Olá pessoal, meu nome é Alexander, trabalho como engenheiro no CIAN e estou envolvido na administração de sistemas e automação de processos de infraestrutura. Nos comentários de um dos artigos anteriores, fomos solicitados a informar onde obtemos 4 TB de logs por dia e o que fazemos com eles. Sim, temos muitos logs e um cluster de infraestrutura separado foi criado para processá-los, o que nos permite resolver rapidamente problemas. Neste artigo, falarei sobre como a adaptamos ao longo do ano para trabalhar com um fluxo crescente de dados.
Por onde começamos
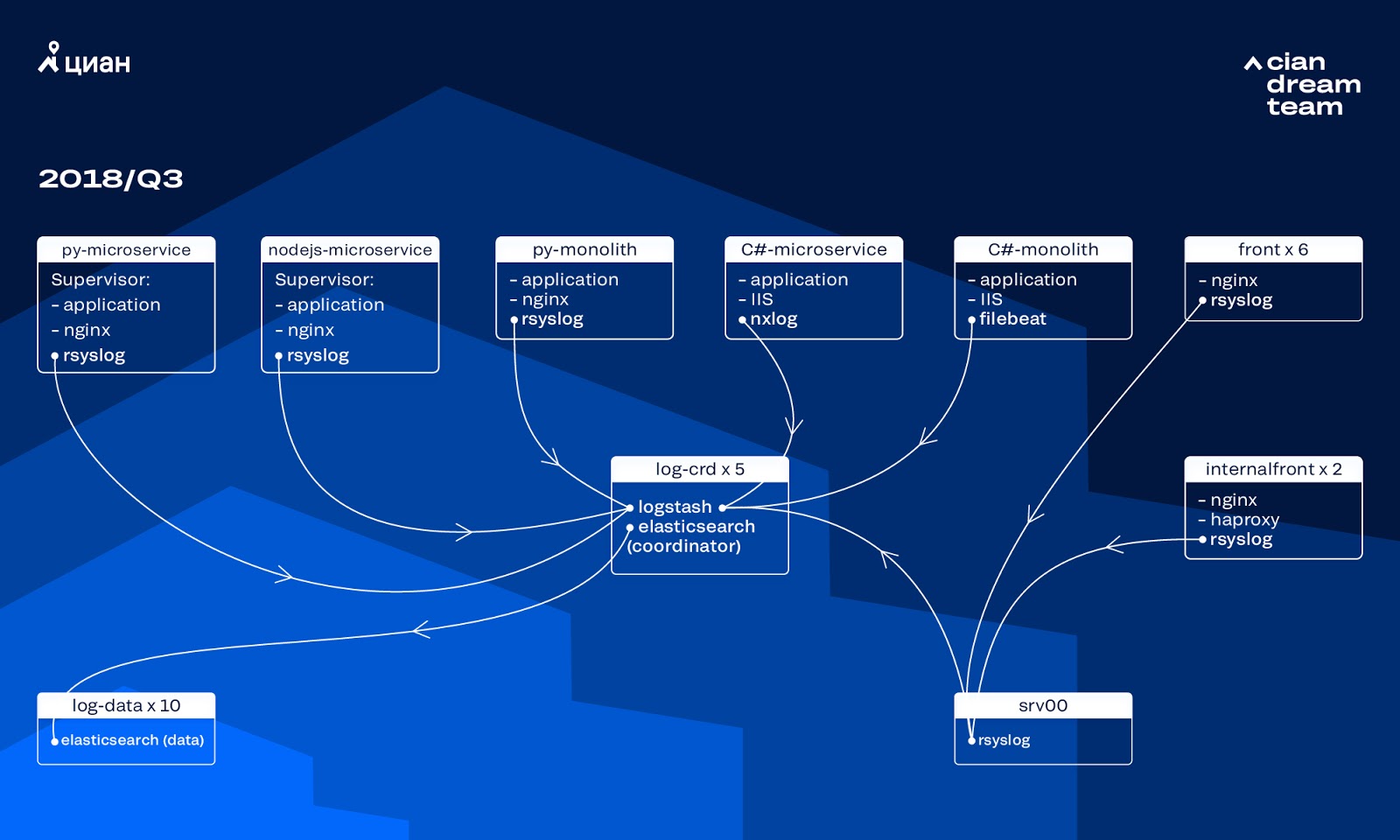
Nos últimos anos, a carga no cian.ru cresceu muito rapidamente e, no terceiro trimestre de 2018, o tráfego de recursos atingiu 11,2 milhões de usuários únicos por mês. Naquele momento, em momentos críticos, perdemos até 40% dos logs, por causa dos quais não conseguimos lidar rapidamente com os incidentes e gastamos muito tempo e esforço resolvendo-os. Muitas vezes, não conseguimos encontrar a causa do problema, e ele voltou após algum tempo. Foi o inferno com o qual você teve que fazer alguma coisa.
