Provavelmente, em todas as cidades da Bielorrússia onde há trólebus, existem grupos VK ou bate-papos no Telegram nos quais as pessoas rastreiam a localização dos controladores. Isso é feito principalmente para não pagar pela viagem e viajar de graça, embora a descrição dos grupos quase sempre contenha o pós-escrito "Pagar pela viagem".
No VC, geralmente é assim:
Um comentário típico é assim:
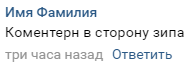
A estrutura é extremamente simples. No comentário, há nomes da parada em que os controladores foram notados no momento, há também a direção em que eles estão:
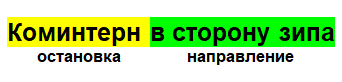
O comentário, como resultado, é um objeto com uma parada, hora e data, além de um ID exclusivo pelo qual podemos identificá-lo. Com isso, você pode calcular o local mais provável de onde os controladores estão agora.
Preparação
Primeiro, você precisa determinar o público-alvo, a partir do qual analisaremos os dados. O grupo deve ter bastante atividade nos comentários, caso contrário, corremos o risco de obter muito poucos dados
No meu caso, este é o grupo "Control Gomel".
Analisaremos os comentários usando a API oficial do VKontakte para Python
Nós nos autenticamos com a chave de acesso do usuário, pois alguns grupos podem ser fechados e o acesso aos comentários deles só pode ser obtido se você for aceito no grupo.
Depois disso, você pode começar a extrair comentários:
Receber comentários
Para começar, obtemos a última postagem disponível no grupo para extrair comentários através do vk.wall.getComments e inicializamos o DataFrame, no qual salvaremos os dados.
Cada postagem de comentário tem a inscrição "Tenha um bom dia, pague a tarifa e não fique sob controle", então faça o download dos comentários, verifique o conteúdo da postagem e obtenha uma série de comentários dos quais você pode obter dados.
Eu recebi comentários de postagens nos últimos 3 meses, uma vez que uma postagem é publicada todos os dias (agora no final de novembro, o ano letivo começa em setembro, e os supervisores provavelmente levam isso em consideração e mudam de lugar). Em princípio, outros sinais podem ser levados em consideração, como, por exemplo, a época do ano.
Alguns dos comentários estão entupidos com mensagens como "Existe alguém no Barykin?" Se você olhar para esses comentários (desnecessários), poderá destacar alguns sinais:
- O texto contém as palavras "limpo", "esquerdo", "ninguém" e similares
- As palavras "me diga", "quem", "o que", "como"
- Símbolos, como emoticons, por exemplo
Depois disso, passamos por uma série de comentários e obtemos deles um ID, texto, hora, data e dia da semana únicos, que colocamos no DataFrame já criado.
Receber comentáriosimport re import time import pandas as pd import lp import vk_api import check_correctness def auth(): vk_session = vk_api.VkApi(lp.login, lp.password) vk_session.auth() vk = vk_session.get_api() return vk def getDataFromComments(vk, groupID):
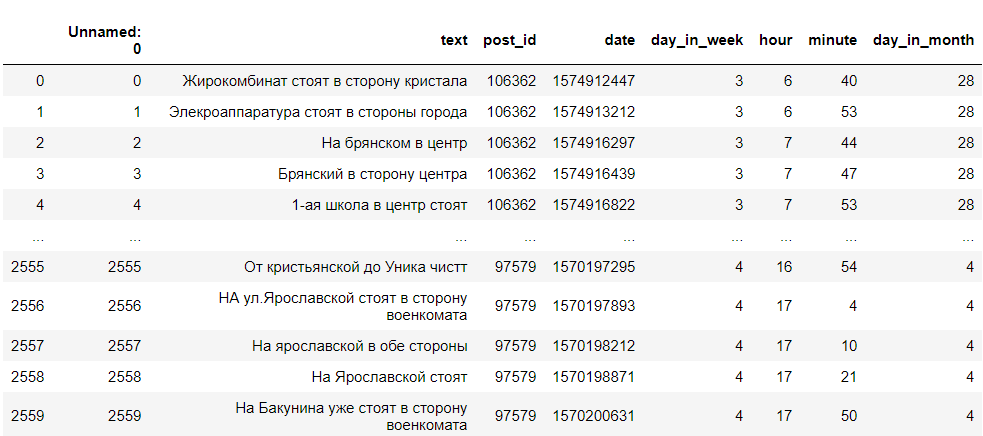
Assim, recebemos um DataFrame com o texto dos comentários, sua identificação, dia da semana, hora e minuto em que o comentário foi escrito. Precisamos apenas do dia da semana, da hora de escrever e do texto. Parece algo como isto:
Limpeza de dados
Agora precisamos limpar os dados. É necessário remover a direção do comentário para cometer menos erros ao procurar a distância de Levenshtein. Encontramos as expressões “ao lado”, “ir”, “como”, “próximo”, como geralmente são seguidas pelo nome da segunda parada, e as excluímos junto com o que vem depois delas, além de substituir alguns nomes de jargões das paradas pelas usuais. .
