
A história do aprendizado de máquina começou em meados do século passado. Naquela época, essa tecnologia era mais uma área de pesquisa e experimentos científicos, e computadores poderosos deram um impulso à aplicação prática da ML.
Hoje, o aprendizado de máquina é uma tendência inegável no mercado de TI. Mais e mais empresas de diferentes setores estão criando divisões de ciência de dados para usar o aprendizado de máquina para encontrar novas oportunidades nos dados acumulados para crescimento e melhoria da eficiência dos negócios. No entanto, embora essas iniciativas não dêem o devido retorno. Segundo as estatísticas, 8 em cada 10 casos confirmados não entram em operação comercial.
Provavelmente, muitos de vocês já ouviram a piada "a maneira mais eficaz de tornar o aprendizado de máquina mais produtivo são os slides do PowerPoint". Infelizmente, isso não é uma piada. Muitas vezes, todo o processo se parece com isso: uma empresa transmite dados e um caso de negócios baixado dos sistemas de negócios. Os cientistas de dados estão desenvolvendo um modelo de aprendizado de máquina no Jupiter Notebook, uma captura de tela dos gráficos é colocada em um slide do PowerPoint e enviada ao cliente comercial. É possível usar o slide resultante na tomada de decisões de gerenciamento? Provavelmente não, pois os dados da previsão rapidamente se tornam desatualizados e a situação nos negócios durante esse período pode mudar seriamente.
Tentando superar todos os obstáculos e colocar o aprendizado de máquina em andamento, a maioria das empresas investe na infraestrutura de coleta, armazenamento e processamento de grandes quantidades de dados - Data Lake. Obviamente, este é um passo necessário. Mas o que isso muda da perspectiva dos negócios? É possível tomar decisões com base no aprendizado de máquina? Não, porque existe uma lacuna entre o Data Lake e os negócios. Obviamente, por que 86% das empresas pesquisadas acreditam que os aplicativos de negócios da próxima geração devem estar equipados com aprendizado de máquina.
Na SAP, decidimos escrever uma série de artigos sobre como superar as dificuldades existentes com a nova plataforma SAP Data Intelligence e colocar uma ferramenta tão poderosa como o aprendizado de máquina a serviço dos negócios. E, se você estiver interessado neste tópico, continue lendo :)
Para começar, falarei sobre o primeiro e muito importante estágio no desenvolvimento de qualquer caso comercial "Pesquisa e Preparação de Dados". Nos artigos subsequentes, consideraremos os estágios “Desenvolvimento e treinamento de modelos”, “Integração com fontes de dados locais e em nuvem SAP e não SAP no local”, “Criando serviços para o uso de modelos”, “Transferir casos de negócios para produtivos”, “Monitorando e a operação de casos de negócios ”e muito mais.
Desenvolvimento de um business case baseado em aprendizado de máquina. Pesquisa e preparação de dados.Vejamos o processo de criação de um caso de negócios (Figura 1).
Inicialmente, uma ideia é geralmente formulada por uma empresa. Freqüentemente, ele faz isso de bom grado, pois tem um objetivo definido de digitalizar funções na transformação digital de toda a empresa. Para coletar, avaliar e priorizar idéias, você pode usar, por exemplo, o SAP Innovation Management.
