
O design de análises de streaming e sistemas de processamento de dados de streaming tem suas próprias nuances, seus próprios problemas e sua própria pilha tecnológica. Conversamos sobre isso na próxima
lição aberta , realizada na véspera do lançamento do curso de
Engenharia de Dados .
No webinar discutido:
- quando o processamento de streaming é necessário;
- quais elementos estão no SPOD, que ferramentas podemos usar para implementar esses elementos;
- como criar seu próprio sistema de análise de fluxo de cliques.
Professor -
Yegor Mateshuk , engenheiro de dados sênior da MaximaTelecom.
Quando é necessário o streaming? Stream vs Batch
Primeiro de tudo, devemos descobrir quando precisamos de streaming e quando o processamento em lote. Vamos explicar os pontos fortes e fracos dessas abordagens.
Portanto, as desvantagens do processamento em lote:- os dados são entregues com um atraso. Como temos um certo período de cálculos, nesse período sempre ficamos para trás em tempo real. E quanto mais iteração, mais ficamos para trás. Assim, temos um atraso de tempo, que em alguns casos é crítico;
- carga de pico no ferro é criada. Se calcularmos muito no modo de lote, no final do período (dia, semana, mês), temos um pico de carga, porque você precisa calcular muitas coisas. O que isso leva a? Primeiro, começamos a descansar contra limites que, como você sabe, não são infinitos. Como resultado, o sistema é executado periodicamente até o limite, o que geralmente resulta em falhas. Em segundo lugar, como todos esses trabalhos começam ao mesmo tempo, eles competem e são calculados muito lentamente, ou seja, você não pode contar com um resultado rápido.
Mas o processamento em lote tem suas vantagens:- alta eficiência. Não aprofundaremos, pois a eficiência está associada à compactação, às estruturas e ao uso de formatos de coluna etc. O fato é que o processamento em lote, se você considerar o número de registros processados por unidade de tempo, será mais eficiente;
- facilidade de desenvolvimento e suporte. Você pode processar qualquer parte dos dados testando e recontando conforme necessário.
Vantagens do processamento de dados de streaming (streaming):- resultar em tempo real. Não esperamos o final de nenhum período: assim que os dados (mesmo que em quantidade muito pequena) cheguem até nós, podemos processá-los e transmiti-los imediatamente. Ou seja, o resultado, por definição, está lutando por tempo real;
- carga uniforme em ferro. É claro que existem ciclos diários etc., no entanto, a carga ainda é distribuída ao longo do dia e resulta mais uniforme e previsível.
A principal desvantagem do processamento de streaming:- complexidade de desenvolvimento e suporte. Primeiro, testar, gerenciar e recuperar dados é um pouco mais difícil quando comparado ao lote. A segunda dificuldade (na verdade, esse é o problema mais básico) está associada a reversões. Se os trabalhos não funcionaram e houve uma falha, é muito difícil capturar exatamente o momento em que tudo ocorreu. E resolver o problema exigirá mais esforço e recursos do que o processamento em lote.
Portanto, se você está pensando
se precisa de fluxos , responda as seguintes perguntas:
- Você realmente precisa em tempo real?
- Existem muitas fontes de streaming?
- Perder um registro é crítico?
Vejamos
dois exemplos :
Exemplo 1. Análise de estoque para varejo:- a exibição de mercadorias não muda em tempo real;
- os dados geralmente são entregues no modo em lote;
- a perda de informações é crítica.
Neste exemplo, é melhor usar o lote.
Exemplo 2. Análise para um portal da web:- a velocidade da análise determina o tempo de resposta a um problema;
- os dados chegam em tempo real;
- Perdas de uma pequena quantidade de informações da atividade do usuário são aceitáveis.
Imagine que a análise reflete como os visitantes de um portal da web se sentem usando seu produto. Por exemplo, você lançou uma nova versão e precisa entender dentro de 10 a 30 minutos se tudo está em ordem, se algum recurso personalizado foi quebrado. Digamos que o texto do botão "Pedido" se foi - a análise permitirá que você responda rapidamente a uma queda acentuada no número de pedidos e você entenderá imediatamente que precisa reverter.
Assim, no segundo exemplo, é melhor usar fluxos.
Elementos SPOD
Os engenheiros de processamento de dados capturam, movem, entregam, convertem e armazenam esses mesmos dados (sim, o armazenamento de dados também é um processo ativo!).
Portanto, para construir um sistema de processamento de dados de streaming (SPOD), precisaremos dos seguintes elementos:
- carregador de dados (meios de entrega de dados ao armazenamento);
- barramento de troca de dados (nem sempre é necessário, mas não há como transmitir sem ele, porque você precisa de um sistema através do qual trocará dados em tempo real);
- armazenamento de dados (como sem ele);
- Mecanismo de ETL (necessário para realizar várias operações de filtragem, classificação e outras);
- BI (para exibir resultados);
- orquestrador (vincula todo o processo, organizando o processamento de dados em vários estágios).
No nosso caso, consideraremos a situação mais simples e focaremos apenas nos três primeiros elementos.
Ferramentas de processamento de fluxo de dados
Temos vários "candidatos" para o papel de
carregador de
dados :
- Apache flume
- Apache nifi
- Streamset
Apache flume
O primeiro sobre o qual falaremos é o
Apache Flume , uma ferramenta para transportar dados entre diferentes fontes e repositórios.