Naquele momento, usamos um cluster de 10 nós de dados com o ElasticSearch versão 5.5.2 com configurações típicas de índice para armazenar logs. Foi introduzida há mais de um ano como uma solução popular e acessível: então o fluxo de logs não era tão grande que não fazia sentido criar configurações não-padrão.
O armazenamento de logs em portas diferentes forneceu o processamento de logs de entrada em cinco coordenadores do ElasticSearch. Um índice, independentemente do tamanho, consistia em cinco fragmentos. Como rotação horária e diária foi organizada, como resultado, cerca de 100 novos fragmentos apareceram no cluster a cada hora. Embora não houvesse muitos logs, o cluster gerenciava e ninguém chamava a atenção para suas configurações.
Problemas de crescimento
O volume dos logs gerados cresceu muito rapidamente, pois dois processos se sobrepuseram. Por um lado, havia cada vez mais usuários do serviço. Por outro lado, começamos a mudar ativamente para a arquitetura de microsserviços, vendo nossos antigos monólitos em C # e Python. Várias dezenas de novos microsserviços que substituíram partes do monólito geraram significativamente mais logs para o cluster de infraestrutura.
Foi o dimensionamento que nos levou ao fato de que o cluster se tornou praticamente incontrolável. Quando os logs começaram a chegar a uma velocidade de 20 mil mensagens por segundo, a rotação inútil freqüente aumentou o número de shards para 6 mil, e um nó foi responsável por mais de 600 shards.
Isso causou problemas com a alocação de RAM e, quando um nó caiu, a movimentação simultânea de todos os shards começou, multiplicando o tráfego e carregando os nós restantes, o que tornou quase impossível gravar dados no cluster. E durante esse período ficamos sem registros. E com um problema no servidor, perdemos 1/10 do cluster em princípio. Um grande número de pequenos índices adicionou complexidade.
Sem registros, não entendíamos as causas do incidente e, mais cedo ou mais tarde, podíamos pisar no mesmo rake novamente, mas isso era inaceitável na ideologia de nossa equipe, pois todos os mecanismos de trabalho que tínhamos foram aprimorados exatamente do contrário - nunca repetimos os mesmos problemas. Para fazer isso, precisávamos de um volume completo de logs e sua entrega quase em tempo real, pois uma equipe de engenheiros de serviço monitorava alertas não apenas das métricas, mas também dos logs. Para entender a extensão do problema - naquele momento, o volume total de logs era de cerca de 2 TB por dia.
Estabelecemos uma meta - eliminar completamente a perda de logs e reduzir o tempo de entrega ao cluster ELK para um máximo de 15 minutos durante casos de força maior (contamos com esse número no futuro como um KPI interno).
