
Tudo começou, ao que parece, com uma pergunta simples que me levou a um estupor - "Por que preciso fazer? Por que não consigo me dar bem com scripts bash ?". E eu pensei - sério, por que preciso fazer? (e mais importante) Que problemas ele resolve?
Então decidi pensar um pouco - como coletaríamos nossos projetos se não tivéssemos o projeto. Digamos que temos um projeto com códigos-fonte. Neles, você precisa obter um arquivo executável (ou biblioteca). À primeira vista, a tarefa parece simples, mas fomos além. Suponha que, no estágio inicial, o projeto consista em um arquivo.
Para compilá-lo, basta executar um comando:
$ gcc main.c -o main
Foi bem simples. Mas algum tempo passa, o projeto se desenvolve, alguns módulos aparecem nele e os arquivos de origem se tornam maiores.

Para compilar, você precisa executar condicionalmente o seguinte número de comandos:
$ gcc -c src0.c $ gcc -c src1.c $ gcc -c main.c $ gcc -o main main.o src0.o src1.o
Concordo, este é um processo bastante demorado e meticuloso. Para fazer isso manualmente, eu não faria. Eu acho que esse processo pode ser automatizado simplesmente criando um script build.sh que contém esses comandos. Ok, isso é muito mais fácil:
$ ./build.sh
Nós seguimos em frente! O projeto está crescendo, o número de arquivos de origem está aumentando e há mais linhas neles também. Estamos começando a perceber que o tempo de compilação aumentou acentuadamente. Aqui vemos uma falha significativa em nosso script - ele compila todos os nossos 50 arquivos com as fontes, embora apenas tenhamos modificado um.
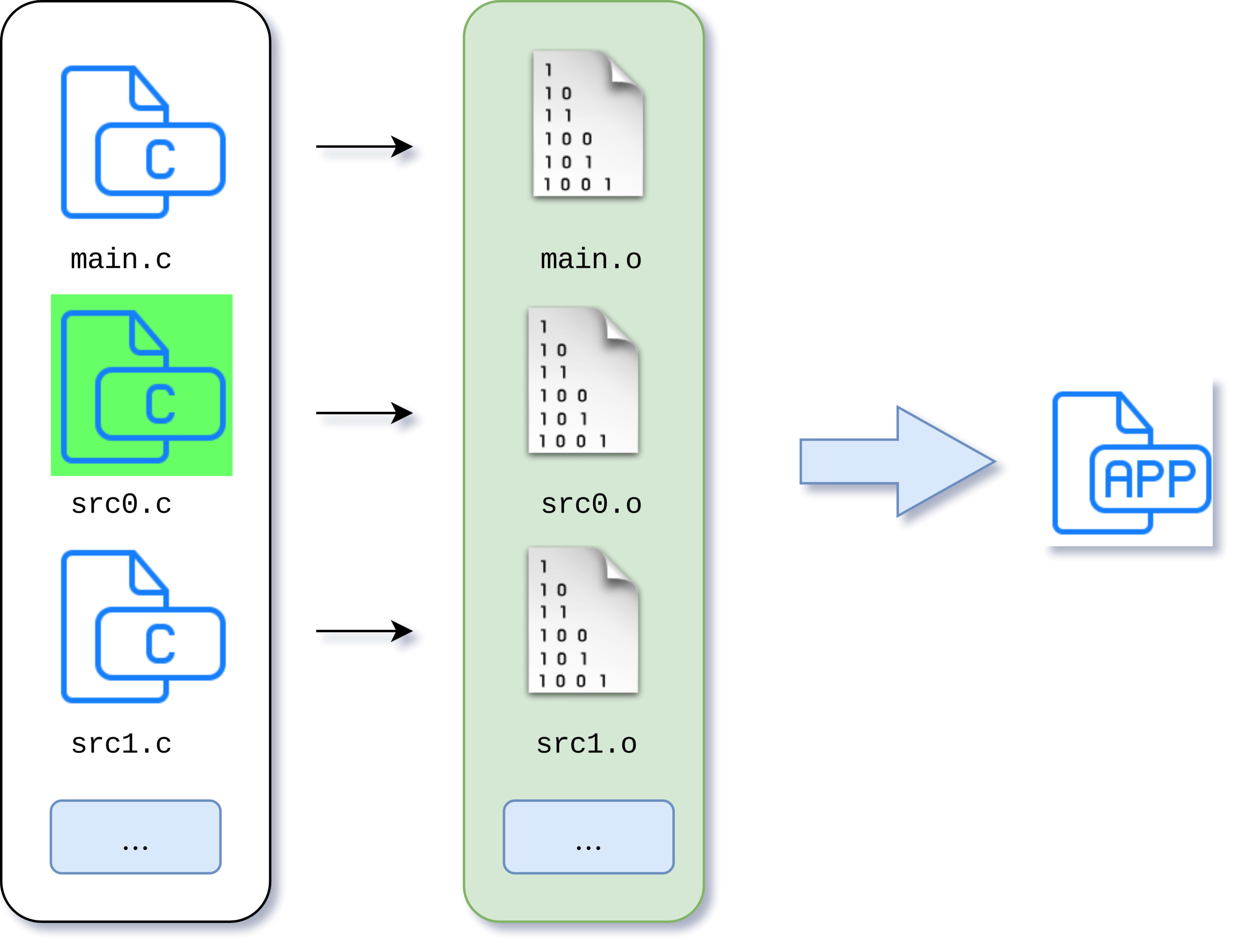
Não vai dar certo! O tempo do desenvolvedor é um recurso muito valioso. Bem, podemos tentar modificar o script de construção para que, antes da compilação, verifiquemos a hora da modificação dos arquivos de origem e de objeto. E compile apenas as fontes que foram alteradas. E condicionalmente, pode ser algo como isto:
E agora apenas as fontes que foram modificadas serão compiladas.