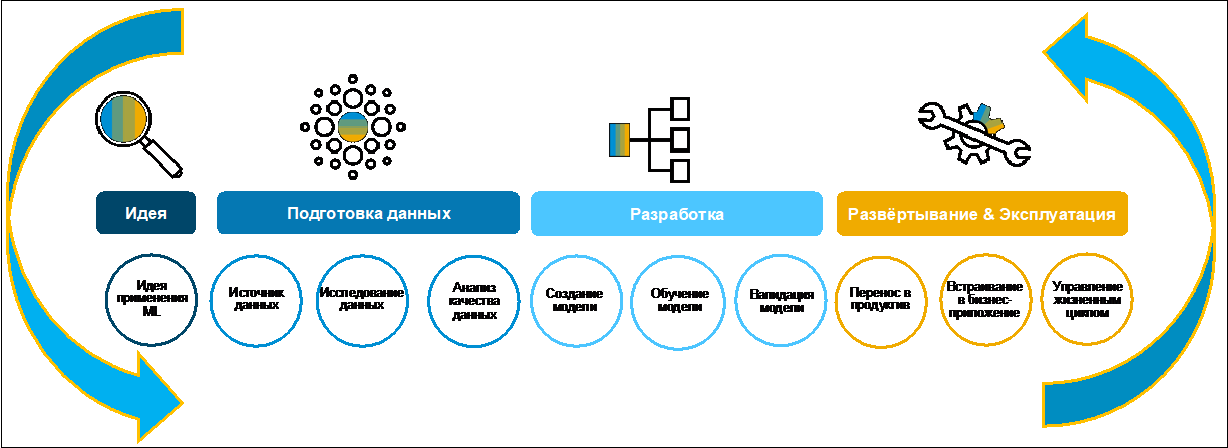 Figura 1
Figura 1No primeiro estágio da pesquisa e preparação dos dados, é necessário entender se eles existem para o desenvolvimento de um caso de negócios, onde estão armazenados, em quais formatos e qual a qualidade deles. A paisagem típica moderna inclui muitos sistemas heterogêneos. Os dados podem ser duplicados em diferentes aplicativos. Encontrar as informações corretas pode levar muito tempo. Para esse fim, no SAP Data Intelligence, essa tarefa foi bastante simplificada usando o Catálogo de Metadados. Vamos ver o que é e como usá-lo.
Catálogo de MetadadosPara usar o catálogo de metadados, você deve conectar o sistema de origem ao Data Intelligence. As fontes de dados para Data Intelligence podem ser sistemas locais SAP ERP, BW, Marketing ... e não SAP MES, Oracle, MS SQL, DB2, Hadoop e muitos outros, além de serviços em nuvem Amazon, Azzure, Google SCP. Para conectar-se a fontes de dados, você precisa de informações sobre a localização dos sistemas e usuários técnicos criados nesses sistemas especificamente para integração com o SAP Data Intelligence. A Figura 2 mostra um exemplo de um cenário de dados personalizado no SAP Data Intelligence.
 Figura 2
Figura 2
Depois de configurado no catálogo de metadados do SAP Data Intelligence, é possível ver as informações armazenadas nos sistemas conectados. A Figura 3 mostra a lista de arquivos localizados na pasta DAT263 no Hadoop, conectada ao SAP Data Intelligence.
 Figura 3
Figura 3Se você encontrar os dados necessários para implementar um caso de negócios, vamos adicionar objetos de dados ao Catálogo usando a função de publicação. Usarei o arquivo autos_history.csv, que contém estatísticas de vendas de carros usados. Na Figura 4, você vê como publicar um objeto de dados e seus metadados no Catálogo para acesso rápido no futuro.