Novo mecanismo de rotação e nós quentes e quentes
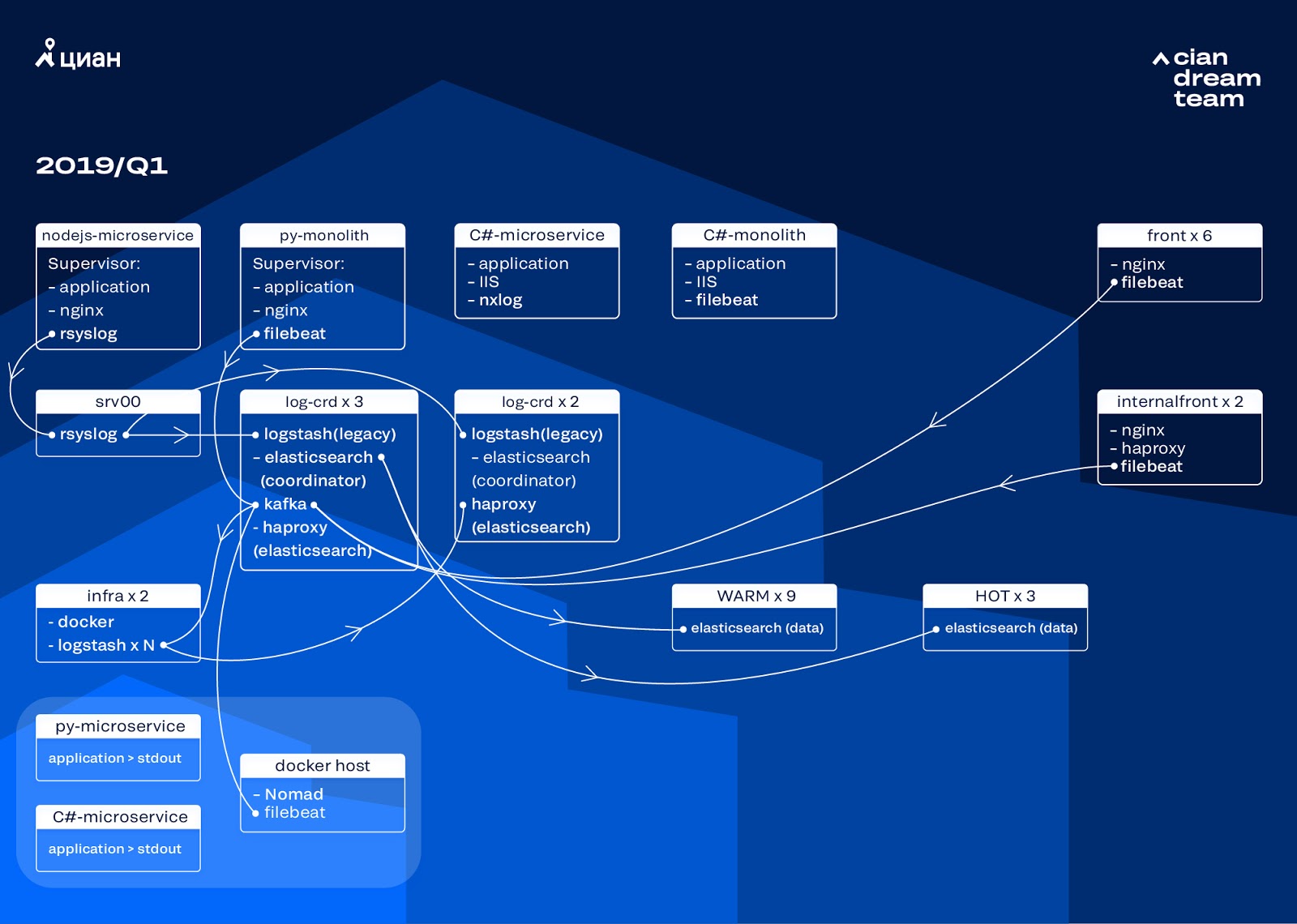
Iniciamos a transformação do cluster atualizando a versão do ElasticSearch de 5.5.2 para 6.4.3. Mais uma vez, um cluster da versão 5 chegou até nós e decidimos reembolsá-lo e atualizar completamente - ainda não há logs. Então fizemos essa transição em apenas algumas horas.
A transformação mais ambiciosa nesse estágio foi a introdução de três nós com o coordenador como um buffer intermediário, Apache Kafka. O intermediário de mensagens nos salvou de perder logs durante problemas com o ElasticSearch. Ao mesmo tempo, adicionamos 2 nós ao cluster e mudamos para uma arquitetura hot-warm com três nós "hot" dispostos em racks diferentes no data center. Nós redirecionamos logs para eles que não devem ser perdidos em nenhum caso - nginx, bem como logs de erro do aplicativo. Logs secundários - depuração, aviso etc. foram para outros nós e, após 24 horas, os logs "importantes" foram movidos dos nós "quentes".
Para não aumentar o número de pequenos índices, passamos da rotação do tempo para o mecanismo de sobreposição. Havia muitas informações nos fóruns de que a rotação por tamanho do índice não é confiável, por isso decidimos usar a rotação pelo número de documentos no índice. Analisamos cada índice e registramos o número de documentos após os quais a rotação deve funcionar. Assim, atingimos o tamanho ideal do shard - não mais que 50 GB.
Otimização de Cluster
No entanto, não nos livramos completamente dos problemas. Infelizmente, pequenos índices pareciam iguais: eles não atingiram o volume definido, não giraram e foram excluídos pela limpeza global de índices com mais de três dias, desde que removemos a rotação por data. Isso levou à perda de dados devido ao fato de o índice do cluster desaparecer completamente e uma tentativa de gravar em um índice inexistente quebrou a lógica do curador que usamos para controle. O alias para gravação foi transformado em um índice e quebrou a lógica da rolagem, causando um crescimento descontrolado de alguns índices para 600 GB.