Prós:
- existe quase todo lugar
- há muito usado
- flexível e extensível o suficiente
Contras:
- configuração inconveniente
- difícil de monitorar
Quanto à sua configuração, é algo como isto:

Acima, criamos um canal simples que fica na porta, pega os dados de lá e simplesmente os registra. Em princípio, para descrever um processo, isso ainda é normal, mas quando você tem dezenas desses processos, o arquivo de configuração se transforma em um inferno. Alguém adiciona alguns configuradores visuais, mas por que se preocupar se existem ferramentas que o tornam pronto para uso? Por exemplo, o mesmo NiFi e StreamSets.
Apache nifi
De fato, ele desempenha o mesmo papel que o Flume, mas com uma interface visual, o que é uma grande vantagem, especialmente quando há muitos processos.
Alguns fatos sobre o NiFi
- originalmente desenvolvido na NSA;
- O Hortonworks agora é suportado e desenvolvido;
- parte do HDF da Hortonworks;
- possui uma versão especial do MiNiFi para coletar dados de dispositivos.
O sistema se parece com isso:
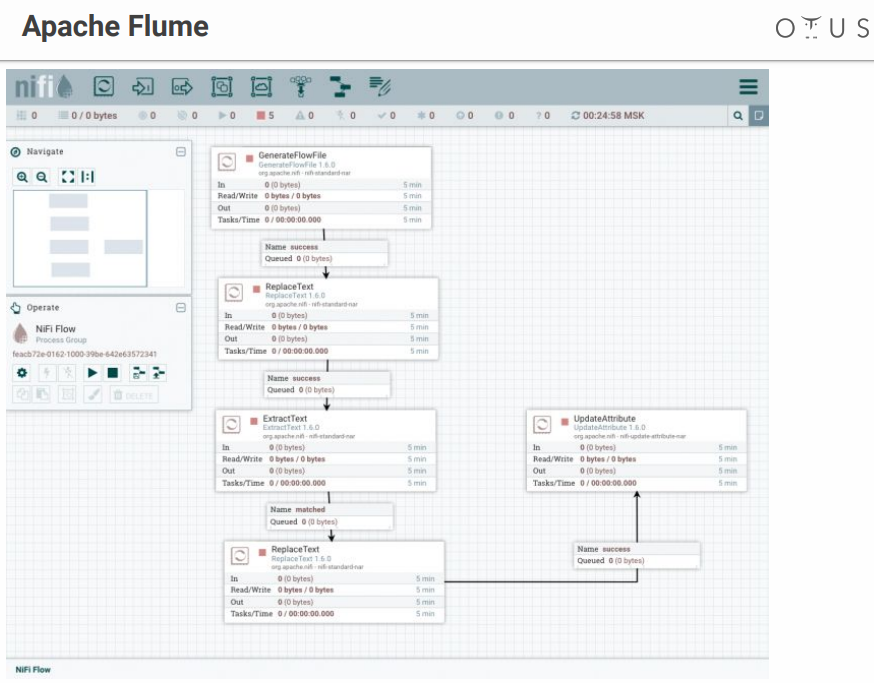
Temos um campo de criatividade e estágios de processamento de dados que lançamos lá. Existem muitos conectores para todos os sistemas possíveis, etc.
Streamset
É também um sistema de controle de fluxo de dados com uma interface visual. Foi desenvolvido por pessoas da Cloudera, é facilmente instalado como Parcel no CDH, possui uma versão especial do SDC Edge para coletar dados de dispositivos.
Consiste em dois componentes:
- SDC - um sistema que realiza processamento direto de dados (gratuito);
- StreamSets Control Hub - um centro de controle para vários SDCs com recursos adicionais para o desenvolvimento de linhas de pagamento (pagas).
Parece algo como isto:

Momento desagradável - o StreamSets tem peças gratuitas e pagas.
Barramento de dados
Agora vamos descobrir onde faremos o upload desses dados. Requerentes:
O Apache Kafka é a melhor opção, mas se você tiver RabbitMQ ou NATS em sua empresa e precisar adicionar um pouco de análise, a implantação do Kafka a partir do zero não será muito lucrativa.
Em todos os outros casos, Kafka é uma ótima opção. Na verdade, é um intermediário de mensagens com escala horizontal e largura de banda enorme. É perfeitamente integrado a todo o ecossistema de ferramentas para trabalhar com dados e pode suportar cargas pesadas. Tem uma interface universal e é o sistema circulatório do nosso processamento de dados.
Por dentro, o Kafka é dividido em Tópico - um determinado fluxo de dados separado de mensagens com o mesmo esquema ou, pelo menos, com o mesmo objetivo.
Para discutir a próxima nuance, lembre-se de que as fontes de dados podem variar um pouco. O formato dos dados é muito importante:

O formato de serialização de dados Apache Avro merece menção especial. O sistema usa JSON para determinar a estrutura de dados (esquema) que é serializada em um
formato binário compacto . Portanto, economizamos uma quantidade enorme de dados e a serialização / desserialização é mais barata.
Tudo parece estar bem, mas a presença de arquivos separados com circuitos apresenta um problema, pois precisamos trocar arquivos entre sistemas diferentes. Parece simples, mas quando você trabalha em departamentos diferentes, os funcionários do outro lado podem mudar alguma coisa e se acalmar, e tudo vai desmoronar para você.
Para não transferir todos esses arquivos para unidades flash, disquetes e pinturas rupestres, existe um serviço especial - registro de esquema. Este é um serviço para sincronizar esquemas avro entre serviços que escrevem e leem do Kafka.

