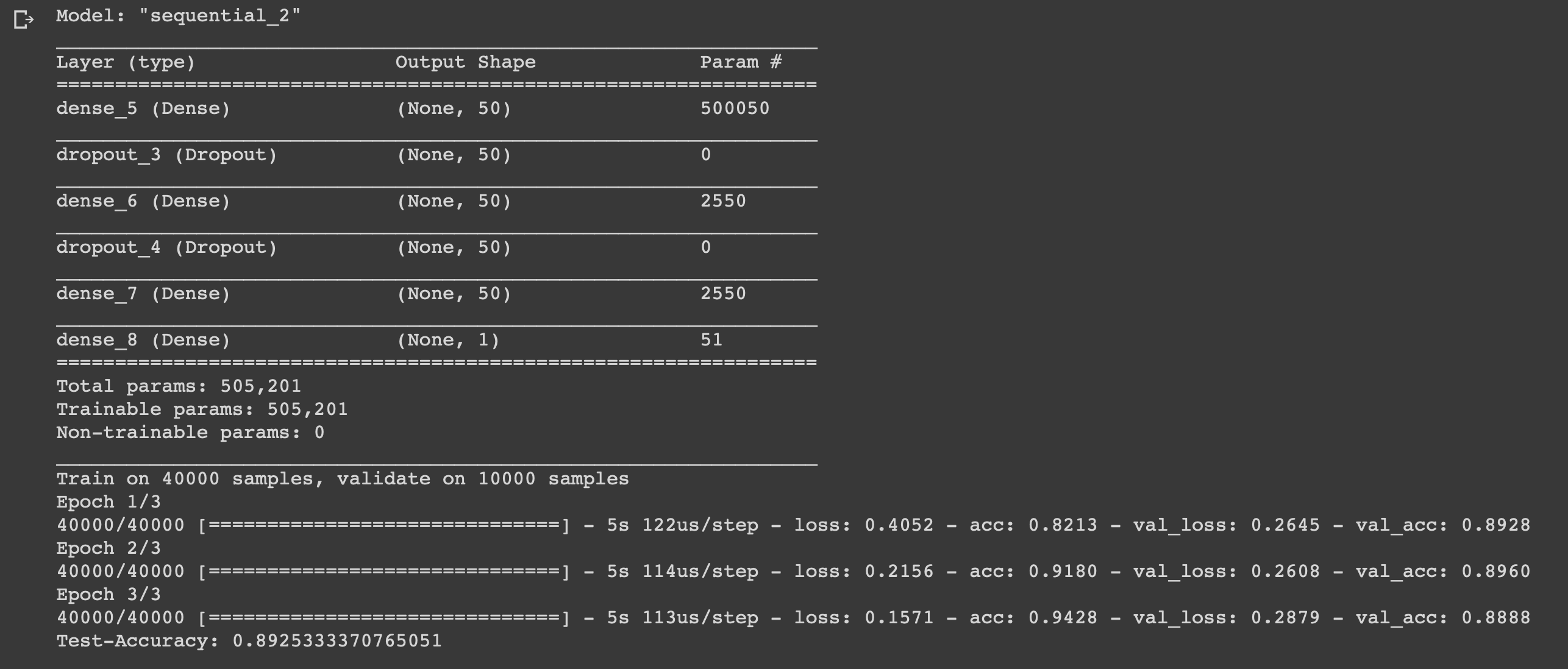
Criamos uma rede neural simples de seis camadas que pode calcular o humor dos cineastas com uma precisão de 0,89. Obviamente, para assistir filmes legais, não é necessário escrever uma rede neural, mas esse foi apenas mais um exemplo de como você pode usar os dados e se beneficiar deles, porque é necessário para isso. A rede neural é universal devido à simplicidade de sua estrutura, alterando alguns parâmetros, você pode adaptá-la para tarefas completamente diferentes.
Sinta-se livre para escrever suas idéias nos comentários.