Quando você confia em alguém a coisa mais preciosa que você tem - os dados do seu aplicativo ou serviço - você quer imaginar como esse alguém lidará com o seu maior valor.
Meu nome é Vladimir Borodin, sou o chefe da plataforma de dados Yandex.Cloud. Hoje, quero contar como tudo está organizado e funciona nos serviços do Yandex Managed Databases, por que tudo é feito dessa maneira e quais são as vantagens - do ponto de vista dos usuários - de nossas várias soluções. E, é claro, você definitivamente descobrirá o que planejamos finalizar no futuro próximo, para que o serviço se torne melhor e mais conveniente para todos que precisam.
Bem, vamos lá!

Bancos de dados gerenciados (bancos de dados gerenciados Yandex) é um dos serviços Yandex.Cloud mais populares. Mais precisamente, este é um grupo inteiro de serviços, que agora perde apenas para as máquinas virtuais Yandex Compute Cloud em popularidade.
O Yandex Managed Databases permite obter rapidamente um banco de dados funcional e executa essas tarefas:
- Dimensionamento - da capacidade elementar de adicionar recursos de computação ou espaço em disco a um aumento no número de réplicas e shards.
- Instale atualizações, menores e maiores.
- Backup e restauração.
- Fornecendo tolerância a falhas.
- Monitoramento
- Fornecendo ferramentas convenientes de configuração e gerenciamento.
Como os serviços de banco de dados gerenciados são organizados: vista superior
O serviço consiste em duas partes principais: plano de controle e plano de dados. O Control Plane é, simplesmente, uma API de gerenciamento de banco de dados que permite criar, modificar ou excluir bancos de dados. Data Plane é o nível de armazenamento direto de dados.
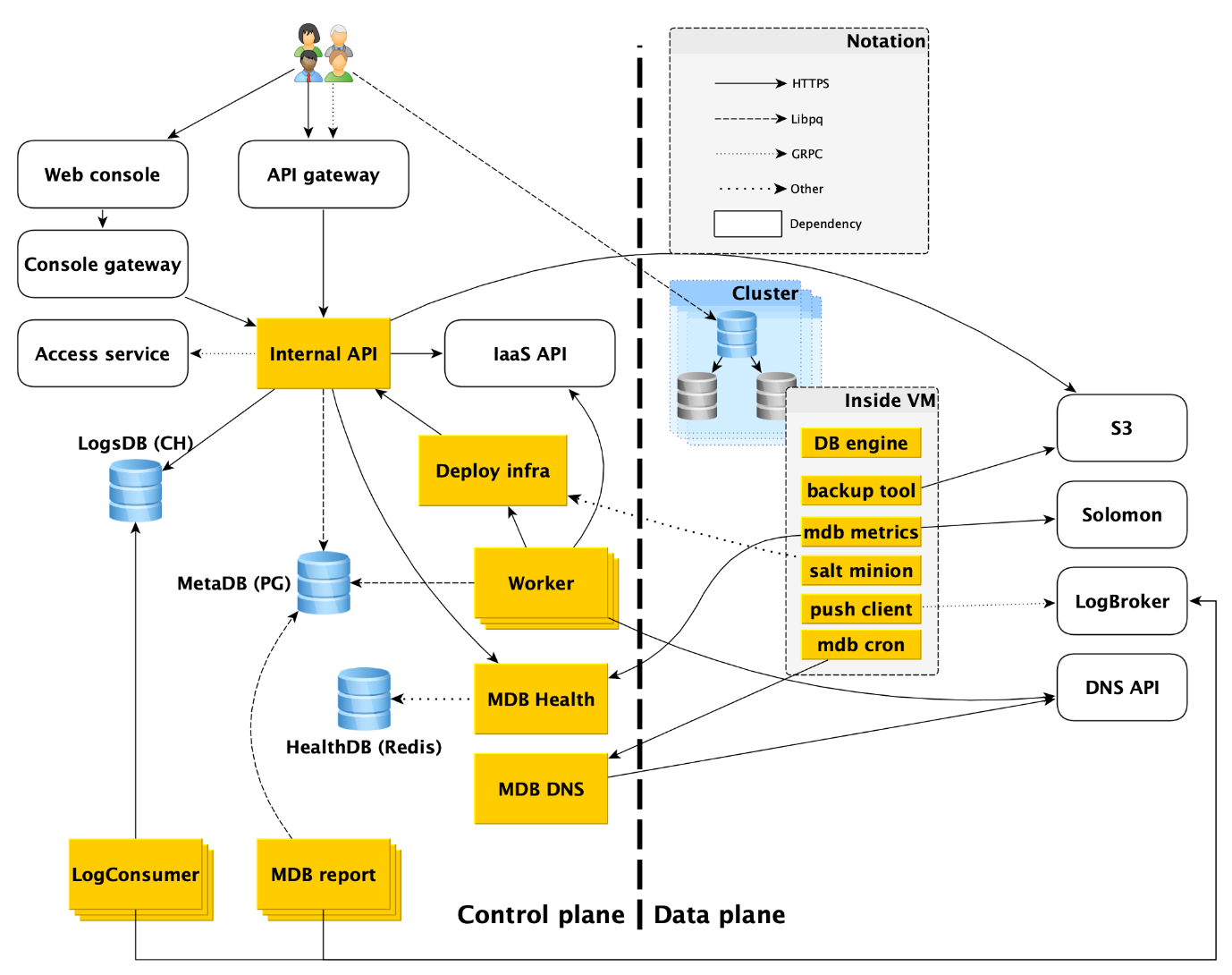
Os usuários do serviço têm, de fato, dois pontos de entrada:
- No plano de controle. De fato, existem muitas entradas - o console da Web, o utilitário CLI e a API do gateway que fornece a API pública (gRPC e REST). Mas todos eles acabam indo para o que chamamos de API interna e, portanto, consideraremos esse ponto de entrada no Plano de controle. De fato, esse é o ponto em que a área de responsabilidade de serviço do Managed Databases (MDB) começa.
- No plano de dados. Esta é uma conexão direta com um banco de dados em execução através de protocolos de acesso ao DBMS. Se for, por exemplo, PostgreSQL, será a interface libpq .
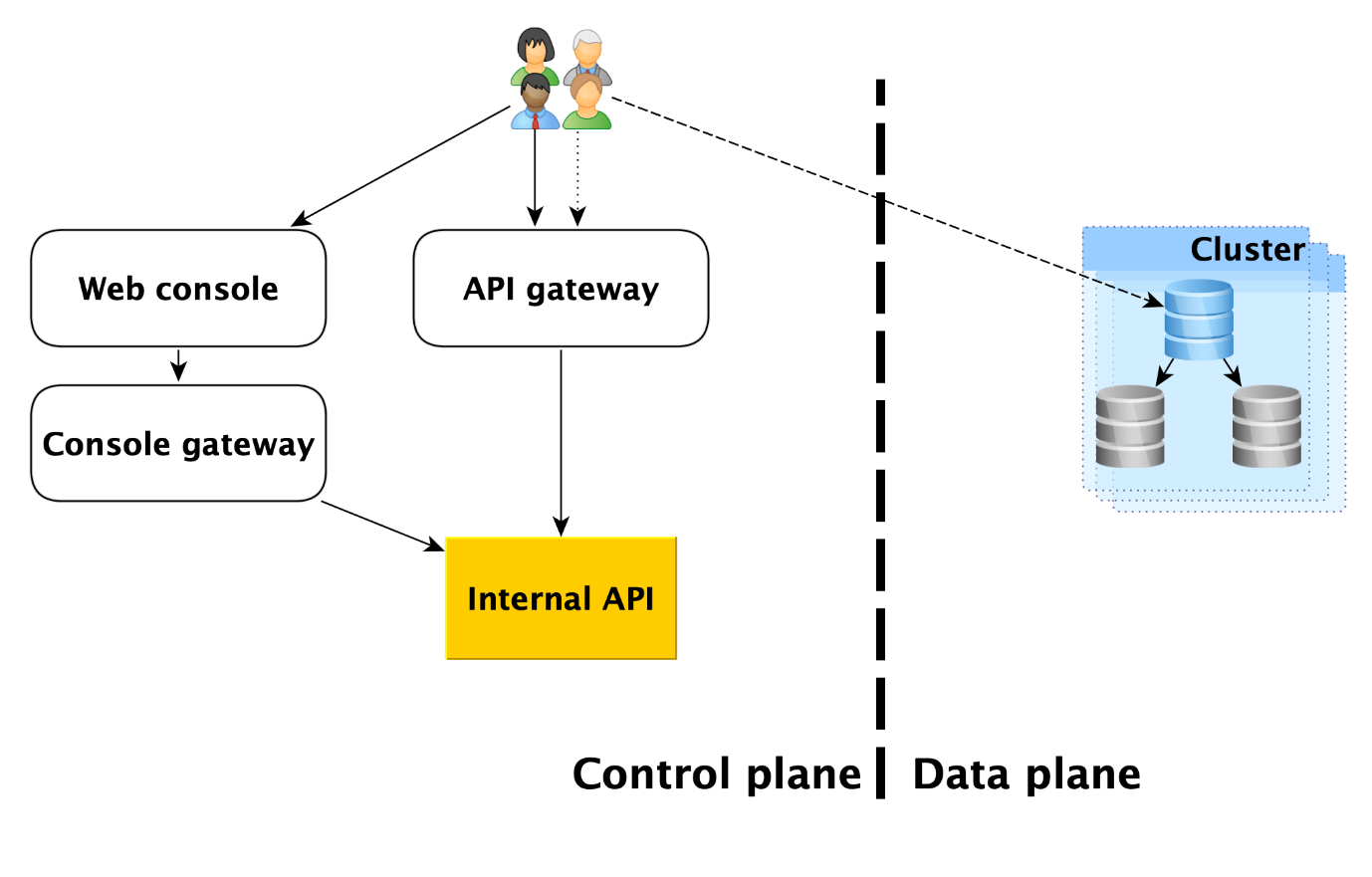
Abaixo, descreveremos com mais detalhes tudo o que acontece no Plano de Dados e analisaremos cada um dos componentes do Plano de Controle.