 Figura 4
Figura 4Você pode personalizar a estrutura de diretórios e os níveis de hierarquia de acordo com os requisitos de caso de negócios. Por exemplo, na minha pasta Habr_demo, todos os metadados sobre os objetos que eu preciso para este artigo serão coletados.
O Catálogo de metadados gerado é um acesso rápido aos dados de casos de negócios. Conduzirei o perfil e a análise de sua qualidade nos objetos da minha pasta no catálogo de metadados do SAP Data Intelligence. A tela inicial do catálogo de metadados é mostrada na Fig. 5)
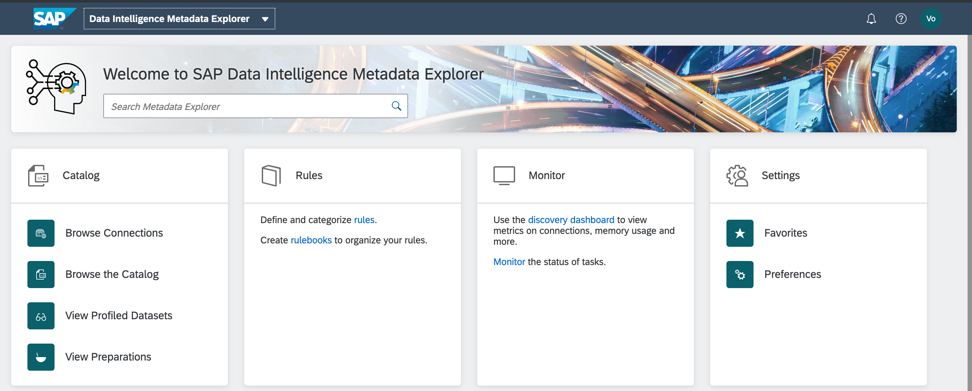 Figura 5
Figura 5E aqui está o próprio objeto de dados que publiquei na pasta Habr_demo (Fig. 6)
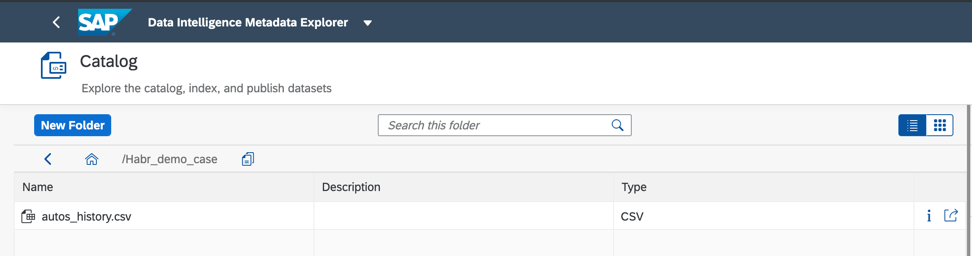 Figura 6
Figura 6Além disso, para melhorar e acelerar a pesquisa, podemos atribuir tags ou rótulos no catálogo de objetos de dados, conforme mostrado na Fig. 7)
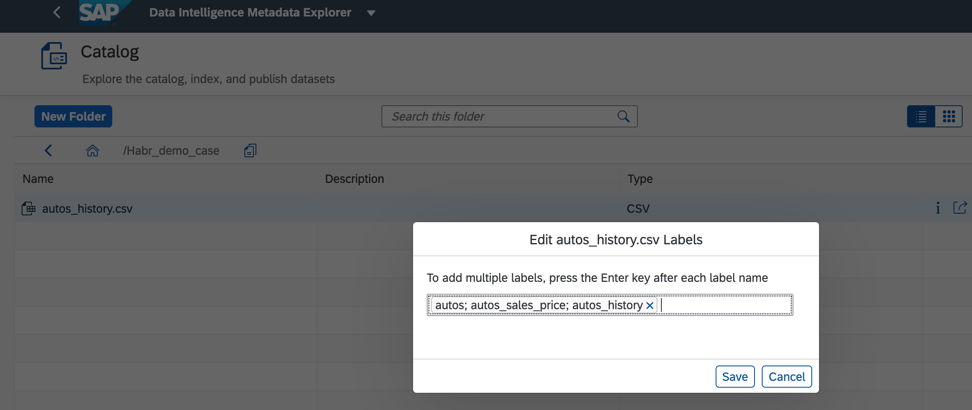 Figura 7
Figura 7O catálogo de metadados permite procurar objetos pelos nomes, campos e também pelo rótulo. Um único objeto de dados pode ter vários rótulos. Isso é conveniente se vários desenvolvedores trabalham com ele, todos podem atribuir um rótulo ao seu caso de negócios e encontrar rapidamente tudo o que você precisa. Além disso, as tags podem destacar dados pessoais e confidenciais, cujo acesso deve ser estritamente limitado.
No conjunto de dados considerado, uma pesquisa por rótulo e por nome de campo fornece um resultado rápido (Fig. 8). Concordo, é muito conveniente!
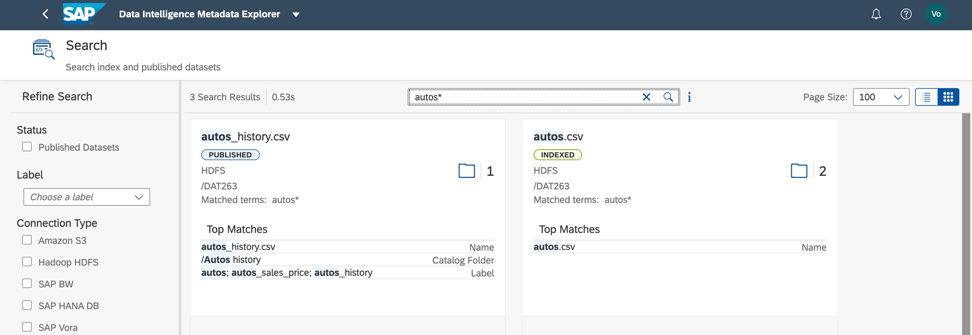 Figura 8
Figura 8Em seguida, precisamos entender como nosso arquivo é preenchido. Para fazer isso, podemos criar um perfil dos dados. Também iniciamos o processo a partir do catálogo de metadados e do menu de contexto para objetos de dados (Fig. 9).