Limpar dados from fuzzywuzzy import process def clear_commentary(text): """ - """ index = 0 splitted = text.split(" ") for i, s in enumerate(splitted): if len(splitted) == 1: return np.NaN if ((("" in s) or ("" in s) or ( "" in s) or ( "" in s)) and s is not ""): index = i if index is not 0 and index < len(splitted) - 2: for i in range(1, 4): splitted.remove(splitted[index]) string = " ".join(splitted) text = (string.lower()) elif index is not 0: splitted = splitted[:index] string = " ".join(splitted) text = string.lower() else: text = " ".join(splitted).lower() return text def clean_data(data): data.dropna(inplace=True) data["text"] = data["text"].map(lambda s: clear_commentary(s)) data.dropna(inplace=True) print("cleaned") return data
Convertendo usando a distância de Levenshtein
Prosseguimos diretamente para a distância de Levenshane. Uma pequena ajuda: distância de Levenshtein - o número mínimo de operações para inserir um caractere, excluir um caractere e substituir um caractere por outro, necessário para transformar uma linha em outra.
Vamos encontrá-lo usando a biblioteca
fuzzywuzzy . Ajuda você a calcular rápida e facilmente a distância de Levenshtein. Para acelerar o trabalho, os autores da biblioteca também recomendam a instalação da biblioteca python-Levenshtein.
Para obter pontos nos comentários, precisamos de uma lista de pontos. Foi gentilmente fornecido a mim pelo desenvolvedor do aplicativo GoTrans, Alexander Kozlov.
A lista teve que ser expandida, adicionando algumas paradas que não estavam lá e mudando parte dos nomes para que eles ficassem melhor localizados.
Párastops = ['supermercado', 'campina', 'remybtekhnika', 'Leningrado', 'Yaroslavl', 'Polesskaya',
'Yaroslavl', 'timofeenko', '8 de março',
'Rechitsky trading house', 'Rechitsky avenue', 'circus', 'store store', 'Chongarskaya',
'chongarka', 'ggu', 'skorina', 'university', 'appliance', '1000 little things', 'maya', 'station',
'parque de pós-graduação', 'comércio e economia', 'aniversário', 'microdistrito 18', 'aeroporto', 'próximo',
«gomelgeodezcentr», «crystal», «lake lyubenskoye», «davydovsky market», «davydovka»,
«rio sozh», «gomeldrev»,
'Sevruki', 'gmu No. 1', 'etc. Rechitsky', 'traje', 'hospital de doenças infecciosas', 'campo de gaivotas',
Volotova, Coral, Gomeltorgmash, Gomelproekt, Vneshgomelstroy, Newspaper,
«Kalenikova», «Eremino», «destilaria», «automação industrial especial», «2ª escola», «Barykina»,
'unidades de máquina', 'juventude', 'corpo fundido', 'químicos', 'golovatsky', 'budenny',
'spu67', '35th', 'gagarin', '50 anos até a fábrica de Gomselmash ',' hill ',' factory factory ',
'avó', 'vidraria', 'castanha', 'motores de partida', 'astronautas',
'rtsrm inicial', 'bykhovskaya', 'instituto do ministério de situações de emergência', 'dk gomselmash', 'store', 'rechitsky',
"Sevruks", "Osovtsy", "turista", "fábrica de carne", "Santíssima Trindade", "cidade médica", "outubro",
'depósito de petróleo', 'gomelloblavtotrans', 'milkavita', 'bakunin', 'zip', 'oma', 'resin',
«mercado da construção ksk», «construtor de estradas», «campo», «kamenetskaya», «bolchevique», «jakubovka»,
'Borodina', 'hipermercado hipopótamo', 'heróis subterrâneos', '9 de maio', 'castanha', 'protético',
'estação iput', 'internacional comunista', 'faculdade pedagógica de música', 'empresa agrícola', 'estrada secundária', 'vitória',
'western', 'pearl', 'Vladimir', 'dry', 'dispensary', 'Ivanova',
'construção de máquinas', 'bétulas', '60 anos ',' engenheiro de potência ',' centrolite ',
'clínica oncológica', 'campo de tiro', 'golovintsy', 'coral', 'sul', 'primavera',
Efremova, fronteira, Bélgica, Gomelstroy, Borisenko, Palácio de Atletismo,
'Michurinsky', 'solar', 'gastello', 'military', 'auto center', 'encanamento', 'uza',
'faculdade de medicina', 'jardim de infância 11', 'bolchevique', 'filhotes', 'Davydovsky', 'oceano', 'progresso',
'Dobrushskaya', 'branco', 'GSK', 'davydovka', 'equipamento elétrico', 'amizade',
'70 anos ',' reparação de automóveis ',' colina sueca ',' circuito ',' canal de água ',' máquina gomel ',
Volotova, Pioneiro, RCM, Khimtorg, 2nd Meadow Lane, Bochkina, Banhos,
'clínica oncológica', 'praça', 'Lênin', '1ª escola', 'loja do sul',
'gomelagrotrans', 'millers', 'lyubensky', 'alistamento militar', 'hospital', 'uza', 'rtsrm',
'lysyukovyh', 'shop iput', 'raton', 'gas station', 'randovsky', 'farmhouse', 'chestnut', 'ropovsky',
'Romanovichi', 'Ilyich', 'remo', 'empresa de construção', 'infeccioso',
'fábrica de gordura', 'serviço de carro', 'agroserviço', 'pegajoso', 'Nikolskaya',
'ceifeiras automotrizes', 'pedreiros', 'materiais de construção', 'máquinas para reparo', 'administração',
«Outubro», «conto de fadas da floresta», «Tatiana», «Boris Tsarikov», «Zharkovsky», «Zaitseva»,
'relocação', 'Karpovich', 'planta de construção de casas', 'transporte elétrico da cidade', 'zlin',
'stadium gomselmash', 'ap 6', 'drive hidráulico', 'locomotive depot', 'car market osovtsy',
'nova vida', 'Zhukova', 'unidade militar', '3ª escola', 'floresta', 'farol vermelho',
'regional', 'Davydovskaya', 'Karbysheva', 'satélite do mundo', 'juventude', 'locomotiva do estádio',
'solar', 'Ladaservice', 'μR 21', 'Aresa', 'internacionalistas', 'Kosareva',
«Bogdanova», «Gomel ferro-betão», μr 20a », μr Rechitsky», «equipamento médico», «Juraeva»,
'faculdade de artesanato', 'gelo', 'dk festival', 'shopping center',
'Kuibyshevsky', 'festival', 'garage koop 27', 'engenharia sísmica', 'milcha', 'tube hospital',
'ptu179', 'produtos químicos', 'corpo de bombeiros', 'hospital', 'ponto de ônibus',
'complexo jornal', 'vitória', 'klenkovsky', 'diamante', 'reparação de motores', 'mkr 19']
Usando .map e fuzzywuzzy.process.extractOne, encontramos a parada com a distância mínima de Levenshtein na lista, após a qual substituímos o texto do comentário pelo nome da parada, o que nos permite obter um conjunto de dados com os nomes das paradas.
O conjunto de dados resultante é mais ou menos assim:
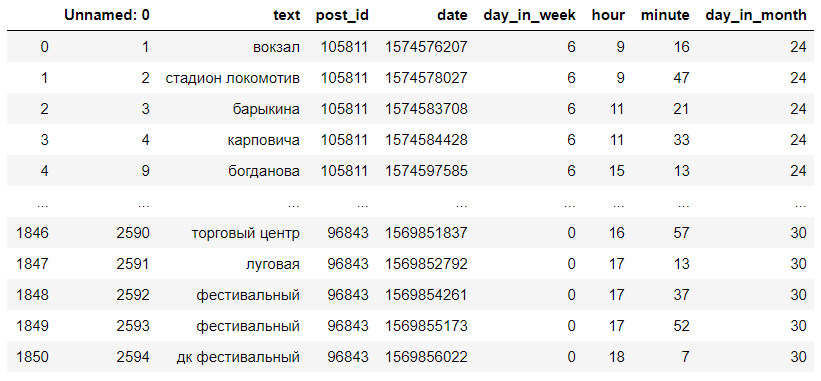
Comentários se transformam em paradas def get_category_from_comment(text): """ """ dict = process.extractOne(text.lower(), stops) if dict[1] > 75: text = dict[0] else: text = np.nan print("wait") return text def get_category_dataset(data): """ """ print("remap started. wait") data.text = data.text.map(lambda comment: get_category_from_comment(str(comment))) print("remap ends") data.dropna(inplace=True) data["text"] = data.text.map(lambda s: "" if s=="" else s) data["text"] = data.text.map(lambda s: "" if s=="" else s) data["text"] = data.text.map(lambda s: " " if s=="" else s) data["text"] = data.text.map(lambda s: " " if s=="" else s) return data
Saída de dados
Agora podemos assumir onde os controladores provavelmente estarão na hora especificada.
Estamos procurando nos registros de dados resultantes por uma hora e dia específicos da semana. Por exemplo, na terça-feira, 9 horas da manhã:
<code>data[(data["day_in_week"] == day) & (data["hour"] == hour)]</code>
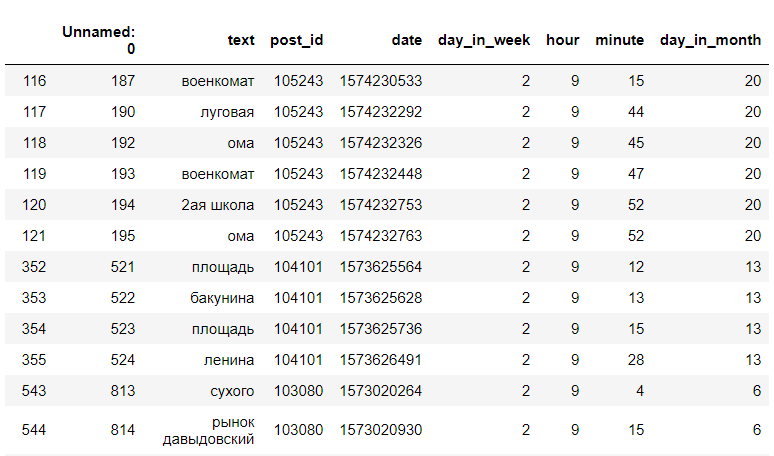 (estes não são todos os dados)
(estes não são todos os dados)Depois disso, encontramos o número de paradas exclusivas e exibimos apenas as paradas e seu número:
df[(df["day_in_week"] == 2) & (df["hour"] == 9)]["text"].value_counts()

Agora podemos dizer que às 9 da manhã, às terças-feiras, os controladores provavelmente serão vistos nas paradas Myasokombinat, ul. Lugovaya, BelGUT, TD "Oma".
A principal falha nesse método é a falta de dados. Não durante todos os dias e horas, há comentários nos comentários feitos na hora do rush, quando as pessoas usam mais o transporte público do que os dados em horários menos populares, mas se você adicionar dados, por exemplo, não apenas dos comentários de um grupo, mas também de grupos alternativos ou bate-papos por telegrama, com o número de entradas, tudo ficará mais fácil.
Bot com a API VK LongPoll
Para dar a oportunidade de receber dados sobre a localização dos controladores, dependendo da hora e sem estar vinculado a um computador, fiz um bot para um grupo no VKontakte que responde a qualquer mensagem enviando o número de paradas nos registros, de acordo com a hora e o dia da semana atuais.
Código bot from random import randint import vk_api from requests import * from get_stops_from_data import get_stops_by_time def start_bot(data, token): vk_session = vk_api.VkApi(token=token) vk = vk_session.get_api() print("bot started") longPoll = vk.groups.getLongPollServer(group_id=183524419) server, key, ts = longPoll['server'], longPoll['key'], longPoll['ts'] while True:
Conclusão
A qualidade de tais hipóteses foi testada por mim mais de uma vez na prática, e tudo funciona bem. Descobriu-se que os controladores estão basicamente nas mesmas paradas, embora previsões absolutamente corretas não possam ser dadas e a probabilidade de sucesso não seja 100%. A distância de Levenshtein tem dezenas de aplicações diferentes, desde a correção de erros em uma palavra até a comparação de genes, cromossomos e proteínas, mas também tem potencial para esses problemas aplicados.
Tenha um bom dia e pague a tarifa.
Todo código de bot e manipulação de dados são publicados
aqui .