Plano de dados
Antes de analisar os componentes do plano de controle, vamos dar uma olhada no que está acontecendo no plano de dados.
Dentro de uma máquina virtual
O MDB executa bancos de dados nas mesmas máquinas virtuais fornecidas no
Yandex Compute Cloud .
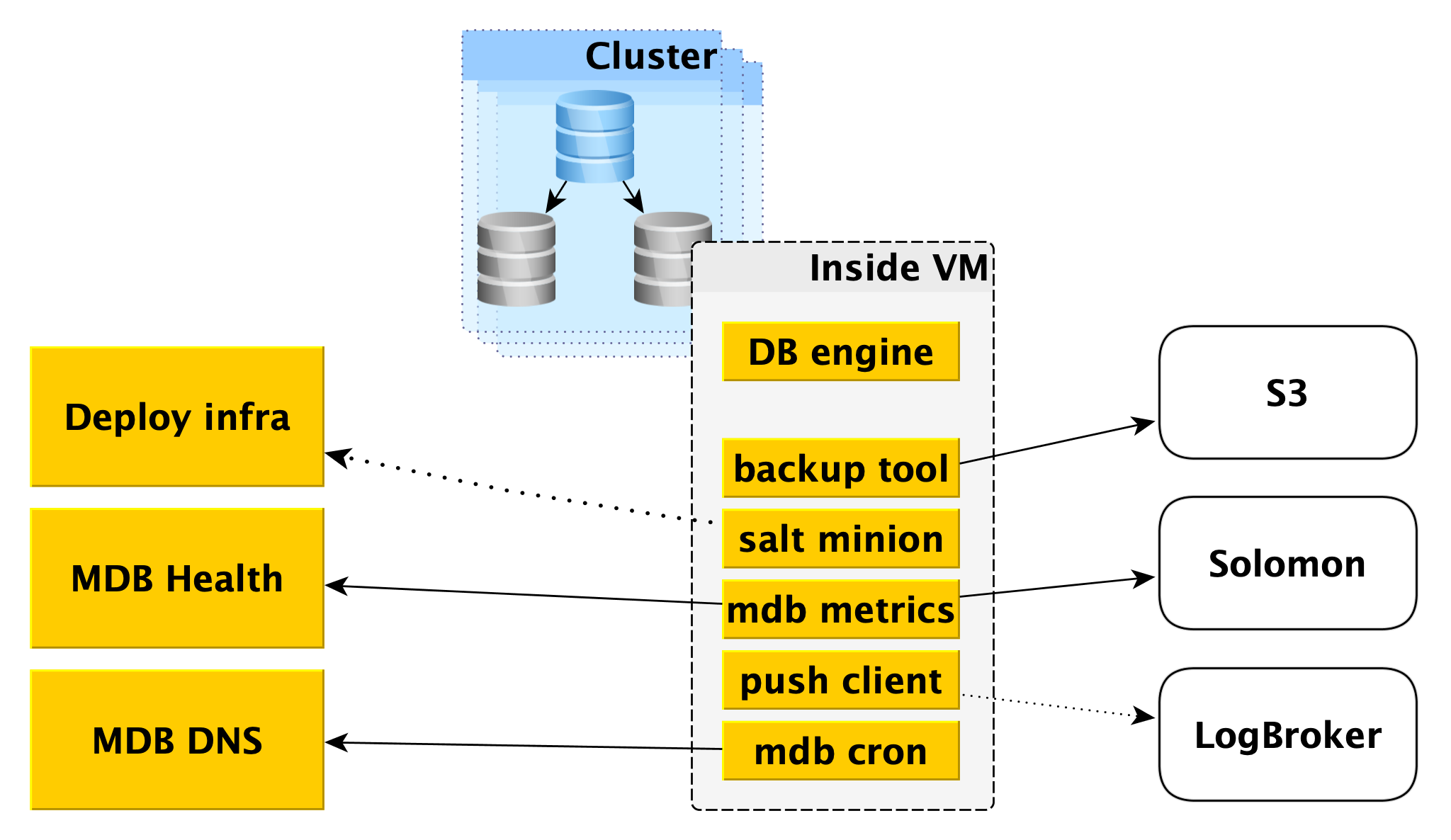
Primeiro, um mecanismo de banco de dados, por exemplo, PostgreSQL, é implantado lá. Paralelamente, vários programas auxiliares podem ser lançados. Para o PostgreSQL, será o
Odyssey , o extrator de conexão com o banco de dados.
Também dentro da máquina virtual, um determinado conjunto de serviços padrão é iniciado, próprio para cada DBMS:
- Serviço para criar backups. Para o PostgreSQL, é uma ferramenta WAL-G de código aberto . Ele cria backups e os armazena no Yandex Object Storage .
- O Salt Minion é um componente do sistema SaltStack para gerenciamento de operações e configurações. Mais informações sobre isso são fornecidas abaixo na descrição da infraestrutura Deploy.
- Métricas do MDB, responsáveis por transmitir as métricas do banco de dados ao Yandex Monitoring e ao nosso microsserviço para monitorar o status dos clusters e hosts do MDB Health.
- O cliente push, que envia logs de DBMS e de cobrança ao serviço Logbroker, é uma solução especial para coletar e entregar dados.
- MDB cron - nossa bicicleta, que difere do cron habitual na capacidade de executar tarefas periódicas com precisão de um segundo.