 Figura 9
Figura 9Durante a criação de perfil, o catálogo de metadados lê o conteúdo do arquivo, analisa sua estrutura e preenchimento. O resultado pode ser encontrado na Folha de dados (Fig. 10).
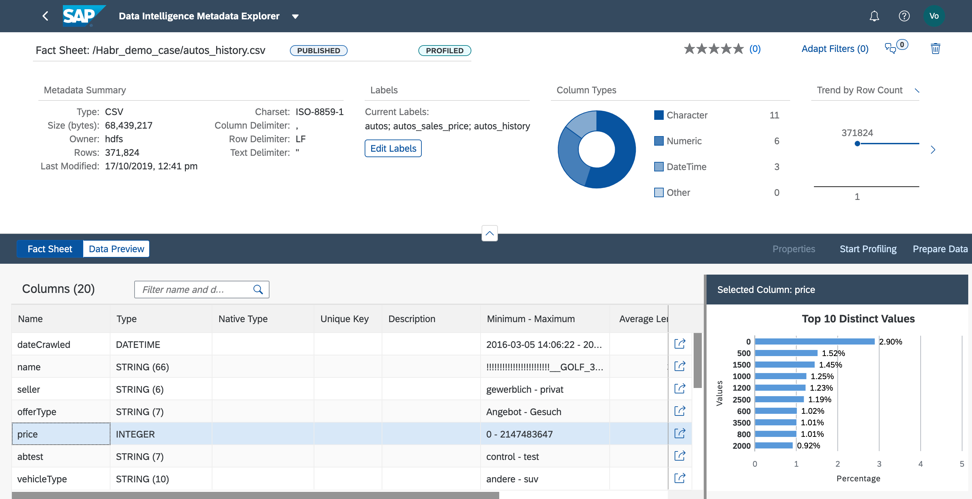 Figura 10
Figura 10
Na ficha técnica, vemos a estrutura do arquivo e informações sobre o preenchimento dos campos.
1. No arquivo selecionado, como resultado da criação de perfil, revelamos: o campo do vendedor possui um valor I em todas as linhas. Isso significa que podemos remover esse campo do conjunto de dados para não usar o aprendizado de máquina ao criar o modelo, pois isso não afetará o resultado da previsão (Fig. 11).
 Figura 11.2.
Figura 11.2. Analisando a coluna de preços, entendemos que quase 3% dos dados que temos contêm preço zero. Para usar esse arquivo em nosso caso de negócios, precisamos preencher o preço com os valores reais ou a média desse produto, ou devemos excluir as linhas com preço zero do arquivo (Fig. 12).
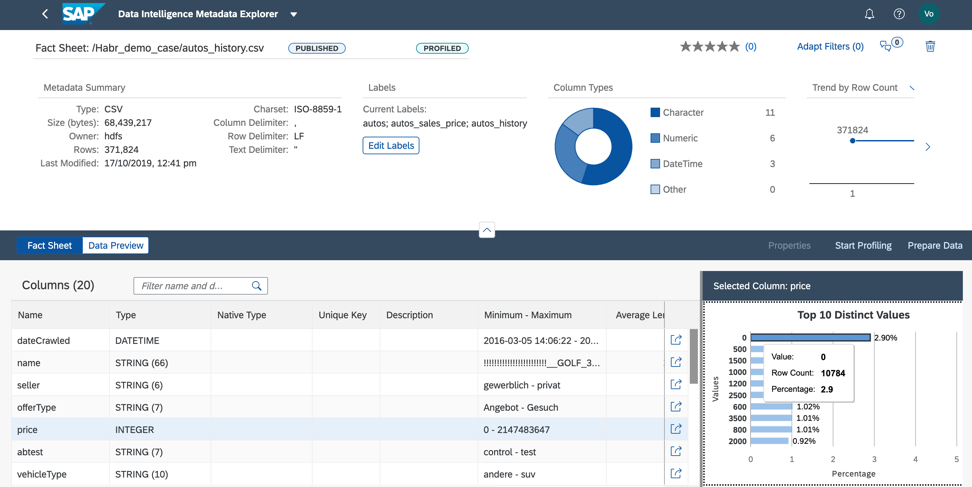 Figura 12.
Figura 12.Podemos realizar o pré-processamento de dados de duas maneiras: no Catálogo de metadados ou diretamente no Bloco de anotações Jupiter. A escolha da ferramenta depende de quem é responsável pelo pré-processamento de dados para o caso de negócios. Se um analista, recomendo usar a interface de preparação de dados visuais, disponível no Catálogo de Metadados. Se um cientista de dados estiver envolvido na preparação dos dados, a escolha deve ser definitivamente a favor do Jupiter Notebook, que também é integrado ao Data Intelligence.
3. O valor do campo do modelo está bem distribuído, o que nos permitirá treinar qualitativamente o modelo, como na Figura 13.
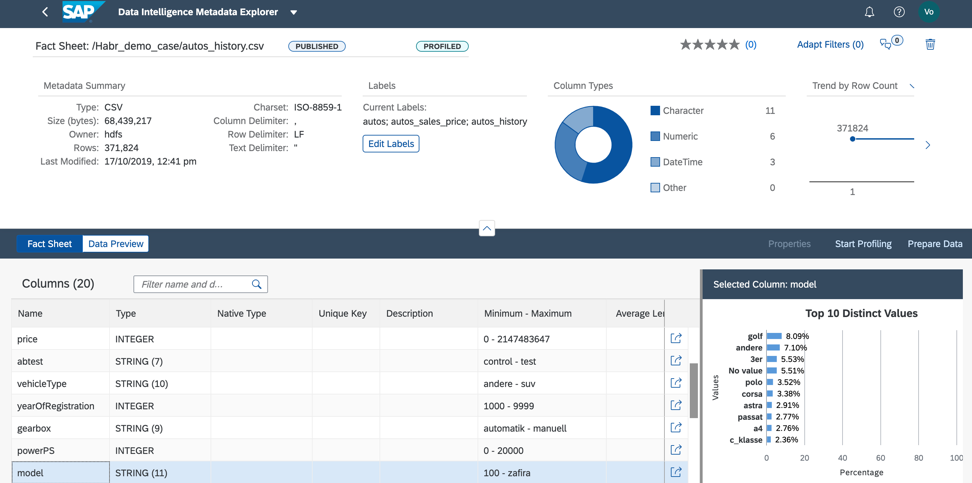 Figura 13.
Figura 13.
Agora entendemos quais objetos de dados são necessários para implementar um caso de negócios, quais objetos de dados são preenchidos, que pré-processamento devemos fazer para usar esses dados para implementar, treinar e testar o modelo. Mas antes de iniciar o pré-processamento, você precisa verificar a qualidade dos dados. Para isso, as regras de negócios estão disponíveis no Catálogo de Metadados. Percebo imediatamente que, no momento, a funcionalidade das regras de negócios tem várias limitações sérias. Portanto, recomendo um pré-processamento de dados mais ou menos complicado no Jupiter Notebook, integrado ao SAP Data Intelligence.
Então, vamos voltar ao nosso conjunto de dados e verificar a conformidade com os limites mínimo e máximo no campo preço, para que possamos estimar aproximadamente se os dados têm anomalias ou valores incorretos. Como você já entendeu, as regras de negócios também são configuradas no Catálogo de Metadados, como na Fig. 14a, c. O relacionamento de regras e dados é configurado no livro de regras (livro de regras). Isso permite que você use as mesmas regras para verificar dados diferentes.