Mas o que acontece quando o projeto se transforma em algo assim:
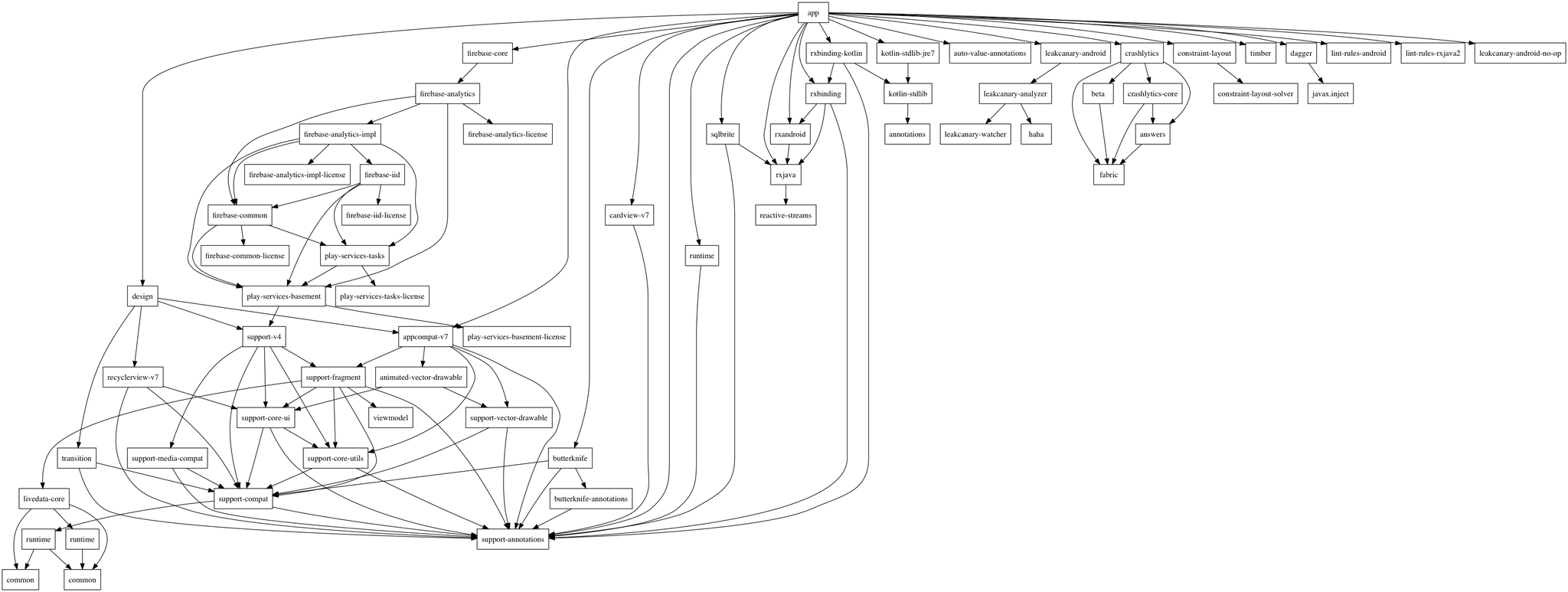
Mais cedo ou mais tarde, chegará um momento em que será muito difícil entender o projeto e o suporte a esses scripts se tornará um processo trabalhoso. E não é fato que esse script verifique adequadamente todas as dependências. Além disso, podemos ter vários projetos e cada um terá seu próprio script para montagem.
Obviamente, vemos que uma solução geral para esse problema surge. Uma ferramenta que forneceria um mecanismo para verificar dependências. E aqui estamos lentamente chegando à invenção do make . E agora, sabendo quais problemas enfrentaremos no processo de construção do projeto, no final, formularia os seguintes requisitos para o make:
- análise de timestamps de dependências e objetivos
- quantidade mínima de trabalho necessária para garantir a relevância dos arquivos derivados
- (bem, + execução paralela de comandos)
Makefile
Makefiles são usados para descrever as regras de montagem do projeto. Criando um Makefile, descrevemos declarativamente um certo estado de relações entre arquivos. A natureza declarativa da determinação do estado é conveniente, pois dizemos que temos uma lista de arquivos e precisamos obter um novo arquivo deles executando uma lista de comandos. No caso de usar alguma linguagem imperativa (por exemplo, shell), teríamos que executar um grande número de verificações diferentes, obtendo código complexo e confuso na saída, enquanto o make faz isso por nós. O principal é construir a árvore de dependência correta.
< > : < ... > < > ... ...
Não vou falar sobre como escrever Makefiles. Na Internet, existem muitos manuais sobre esse assunto e, se desejar, você pode consultá-los. Além disso, poucas pessoas escrevem Makefiles manualmente. E Makefiles muito complexos podem ser uma fonte de complicações em vez de simplificar o processo de compilação.