Topologia de rede
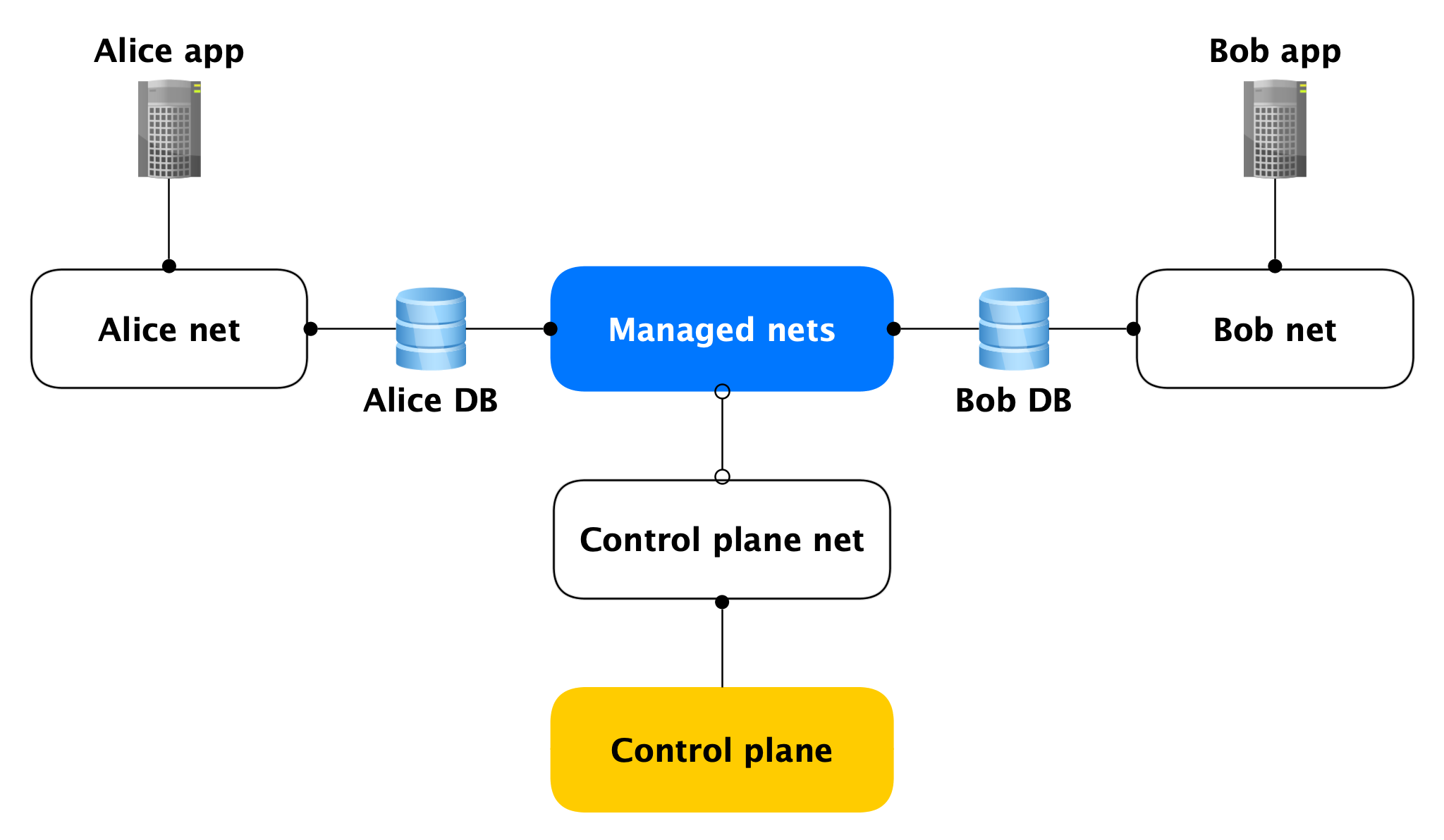
Cada host do Data Plane possui duas interfaces de rede:
- Um deles adere à rede do usuário. Em geral, é necessário atender à carga do produto. Por meio dele, a replicação está perseguindo.
- O segundo fica em uma de nossas redes gerenciadas através da qual os hosts acessam o Control Plane.
Sim, hosts de clientes diferentes estão presos em uma dessas redes gerenciadas, mas isso não é assustador, porque na interface gerenciada (quase) nada está escutando, as conexões de rede de saída no Control Plane são abertas apenas a partir dela. Quase ninguém, porque há portas abertas (por exemplo, SSH), mas elas são fechadas por um firewall local que permite apenas conexões de hosts específicos. Assim, se um invasor obtém acesso a uma máquina virtual com um banco de dados, ele não pode acessar os bancos de dados de outras pessoas.
Segurança do plano de dados
Como estamos falando de segurança, deve-se dizer que inicialmente projetamos o serviço com base no invasor obtendo root na máquina virtual do cluster.
No final, nos esforçamos muito para fazer o seguinte:
- Firewall local e grande;
- Criptografia de todas as conexões e backups;
- Tudo com autenticação e autorização;
- AppArmor
- IDS auto-escrito.
Agora considere os componentes do plano de controle.
Plano de controle
API interna
A API interna é o primeiro ponto de entrada no plano de controle. Vamos ver como tudo funciona aqui.
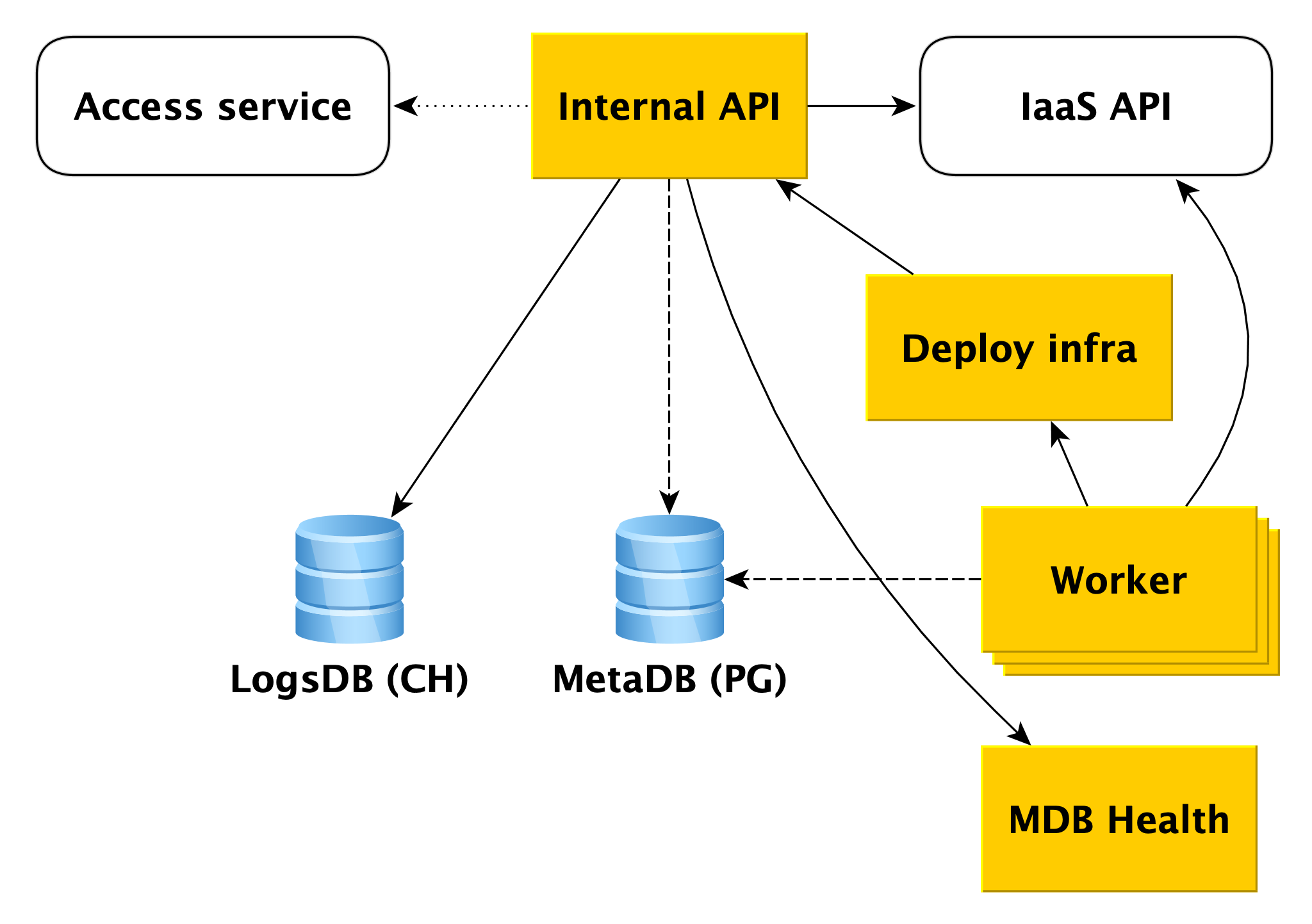
Suponha que a API interna receba uma solicitação para criar um cluster de banco de dados.