Por exemplo, para configurar a rotação:
urator-elk-rollover.yaml --- actions: 1: action: rollover options: name: "nginx_write" conditions: max_docs: 100000000 2: action: rollover options: name: "python_error_write" conditions: max_docs: 10000000
Na ausência de alias de rollover, ocorreu um erro:
ERROR alias "nginx_write" not found. ERROR Failed to complete action: rollover. <type 'exceptions.ValueError'>: Unable to perform index rollover with alias "nginx_write".
Deixamos a solução para esse problema para a próxima iteração e levantamos outra questão: alternamos para puxar a lógica do Logstash, que lida com os logs recebidos (removendo informações desnecessárias e enriquecendo). Nós o colocamos na janela de encaixe, que é lançada através do docker-compondo, e no mesmo lugar, colocamos logstash-exportador, que fornece métricas ao Prometheus para monitoramento operacional do fluxo de logs. Portanto, tivemos a oportunidade de alterar suavemente o número de instâncias de logstash responsáveis pelo processamento de cada tipo de log.
Enquanto aprimorávamos o cluster, o tráfego do cian.ru cresceu para 12,8 milhões de usuários únicos por mês. Como resultado, nossas conversões não acompanharam um pouco as mudanças na produção, e fomos confrontados com o fato de que os nós "quentes" não podiam lidar com a carga e atrasaram toda a entrega de logs. Recebemos os dados "quentes" sem falhas, mas tivemos que intervir na entrega do restante e fazer a substituição manual para distribuir uniformemente os índices.
Ao mesmo tempo, o dimensionamento e a alteração das configurações das instâncias de logstash no cluster foram complicados pelo fato de ser uma composição de docker local e todas as ações foram executadas manualmente (para adicionar novos fins, você teve que passar por todos os servidores com as mãos e fazer docker-compose em todos os lugares).
Redistribuição de log
Em setembro deste ano, continuamos vendo o monólito, a carga no cluster aumentou e o fluxo de logs estava se aproximando de 30 mil mensagens por segundo.
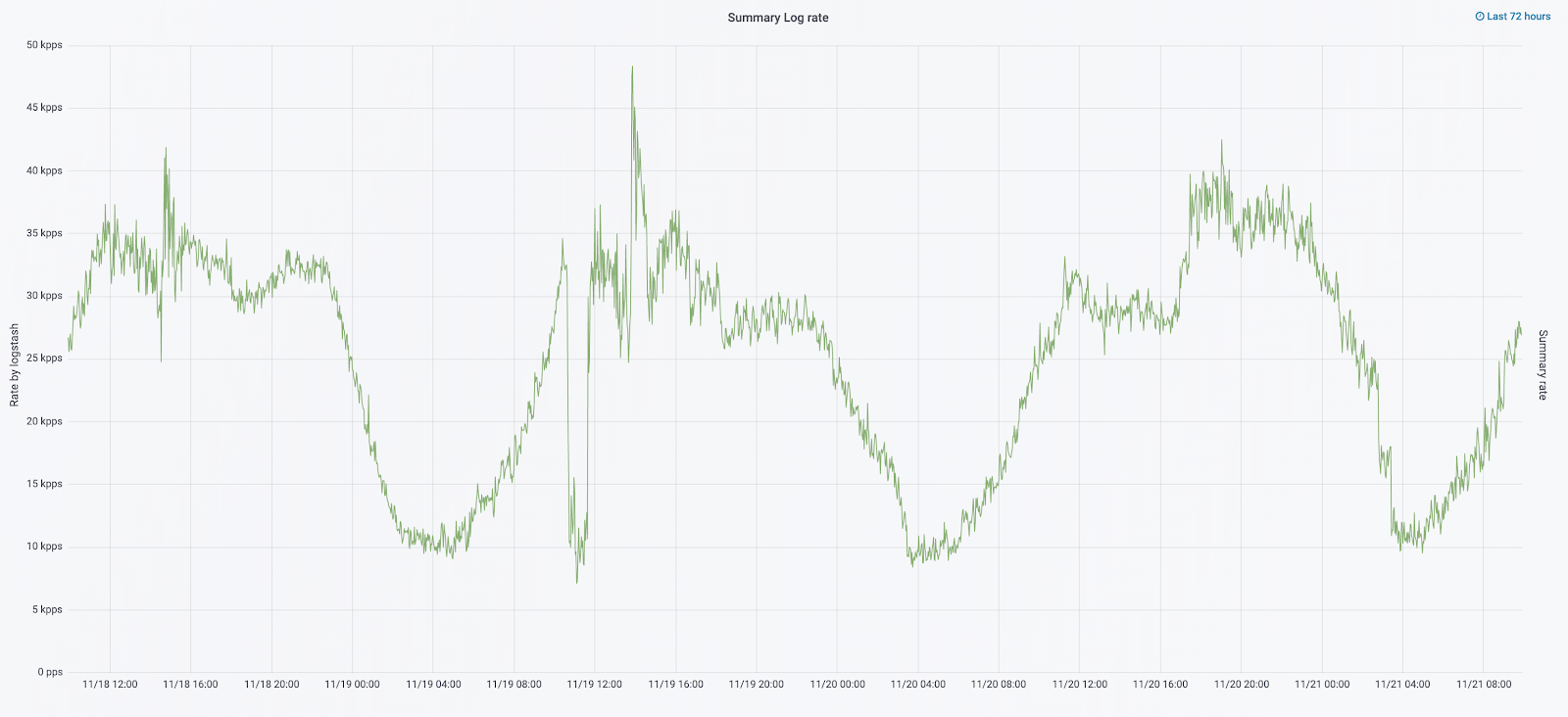
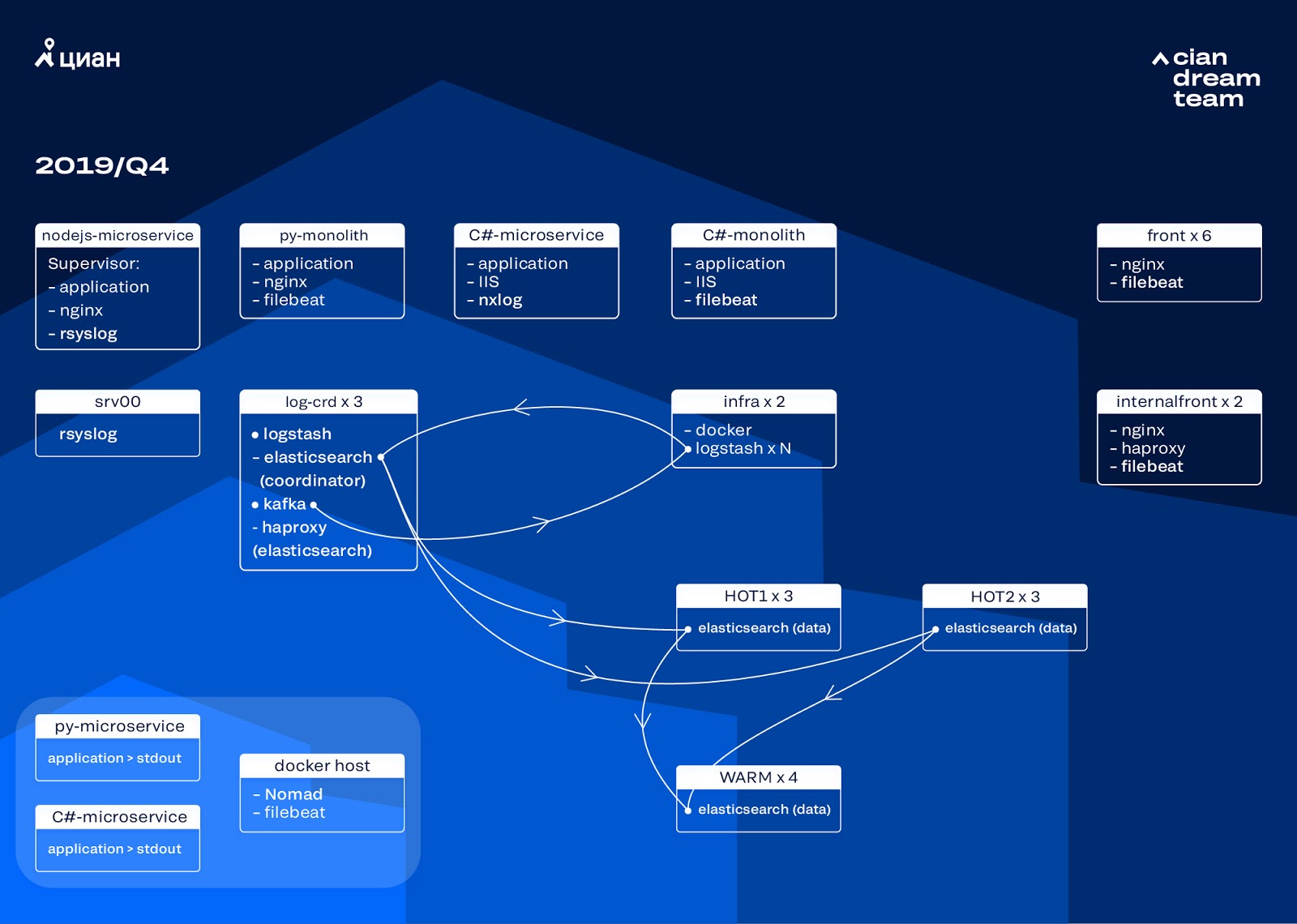
Iniciamos a próxima iteração com a atualização do ferro. Trocamos de cinco coordenadores para três, substituímos os nós de dados e vencemos em termos de dinheiro e volume de armazenamento. Para nós, usamos duas configurações:
- Para nós quentes: E3-1270 v6 / 960Gb SSD / 32 Gb x 3 x 2 (3 para Hot1 e 3 para Hot2).
