
Neste post, falarei sobre uma ferramenta para encontrar rapidamente linhas em um banco de dados e navegar por elas. Se você trabalha no suporte e precisa fazer muitas consultas ao banco de dados, se está cansado de escrever SELECTs, por favor, em cat.
Motivação
Há algum tempo, ajudei a manter um grande sistema contábil. No decorrer do trabalho, foi necessário procurar informações no banco de dados. Cenário típico: um usuário com problema chama a pedido N1. Para diagnósticos, você precisa visualizar alguns dados sobre esse aplicativo no banco de dados. Atendemos à solicitação:
SQL SELECT * FROM ORDER WHERE ID = 'N1'
A unidade está associada ao aplicativo, portanto, realizamos a seguinte solicitação para obter informações sobre a unidade:
SQL SELECT * FROM DEVICE WHERE ORDER_ID = 'N1'
Em seguida, procuramos todas as aplicações relacionadas à unidade:
SQL SELECT * FROM ORDERS WHERE DEVICEID = '92375'
E assim por diante Após executar N consultas, mais cedo ou mais tarde, encontraremos um problema nos dados e tomaremos medidas. As desvantagens dessa abordagem são óbvias:
- Escrever consultas manualmente é lento e inconveniente. Especialmente se a estrutura do banco de dados for complexa e houver muitas tabelas. Portanto, é possível modificar a síndrome do túnel.
- Quando você precisar encontrar uma linha relacionada por restrição exclusiva ou chave estrangeira, precisará escrever uma nova consulta.
- Normalmente, as ferramentas de banco de dados exibem dados em forma de tabela. Quando há muitas colunas na tabela, você precisa rolar a tabela horizontalmente ou selecionar colunas na consulta. Novamente, é necessário trabalho manual.
Idéia
Primeiro você precisa simplificar a pesquisa. Esta ação deve ser realizada com um mínimo de cliques. Basta digitar a linha desejada na caixa de texto e pressionar Enter. Normalmente, as chaves primárias são indexadas, para que você possa procurar um valor imediatamente em todas as colunas incluídas em Chaves Primárias ou Restrições Exclusivas.
Então você precisa resolver o problema de navegação. Como pular rapidamente para uma entrada relacionada em uma Chave estrangeira? Você pode imaginar um banco de dados como um sistema de arquivos: imagine que uma linha do banco de dados seja um diretório, uma linha relacionada por Chave Estrangeira seja um link simbólico e um campo que não seja uma Chave Estrangeira seja um arquivo simples. Não vou escrever um driver de sistema de arquivos, é apenas uma analogia. Portanto, as linhas do banco de dados podem ser representadas como uma estrutura hierárquica, que pode ser exibida usando o componente TreeTable.
Você também pode adicionar uma coluna ao componente TreeTable, na qual algum valor significativo para uma determinada linha será exibido. Este valor pode ser obtido concatenando os valores dos campos de linha do banco de dados. Por exemplo, para uma linha de pedido, você pode fazer uma expressão:
ORDER_NAME + ', ' + ORDER_STATUS + ', ' + ORDER_CUSTOMER
Analogia mais próxima: método toString () em java.
Implementação
A programação levou muitos meses. No começo, tentei usar C ++ e Qt, mas acabou sendo difícil: no mundo C ++, não há nada semelhante aos drivers jdbc, e a própria linguagem é muito mais complicada. Portanto, o aplicativo é escrito em Java.
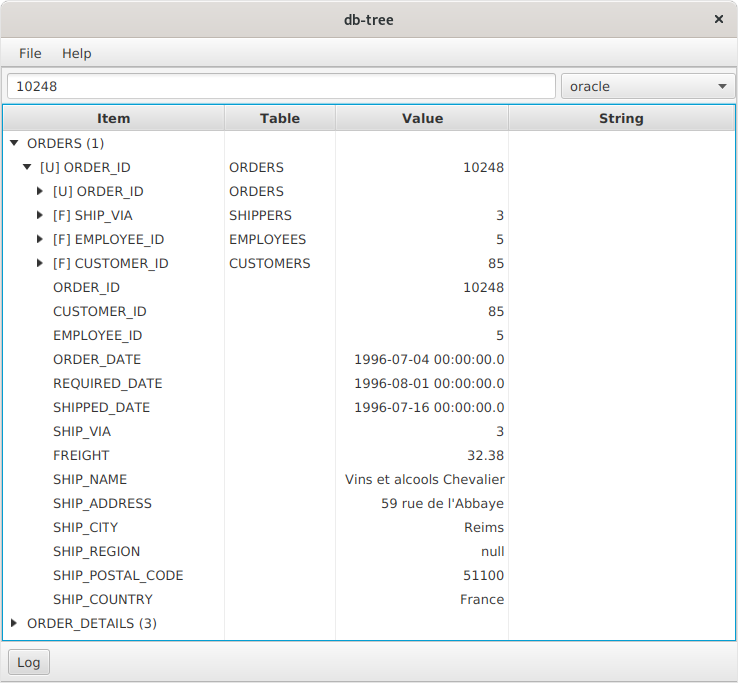
Na captura de tela, vemos a caixa de pesquisa, caixa de combinação para alternar a conexão atual e o componente TreeTable, que exibe dados hierárquicos.
Pesquisar
Você pode inserir uma sequência na caixa de texto e pressionar Enter. A pesquisa agora funciona apenas em colunas de tipos seqüenciais e numéricos: VARCHAR, NUMBER, etc. Os tipos de data e hora ainda não são suportados. Por padrão, a ferramenta procura valores nas colunas incluídas na Chave Primária. Nas configurações, você pode marcar os outros campos que serão usados na pesquisa.
Navegação chave
Os nós rotulados [F] são a chave estrangeira. Na coluna Tabela, vemos o nome da tabela a que essa chave se refere. Depois de aberto o nó, passamos para a linha relacionada. Chaves estrangeiras compostas também são suportadas.
Os nós rotulados como [U] são restrição exclusiva ou chave primária. Tendo expandido o nó, você pode ir para as linhas relacionadas. Dê uma olhada na captura de tela:
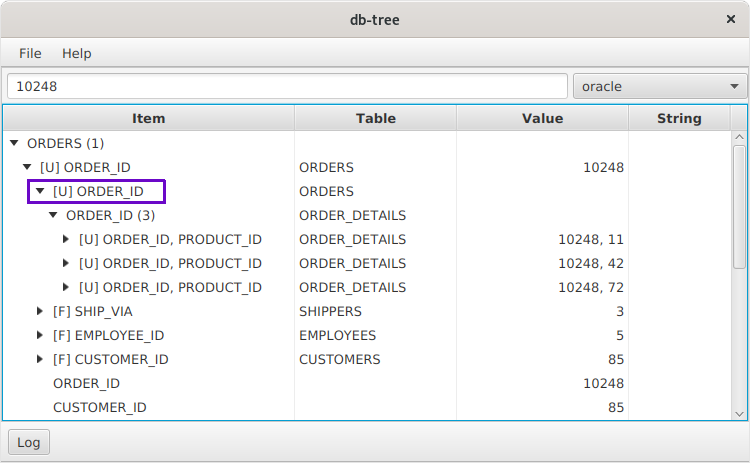
Nós inserimos o valor 10248 na barra de pesquisa e encontramos uma linha na tabela ORDERS. Abrimos o nó [U] ORDER_ID e encontramos 3 linhas na tabela ORDER_DETAILS. Em seguida, você pode expandir cada nó e ir para as linhas da tabela ORDER_DETAILS.
String da coluna
Os valores da chave primária geralmente não são informativos. Na captura de tela anterior, vemos os valores ORDER_ID = 10248, PRODUCT_ID = 11. Esses números não nos dizem nada. Para humanizá-los de alguma forma, você pode fazer uma expressão:
'Product: ' + PRODUCT_ID.PRODUCT_NAME + ', Price: ' + UNIT_PRICE
e insira-o na célula da coluna String:
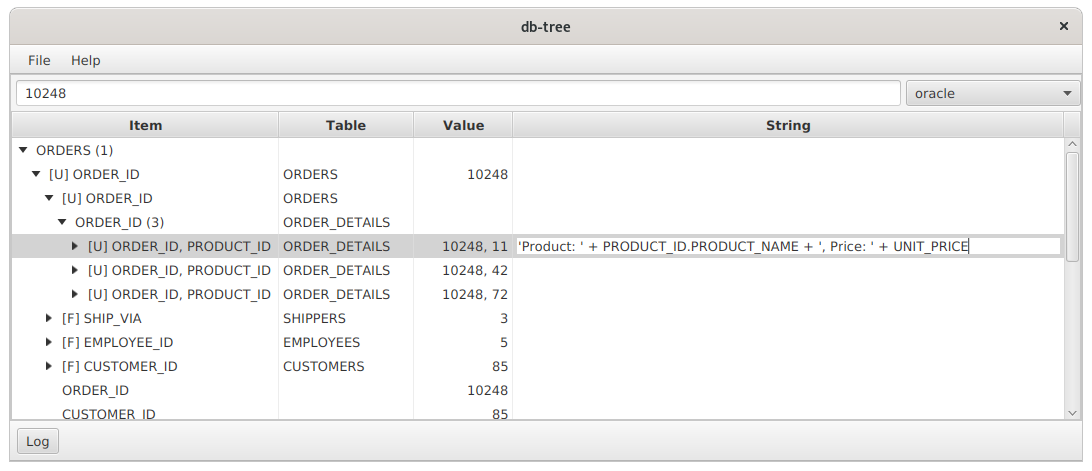
Pressione Enter e veja mais valores significativos:

Detalhes técnicos
O aplicativo é escrito em Java, uma interface em JavaFX. Você pode perceber que o TreeTable usa as seqüências de caracteres "[U]" e "[F]" em vez de ícones, isso foi feito devido a este bug irritante:
JDK-8190331 . As senhas do banco de dados são armazenadas em um repositório seguro usando a biblioteca
java-keyring . O OpenJDK 13 e o
jpackage de compilação de acesso
antecipado são usados para criar
instaladores . Os comandos de compilação podem ser encontrados
aqui .
Os bancos de dados Oracle, MariaDB e PostgreSQL agora são suportados.
Referências
Página de projeto no github:
db-tree-fxSe você encontrar um erro ou precisar adicionar algo, sinta-se à vontade para iniciar o problema ou escreva diretamente no e-mail:
db.tree.app@gmail.com .
Pacotes de instalação
Rpm para GNU / Linux:
db-tree-0.0.2-1.x86_64.rpmDeb para GNU / Linux:
db-tree_0.0.2-1_amd64.debDmg assinado para macOS:
db-tree-0.0.2.dmgMSI assinado para Windows:
db-tree-0.0.2.msi
A versão mais recente pode ser encontrada no
github