Primeiro, a API interna acessa o serviço de acesso à nuvem, que é responsável por verificar a autenticação e autorização do usuário. Se o usuário passar na verificação, a API interna verificará a validade da solicitação em si. Por exemplo, uma solicitação para criar um cluster sem especificar seu nome ou com um nome já utilizado falhará no teste.
E a API interna pode enviar solicitações para a API de outros serviços. Se você deseja criar um cluster em uma determinada rede A e um host específico em uma sub-rede específica B, a API interna deve garantir que você tenha direitos para a rede A e a sub-rede especificada B. Ao mesmo tempo, verificará se a sub-rede B pertence à rede A Isso requer acesso à API de infraestrutura.
Se a solicitação for válida, as informações sobre o cluster criado serão salvas na metabase. Nós o chamamos de MetaDB, é implantado no PostgreSQL. O MetaDB possui uma tabela com uma fila de operações. A API interna salva informações sobre a operação e define a tarefa de maneira transacional. Depois disso, as informações sobre a operação são retornadas ao usuário.
Em geral, para processar a maioria das solicitações da API Interna, basta usar o MetaDB e a API de serviços relacionados. Mas há mais dois componentes que a API interna utiliza para responder a algumas consultas - LogsDB, onde estão localizados os logs do cluster de usuários, e MDB Health. Sobre cada um deles será descrito em mais detalhes abaixo.
Trabalhador
Trabalhadores são simplesmente um conjunto de processos que consultam a fila de operações no MetaDB, as agarram e as executam.
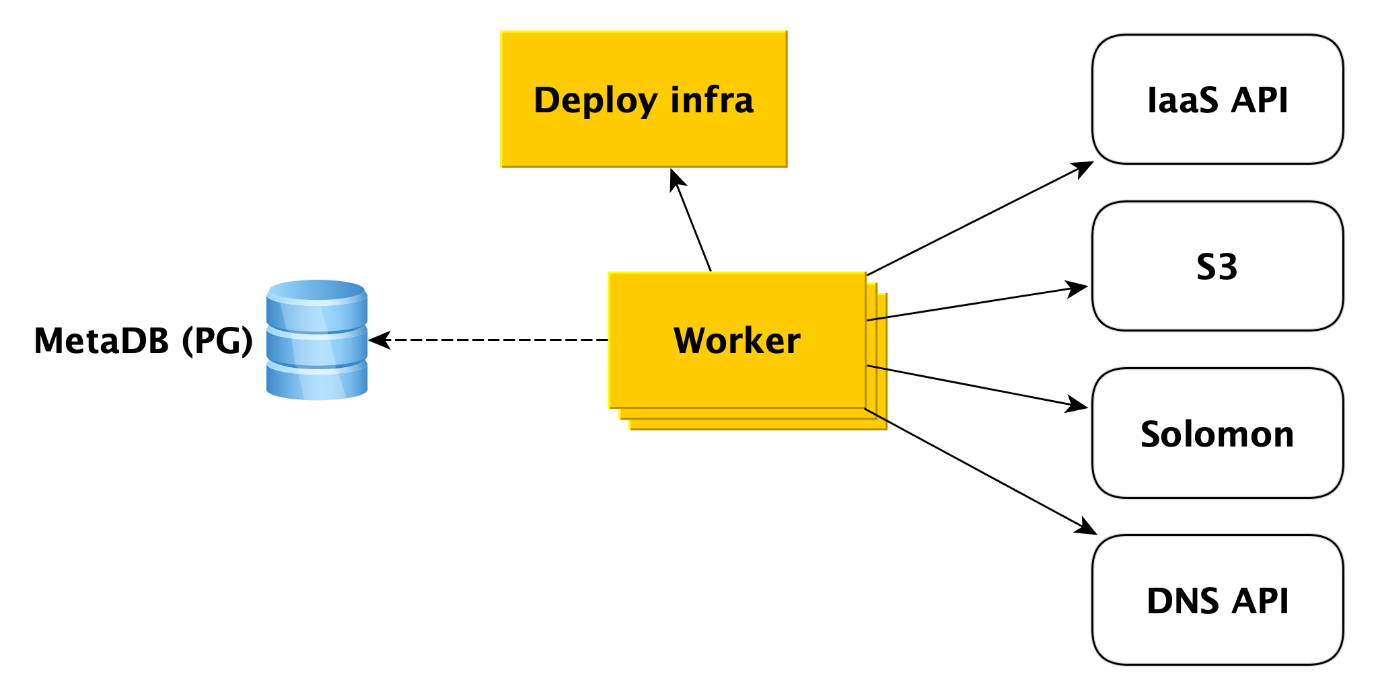
O que exatamente um trabalhador faz quando um cluster é criado? Primeiro, ele recorre à API de infraestrutura para criar máquinas virtuais a partir de nossas imagens (elas já possuem todos os pacotes necessários instalados e quase tudo está configurado, as imagens são atualizadas uma vez por dia). Quando as máquinas virtuais são criadas e a rede decola nelas, o trabalhador recorre à infra-estrutura Deploy (falaremos mais sobre isso mais adiante) para implantar o que o usuário precisa nas máquinas virtuais.
Além disso, o trabalhador acessa outros serviços em nuvem. Por exemplo, no
Yandex Object Storage para criar um bucket no qual os backups de cluster serão salvos. Para o serviço de
Monitoramento Yandex , que coletará e visualizará as métricas do banco de dados. O trabalhador deve criar lá as meta-informações do cluster. Para a API DNS, se o usuário desejar atribuir endereços IP públicos aos hosts do cluster.
Em geral, o trabalhador trabalha de maneira muito simples. Ele recebe a tarefa da fila da metabase e acessa o serviço desejado. Após concluir cada etapa, o trabalhador armazena informações sobre o andamento da operação na metabase. Se ocorrer uma falha, a tarefa simplesmente reiniciará e será executada de onde parou. Mas nem mesmo reiniciá-lo desde o início não é um problema, porque quase todos os tipos de tarefas para trabalhadores são gravados de maneira idempotente. Isso ocorre porque o trabalhador pode executar uma ou outra etapa da operação, mas não há informações sobre isso no MetaDB.
Implantar infraestrutura
No fundo, está o
SaltStack , um sistema de gerenciamento de configuração de código aberto bastante comum, escrito em Python. O sistema é muito
expansível , pelo qual nós o amamos.
Os principais componentes do salt são salt master, que armazena informações sobre o que deve ser aplicado e onde e o salt minion, um agente que está instalado em cada host, interage com o mestre e pode aplicar diretamente o sal do mestre de sal ao host. Para os fins deste artigo, possuímos conhecimento suficiente e você pode ler mais na
documentação do
SaltStack .
Um mestre de sal não é tolerante a falhas e não escala para milhares de lacaios, são necessários vários mestres. Interagir com isso diretamente do trabalhador é inconveniente, e escrevemos nossas ligações no Salt, que chamamos de estrutura Deploy.