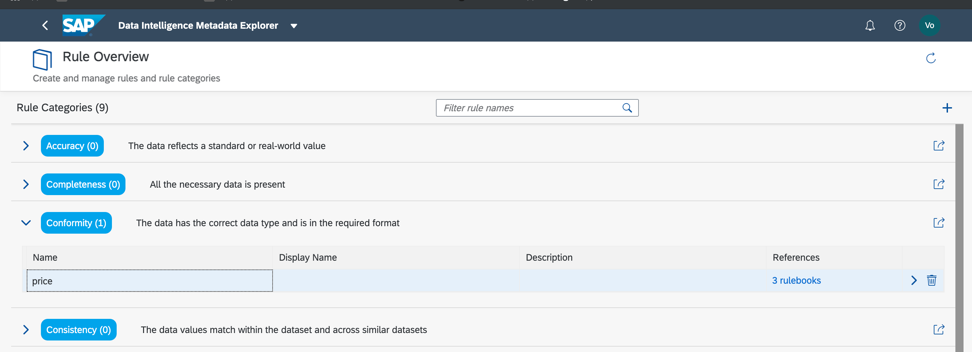 Figura 14 a.
Figura 14 a.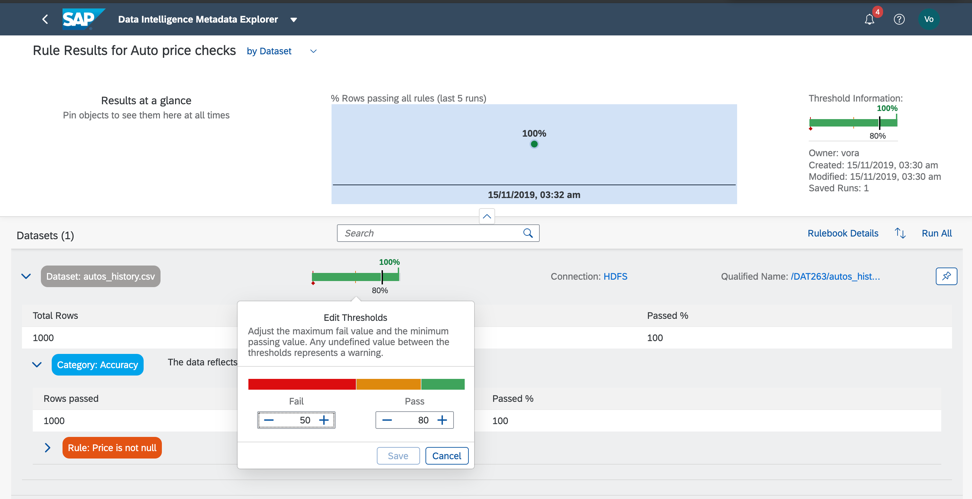 Figura 14 c.
Figura 14 c.Portanto, como vemos, nossos dados estão 100% corretos.
Mas isso nem sempre acontece. Os dados podem ser considerados corretos se 75% dos registros atenderem às condições especificadas nas regras.
É possível melhorar a qualidade dos dados e, acima de tudo, isso é feito nos sistemas contábeis. Para isso, as empresas organizam o processo de gerenciamento de dados. Outro motivo possível é o critério de qualidade dos dados definido incorretamente.
Resumindo, quero dizer sobre as vantagens e desvantagens do Catálogo de Metadados.
Na minha opinião, tem 3 vantagens principais:
- Simplifique o acesso a dados.
- Acelerando a recuperação de dados.
- Interface conveniente e intuitiva, destinada não apenas aos especialistas avançados em TI ou Ciência de Dados, mas também aos negócios envolvidos na implementação e suporte adicional do business case.
E, é claro, sobre as falhas. Eles são óbvios. Atualmente, a funcionalidade do catálogo de metadados no SAP Data Intelligence está em um nível básico. Pode ser suficiente começar a usar, mas a funcionalidade não cobre exatamente todos os requisitos para uma solução de gerenciamento de dados.
E isso é uma consequência da novidade e complexidade do SAP Data Intelligence. A SAP investe muitos recursos para melhorar esta solução. E isso inspira confiança de que, no futuro próximo, o Catálogo de Metadados se tornará uma ferramenta poderosa para o gerenciamento de dados. Haverá uma oportunidade de criar regras comerciais complexas sem programação. Também será possível integrar o SAP Information Steward e o SAP Data Hub com o objetivo de cobertura totalmente funcional do tópico de gerenciamento de dados.
No próximo artigo, falaremos sobre a fase "Desenvolvimento e treinamento de um modelo no SAP Data Intelligence". Tudo o mais interessante pela frente!
Postado por Elena Ganchenko, especialista em SAP CIS