- Para nós quentes: E3-1230 v6 / 4Tb SSD / 32 Gb x 4.
Nessa iteração, removemos o índice com os logs de acesso ao microsserviço, que ocupam tanto espaço quanto os logs nginx do front-end, no segundo grupo de três nós ativos. Agora, armazenamos dados em nós quentes por 20 horas e depois os transferimos para quente para outros logs.
Resolvemos o problema do desaparecimento de pequenos índices reconfigurando sua rotação. Os índices agora são alternados de qualquer maneira a cada 23 horas, mesmo que haja poucos dados. Isso aumentou um pouco o número de shards (eles se tornaram cerca de 800), mas do ponto de vista do desempenho do cluster isso é tolerável.
Como resultado, seis nós "quentes" e apenas quatro nós "quentes" apareceram no cluster. Isso causa um pequeno atraso nas solicitações por longos intervalos de tempo, mas aumentar o número de nós no futuro resolverá esse problema.
Nesta iteração, o problema da falta de escala semiautomática também foi corrigido. Para isso, implantamos um cluster Nomad de infraestrutura - semelhante ao que já implantamos para produção. Embora o número de Logstash não seja alterado automaticamente, dependendo da carga, mas chegaremos a isso.
Planos futuros
A configuração implementada é bem dimensionada e agora armazenamos 13,3 TB de dados - todos os logs em 4 dias, o que é necessário para a análise emergencial de alertas. Convertemos parte dos logs em métricas, adicionadas ao Graphite. Para facilitar o trabalho dos engenheiros, temos métricas para o cluster de infraestrutura e scripts para corrigir problemas típicos semiautomáticos. Depois de aumentar o número de nós de dados, planejado para o próximo ano, mudaremos para o armazenamento de dados de 4 para 7 dias. Isso será suficiente para o trabalho operacional, pois sempre tentamos investigar incidentes o mais rápido possível e os dados de telemetria estão disponíveis para investigações de longo prazo.
Em outubro de 2019, o tráfego do cian.ru aumentou para 15,3 milhões de usuários únicos por mês. Este foi um teste sério da solução arquitetural para a entrega de logs.
Agora, estamos nos preparando para atualizar o ElasticSearch para a versão 7. No entanto, para isso, precisaremos atualizar o mapeamento de muitos índices no ElasticSearch, porque eles passaram da versão 5.5 e foram declarados descontinuados na versão 6 (eles simplesmente não existem na versão 7). E isso significa que, no processo de atualização, certamente haverá alguma força maior que nos deixará sem registros por enquanto. Das 7 versões, estamos ansiosos pelo Kibana com uma interface aprimorada e novos filtros.
Atingimos o objetivo principal: paramos de perder logs e reduzimos o tempo de inatividade do cluster de infraestrutura de 2-3 quedas por semana para algumas horas de serviço por mês. Todo esse trabalho de produção é quase invisível. No entanto, agora podemos determinar com precisão o que está acontecendo com nosso serviço, podemos fazê-lo rapidamente em modo silencioso e não nos preocupar que os logs sejam perdidos. Em geral, estamos satisfeitos, felizes e nos preparando para novas explorações, sobre as quais falaremos mais adiante.