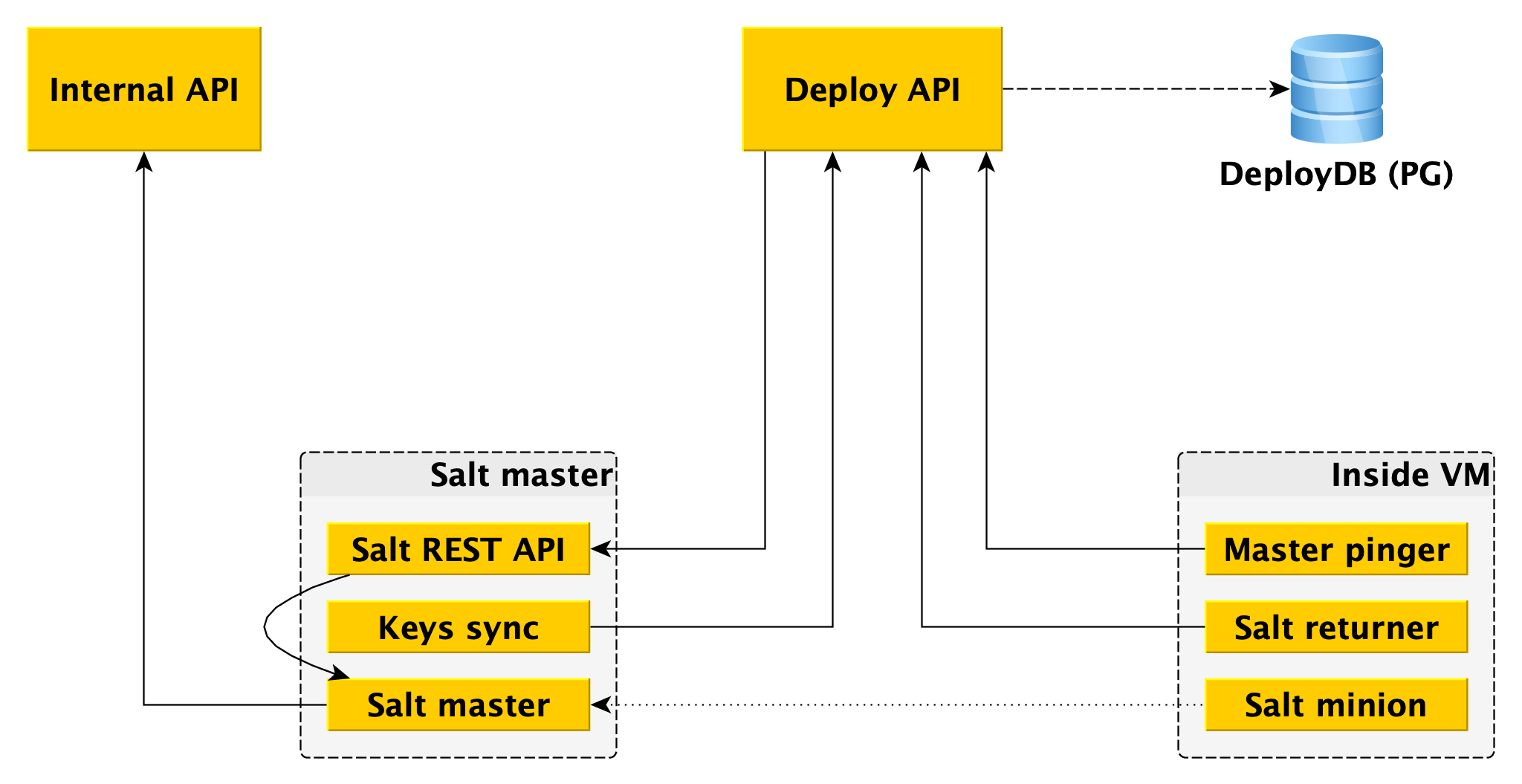
Para o trabalhador, o único ponto de entrada é a API Deploy, que implementa métodos como "Aplicar o estado inteiro ou suas partes individuais a esses subordinados" e "Informar o status de tal e qual implementação". A API de implantação armazena informações sobre todos os lançamentos e suas etapas específicas no DeployDB, onde também usamos o PostgreSQL. Informações sobre todos os subordinados e mestres e sobre a pertença do primeiro ao segundo também são armazenadas lá.
Dois componentes adicionais são instalados nos mestres de sal:
- API REST Salt , com a qual a API de Implantação interage para iniciar lançamentos. A API REST vai para o salt-master local e ele já se comunica com minions usando o ZeroMQ.
- A essência é que ele vai para a API Deploy e recebe as chaves públicas de todos os minions que devem estar conectados a este salt-master. Sem uma chave pública no mestre, o lacaio simplesmente não pode se conectar ao mestre.
Além do salt minion, dois componentes também são instalados no Data Plane:
- Returner - um módulo (uma das partes extensíveis do salt), que traz o resultado da implantação não apenas para o salt master, mas também na API Deploy. A API de implantação inicia a implantação acessando a API REST no assistente e recebe o resultado através do retornador do minion.
- Pinger mestre, que pesquisa periodicamente a API de Implantação à qual os subordinados principais devem estar conectados. Se a API de Implementação retornar um novo endereço do assistente (por exemplo, porque o antigo está morto ou sobrecarregado), o pinger reconfigura o lacaio.
Outro local em que usamos a extensibilidade do SaltStack é
ext_pillar - a capacidade de obter
pilares de algum lugar externo (algumas informações estáticas, por exemplo, a configuração do PostgreSQL, usuários, bancos de dados, extensões etc.). Vamos para a API interna do nosso módulo para obter configurações específicas do cluster, pois elas são armazenadas no MetaDB.
Separadamente, observe que o pilar também contém informações confidenciais (senhas de usuários, certificados TLS, chaves GPG para criptografar backups) e, portanto, primeiro, toda a interação entre todos os componentes é criptografada (não em nenhum de nossos bancos de dados sem TLS, HTTPS em todos os lugares, o minion e o mestre também criptografam todo o tráfego). Em segundo lugar, todos esses segredos são criptografados no MetaDB, e usamos a separação de segredos - nas máquinas da API interna, há uma chave pública que criptografa todos os segredos antes de serem armazenados no MetaDB, e a parte privada fica em mestres de sal e somente eles podem obter segredos abertos para a transferência como pilar para um lacaio (novamente por meio de um canal criptografado).
MDB Health
Ao trabalhar com bancos de dados, é útil conhecer seu status. Para isso, temos o microsserviço MDB Health. Ele recebe informações de status do host do componente interno dos MDBs da máquina virtual MDB e as armazena em seu próprio banco de dados (nesse caso, Redis). E quando chega uma solicitação sobre o status de um cluster específico na API interna, a API interna usa dados do MetaDB e MDB Health.
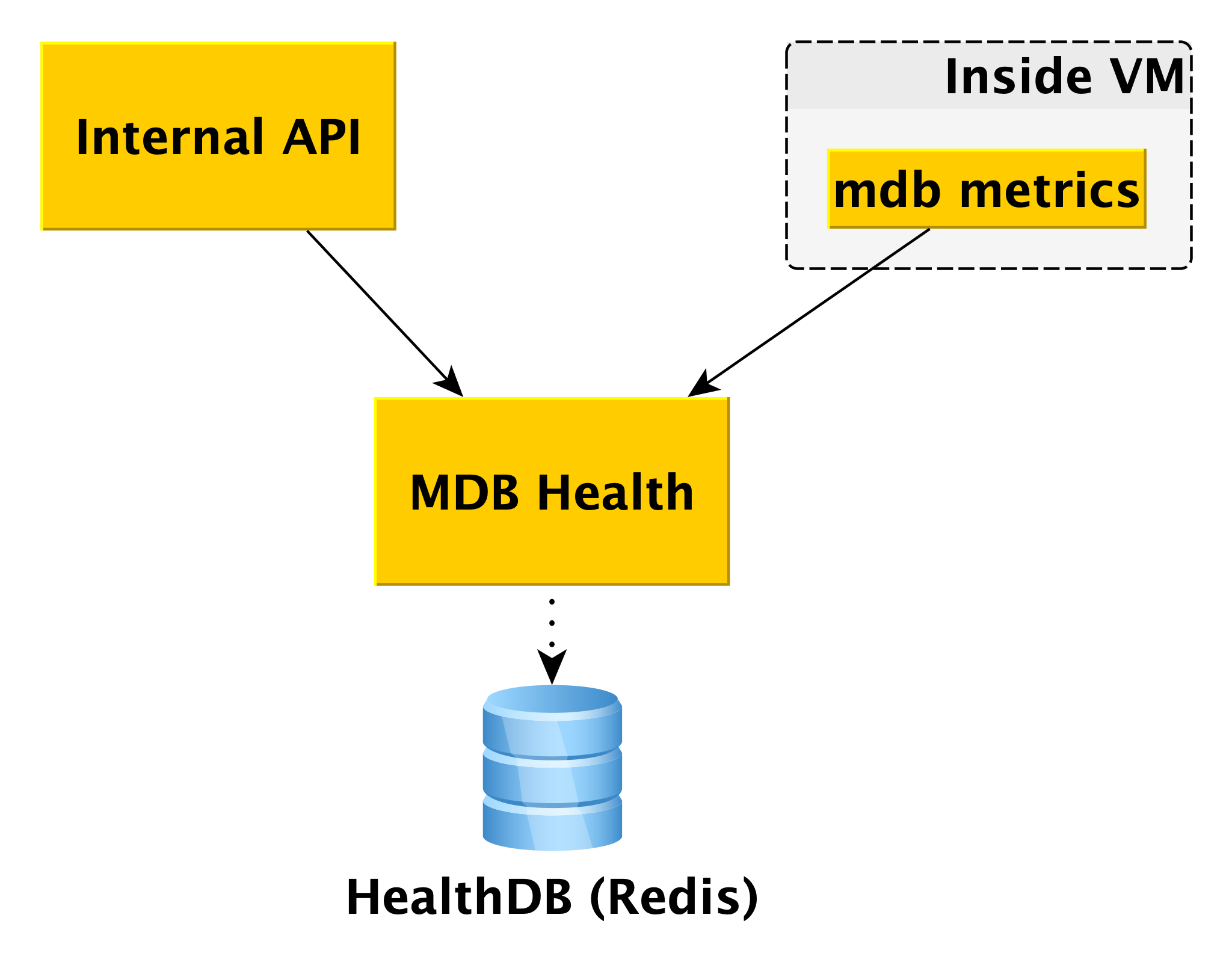
As informações sobre todos os hosts são processadas e apresentadas de forma compreensível na API. Além do estado de hosts e clusters para alguns DBMSs, o MDB Health também retorna se um host específico é um mestre ou uma réplica.