Em termos de Kafka, o produtor é quem escreve, o consumidor é quem consome (lê) os dados.
Data warehouse
Desafiantes (de fato, existem muitas mais opções, mas são necessárias apenas algumas):
- HDFS + Hive
- Kudu + Impala
- Clickhouse
Antes de escolher um repositório, lembre-se do que
é idempotência . A Wikipedia diz que idempotência (latim idem - o mesmo + potens - capaz) - a propriedade de um objeto ou operação ao aplicar a operação ao objeto novamente, fornece o mesmo resultado que o primeiro. No nosso caso, o processo de processamento de streaming deve ser construído para que, ao preencher novamente os dados de origem, o resultado permaneça correto.
Como conseguir isso em sistemas de streaming:
- identificar um ID exclusivo (pode ser composto)
- use esse ID para deduplicar dados
O armazenamento HDFS + Hive
não fornece idempotência para a gravação de streaming "
pronta para uso", portanto, temos:
O Kudu é um repositório adequado para consultas analíticas, mas com uma Chave Primária, para desduplicação.
Impala é a interface SQL para este repositório (e vários outros).
Quanto ao ClickHouse, este é um banco de dados analítico da Yandex. Seu principal objetivo é a análise em uma tabela preenchida com um grande fluxo de dados brutos. Das vantagens - existe um mecanismo ReplacingMergeTree para desduplicação de chave (a desduplicação foi projetada para economizar espaço e pode deixar duplicados em alguns casos, é necessário levar em consideração as
nuances ).
Resta acrescentar algumas palavras sobre o
Divolte . Se você se lembra, falamos sobre o fato de que alguns dados precisam ser capturados. Se você precisar organizar de forma rápida e fácil as análises para um portal, o Divolte é um excelente serviço para capturar eventos do usuário em uma página da Web via JavaScript.
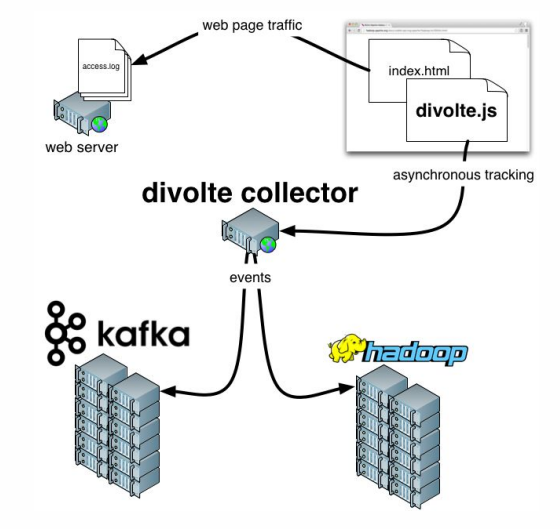
Exemplo prático
O que estamos tentando fazer?
Vamos tentar criar um pipeline para coletar dados do Clickstream em tempo real.
Clickstream é um espaço virtual que um usuário deixa enquanto está no site. Vamos capturar dados usando o Divolte e gravá-los em Kafka.

Você precisa que o Docker funcione, além de clonar o
seguinte repositório . Tudo o que acontece será lançado em contêineres. Para executar consistentemente vários contêineres ao mesmo tempo, o
docker-compose.yml será usado. Além disso, há um
Dockerfile compilando nossos StreamSets com determinadas dependências.
Existem também três pastas:
- os dados da clickhouse serão gravados em clickhouse-data
- exatamente o mesmo pai ( dados sdc ) que teremos para o StreamSets, onde o sistema pode armazenar configurações
- a terceira pasta ( exemplos ) inclui um arquivo de solicitação e um arquivo de configuração de canal para StreamSets

Para iniciar, digite o seguinte comando:
docker-compose up
E gostamos de quão lenta, mas seguramente, os contêineres começam. Após o início, podemos ir para o endereço
http: // localhost: 18630 / e tocar imediatamente em Divolte:

Temos o Divolte, que já recebeu alguns eventos e os gravou em Kafka. Vamos tentar calculá-los usando StreamSets:
http: // localhost: 18630 / (senha / login - admin / admin).

Para não sofrer, é melhor
importar o Pipeline , nomeando-o, por exemplo,
clickstream_pipeline . E da pasta de exemplos importamos
clickstream.json . Se estiver tudo bem,
veremos a seguinte imagem :

Então, criamos uma conexão com o Kafka, registramos qual Kafka precisamos, registramos qual tópico nos interessa, selecionamos os campos que nos interessam e, em seguida, colocamos um dreno em Kafka, registrando qual Kafka e qual tópico. As diferenças são que, em um caso, o formato Data é Avro e, no segundo, é apenas JSON.
Vamos seguir em frente. Podemos, por exemplo,
fazer uma visualização que captura certos registros em tempo real do Kafka. Então escrevemos tudo.
Após o lançamento, veremos que um fluxo de eventos voa para Kafka, e isso acontece em tempo real:

Agora você pode criar um repositório para esses dados no ClickHouse. Para trabalhar com ClickHouse, você pode usar um cliente nativo simples executando o seguinte comando:
docker run -it --rm --network divolte-ss-ch_default yandex/clickhouse-client --host clickhouse
Observe que esta linha indica a rede à qual você deseja se conectar. E, dependendo de como você nomeia a pasta com o repositório, o nome da sua rede pode ser diferente. Em geral, o comando será o seguinte:
docker run -it --rm --network {your_network_name} yandex/clickhouse-client --host clickhouse
A lista de redes pode ser visualizada com o comando:
docker network ls
Bem, não há mais nada:
1.
Primeiro, "assine" nosso ClickHouse para Kafka , "explicando a ele" que formato de dados precisamos lá:
CREATE TABLE IF NOT EXISTS clickstream_topic ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = Kafka SETTINGS kafka_broker_list = 'kafka:9092', kafka_topic_list = 'clickstream', kafka_group_name = 'clickhouse', kafka_format = 'JSONEachRow';
2.
Agora vamos criar uma tabela real onde colocaremos os dados finais:
CREATE TABLE clickstream ( firstInSession UInt8, timestamp UInt64, location String, partyId String, sessionId String, pageViewId String, eventType String, userAgentString String ) ENGINE = ReplacingMergeTree() ORDER BY (timestamp, pageViewId);
3.
E então forneceremos um relacionamento entre essas duas tabelas :
CREATE MATERIALIZED VIEW clickstream_consumer TO clickstream AS SELECT * FROM clickstream_topic;
4.
E agora vamos selecionar os campos necessários :
SELECT * FROM clickstream;
Como resultado, a escolha na tabela de destino nos dará o resultado que precisamos.
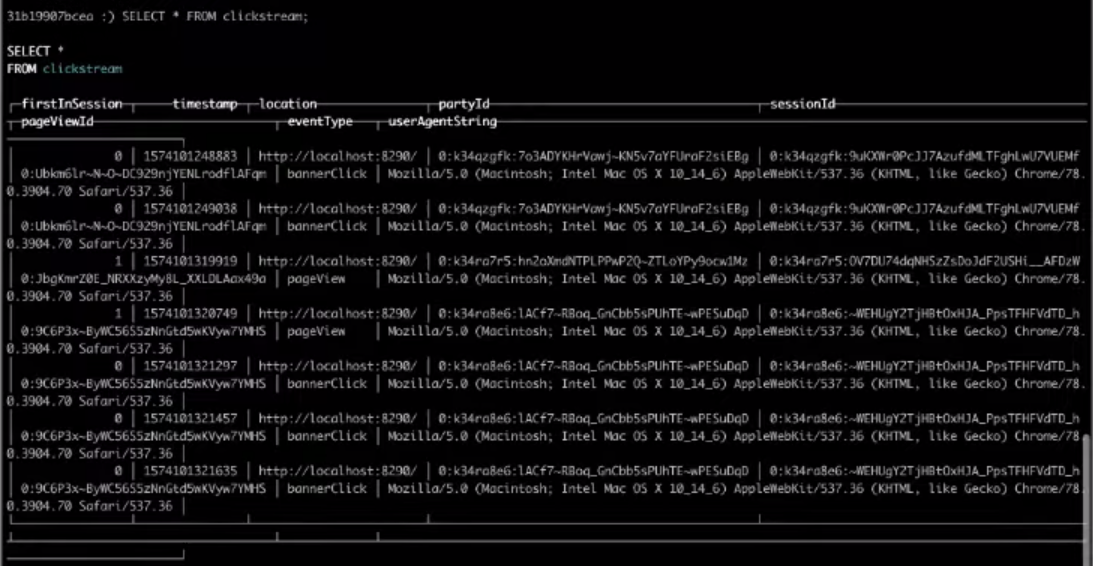
Isso é tudo, foi o Clickstream mais simples que você pode criar. Se você deseja concluir as etapas acima,
assista ao vídeo inteiro.