DNS MDB
O microsserviço DNS do MDB é necessário para gerenciar registros CNAME. Se o driver para conectar-se ao banco de dados não permitir a transferência de vários hosts na cadeia de conexão, você poderá conectar-se a um
CNAME especial, que sempre indica o mestre atual no cluster. Se o mestre mudar, o CNAME será alterado.
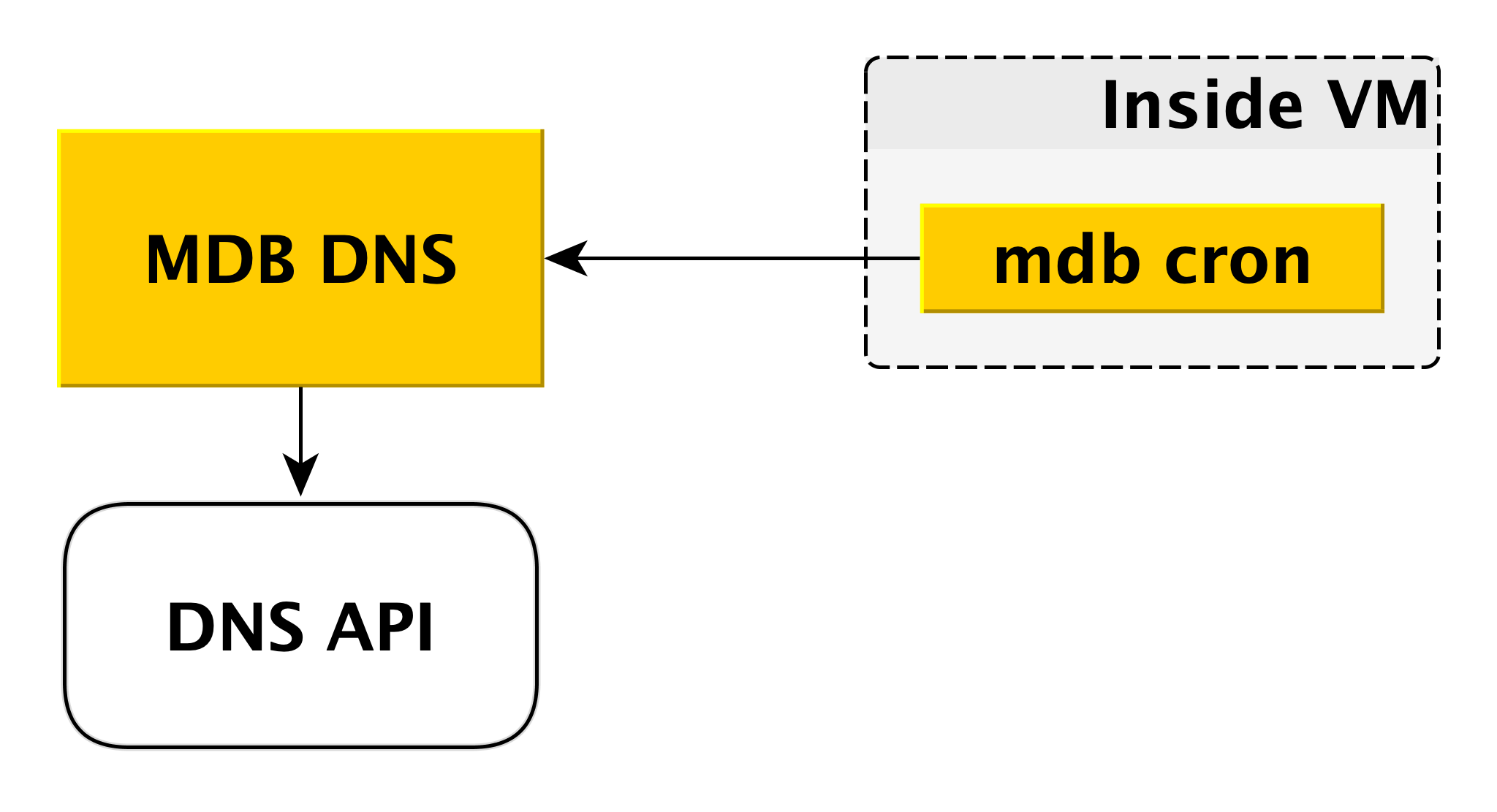
Como está indo isso? Como dissemos acima, dentro da máquina virtual há um cron MDB, que envia periodicamente uma pulsação do seguinte conteúdo para o DNS do MDB: "Nesse cluster, o registro CNAME deve apontar para mim". O DNS do MDB aceita essas mensagens de todas as máquinas virtuais e decide se deseja alterar os registros CNAME. Se necessário, ele altera o registro pela API DNS.
Por que fizemos um serviço separado para isso? Porque a API DNS tem controle de acesso apenas no nível da zona. Um invasor em potencial, obtendo acesso a uma máquina virtual separada, pode alterar os registros CNAME de outros usuários. O DNS do MDB exclui esse cenário porque verifica a autorização.
Entrega e exibição de logs do banco de dados
Quando o banco de dados na máquina virtual grava no log, o componente cliente push especial lê esse registro e envia a linha que acabou de aparecer para o Logbroker (
eles já escreveram sobre ele no Habré). A interação do cliente push com o LogBroker é construída com a semântica exata: nós definitivamente o enviaremos e garantiremos estritamente uma vez.
Um conjunto separado de máquinas - LogConsumers - pega os logs da fila do LogBroker e os armazena no banco de dados do LogsDB. O DBMS do ClickHouse é usado para o banco de dados de log.
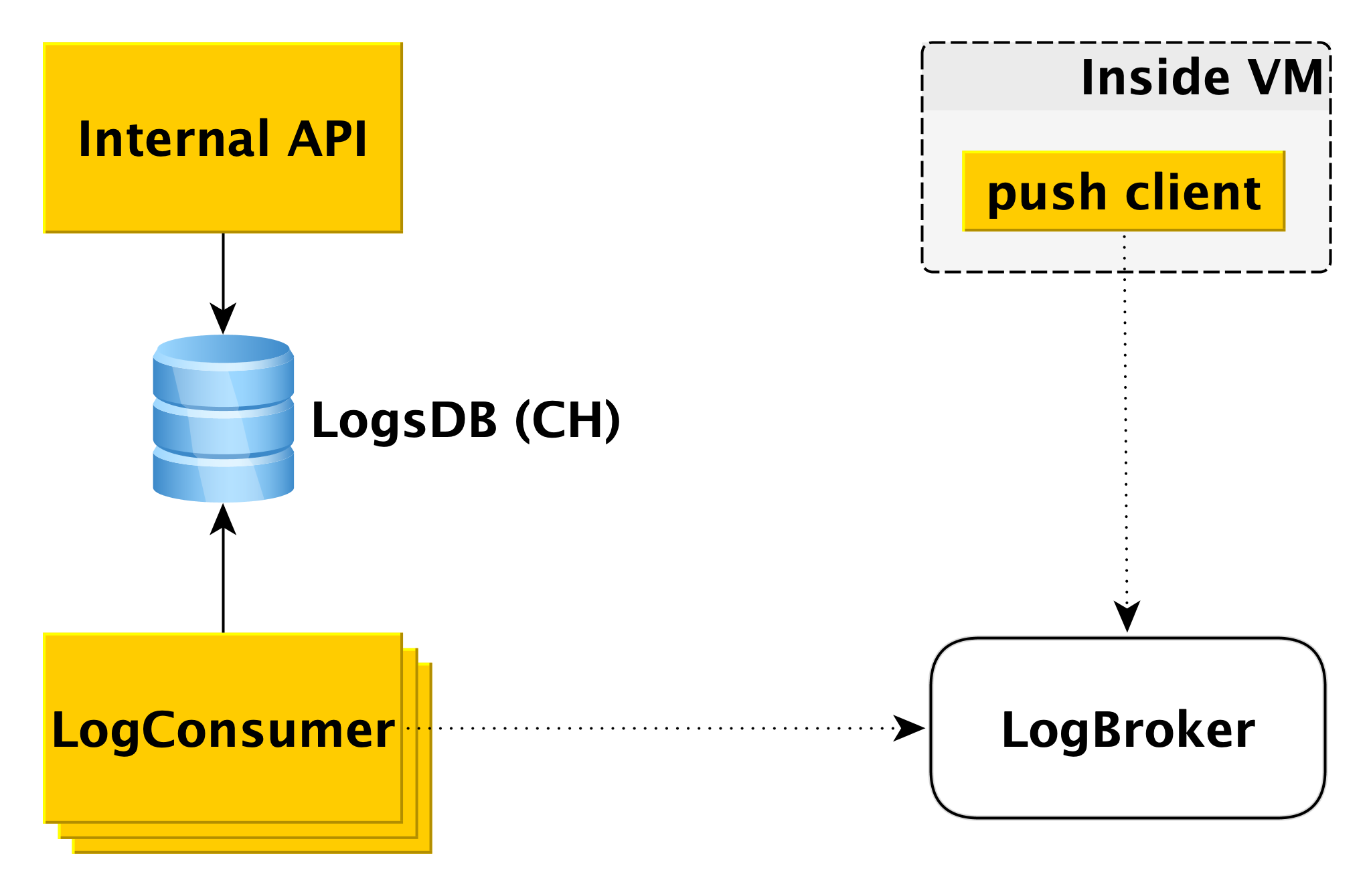
Quando uma solicitação é enviada à API Interna para exibir logs por um intervalo de tempo específico para um cluster específico, a API Interna verifica a autorização e envia a solicitação ao LogsDB. Portanto, o loop de entrega de log é completamente independente do loop de exibição de log.
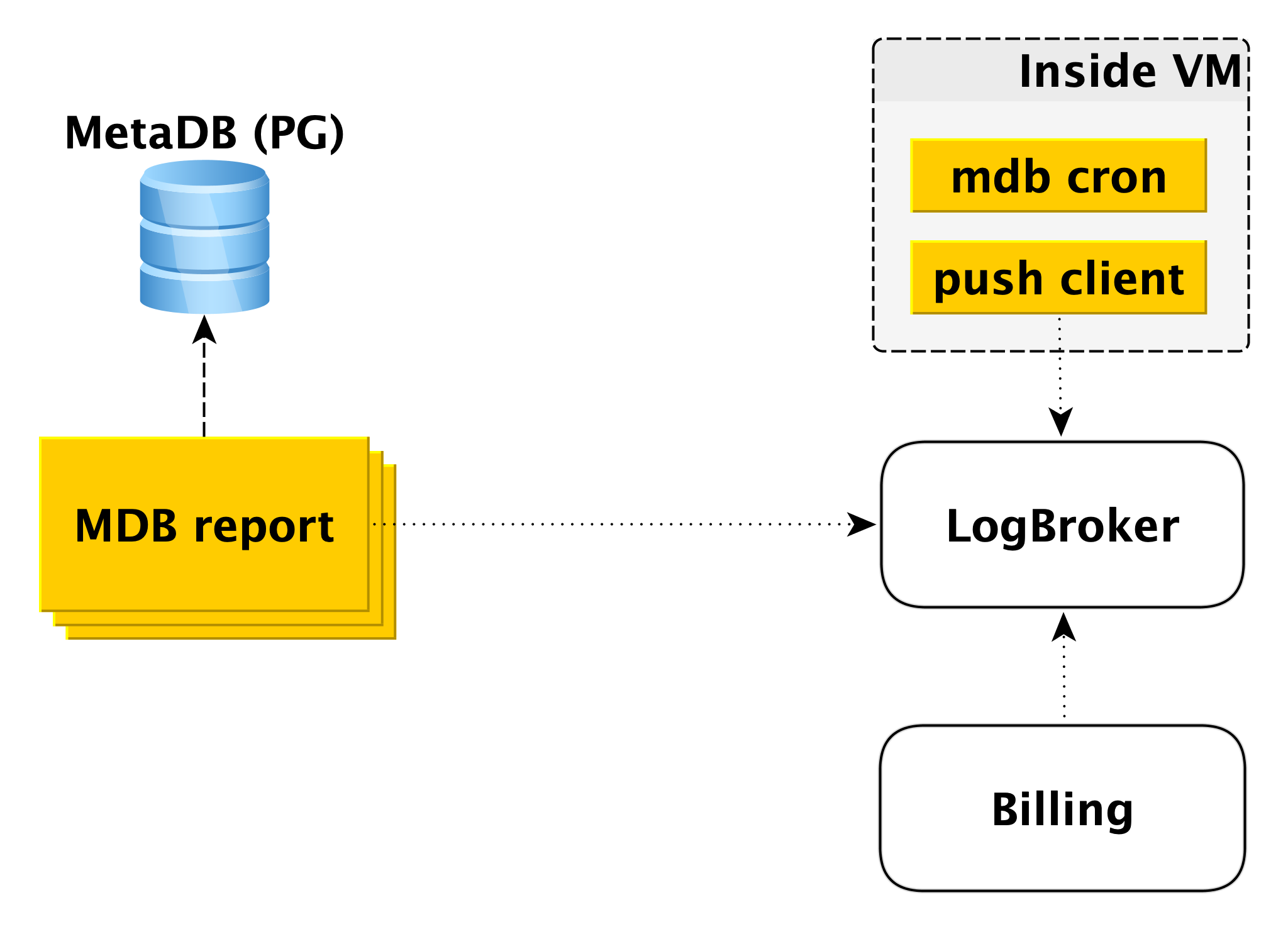
Faturamento
O esquema de cobrança é construído de maneira semelhante. Dentro da máquina virtual, há um componente que verifica com certa periodicidade que tudo está em ordem com o banco de dados. Se tudo estiver bem, você poderá executar o faturamento para esse intervalo de tempo a partir do momento do último lançamento. Nesse caso, um registro é feito no log de cobrança e, em seguida, o cliente push envia o registro para o LogBroker. Os dados do Logbroker são transferidos para o sistema de faturamento e os cálculos são feitos lá. Este é um esquema de cobrança para a execução de clusters.
Se o cluster estiver desativado, o uso de recursos de computação deixa de ser cobrado; no entanto, o espaço em disco é cobrado. Nesse caso, o faturamento da máquina virtual é impossível e o segundo circuito está envolvido - o circuito de faturamento offline. Há um conjunto de máquinas separado que executa a varredura da lista de clusters de desligamento do MetaDB e grava um log no mesmo formato no Logbroker.
O faturamento off-line pode ser usado para faturamento e também inclui clusters, mas, em seguida, os hosts de faturamento, mesmo que estejam em execução, mas não funcionam. Por exemplo, quando você adiciona um host a um cluster, ele é implantado a partir do backup e é acompanhado pela replicação. É errado cobrar o usuário por isso, porque o host está inativo por esse período.
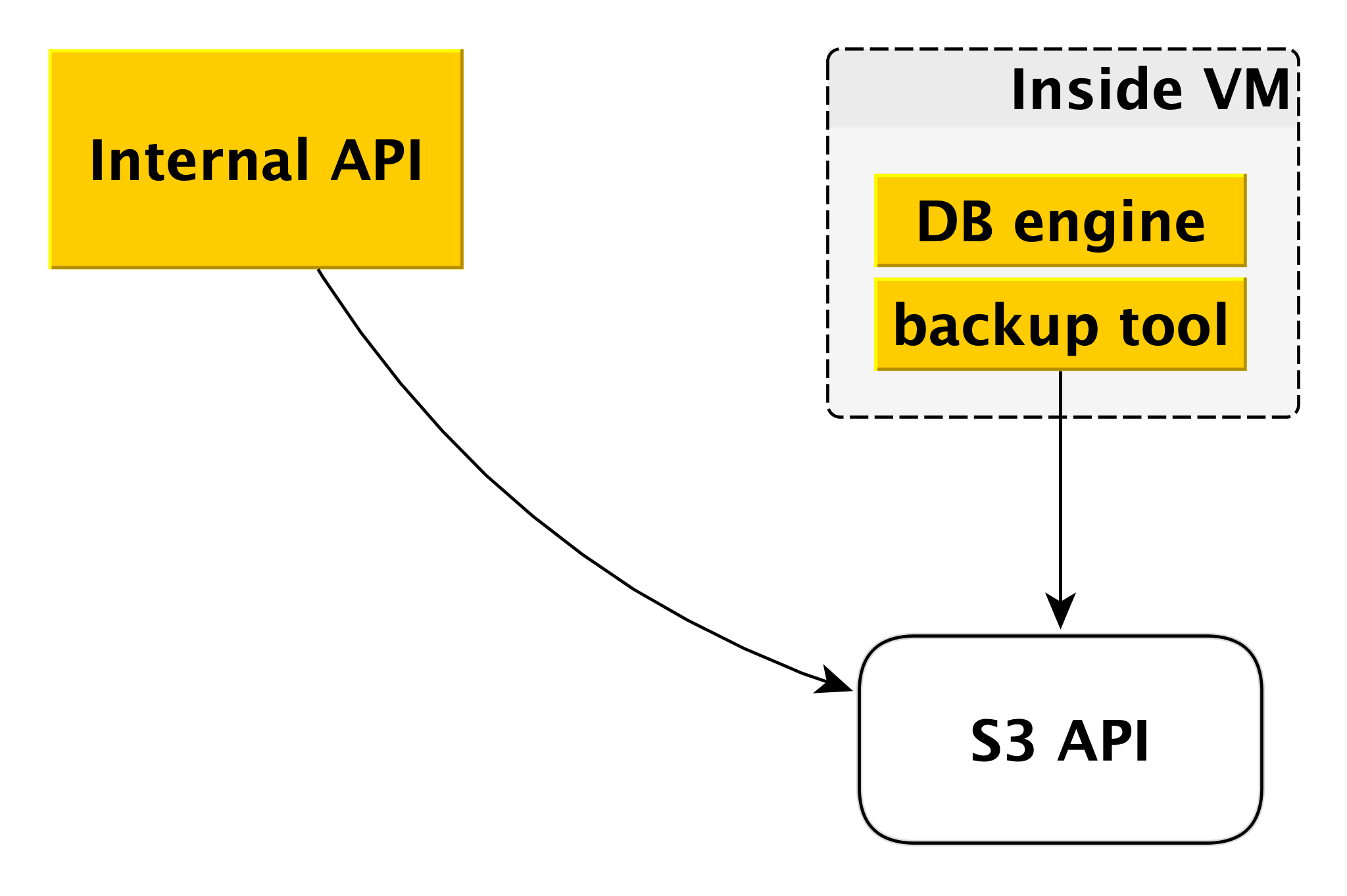
Backup
O esquema de backup pode diferir ligeiramente para diferentes DBMSs, mas o princípio geral é sempre o mesmo.
Cada mecanismo de banco de dados usa sua própria ferramenta de backup. Para PostgreSQL e MySQL, este é o
WAL-G . Ele cria backups, os compacta, criptografa e os coloca no
Yandex Object Storage . Ao mesmo tempo, cada cluster é colocado em um bucket separado (primeiro, para isolamento e, em segundo lugar, para facilitar a economia de espaço para backups) e é criptografado com sua própria chave de criptografia.
É assim que o plano de controle e o plano de dados funcionam. De tudo isso, o serviço de banco de dados gerenciado Yandex.Cloud é formado.
Por que tudo está organizado dessa maneira
Obviamente, no nível global, algo poderia ser implementado de acordo com esquemas mais simples. Mas tínhamos nossas próprias razões para não seguir o caminho de menor resistência.
Antes de tudo, queríamos ter um plano de controle comum para todos os tipos de DBMS. Não importa qual você escolher, no final, sua solicitação chega à mesma API interna e todos os componentes nela também são comuns a todos os DBMSs. Isso torna nossa vida um pouco mais complicada em termos de tecnologia. Por outro lado, é muito mais fácil introduzir novos recursos e recursos que afetam todos os DBMSs. Isso é feito uma vez, não seis.
O segundo momento importante para nós - queríamos garantir o máximo possível a independência do plano de dados do plano de controle. E hoje, mesmo que o Control Plane esteja completamente indisponível, todos os bancos de dados continuarão funcionando. O serviço garantirá sua confiabilidade e disponibilidade.
Em terceiro lugar, o desenvolvimento de praticamente qualquer serviço é sempre um compromisso. Em um sentido geral, grosso modo, em algum lugar mais importante é a velocidade de lançamento de lançamentos e em alguma confiabilidade adicional. Ao mesmo tempo, agora ninguém pode se dar ao luxo de fazer um ou dois lançamentos por ano, isso é óbvio. Se você olhar para o Control Plane, aqui vamos nos concentrar na velocidade do desenvolvimento, na rápida introdução de novos recursos, lançando atualizações várias vezes por semana. E o Data Plane é responsável pela segurança de seus bancos de dados, pela tolerância a falhas, então aqui está um ciclo de lançamento completamente diferente, medido em semanas. E essa flexibilidade em termos de desenvolvimento também nos proporciona sua independência mútua.
Outro exemplo: os serviços de banco de dados gerenciados geralmente fornecem aos usuários apenas unidades de rede. O Yandex.Cloud também oferece unidades locais. O motivo é simples: a velocidade deles é muito maior. Com unidades de rede, por exemplo, é mais fácil escalar a máquina virtual para cima e para baixo. É mais fácil fazer backups na forma de instantâneos do armazenamento em rede. Como muitos usuários precisam de alta velocidade, aumentamos o nível das ferramentas de backup.
Planos futuros
E algumas palavras sobre planos para melhorar o serviço a médio prazo. Esses são os planos que afetam os bancos de dados gerenciados Yandex como um todo, em vez dos DBMSs individuais.
Antes de tudo, queremos oferecer mais flexibilidade na definição da frequência de criação de backup. Existem cenários em que é necessário que durante o dia os backups sejam feitos uma vez a cada poucas horas, durante a semana - uma vez por dia, durante o mês - uma vez por semana, durante o ano - uma vez por mês. Para fazer isso, estamos desenvolvendo um componente separado entre a API interna e o
Yandex Object Storage .
Outro ponto importante, importante para nós e usuários, é a velocidade das operações. Recentemente, fizemos grandes alterações na infraestrutura Deploy e reduzimos o tempo de execução de quase todas as operações para alguns segundos. Não foram cobertas apenas as operações de criação de um cluster e inclusão de um host no cluster. O tempo de execução da segunda operação depende da quantidade de dados. Mas o primeiro, aceleraremos em um futuro próximo, porque os usuários geralmente desejam criar e excluir clusters em seus pipelines de CI / CD.
Nossa lista de casos importantes inclui a adição da função de aumentar automaticamente o tamanho do disco. Agora isso é feito manualmente, o que não é muito conveniente e nem muito bom.
Por fim, oferecemos aos usuários um grande número de gráficos mostrando o que está acontecendo com o banco de dados. Damos acesso aos logs. Ao mesmo tempo, vemos que os dados às vezes são insuficientes. Precisa de outros gráficos, outras fatias. Aqui também planejamos melhorias.
Nossa história sobre o serviço de banco de dados gerenciado acabou sendo longa e provavelmente bastante entediante. Melhor do que quaisquer palavras e descrições, apenas prática real. Portanto, se você quiser, poderá avaliar independentemente os recursos de nossos serviços: